前言
在上一篇课程《【课程总结】Day7:深度学习概述》中,我们了解到:
- 模型训练过程→本质上是固定w和b参数的过程;
- 让模型更好→本质上就是让模型的损失值loss变小;
- 让loss变小→本质上就是求loss函数的最小值;
本篇文章,我们将继续深入了解深度学习的项目流程,包括:批量化打包数据、模型定义、损失函数、优化器以及训练模型等内容。
求函数最小值回顾
以 y = 2 x 2 y=2x^2 y=2x2,我们回顾使用pytorch框架求函数最小值,其过程大致如下:
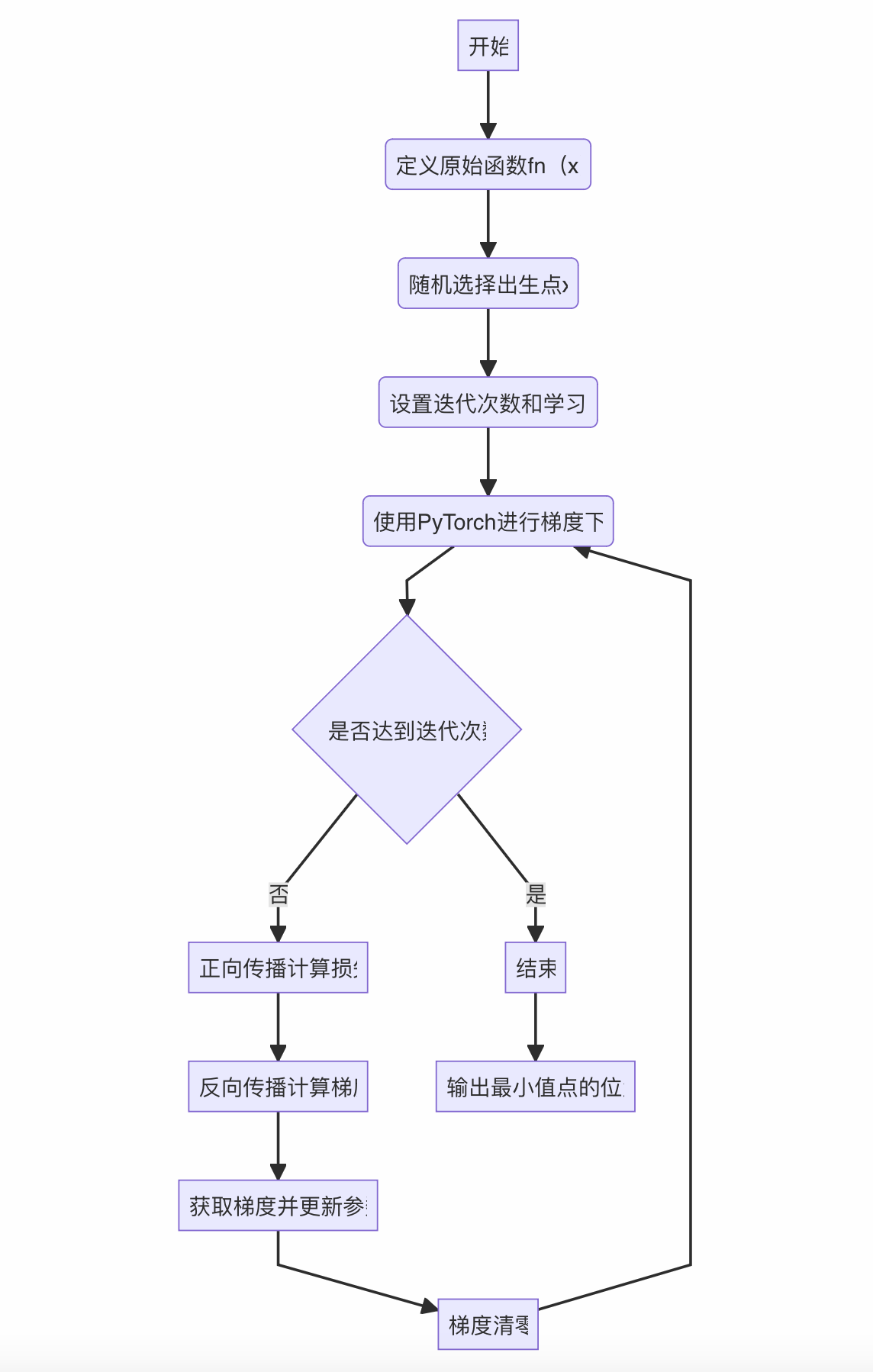
备注:代码不再重复赘述,回顾代码请见使用pytorch求函数最小值
深度学习基本流程
由于训练的本质:求loss函数的最小值;所以,我们类比求 y = 2 x 2 y=2x^2 y=2x2最小值的过程,来看一下线性回归训练(也就是求loss最小值)的过程,其流程如下:

相比于求 y = 2 x 2 y=2x^2 y=2x2最小值的过程,我们有如下调整:
- 替换:随机选择出生点→准备训练数据(本例中训练数据先模拟生成)
- 替换:定义原始函数→定义模型
- 增加:初始化优化器(训练时要定义损失函数,我们常用MSE)
- 替换:输出最小值位置→输出训练后的模型权重和偏置
具体代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
# 生成模拟数据
torch.manual_seed(42)
x_train = torch.randn(100, 13) # 100个样本,每个样本有13个特征
y_train = torch.randn(100, 1) # 每个样本对应一个输出值
# 定义模型
model = nn.Linear(13, 1) # 输入特征数为13,输出特征数为1
# 初始化优化器
criterion = nn.MSELoss() # 均方误差损失
optimizer = optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降优化器
# 迭代次数和学习率
epochs = 1000
learning_rate = 1e-2
# 使用 PyTorch 进行梯度下降
for _ in range(epochs):
optimizer.zero_grad() # 梯度清零
outputs = model(x_train) # 正向传播
loss = criterion(outputs, y_train) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 输出最终模型参数
print("线性回归模型的权重:", model.weight)
print("线性回归模型的偏置:", model.bias)
运行结果:

至此,我们完成了线性回归模型的训练。接下来,我们参照上面代码,再深入理解一下相关的基础理论。
模型 model
-
前向传播的定义:把特征 X 带入模型 model ,得到预测结果 y_pred
-
训练时:自动在底层构建计算图(把正向传播的流程记录下来,方便进行后续的分布求导/链式求导。
例如:在导数中,对于一个复合函数h( g( f(x))),我们需要进行链式求导,即h( g( f(x))) = f’ * g’ * h’
-
推理时:直接调用正向传播即可,不需要构建计算图
-
-
反向传播的定义:本质是计算每个参数的梯度,是通过损失函数发起的
-
模型的作用:只负责前向传播 forward,不负责后向传播 backward
训练流程
- 从训练集中,取一批
batch样本(x, y) - 把样本特征
X送入模型model,得到预测结果y_pred - 计算损失函数
loss = f(y_pred, y),计算当前的误差loss - 通过
loss, 反向传播,计算每个参数(w, b)的梯度 - 利用优化器
optimizer,通过梯度下降法,更新参数 - 利用优化器
optimizer清空参数的梯度 - 重复
1-6直至迭代结束(各项指标满足要求或是误差很小)
预测流程
- 拿到待测样本
X(推理时,没有标签,只有特征) - 把样本特征
X送入模型model,得到预测结果y_pred - 根据
y_pred解析并返回预测结果即可
深度学习项目流程
通过上述内容梳理,我们已经了解深度学习的一个基本流程,包括:定义模型、训练、预测。
但是在实际工程使用中,由于训练数据比较庞大,所以我们还需要一些额外的步骤,例如:增加批量化打包流程。
为了更好地理解深度学习的整体流程,我们仍然使用机器学习中使用的《波士顿房价预测》案例,来看一下深度学习下应该如何实现。
批量化打包数据
背景
在实际的工程中,由于深度学习是要进行大数据量的训练,所以我们需要基于以下原因进行批量化打包数据。
- 提高训练效率:通过批量化处理数据,可以充分利用GPU的并行计算能力,加快模型训练速度。
- 稳定模型训练:批量化处理可以降低训练过程中的方差,使模型更加稳定。
- 减少内存消耗:批量化处理可以减少在每个迭代中需要存储的数据量,节省内存消耗。
原理
-
使用生成器来打包数据
生成器记录了一个规则,每次调用生成器就会返回一个批次数据。
实现
- 先自定义
dataset - 再定义
dataloader
from torch.utils.data import DataLoader, TensorDataset
# 批量化打包数据示例代码
# 创建数据集和数据加载器
dataset = TensorDataset(x_tensor, y_tensor)
data_loader = DataLoader(dataset, batch_size=16, shuffle=True)
构建模型
定义
在深度学习中构建模型是指设计神经网络结构,确定网络的层数、每层的神经元数量、激活函数等参数,以实现特定的学习任务。
常见方式
- Sequential模型:Sequential模型是一种简单的线性堆叠模型,层按顺序依次堆叠在一起,适用于顺序处理的神经网络结构。
- Class子类化模型:通过继承框架提供的模型基类,用户可以自定义模型的结构和计算逻辑,实现更加灵活和定制化的模型构建。
除上述方式之外,还有迁移学习、模型组合、模型集成、自动机器学习(AutoML)、**超网络(Hypernetwork)**等方式,由于不是本章内容重点,暂不展开。
筹备训练
定义损失函数
- 目的:损失函数用于衡量模型预测结果与真实标签之间的差异,是优化算法的目标函数,帮助模型学习正确的参数。
常见损失函数
- 均方误差损失(Mean Squared Error, MSE)
- 交叉熵损失(Cross Entropy Loss)
定义优化器
- 目的:优化器用于更新模型参数,通过最小化损失函数来提高模型性能,调整模型参数使得损失函数达到最小值。
常见优化算法
- 随机梯度下降(SGD)
- Adam
- Adagrad等
定义训练次数(Epochs)
-
定义:训练次数指的是将整个训练数据集在模型上反复训练的次数,每次完整地遍历整个数据集称为一个训练周期(Epoch)。
-
作用:通过增加训练次数,模型可以更好地学习数据集中的模式和特征,提高模型的泛化能力,减少过拟合的风险。
定义学习率(Learning Rate)
- 定义:学习率是优化算法中的一个重要超参数,控制模型参数在每次迭代中更新的步长大小,即参数沿着梯度方向更新的幅度。
- 目的:学习率的选择影响模型训练的速度和性能,合适的学习率能够使模型更快地收敛到最优解,而过大或过小的学习率可能导致训练不稳定或陷入局部最优解。
训练模型
-
训练过程中需要监控模型指标,如:准确率、损失值等
-
训练过程中需要保存模型参数,方便后续推理
-
避免过拟合
推理模型
训练好模型之后,直接使用模型进行推理即可。
回归问题:深度学习实现房价预测案例
1. 数据预处理
1.1 数据读取
file_name = './housing.data'
# 原始数据读取
X = []
y = []
with open(file=file_name, mode='r', encoding='utf8') as f:
# f.readline()
for line in f:
line = line.strip()
if line:
sample = [float(ele) for ele in line.split(" ") if ele]
X.append(sample[:-1])
y.append(sample[-1])
1.2 数据切分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=0)
1.3 数据预处理(规范化)
# 规范化
import numpy as np
# 转numpy数组
X_train = np.array(X_train)
X_test = np.array(X_test)
# 提取参数
_mean = X_train.mean(axis=0)
_std = X_train.std(axis=0) + 1e-9 # 为了避免除零,此处加上一个非常小的数
# 执行规范化处理
X_train = (X_train - _mean) / _std
X_test = (X_test - _mean) / _std
2. 批量化打包数据
通过定义一个继承Dataset的数据集类,方便数据的常见操作,如:len()、index()等。
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
# 1. 继承Dataset 自定义一个数据集类
class HouseDataset(Dataset):
"""
自定义一个房价数据集
"""
def __init__(self, X, y):
"""
接受参数,定义静态属性
"""
self.X = X
self.y = y
def __len__(self):
"""
返回数据集样本的个数
"""
return len(self.X)
def __getitem__(self, idx):
"""
通过索引,读取第idx个样本
"""
x = self.X[idx]
y = self.y[idx]
# 转张量
x = torch.tensor(data=x, dtype=torch.float32)
y = torch.tensor(data=[y], dtype=torch.float32)
return x, y
此处__len__和__getitem__方法是Python的魔法方法,他们是回调(callback)函数,不需要用户自己调用而由系统调用。即:
- 告诉系统我定义的数据集在
取长度和按index取元素调用哪个方法;- 当系统触发这两种情况(
取长度和按index取元素)时,会自动调用类里的__len__和__getitem__方法。
# 训练集加载器
house_train_dataset = HouseDataset(X=X_train, y=y_train)
house_train_dataloader = DataLoader(dataset=house_train_dataset,
batch_size=12,
shuffle=True)
# 测试集加载器
house_test_dataset = HouseDataset(X=X_test, y=y_test)
house_test_dataloader = DataLoader(dataset=house_test_dataset,
batch_size=32,
shuffle=True)
通过下面的测试代码,可以查看上述训练集和测试集的数据形状
# 测试代码
for X, y in house_train_dataset:
print(X)
print(X.shape)
print(y)
print(y.shape)
break
运行结果:

3. 模型搭建
模型的构建方法有以下三种写法,一般情况下,我们使用第三种class的方法,这种方法可以自定义模型的结构和计算逻辑,实现更加灵活和定制化的模型。
from torch import nn
# # 搭建方法1:
# model = nn.Linear(in_features=13, out_features=1)
# # 搭建方法2:
# model = nn.Sequential(
# nn.Linear(in_features=13, out_features=1)
# )
# 搭建方法3:
class Model(nn.Module):
"""
自定义一个类
- 必须继承 nn.Module
"""
def __init__(self, n_features=13):
"""
接收超参
定义处理的层
"""
# 先初始化父类
super(Model, self).__init__()
# 定义一个线性层(做一次矩阵变换)
self.linear = nn.Linear(in_features=n_features, out_features=1)
def forward(self, x):
"""
模型前向传播逻辑
"""
x = self.linear(x)
return x
实例化模型
model = Model(n_features=13)
通过一下测试代码,可以看到模型的运行结果:
# 测试代码
for X, y in house_train_dataloader:
y_pred = model(X)
print(y_pred)
print(y)
break
运行结果:

4. 筹备训练
这一步骤,我们将定义模型(实例化上述自定义模型)、定义损失函数、定义优化器、定义训练次数和定义学习率。
# 定义模型
model = Model(n_features=13)
# 定义训练的轮次
epochs = 100
# 定义学习率
learing_rate = 1e-3
# 定义损失函数
loss_fn = nn.MSELoss()
# 定义优化器
optimizer = torch.optim.SGD(params=model.parameters(),
lr=learing_rate)
5. 训练模型
5.1 定义监控指标和方法
在训练的过程中,我们需要对训练过程的重要指标加以监控,以避免训练有问题。
# 定义查看损失函数的方法,用于监控训练过程
def get_loss(dataloader):
# 模型设置为评估模式
# (BatchNorm LayNorm Dropout层,在train模式和eval模式下,行为是不一样)
model.eval()
# 收集每个批量的损失
losses = []
# 构建一个无梯度的环境(底层不会默认自动创建计算图,节约资源)
with torch.no_grad():
for X, y in dataloader:
y_pred = model(X)
loss = loss_fn(y_pred, y)
losses.append(loss.item())
# 计算每个批量损失的平均值
final_loss = sum(losses) / len(losses)
# 保留小数点后5位
final_loss = round(final_loss, ndigits=5)
return final_loss
5.2 实现训练过程
def train():
# 记录训练过程
train_losses = []
test_losses = []
# 每一轮次
for epoch in range(epochs):
#模型设为训练模式
model.train()
# 每一批量
for X, y in house_train_dataloader:
# 1. 正向传播
y_pred = model(X)
# 2. 损失计算
loss = loss_fn(y_pred, y)
# 3. 反向传播
loss.backward()
# 4. 优化一步
optimizer.step()
# 5. 清空梯度
optimizer.zero_grad()
# 计算模型当前的损失情况
train_loss = get_loss(dataloader=house_train_dataloader)
test_loss = get_loss(dataloader=house_test_dataloader)
train_losses.append(train_loss)
test_losses.append(test_loss)
print(f"当前是第{epoch+1}轮,训练集损失为:{train_loss}, 测试集损失为:{test_loss}")
return train_losses, test_losses
5.3 开始训练
至此,我们已经完成整体训练前的重要步骤实现,接下来就可以:训练,启动!
train_losses, test_losses = train()
运行结果:

5.4 图形化监控数据
为了方便查看训练过程变化情况,可以使用matplotlib绘制损失函数的变化曲线。
from matplotlib import pyplot as plt
plt.plot(train_losses, c="blue", label="train_loss")
plt.plot(test_losses, c="red", label="test_loss")
plt.title("The Losses")
plt.xlabel(xlabel="epoches")
plt.ylabel(ylabel="loss")
plt.legend()
运行结果:

由上图可以看到
- 在一开始的训练中,损失值快速下降;当训练次数到40次左右后,损失值已经下降不明显。
我们可以通过加入激活函数,引入非线性因素来优化模型。
5.5 激活函数
-
定义:激活函数是神经网络中的一种非线性函数,通常应用在神经元的输出上,将输入信号转换为输出信号。激活函数引入了非线性因素,使神经网络可以学习和表达复杂的非线性关系。
举个例子:
-
想象一下,神经网络就像是一个复杂的拼图游戏,每个神经元就像是拼图中的一个小块。当我们只使用线性函数(比如直线)作为激活函数时,就好比每个小块都是直线,无法拼出复杂的图案,只能表达简单的线性关系。
-
但是,当我们引入非线性的激活函数时,就好比在每个小块上加入了各种形状和曲线,使得每个小块可以表达更加复杂的形状和关系。这样,当我们把许多这样的小块(神经元)组合在一起时,就可以拼出更加复杂和多样的图案(非线性关系),从而让神经网络能够学习和表达更加复杂的模式和特征。
-
因此,激活函数的作用就是为神经网络引入了这种非线性因素,使得神经网络可以更好地学习和表达复杂的非线性关系,就像在拼图游戏中加入了各种形状和曲线,让我们能够拼出更加丰富多彩的图案一样。
-
常见激活函数有:Sigmoid函数、Tanh函数、ReLU函数、Softmax函数,相关内容在补充知识段落展开。
使用方法
在自定义模型类的forward函数中,增加
class Model(nn.Module):
"""
自定义一个类
- 必须继承 nn.Module
"""
def __init__(self, n_features=13):
"""
接收超参
定义处理的层
"""
# 先初始化父类
super(Model, self).__init__()
# 定义一个线性层(做一次矩阵变换)
self.linear = nn.Linear(in_features=n_features, out_features=1)
def forward(self, x):
"""
模型前向传播逻辑
"""
x = self.linear(x)
x = nn.ReLU()(x) # 添加ReLU激活函数
return x
运行结果:


对比加入激活函数前后的图形,其训练集的损失仍然在19左右,只是下降过程不如之前那么快了。
5.6 多层感知机
定义
由于无法模拟诸如异或以及其他复杂函数的功能,使得单层感知机的应用较为单一。一个简单的想法是,如果能在感知机模型中增加若干隐藏层,增强神经网络的非线性表达能力,就会让神经网络具有更强拟合能力。

大脑是一个多层感知机,每一层都在学习不同级别的特征。
- 输入层:输入层就像你的眼睛,它接收到动物的各种特征信息,比如颜色、大小等。
- 隐藏层:隐藏层就像你的大脑皮层,它处理输入的特征信息,并尝试从中提取出更加抽象和复杂的特征,比如动物的轮廓、纹理等。
- 输出层:输出层就像你的嘴巴,它根据隐藏层提取的特征信息做出判断,比如判断输入的动物是狗还是猫。
通过多次学习和训练,你的大脑(多层感知机)会逐渐调整隐藏层中的神经元(神经元就像大脑中的神经元)的连接权重,从而更好地识别不同类型的动物。
实现方法:
修改自定义模型的初始化方法,加入一个新的线性层
class Model(nn.Module):
"""
自定义一个类
- 必须继承 nn.Module
"""
def __init__(self, n_features=13):
"""
接收超参
定义处理的层
"""
# 先初始化父类
super(Model, self).__init__()
# 定义两个线性层
self.linear1 = nn.Linear(in_features=n_features, out_features=8)
self.linear2 = nn.Linear(in_features=8, out_features=1)
def forward(self, x):
"""
模型前向传播逻辑
"""
x = self.linear1(x)
x = torch.relu(x) # 添加ReLU激活函数
x = self.linear2(x)
return x
重新执行训练过程并绘制损失值图形:


由上图可以看到,多层感知机+引入激活函数,损失值已经降到8左右;对比之前未优化的模型,模型的损失值变小,预测准确性得到提升。
深度学习 vs 机器学习
至此,我们借助房价预测的示例,已经完整地实现了深度学习的整体流程;接下来,我们对比一下深度学习和机器学习,在同一问题:房价预测问题上的结果。
from sklearn.tree import DecisionTreeRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
file_name = './housing.data'
# 原始数据读取
X = []
y = []
with open(file=file_name, mode='r', encoding='utf8') as f:
# f.readline()
for line in f:
line = line.strip()
if line:
sample = [float(ele) for ele in line.split(" ") if ele]
X.append(sample[:-1])
y.append(sample[-1])
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=0)
# 规范化
import numpy as np
# 转numpy数组
X_train = np.array(X_train)
X_test = np.array(X_test)
# 提取参数
_mean = X_train.mean(axis=0)
_std = X_train.std(axis=0) + 1e-9
# 执行规范化处理
X_train = (X_train - _mean) / _std
X_test = (X_test - _mean) / _std
# 决策树
dt_model = DecisionTreeRegressor()
dt_model.fit(X_train, y_train)
dt_pred = dt_model.predict(X_test)
dt_loss = mean_squared_error(y_test, dt_pred)
# KNN
knn_model = KNeighborsRegressor()
knn_model.fit(X_train, y_train)
knn_pred = knn_model.predict(X_test)
knn_loss = mean_squared_error(y_test, knn_pred)
# 支持向量机
svm_model = SVR()
svm_model.fit(X_train, y_train)
svm_pred = svm_model.predict(X_test)
svm_loss = mean_squared_error(y_test, svm_pred)
# 随机森林
rf_model = RandomForestRegressor()
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
rf_loss = mean_squared_error(y_test, rf_pred)
models = ['Decision Tree', 'KNN', 'SVM', 'Random Forest']
loss_values = [dt_loss, knn_loss, svm_loss, rf_loss]
plt.figure(figsize=(10, 6))
bars = plt.bar(models, loss_values, color='skyblue')
plt.xlabel('Models')
plt.ylabel('Mean Squared Error')
plt.title('Comparison of Mean Squared Error for Different Models')
# 添加数据标签
for bar, loss in zip(bars, loss_values):
plt.text(bar.get_x() + bar.get_width() / 2 - 0.1, bar.get_height() + 0.001, f'{loss:.4f}', ha='center', color='black', fontsize=10)
plt.show()
运行结果:

通过对比机器学习和深度学习的平均平方偏差(MSE),深度学习是明显优于机器学习的。
分类问题:深度学习实现鸢尾花分类案例
上述案例中,我们以房价预测为例,使用深度学习实现了线性回归的训练和预测。接下来,我们将以《鸢尾花分类》为例,学习了解深度学习如何实现分类问题。
流程回顾与对比
深度学习实现分类问题与深度学习实现回归问题流程基本一致,对比不同点如下:
| 流程步骤 | 回归问题 | 分类问题 | 说明 |
|---|---|---|---|
| 1.数据预处理 | \ | \ | |
| 1.1 数据读取 | ✔ | ✔ | 读取数据源不同 |
| 1.2数据切分 | ✔ | ✔ | 相同 |
| 1.3数据预处理 | ✔ | ✔ | 相同 |
| 2. 批量化数据打包 | ✔ | ⭕️ | 标签数据类型不同: 1.回归问题标签数据类型为torch.float32 2.分类问题需要将标签y定义类型改为torch.long |
| 3. 模型搭建 | ✔ | ⭕️ | 超参定义不同: 1.回归问题预测结果是1个,out_features=1 2.分类问题预测结果有N类,out_features=N |
| 4. 筹备训练 | ✔ | ⭕️ | 损失不同: 1.回归问题使用的是MSE 2.分类问题使用的是交叉熵 |
| 5.训练模型 | \ | \ | |
| 5.1定义监控指标和方法 | ✔ | ⭕️ | 监控指标不同: 1.回归问题监控MSE 2.分类问题监控准确率 |
| 5.2实现训练过程 | ✔ | ✔ | 相同 |
| 5.3开始训练 | ✔ | ✔ | 相同 |
| 5.4图形化监控数据 | ✔ | ✔ | 相同 |
| 5.5激活函数 | ✔ | ✔ | 相同 |
代码实现
import numpy as np
import torch
from torch import nn
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from matplotlib import pyplot as plt
# 1. 继承Dataset 自定义一个数据集类
class IrisDataset(Dataset):
"""
自定义一个鸢尾花数据集
"""
def __init__(self, X, y):
"""
接受参数,定义静态属性
"""
self.X = X
self.y = y
def __len__(self):
"""
返回数据集样本的个数
"""
return len(self.X)
def __getitem__(self, idx):
"""
通过索引,读取第idx个样本
"""
x = self.X[idx]
y = self.y[idx]
# 转张量
x = torch.tensor(data=x, dtype=torch.float32)
# 索引号,long类型
y = torch.tensor(data=y, dtype=torch.long)
return x, y
# 搭建方法3:
class Model(nn.Module):
"""
自定义一个类
- 必须继承 nn.Module
"""
def __init__(self, n_features=4, n_classes=3):
"""
接收超参
定义处理的层
"""
# 先初始化父类
super(Model, self).__init__()
# 定义一个线性层(做一次矩阵变换)
self.linear = nn.Linear(in_features=n_features, out_features=n_classes)
def forward(self, x):
"""
模型前向传播逻辑
"""
x = self.linear(x)
return x
def get_acc(dataloader):
# 模型设置为评估模式
# (BatchNorm LayNorm Dropout层,在train模式和eval模式下,行为是不一样)
model.eval()
# 收集每个批量的损失
accs = []
# 构建一个无梯度的环境(底层不会默认自动创建计算图,节约资源)
with torch.no_grad():
for X, y in dataloader:
y_pred = model(X)
y_pred = y_pred.argmax(dim=-1)
acc = (y_pred == y).to(dtype=torch.float32).mean().item()
accs.append(acc)
# 计算每个批量损失的平均值
final_acc = sum(accs) / len(accs)
# 保留小数点后5位
final_acc = round(final_acc, ndigits=5)
return final_acc
def train():
# 记录训练过程
train_accs = []
test_accs = []
# 每一轮次
for epoch in range(epochs):
#模型设为训练模式
model.train()
# 每一批量
for X, y in iris_train_dataloader:
# 1. 正向传播
y_pred = model(X)
# 2. 损失计算
loss = loss_fn(y_pred, y)
# 3. 反向传播
loss.backward()
# 4. 优化一步
optimizer.step()
# 5. 清空梯度
optimizer.zero_grad()
# 计算模型当前的损失情况
train_acc= get_acc(dataloader=iris_train_dataloader)
test_acc = get_acc(dataloader=iris_test_dataloader)
train_accs.append(train_acc)
test_accs.append(test_acc)
print(f"当前是第{epoch+1}轮,训练集准确率为:{train_acc}, 测试集准确率为:{test_acc}")
return train_accs, test_accs
X,y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=0)
# 转numpy数组
X_train = np.array(X_train)
X_test = np.array(X_test)
# 提取参数
_mean = X_train.mean(axis=0)
_std = X_train.std(axis=0) + 1e-9
# 执行规范化处理
X_train = (X_train - _mean) / _std
X_test = (X_test - _mean) / _std
# 训练集加载器
iris_train_dataset = IrisDataset(X=X_train, y=y_train)
iris_train_dataloader = DataLoader(dataset=iris_train_dataset,
batch_size=4,
shuffle=True)
# 测试集加载器
iris_test_dataset = IrisDataset(X=X_test, y=y_test)
iris_test_dataloader = DataLoader(dataset=iris_test_dataset,
batch_size=8,
shuffle=True)
# 定义模型
model = Model(n_features=4)
# 定义训练的轮次
epochs = 50
# 定义学习率
learing_rate = 1e-3
# 定义损失函数:分类问题使用交叉熵
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
optimizer = torch.optim.SGD(params=model.parameters(),
lr=learing_rate)
train_accs, test_accs = train()
plt.plot(train_accs, c="blue", label="train_acc")
plt.plot(test_accs, c="red", label="test_acc")
plt.title("The Accs")
plt.xlabel(xlabel="epoches")
plt.ylabel(ylabel="acc")
plt.legend()
运行结果:

补充知识
概率模拟
由于分类问题,模型是不会直接输出预测类别,而是输出每个类别的数字(或者叫权重),此时我们需要通过模拟概率将每个类别的数字转换为[0, 1]之间的概率。
常见方法
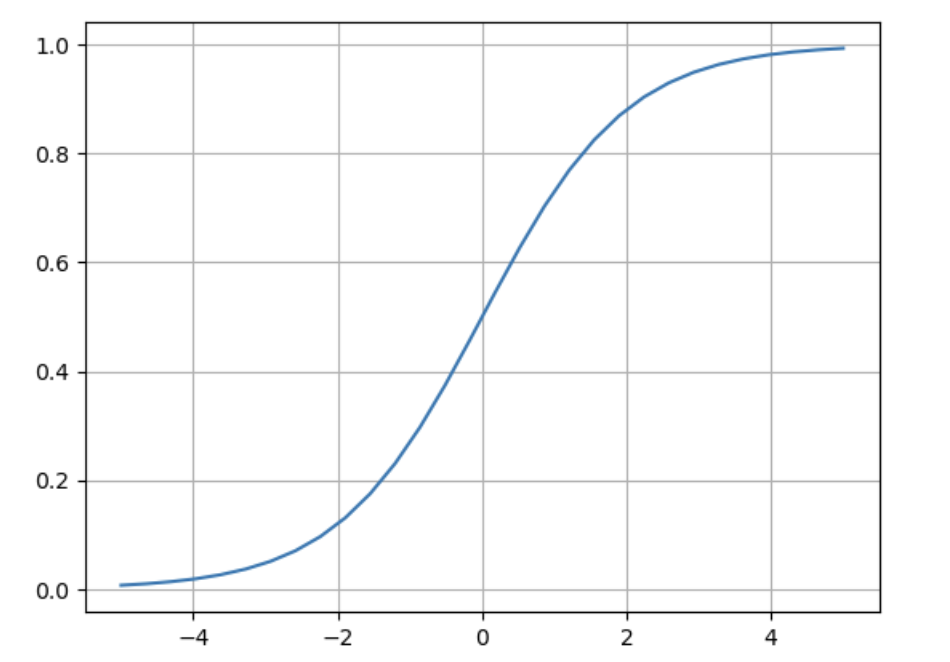
- 二分类概率模拟:Sigmoid函数: σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1,取值范围在(0, 1)。
def sigmod(x):
"""
sigmoid
- (0, 1)
- 单调递增函数
- x为0时,模拟概率为0.5
- x < 0时,模拟概率<0.5
- x > 0时,模拟概率>0.5
"""
return 1 / (1 + np.exp(-x))
x = np.linspace(start=-5, stop=5, num=30)
plt.plot(x, sigmod(x))
plt.grid()
- 多分类概率模拟:Softmax函数:
import numpy as np
def softmax(logits):
"""
softmax:
- 原来比较大的数,模拟概率也比较大
"""
# 转化为np数组
logits = np.array(logits)
# 转化为正数
logits = np.exp(logits)
# 模拟概率
return logits /logits.sum()
# 模型输出的都是原始数据
logits = [0.6 , -3.6, 18.9 ]
logtis = np.array(logits)
softmax(logits)
运行结果:

one-hot编码
在《【课程总结】Day6(上):机器学习项目实战–外卖点评情感分析预测》中,我们曾接触过one-hot编码。本次我们再做下回顾:
-
这是一种状态编码,适合于离散量内涵
-
特征编码时:
以汽车的行驶状态举例:
- 三个状态:左转0,右转1,直行2
- 左转:[1, 0, 0]
- 右转:[0, 1, 0]
- 直行:[0, 0, 1]
-
标签编码时:
以鸢尾花类别举例:
- 三种花:第一种0,第二种1,第三种2
- 第一种:[1, 0, 0]
- 第二种:[0, 1, 0]
- 第三种:[0, 0, 1]
-
特点:
- 互相垂直的向量,没有鲜艳的远近关系
- 都是比较长的向量,跟类别数量一致
- 每个向量只有1位是1,其余都是0(这种状态被称为高度稀疏sparse)
- 从计算和存储上来说,都比较浪费性能
神经网络在预测多类别分类任务时:n_classes个类别的预测问题,模型会输出n_classes个概率。
以鸢尾花为例,神经网络不会直接输出预测的结果是哪个花的类别,而是给出三种花各自的概率,只不过最高概率的哪种花可能就是我们需要的预测结果类别。
交叉熵
作用:从分布的角度来衡量两个概率的远近程度
计算过程:
# 以鸢尾花分类举例:
# 假设我们有一个真实结果y_true,结果是第2类,索引号是1
# 真实结果:y_true: 第2类,索引号为1
# 预测结果1:y_pred1: [12.5, -0.5, 2.7]
# 预测结果2:y_pred2: [-12.5, 6.4, 2.7]
# 第一步:使用one-hot对类别进行编码
y_true = np.array( [0, 1, 0])
# 第二步:进行第一次预测
# 1、对预测结果使用softmax进行概率模拟
y_pred1 = np.array([12.5, -0.5, 2.7])
y_pred1 = softmax(y_pred1)
# 执行结果:
# y_pred1
# array([9.99942291e-01, 2.26019897e-06, 5.54483994e-05])
# 2、计算交叉熵损失 y_true @ y_pred1
loss1 = -(0 * np.log(9.99942291e-01) + 1 * np.log(2.26019897e-06) + 0 * np.log(5.54483994e-05))
# 执行结果
# loss1
# 13.00005770873235
# 第三步:进行第二次预测
y_pred2 = np.array( [-12.5, 6.4, 2.7])
y_pred2 = softmax(y_pred2)
# 执行结果:
# y_pred2
# array([6.04265198e-09, 9.75872973e-01, 2.41270213e-02])
loss1 = -(np.log(9.75872973e-01))
# 执行结果:
# loss1
# 0.024422851654124902
通过上面计算可以看到:
- loss1交叉损失熵最低时,也就是预测结果[-12.5, 6.4, 2.7]与真实结果(第2类)相匹配,由此得到交叉熵越低,预测结果与真实值差异越小。
- 交叉熵相比MSE,交叉熵计算代码要小。
- 在计算交叉熵时,计算方法是进行第i个类别one-hot编码与第i个类别概率相乘,最后再相加;
- 表面上看求了多个熵,实际上只求1个熵(因为one-hot编码为0的位置实际没有参与计算);
激活函数
-
Sigmoid 函数
-
公式: s i g m o i d ( x ) = 1 1 + e − x {sigmoid}(x) = \frac{1}{1 + e^{-x}} sigmoid(x)=1+e−x1
-
特点:将输入值压缩到 0 到 1 之间,常用于输出层的二分类问题,但容易出现梯度消失问题.
-
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-5, 5, 100)
sigmoid = 1 / (1 + np.exp(-x))
plt.plot(x, sigmoid, label='Sigmoid Function')
plt.xlabel('x')
plt.ylabel('sigmoid(x)')
plt.legend()
plt.show()

-
Tanh 函数
-
公式: t a n h ( x ) = e x − e − x e x + e − x {tanh}(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}} tanh(x)=ex+e−xex−e−x
-
特点:将输入值压缩到 -1 到 1 之间,解决了 Sigmoid 函数的零中心问题,但仍存在梯度消失问题。
-
import numpy as np
import matplotlib.pyplot as plt
# 生成 x 值
x = np.linspace(-5, 5, 100)
# 计算双曲正切函数的 y 值
y = np.tanh(x)
# 绘制双曲正切函数图像
plt.figure(figsize=(8, 6))
plt.plot(x, y, label='tanh(x)')
plt.xlabel('x')
plt.ylabel('tanh(x)')
plt.title('Plot of Hyperbolic Tangent Function')
plt.grid(True)
plt.legend()
plt.show()

-
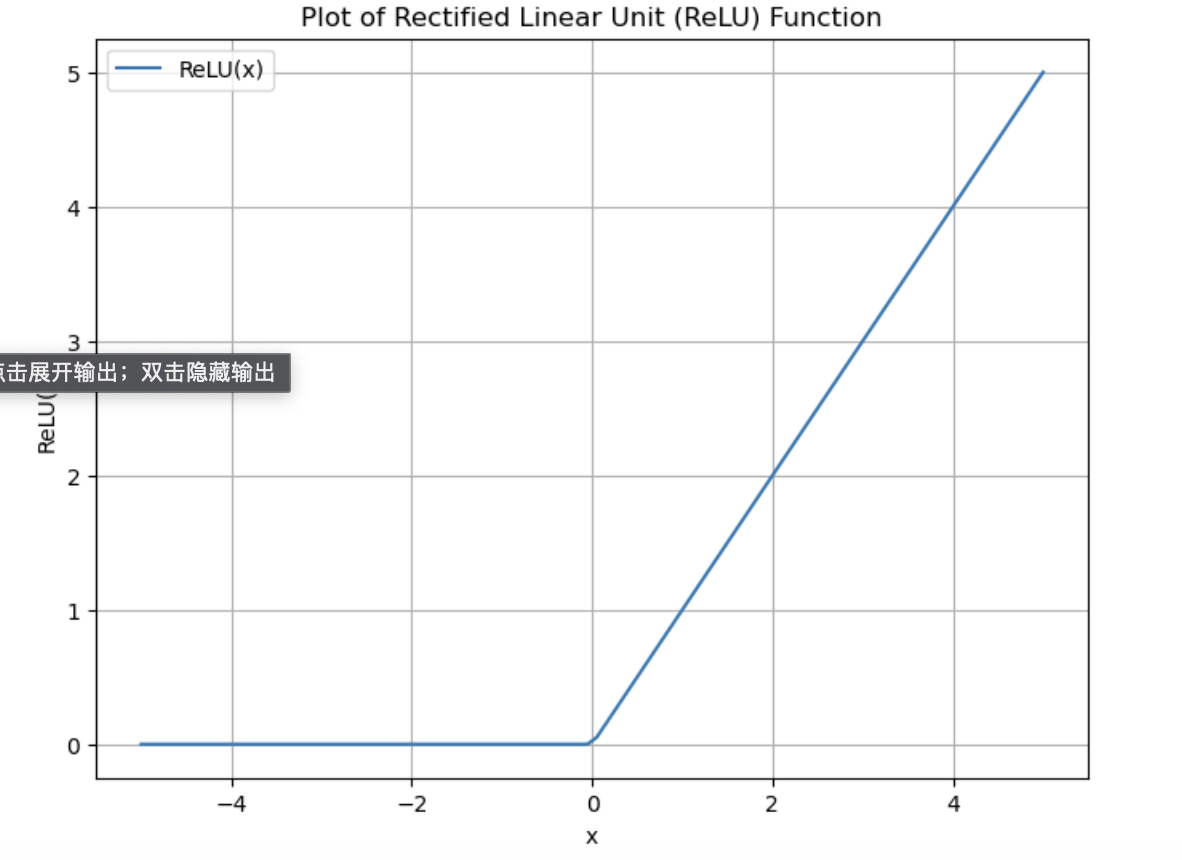
ReLU 函数(Rectified Linear Unit)
-
公式: R e L U ( x ) = max ( 0 , x ) {ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)
-
特点:简单且高效,解决了梯度消失问题,但可能导致神经元死亡问题(输出恒为 0)
-
import numpy as np
import matplotlib.pyplot as plt
# 定义 ReLU 函数
def relu(x):
return np.maximum(0, x)
# 生成 x 值
x = np.linspace(-5, 5, 100)
# 计算 ReLU 函数的 y 值
y = relu(x)
# 绘制 ReLU 函数图像
plt.figure(figsize=(8, 6))
plt.plot(x, y, label='ReLU(x)')
plt.xlabel('x')
plt.ylabel('ReLU(x)')
plt.title('Plot of Rectified Linear Unit (ReLU) Function')
plt.grid(True)
plt.legend()
plt.show()
内容小结
-
模型训练本质:固定w和b参数的过程
- 让模型更好→本质上就是让模型的损失值loss变小;
- 让loss变小→本质上就是求loss函数的最小值;
-
深度学习的整体项目路程
- 第一步:读取数据、切分数据、数据规范化
- 第二步:批量化打包数据
- 第三步:构建模型
- 第四步:筹备训练,定义损失函数、定义优化器、定义训练次数、定义学习率
- 第五步:训练模型,在训练的过程中需要对损失值进行监控
- 第六步:推理模型,即直接将待预测样本数据代入模型求预测值y_pred即可
-
第三步构建模型时
- 一般常用自定义class类的方法,这种方法更加灵活
- 为了降低模型的损失值,可以采用加入激活函数以及多层感知机的方式
-
第五步实现训练模型时
- 基本的五步法:1.正向传播→2.损失计算→3.反向传播→4.优化一步→5.清空梯度
-
使用深度学习进行分类问题时,流程与回归问题基本一致,不同的地方在于
- 损失函数计算方法不同:回归问题使用的是MSE,分类问题使用的是交叉熵。
- 训练过程中监控的指标不同,回归问题监控MSE,分类问题监控的是准确率。
-
神经网络在处理分类问题时,输出的不是某个类别,而是不同类别的概率。
- 在输出概率时,需要进行概率模拟
- 二分类问题概率模拟时,使用Sigmoid函数;多分类概率模拟时,使用的是softmax函数
参考资料:
多层感知机
百度百科:ReLU函数
百度百科:Sigmoid函数