文章目录
- Hadoop简介
- 主要特点
- 核心组件
- 生态系统
- Docker Compose 部署集群
- 参考文章

Hadoop简介
Hadoop是一个开源框架,由Apache软件基金会开发,用于在普通硬件构建的集群中存储和处理大量数据。它最初由Doug Cutting和Mike Cafarella创建,并受Google的MapReduce和Google File System (GFS) 论文的启发。Hadoop已成为大数据处理的事实上的标准,并被许多企业和组织广泛采用。
主要特点
-
可扩展性:Hadoop可以处理从GB到PB级别的数据,通过增加更多的节点来扩展集群。
-
可靠性:通过Hadoop的分布式存储和处理能力,即使在硬件故障的情况下,也能保持数据的完整性和可用性。
-
简单性:Hadoop的设计哲学是“写起来简单,用起来简单”,使得它易于使用和维护。
-
成本效益:它允许使用普通的硬件来构建集群,而不是依赖昂贵的专有系统。
-
支持多种数据类型:Hadoop可以处理结构化、半结构化和非结构化数据。
-
批处理和实时处理:初始版本的Hadoop主要用于批处理,但随着技术的发展,它也支持实时数据流处理。
核心组件
-
HDFS (Hadoop Distributed File System):
- 一个分布式文件系统,设计用于在集群中存储大量数据。
-
MapReduce:
- 一个编程模型和软件框架,用于在Hadoop集群上进行并行处理。
-
YARN (Yet Another Resource Negotiator):
- 一个资源管理器,用于协调计算资源并调度作业。
-
Hadoop Common:
- 包含Hadoop生态系统中所有项目共有的一些实用工具和库。
生态系统
Hadoop不仅仅是一个单一的框架,它还包括了一系列扩展项目,形成了一个庞大的生态系统,包括但不限于:
- Apache Hive:数据仓库软件,用于对存储在HDFS中的大数据进行查询和管理。
- Apache Pig:一种高级平台,用于创建MapReduce程序。
- Apache HBase:一个分布式的列存储系统,可以进行随机实时读/写访问。
- Apache Spark:一个快速的内存数据处理引擎,支持批处理和流处理。
- Apache Storm:一个分布式实时计算系统。
- Apache Kafka:一个分布式流处理平台。
Hadoop适用于需要处理和分析大规模数据集的场合,如日志分析、数据挖掘、机器学习等。随着技术的发展,Hadoop也在不断地演进,以支持更广泛的应用场景和更高效的数据处理方式。
Docker Compose 部署集群
使用Docker部署Hadoop集群可以通过编写docker-compose.yml文件来实现。以下是一个使用Apache Hadoop官方镜像部署Hadoop伪分布式模式的示例:
-
获取官方镜像:
docker pull apache/hadoop:3.3.6 -
创建hadoop目录:
- 创建目录
/opt/hadoop, 下面的docker-compose.yml和config文件均在该目录下创建。sudo mkidr /opt/hadoop
- 创建目录
-
创建
docker-compose.yml文件:
创建一个包含以下内容的docker-compose.yml文件:version: "3" services: namenode: image: apache/hadoop:3.3.6 hostname: namenode command: ["hdfs", "namenode"] ports: - 9870:9870 env_file: - ./config environment: ENSURE_NAMENODE_DIR: "/tmp/hadoop-root/dfs/name" datanode: image: apache/hadoop:3.3.6 command: ["hdfs", "datanode"] env_file: - ./config resourcemanager: image: apache/hadoop:3.3.6 hostname: resourcemanager command: ["yarn", "resourcemanager"] ports: - 8088:8088 env_file: - ./config volumes: - ./test.sh:/opt/test.sh nodemanager: image: apache/hadoop:3.3.6 command: ["yarn", "nodemanager"] env_file: - ./config使用
Docker Compose在多个容器中启动一个Hadoop集群,包括HDFS的NameNode和DataNode,以及YARN的ResourceManager和NodeManager。通过env_file加载的环境变量文件./config包含了Hadoop配置信息。 -
创建配置文件:
创建config文件,包含Hadoop启动需要的配置信息:CORE-SITE.XML_fs.default.name=hdfs://namenode CORE-SITE.XML_fs.defaultFS=hdfs://namenode HDFS-SITE.XML_dfs.namenode.rpc-address=namenode:8020 HDFS-SITE.XML_dfs.replication=1 MAPRED-SITE.XML_mapreduce.framework.name=yarn MAPRED-SITE.XML_yarn.app.mapreduce.am.env=HADOOP_MAPRED_HOME=$HADOOP_HOME MAPRED-SITE.XML_mapreduce.map.env=HADOOP_MAPRED_HOME=$HADOOP_HOME MAPRED-SITE.XML_mapreduce.reduce.env=HADOOP_MAPRED_HOME=$HADOOP_HOME YARN-SITE.XML_yarn.resourcemanager.hostname=resourcemanager YARN-SITE.XML_yarn.nodemanager.pmem-check-enabled=false YARN-SITE.XML_yarn.nodemanager.delete.debug-delay-sec=600 YARN-SITE.XML_yarn.nodemanager.vmem-check-enabled=false YARN-SITE.XML_yarn.nodemanager.aux-services=mapreduce_shuffle CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.maximum-applications=10000 CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.maximum-am-resource-percent=0.1 CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.queues=default CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.capacity=100 CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.user-limit-factor=1 CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.maximum-capacity=100 CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.state=RUNNING CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.acl_submit_applications=* CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.acl_administer_queue=* CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.node-locality-delay=40 CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.queue-mappings= CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.queue-mappings-override.enable=false-
CORE-SITE.XML:
fs.default.name: 指定Hadoop文件系统的默认名称,这里设置为hdfs://namenode,意味着客户端将通过namenode主机上的HDFS服务进行文件操作。fs.defaultFS: 也是设置默认文件系统的URI,这里同样设置为hdfs://namenode,通常两个属性可以任选其一,但这里为了明确指定,两个属性都被设置了。
-
HDFS-SITE.XML:
dfs.namenode.rpc-address: 设置NameNode的RPC通信地址和端口,这里设置为namenode:8020。dfs.replication: 设置HDFS的副本因子,这里设置为1,意味着每个文件将只有一个副本。
-
MAPRED-SITE.XML:
mapreduce.framework.name: 设置MapReduce的计算框架为YARN。mapreduce.am.env,mapreduce.map.env,mapreduce.reduce.env: 设置MapReduce应用程序的执行环境变量,这里将HADOOP_MAPRED_HOME设置为$HADOOP_HOME,后者通常是Hadoop安装的根目录。
-
YARN-SITE.XML:
yarn.resourcemanager.hostname: 设置ResourceManager的主机名,这里设置为resourcemanager。yarn.nodemanager.pmem-check-enabled: 设置是否开启物理内存检查,这里设置为false,即不开启。yarn.nodemanager.delete.debug-delay-sec: 设置NodeManager删除工作目录的延迟时间,这里设置为600秒。yarn.nodemanager.vmem-check-enabled: 设置是否开启虚拟内存检查,这里设置为false,即不开启。yarn.nodemanager.aux-services: 设置NodeManager的辅助服务,这里设置为mapreduce_shuffle,即MapReduce的混洗服务。yarn.scheduler.capacity.maximum-applications: 设置容量调度器可以处理的最大应用程序数量。yarn.scheduler.capacity.maximum-am-resource-percent: 设置应用程序Master的最大资源使用百分比。yarn.scheduler.capacity.resource-calculator: 设置资源计算器的类。yarn.scheduler.capacity.root.queues: 设置根队列的名称。yarn.scheduler.capacity.root.default.capacity: 设置默认队列的容量比例。yarn.scheduler.capacity.root.default.user-limit-factor: 设置用户限制因子。yarn.scheduler.capacity.root.default.maximum-capacity: 设置默认队列的最大容量。yarn.scheduler.capacity.root.default.state: 设置默认队列的状态。yarn.scheduler.capacity.root.default.acl_submit_applications: 设置允许提交应用程序的访问控制列表。yarn.scheduler.capacity.root.default.acl_administer_queue: 设置允许管理队列的访问控制列表。yarn.scheduler.capacity.node-locality-delay: 设置节点本地延迟。yarn.scheduler.capacity.queue-mappings: 设置队列映射。yarn.scheduler.capacity.queue-mappings-override.enable: 设置是否启用队列映射覆盖。
这些配置项通常在Hadoop集群启动前设置,以确保Hadoop服务按照预期的方式运行。
-
-
启动Hadoop服务:
在包含docker-compose.yml的目录下,运行以下命令来启动服务:docker-compose up -d -
验证服务状态:
使用以下命令检查服务是否正常启动:docker-compose ps -
测试服务:
# 进入容器 docker exec -it hadoop_namenode_1 /bin/bash # 运行Mapreduce任务 yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 10 15 -
访问Hadoop Web界面:
- NameNode UI: `http://:9870/
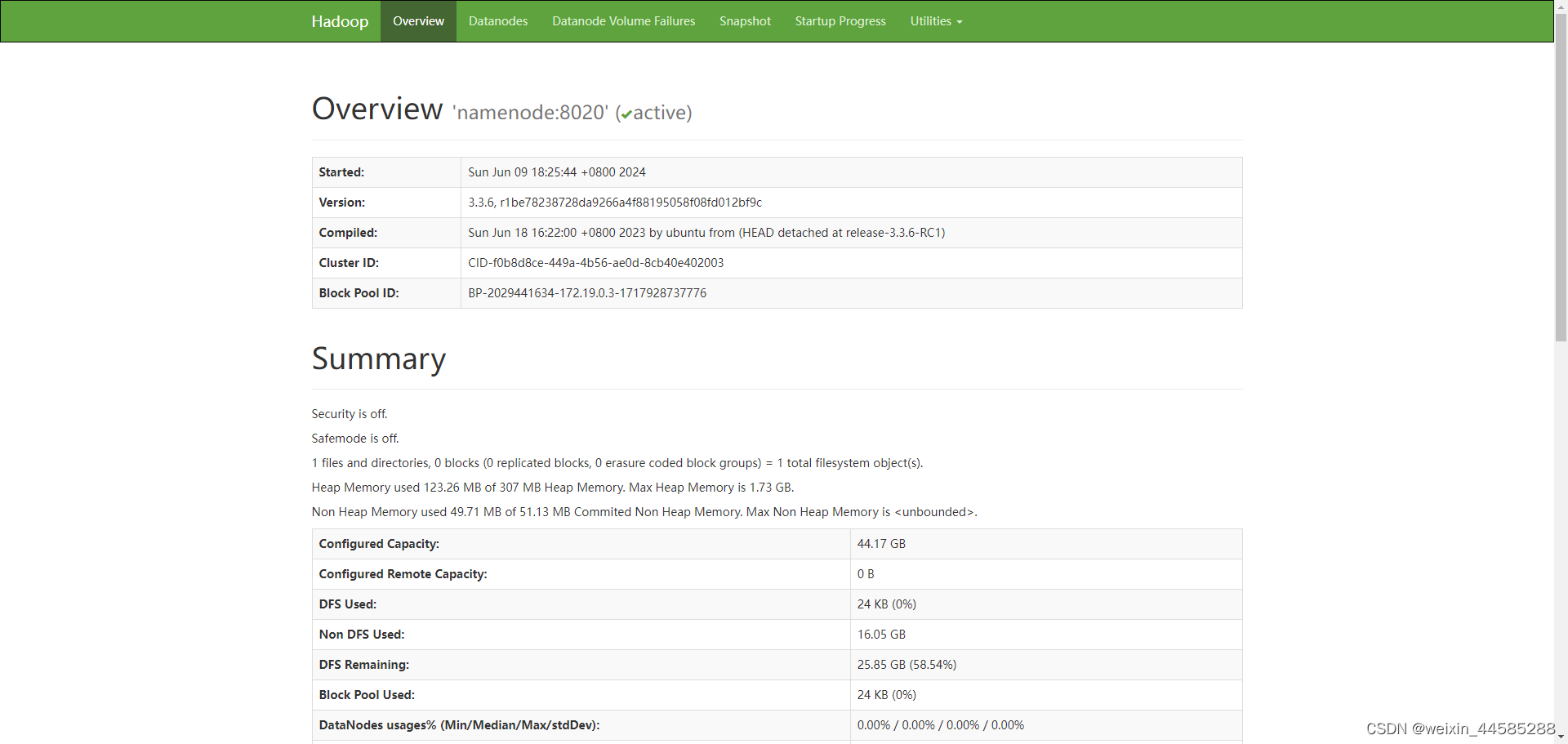
- ResourceManager UI:
http://<your-ip>:8088/

- NameNode UI: `http://:9870/
-
停止和删除服务:
当您完成测试后,可以停止并删除所有服务:
docker-compose down
参考文章
Docker Hub Apache Hadoop
docker部署hadoop