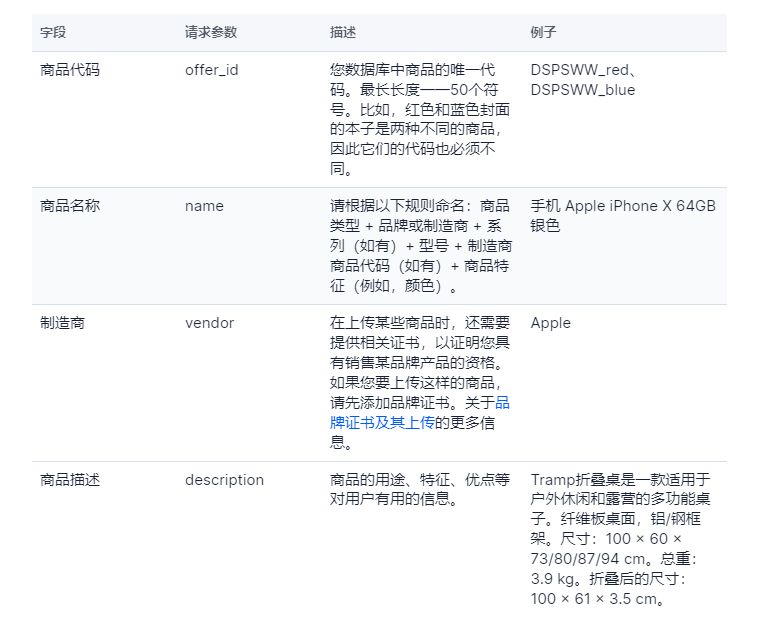
LLM的Attention部分处理给计算系统带来巨大的计算和访存压力。业界先后出现FlashAttention、FlashAttention2等算法,通过计算等价和切分有效降低HBM数据访问量。
昇腾异构计算架构CANN针对昇腾AI处理器的片上内存和缓存大小,以及数据搬运通路,基于Ascend C算子编程语言优化实现FlashAttention融合算子,充分利用片上缓存,提升Attention处理性能。根据实测,在一些典型场景中CANN的FlashAttention算子相比小算子取得了5倍以上的性能提升,开发者可直接调用相关算子API接口使能大模型极致性能优化。
本文针对FlashAttention反向融合算子的性能优化方案展开介绍,并通过优化实现了典型场景4倍左右的性能提升,希望对开发者优化此类基于Ascend C开发的融合算子带来启发。
FlashAttention算法简介
在主流大模型网络模型中,大量使用典型的Multi-Head Attention结构,带来了巨大的计算和内存开销。其运行过程中,矩阵乘和softmax结果存放在片上内存会带来巨大的内存消耗,访存性能严重下降,甚至会导致模型无法正常运行,同时网络中的矩阵和向量计算串行执行,也会导致硬件算力发挥受限。
斯坦福的Tri DAO提出了FlashAttention融合算子,其原理是对attention处理过程进行切分和计算等价,使得attention的多个步骤在一个算子中完成,并且通过多重循环、每次处理一小部分数据,以近似流式的方式访问片上内存,减少了片上内存访问的总数据量,并能够将计算和数据搬运更好的重叠隐藏。


注意力的正向计算公式为:
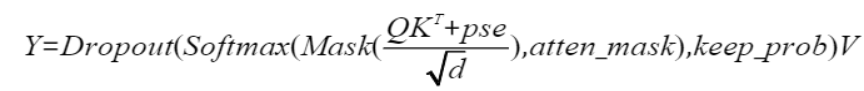
为方便表达,以变量S和P表示计算公式:
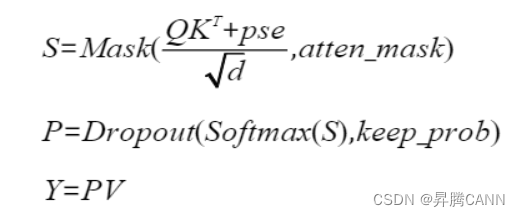
注意力的反向计算公式为:
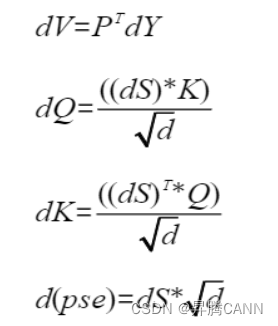
昇腾CANN基于Ascend C编程语言实现了FlashAttention正反向融合算子,其中反向算子计算流程可参考下图所示:
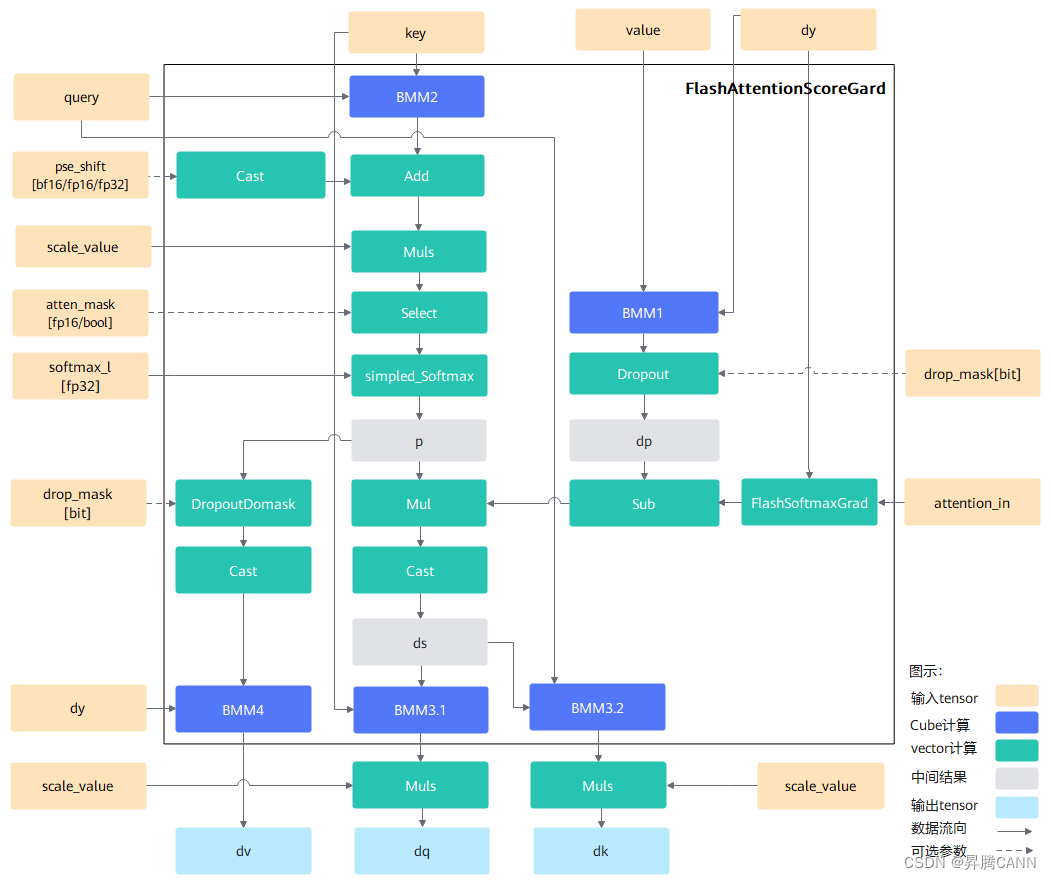
本案例对FlashAttention反向算子进行了性能优化,主要涉及的优化手段包括tiling基本块大小调整,核间负载均衡,CV流水并行,MTE2流水优化以及FixPipe流水优化等,并在Atlas A2训练系列产品/Atlas 800I A2推理产品 验证平台下收益4倍左右的性能提升。下面以如下两个输入场景为例,介绍整个优化过程。
- 第一个场景的输入维度信息为:B=1,N1=12,N2=12,S1=6144,S2=6144,D=128,并且为casual场景,casual场景即atten_mask的形状为下三角。
- 第二个场景的输入维度信息为:B=24,N1=5,N2=5,S1=9216,S2=9216,D=64,不带atten_mask和drop_mask输入。
tiling基本块调整
根据以往优化的经验,循环间可能存在一些不必要的头开销,循环越多性能可能越差;满足UB最大空间限制的情况下,UB切分的基本块越大,循环越少,算子中通过InitBuffer接口分配UB buffer大小。
pipe->InitBuffer(ubBuffer, 120 * 1024);
pipe->InitBuffer(tmpBuffer, 30 * 1024);
pipe->InitBuffer(vecClc3, 8 * 1024);
如上代码所示,InitBuffer接口的第二个参数表示buffer占用的大小,所有buffer大小的和即为占用的总空间。这里120 * 1024 + 30 * 1024 + 8 * 1024 = 158KB < UB Size,没有充分利用UB空间。
接下来试图通过调整tiling基本块进行性能优化,在满足UB空间大小够用的情况下,tiling基本块切分的越大越好。下图为优化前按照(64, 128)切分计算,总共需要循环计算32次:

考虑到UB空间没有用满,基本块调整到(128, 128),如下图优化后只需循环计算16次,切分后算子性能提升一倍:

CV流水并行
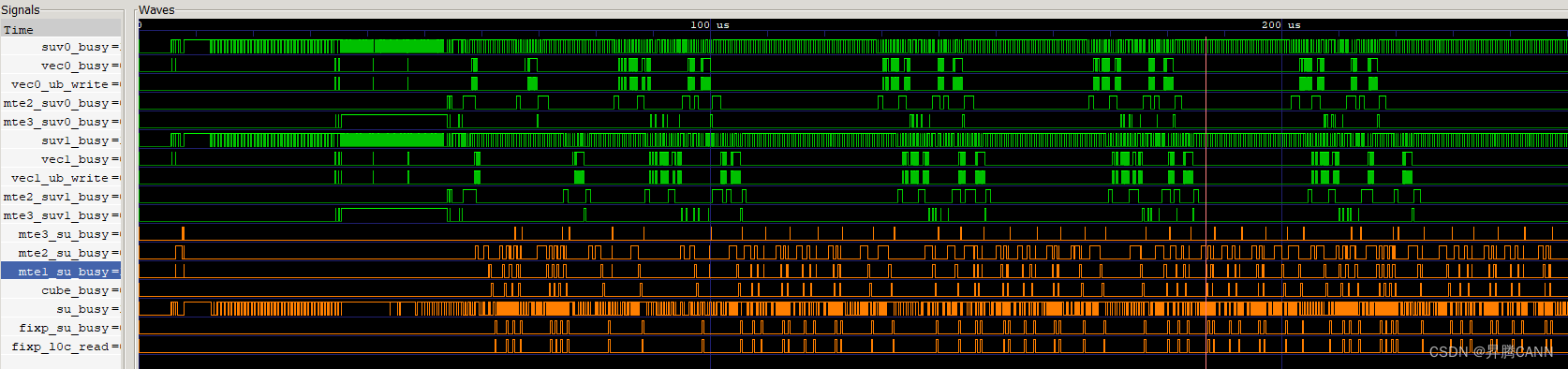
从流水图可以看到,可以看出两侧的流水都存在大段的空隙(图中绿色为vector部分流水,橙色为cube侧流水),CV之间流水很大程度上未并行,需要考虑CV流水优化。
由于FAG算子中cube计算比vector计算快且存在依赖性,同时为了减少CV之间的通信次数,通过缓存机制实现让matmul提前计算多块,这里的缓存机制指的是将mm一次性计算多个基本块缓存到GM上。如下代码中,SetTail设置的SingleM和SingleN大小为BaseM,BaseN的倍数,即matmul一次发起多个基本块的计算,实现matmul结果的缓存,vector侧分多次取matmul的结果。
mm3.SetTail(s2CvExtend, -1, preS1Extend);
mm3.SetTensorA(mulWorkSpaceGm[pingpongIdx * coreNum * cubeBaseMN + cBlockIdx * cubeBaseMN], true);
mm3.SetTensorB(queryGm[mm2aTensorOffsetCv]);
mm3.template IterateAll<false>(dkWorkSpaceGm[bTensorOffsetCv], true);
下图是实现mm1、mm2和mm3缓存的流水图,绿色的vector流水与橙色的cube流水均变得更密集,并行度提高,cv的间隔减小,提升了算子性能: 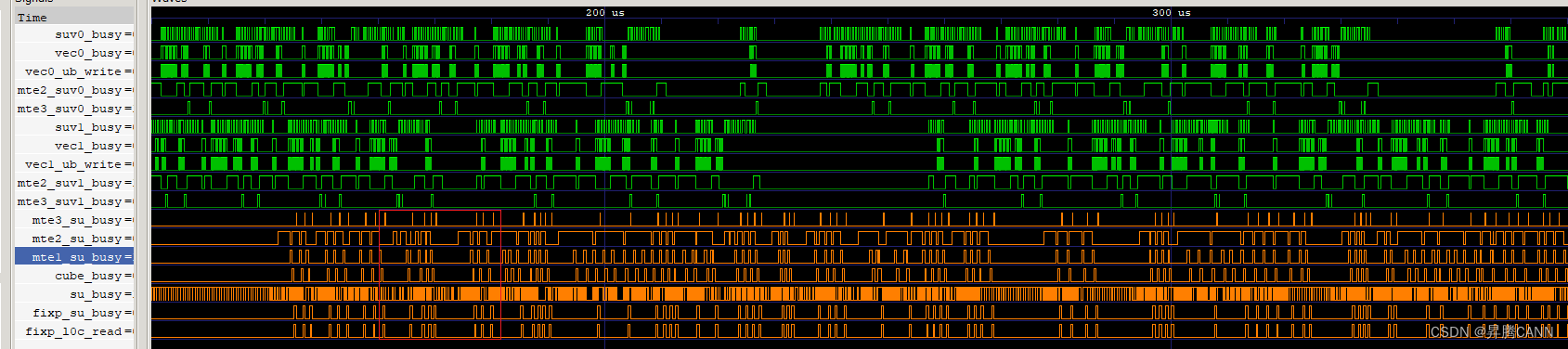
基于缓存mm1/mm2/mm3的优化后,在本轮Vector等Cube流水的间隔,插入下一轮循环的Vector计算,这样使Vector流水与Cube流水之间的并行度更高,反映到流水图中为Vector计算更密集: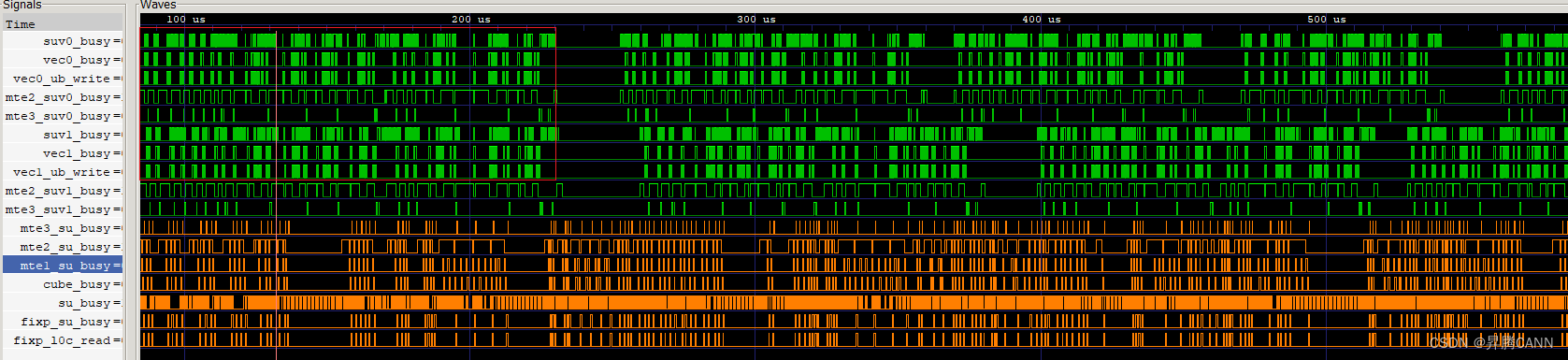
相关优化点实现伪代码如下所示:
mm1计算;
dropout();
Sub();
dropout(); // 下一轮循环的Vector计算
Sub(); // 下一轮循环的Vector计算
mm2计算;
Softmax();
AttenMask();
...
核间负载均衡
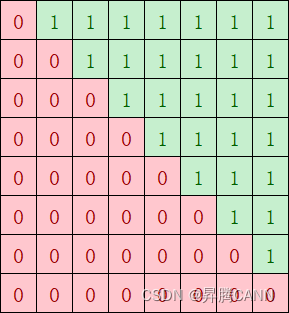
对于上述场景一,casual场景下可能存在核间分布不均匀的情况,如下图经过atten mask掩码后,红色部分是算子需要计算的部分,绿色无需计算;如果不按照基本块的个数来分核,按照第一根轴的大小8(行)来分核,假设平均分到9个核上,每个核做ceil(8 / 9) = 1行,则第一个核只需做1个基本块,但是第8个核需要做8个基本块的计算,出现严重的负载不均衡:
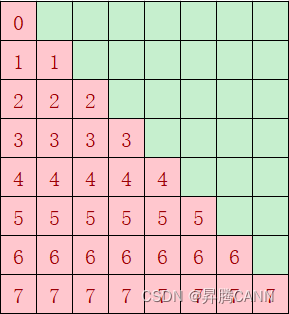
因此需要考虑将红色块均匀分到多个核上计算,尽量实现每个核的计算量均匀,负载均衡。优化后,红色块总共36个基本块,均分到每个核上,每个核的计算量为4块,性能提升一倍。

FixPipe流水优化
通过对场景一的Profilling数据进行分析可以看到,aic_fixpipe_ratio占比极高,占比高达81%,出现了很严重的bound:
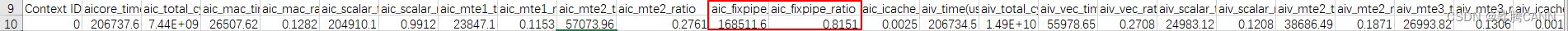
同时,CAModel工具打印发现存在很多异常的128B搬运,经过代码排查,发现workspace地址未512B对齐。代码实现中使用SetGlobalBuffer接口设置workspace的起始地址,如果起始地址不是按照512B对齐,搬运效率会很低,可以强制地址512B对齐来避免这个情况,下面代码中ADDR_ALIGN_SIZE即为512:
// init workspace address
syncGlobal.SetGlobalBuffer((__gm__ int32_t*)workspace);
uint64_t workspaceOffsets = SYNC_GLOBAL_WORKSPACE_SIZE;
dqWorkSpaceGm.SetGlobalBuffer((__gm__ float*)workspace + workspaceOffsets / sizeof(T2));
workspaceOffsets = (workspaceOffsets + qPostBlockTotal * sizeof(float) + ADDR_ALIGN_SIZE) / ADDR_ALIGN_SIZE * ADDR_ALIGN_SIZE; dkWorkSpaceGm.SetGlobalBuffer((__gm__ float*)workspace + workspaceOffsets / sizeof(T2));
workspaceOffsets = (workspaceOffsets + kvPostBlockTotal * sizeof(float) + ADDR_ALIGN_SIZE) / ADDR_ALIGN_SIZE * ADDR_ALIGN_SIZE; dvWorkSpaceGm.SetGlobalBuffer((__gm__ float*)workspace + workspaceOffsets / sizeof(T2));
workspaceOffsets = (workspaceOffsets + kvPostBlockTotal * sizeof(float) + ADDR_ALIGN_SIZE) / ADDR_ALIGN_SIZE * ADDR_ALIGN_SIZE;
// matmul1 and matmul2 workspace size
matmulWorkspaceSize = cubeBaseMN * sizeof(float);
mm1WorkspaceGm.SetGlobalBuffer((__gm__ T2*)(workspace + workspaceOffsets + cBlockIdx * matmulWorkspaceSize)); mm2WorkspaceGm.SetGlobalBuffer((__gm__ T2*)(workspace + workspaceOffsets + coreNum * matmulWorkspaceSize + cBlockIdx * matmulWorkspaceSize)); // drop workspace offset
workspaceOffsets = (workspaceOffsets + coreNum * cubeBaseMN * sizeof(float) * INPUT_NUMS + ADDR_ALIGN_SIZE) / ADDR_ALIGN_SIZE * ADDR_ALIGN_SIZE;
dropWorkSpaceGm.SetGlobalBuffer((__gm__ T1*)workspace + workspaceOffsets / sizeof(T1));
// mul workspace offset
workspaceOffsets = (workspaceOffsets + coreNum * cubeBaseMN * sizeof(half) * 2 + ADDR_ALIGN_SIZE) / ADDR_ALIGN_SIZE * ADDR_ALIGN_SIZE;
mulWorkSpaceGm.SetGlobalBuffer((__gm__ T1*)workspace + workspaceOffsets / sizeof(T1));
修改代码,workspace地址经过512B对齐后,fixpipe时间减半:

MTE2流水优化
从场景二采集的profiling和打点图来看,mte2_ratio占比高,cube MTE2出现了明显bound,且部分MTE2搬运时间异常。


将输入数据排布格式从BSH更改为BNSD后,数据搬运连续,不需要跳地址读取数据,搬运效率提升一倍,部分异常搬运时长降低了一半。
优化方案性能收益
- 调整tiling基本块:理论评估vector切块越大,计算和搬运循环次数越少,同时能够充分利用搬运带宽和vector算力。基本块大小从(64, 128)增大到(128, 128)后,性能提升一倍,实测与理论分析一致。
- CV流水并行:CV流水掩盖的时间即为提升的性能,符合预期的收益。
- 核间负载均衡:优化前负载最多的核的计算量减少的倍数,即为预期提升的性能;案例中优化前负载最多的核的计算量大小为8块,优化后为4块,实际性能提升一倍,符合预期的收益。
- FixPipe优化:从Profiling数据看出FixPipe占比0.8,优化后占比0.55,实测算子性能提升45%,与理论分析一致。
- MTE2优化:从Profiling数据看出MTE2占比0.52,优化后占比减少一半,实测算子性能提升30%,与理论分析一致。
开发者在对基于Ascend C开发的融合算子进行性能优化时,可参考此案例中的优化思路。
更多学习资源
了解更多Ascend C算子性能优化手段和实践案例,请访问:昇腾Ascend C-入门课程-学习资源-算子文档-昇腾社区