背景
检索增强型语言模型(RALMs)在处理需要不断更新的知识和大量信息的文档时确实展现出了优势。然而,现有的方法在处理长篇文档时存在局限性,主要是因为它们通常只能检索较短的文本片段,这限制了对整体文档上下文的全面理解。在NLP中,长篇文档的检索和理解一直是一个挑战,因为传统检索方法往往难以有效处理长文档中的复杂结构和信息,可能导致检索结果不准确或遗漏关键信息。
为了解决这一问题,RAPTOR模型提出了一种创新的策略。它**通过递归地进行文本片段的向量化、聚类和摘要生成,构建了一个树状索引结构。**这种结构不仅捕捉了文档的高层次主题,还保留了低层次的细节,允许基于语义相似性而非仅仅是文本顺序对节点进行分组。这样的树状结构使得RAPTOR能够在不同的抽象层次上加载文档的上下文片段,从而有效地回答不同层次的问题。
方法
一、RAPTOR 树的构建
RAPTOR 树的构建是该模型的核心部分,通过递归的方式创建了一个多层次的树状结构,便于更好地理解和检索长文本信息。以下是 RAPTOR 树构建的步骤:
-
文本分块:
RAPTOR 首先将长文本分割成较短的、连续的文本块。每块文本的长度被限制在100个标记(tokens)以内。如果一个句子的标记数超过这个限制,它会完整地被移动到下一个文本块中,以保持语义的连贯性。 -
文本向量化:
使用SBERT(multi-qa-mpnet-base-cos-v1)对每个文本块进行embedding,生成文本的向量表示,这些嵌入向量将形成树结构的叶节点。 -
文本聚类:
通过文本聚类算法,将语义相似的文本块分组。RAPTOR 使用软聚类方法,允许文本块根据其语义相关性属于多个不同的聚类。聚类算法基于高斯混合模型(GMMs),并采用均匀流形近似和**投影(UMAP)**技术进行降维处理,以更好地捕捉文本数据的局部和全局结构。-
软聚类(Soft Clustering):与传统硬聚类不同,软聚类允许文本片段属于多个聚类,增加了灵活性。
-
高斯混合模型(Gaussian Mixture Models, GMMs): 假设数据点是从多个高斯分布的混合中生成的。
对于给定的文本向量 ( x ),其属于第 ( k ) 个高斯分布的概率表示为:
P ( x ∣ k ) = N ( x ; μ k , Σ k ) P(x|k) = \mathcal{N}(x; \mu_k, \Sigma_k) P(x∣k)=N(x;μk,Σk)
其中 N \mathcal{N} N 是多元高斯分布, μ k \mu_k μk是均值向量, Σ k \Sigma_k Σk 是协方差矩阵。
整体概率分布是一个加权组合:
P ( x ) = ∑ k = 1 K π k N ( x ; μ k , Σ k ) P(x) = \sum_{k=1}^{K} \pi_k \mathcal{N}(x; \mu_k, \Sigma_k) P(x)=k=1∑KπkN(x;μk,Σk)π k \pi_k πk表示第 k k k 个高斯分布的混合权重。
-
降维处理(Dimensionality Reduction):
由于向量嵌入的高维性,使用传统的距离度量可能在高维空间中表现不佳。采用 UMAP技术进行降维。 -
层次聚类结构:
UMAP 中的最近邻参数 n 邻居决定了局部和全局结构的平衡。算法通过变化 n 邻居来创建层次聚类结构,首先识别全局聚类,然后在这些全局聚类内部执行局部聚类。 -
模型选择(Model Selection):
使用贝叶斯信息准则(Bayesian Information Criterion, BIC)来确定最优的聚类数量。- BIC 公式为:
BIC = ln ( N ) ⋅ k − 2 ln ( L ^ ) \text{BIC} = \ln(N) \cdot k - 2 \ln(\hat{L}) BIC=ln(N)⋅k−2ln(L^)
其中 N N N 是文本片段(或数据点)的数量, k k k 是模型参数的数量, L ^ \hat{L} L^ 是模型似然函数的最大值。
- BIC 公式为:
小结:通过聚类算法,RAPTOR 能够有效地组织文本片段,形成具有不同层次的树状结构,从而在检索时能够提供更准确和全面的上下文信息。
-
-
文本摘要生成:
对于每个聚类,使用GPT-3.5生成该聚类的文本摘要。这些摘要随后被重新嵌入,形成树的上一层节点。GPT使用的文本摘要prompt如下:

-
递归构建:
上述过程(3 聚类和 4 摘要生成)递归地重复执行,直到无法进一步聚类或达到预设的层数限制,从而构建出一个从底向上的多层次树状结构。在这个结构中,父节点包含子节点的文本摘要,而子节点是原始文本块或下一级的摘要。

- 树的深度和广度:
- 树的深度取决于文本的复杂性和长度,以及聚类过程何时变得不可行。
- 树的广度则取决于每个聚类中文本块的数量。
二、树的检索
构建好的 RAPTOR 树可以在推理时用于检索。有两种检索策略:树遍历和折叠树。树遍历逐层检索树,而折叠树则将所有层展平为单层进行检索。
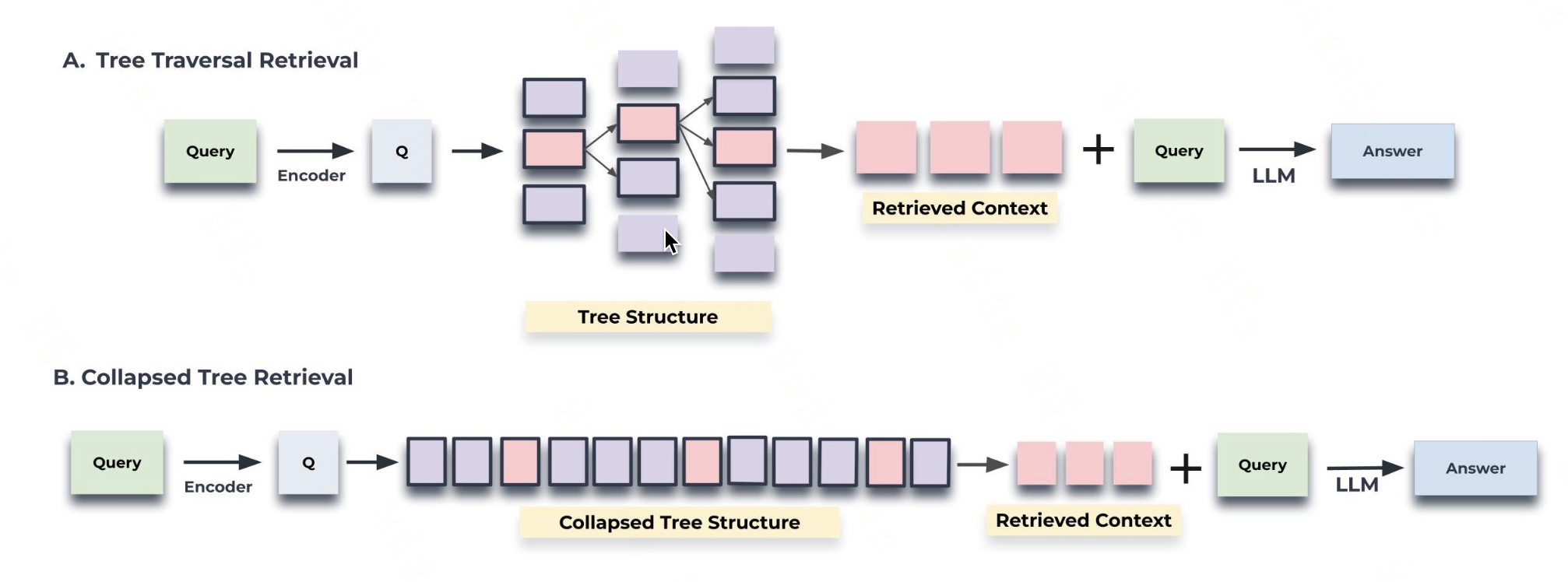
上图展示了树遍历和折叠树检索机制的示意图。树遍历从树的根级别开始,根据与查询向量的余弦相似度检索顶层的 top-k (这里为 top-1) 节点。在每一层,它根据与查询向量的余弦相似度从上一层的 top-k 节点的子节点中检索 top-k 节点。这个过程一直重复,直到达到叶节点。最后,将所有选定节点的文本连接起来形成检索到的上下文。折叠树方法将整个树压缩成单一层,然后根据与查询向量的余弦相似度评估所有层的节点,直到达到设定阈值。
通过树检索信息的例子:

树遍历算法

- 初始化:从树的最底层(即叶子节点层)开始。
- 相似度计算:对于当前层中的每个节点,计算它与查询向量的余弦相似度。
- 选择Top-k节点:根据余弦相似度,选择每个层中与查询最相关的k个节点。
- 递归访问子节点:对于选定的节点,查看其子节点,并重复步骤2和3,直到达到树的根节点。
- 结果整合:将所有选定的节点文本进行拼接,形成检索到的上下文。
折叠树算法

- 树的扁平化:首先,将整个树结构扁平化为一个单一的节点集合,忽略节点之间的层级关系。
- 相似度计算:对于扁平化后的每个节点,计算它与查询向量的余弦相似度。
- 选择Top-k节点:根据余弦相似度,选择与查询最相关的k个节点。
- 限制Token数量:在添加节点到结果集中时,确保不超过模型输入限制的最大Token数量。
- 结果拼接:将选择的节点文本进行拼接,形成检索到的上下文。
小结:通过这种递归构建的树状结构,RAPTOR 能够将长篇文档分解成不同层次的摘要,从而在检索时提供更准确和全面的上下文信息,这对于处理需要综合多部分信息的复杂查询尤为重要。
实验
相关数据集实验


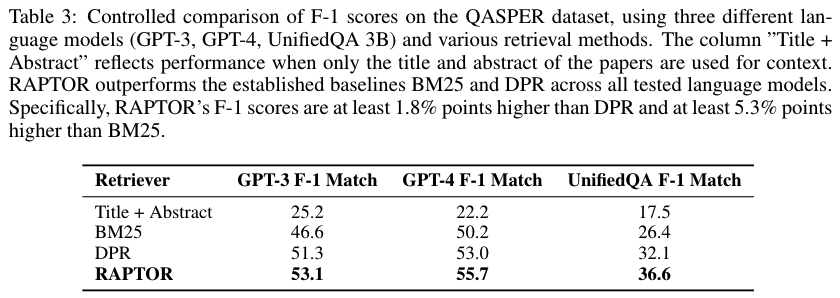


检索效率
RAPTOR 树构建成本与每个数据集的文档长度成线性比例。

对于最大长度为80,000个Tokens的文档,RAPTOR树的构建时间确实与文档长度成正比例关系。这意味着无论文档的实际内容如何,构建树所需的时间都会随着文档长度的增加而线性增加。
这种线性关系表明RAPTOR模型具有良好的可扩展性,能够高效地处理不同长度的文档。这一点非常重要,因为它确保了即使是较长的文档,RAPTOR也能够在合理的时间内完成索引结构的构建。

简易使用
设置LLM
import os
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
from raptor import RetrievalAugmentation
# Initialize with default configuration. For advanced configurations, check the documentation. [WIP]
RA = RetrievalAugmentation()
创建文档树
with open('sample.txt', 'r') as file:
text = file.read()
RA.add_documents(text)
进行问答
question = "How did Cinderella reach her happy ending?"
answer = RA.answer_question(question=question)
print("Answer: ", answer)
保存文档树
SAVE_PATH = "demo/cinderella"
RA.save(SAVE_PATH)
加载文档树问答
RA = RetrievalAugmentation(tree=SAVE_PATH)
answer = RA.answer_question(question=question)
总结
综上所述,RAPTOR模型通过其递归抽象处理方法,有效地解决了现有方法在长篇文档检索中的局限。通过构建树状索引结构,RAPTOR不仅提升了对长篇文档的理解,还增强了检索的准确性和效率,为处理知识密集型任务提供了新的可能。
参考文献
- paper:RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL,https://arxiv.org/pdf/2401.18059
- code:https://github.com/parthsarthi03/raptor