您还可以使用SHOW DATA TYPES;查看Doris支持的所有数据类型。
部分类型如下:
| Type name | Number of bytes | Description |
|---|---|---|
| STRING | / | 可变长度字符串,默认支持1048576字节(1Mb),最大精度限制为2147483643字节(2gb)。大小可以通过BE配置string_type_length_soft_limit_bytes调整。字符串类型只能在值列中使用,不能在键列和分区桶列中使用。 |
| HLL | / | HLL是HyperLogLog的缩写,是一种模糊重复数据删除。在处理大型数据集时,它比Count Distinct性能更好。HLL的错误率一般在1%左右,有时甚至可以达到2%。HLL不能作为键列,创建表时聚合类型为HLL_UNION。用户不需要指定长度或默认值,因为它是根据数据的聚合级别在内部控制的。HLL列只能通过hll_union_agg、hll_raw_agg、hll_cardinality和hll_hash等配套函数查询或使用。 |
| BITMAP | / | BITMAP类型可用于Aggregate 表或Unique 表。-- 当在Unique表中使用时,BITMAP必须作为非键列。—在聚合表中使用BITMAP时,BITMAP还必须作为非键列,并且在创建表时必须将聚合类型设置为BITMAP_UNION。用户不需要指定长度或默认值,因为它是根据数据的聚合级别在内部控制的。BITMAP列只能通过bitmap_union_count、bitmap_union、bitmap_hash和bitmap_hash64等配套函数查询或使用。 |
| QUANTILE_STATE | / | 一种用于计算近似分位数值的类型。加载时,它对具有不同值的相同键执行预聚合。当值的个数不超过2048时,详细记录所有数据。当值的个数大于2048时,采用TDigest算法对数据进行聚合(聚类),聚类后存储质心点。QUANTILE_STATE不能用作键列,在创建表时应该与聚合类型QUANTILE_UNION配对。用户不需要指定长度或默认值,因为它是根据数据的聚合级别在内部控制的。QUANTILE_STATE列只能通过QUANTILE_PERCENT、QUANTILE_UNION和TO_QUANTILE_STATE等配套函数查询或使用。 |
| ARRAY | / | 由T类型元素组成的数组不能用作键列。目前支持在具有Duplicate 和Unique 模型的表中使用。 |
| MAP | / | 由K和V类型元素组成的映射(Maps)不能用作Key列。这些映射目前在使用Duplicate和Unique模型的表中得到支持。 |
| STRUCT | / | 由多个字段组成的结构也可以理解为多个列的集合。它不能用作Key。目前,STRUCT只能在Duplicate模型的表中使用。Struct中字段的名称和数量是固定的,并且总是可空的。 |
| JSON | / | 二进制JSON类型,以二进制JSON格式存储,通过JSON函数访问内部JSON字段。默认最大支持1048576字节(1MB),可调整为最大2147483643字节(2GB)。这个限制可以通过be配置参数jsonb_type_length_soft_limit_bytes来修改。 |
| AGG_STATE | / | 聚合函数只能与state/merge/union函数组合器一起使用。AGG_STATE不能用作键列。在创建表时,需要同时声明聚合函数的签名。用户不需要指定长度或默认值。实际的数据存储大小取决于函数的实现。 |
1、STRING
注意:可变长度字符串以UTF-8编码存储,所以通常英文字符占用1字节,中文字符占用3字节。
2、HLL (HyperLogLog)
HLL是不同元素的近似计数,当数据量较大时,其性能优于count distinct。HLL的误差通常在1%左右,有时高达2%。
3、BITMAP
在离线场景下使用BITMAP会影响导入速度。在数据量大的情况下,查询速度会比HLL慢,而比Count Distinct好。注意:如果BITMAP在实时场景下不使用全局字典,使用bitmap_hash()可能会导致千分之一左右的错误。如果错误率不能容忍,可以使用bitmap_hash64代替。
example
创建表示例:
create table metric_table (
datekey int,
hour int,
device_id bitmap BITMAP_UNION
)
aggregate key (datekey, hour)
distributed by hash(datekey, hour) buckets 1
properties(
"replication_num" = "1"
);
插入数据示例:
insert into metric_table values
(20200622, 1, to_bitmap(243)),
(20200622, 2, bitmap_from_array([1,2,3,4,5,434543])),
(20200622, 3, to_bitmap(287667876573));
查询数据示例:
select hour, BITMAP_UNION_COUNT(pv) over(order by hour) uv from(
select hour, BITMAP_UNION(device_id) as pv
from metric_table -- Query the accumulated UV per hour
where datekey=20200622
group by hour order by 1
) final;
查询时,BITMAP可以与return_object_data_as_binary配合使用。具体请参考变量。
4、QUANTILE_STATE
在2.0中,我们支持agg_state函数,并且建议使用agg_state quantile_union(quantile_state not null)来代替这种类型。
QUANTILE_STATE不能用作键列。QUANTILE_STATE类型的列可用于Aggregate表、Duplicate表和Unique表。在Aggregate表中使用时,在构建表时聚合类型为HLL_UNION。
用户不需要指定长度和缺省值。长度在系统内根据数据聚合的程度进行控制。并且QUANTILE_STATE列只能通过支持的QUANTILE_PERCENT、QUANTILE_UNION和TO_QUANTILE_STATE函数来查询或使用。
QUANTILE_STATE是计算分位数近似值的类型。在加载过程中,对具有相同键的不同值进行预聚合。当聚合值不超过2048个时,将详细记录所有数据。当聚合值的个数大于2048时,使用TDigest算法对数据进行聚合(聚类),聚类后保存质心点。
QUANTILE_UNION(QUANTILE_STATE):
This function is an aggregation function, which is used to aggregate the intermediate results of different quantile calculations. The result returned by this function is still QUANTILE_STATE
TO_QUANTILE_STATE(DOUBLE raw_data [,FLOAT compression]):
This function converts a numeric type to a QUANTILE_STATE type
The compression parameter is optional and can be set in the range [2048, 10000].
The larger the value, the higher the precision of quantile approximation calculations, the greater the memory consumption, and the longer the calculation time.
An unspecified or set value for the compression parameter is outside the range [2048, 10000], run with the default value of 2048
QUANTILE_PERCENT(QUANTILE_STATE, percent):
This function converts the intermediate result variable (QUANTILE_STATE) of the quantile calculation into a specific quantile value
notice
现在,QUANTILE_STATE只能在Aggregate模型表中使用。在使用之前,我们应该用下面的命令打开QUANTILE_STATE类型特性的开关:
$ mysql-client > admin set frontend config("enable_quantile_state_type"="true");
这样,FE进程重启后,配置将被重置。对于永久设置,可以在fe.conf中添加enable_quantile_state_type=true。
example
select QUANTILE_PERCENT(QUANTILE_UNION(v1), 0.5) from test_table group by k1, k2, k3;
5、ARRAY
T类型项的数组,不能用作键列。现在ARRAY只能在Duplicate 模型表中使用。
在2.0版本之后,它支持在Unique模型表中使用非键列。
T类型可以是:
BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, FLOAT, DOUBLE, DECIMAL, DATE,
DATEV2, DATETIME, DATETIMEV2, CHAR, VARCHAR, STRING
example
创建表示例:
mysql> CREATE TABLE `array_test` (
`id` int(11) NULL COMMENT "",
`c_array` ARRAY<int(11)> NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`id`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"in_memory" = "false",
"storage_format" = "V2"
);
插入数据示例:
mysql> INSERT INTO `array_test` VALUES (1, [1,2,3,4,5]);
mysql> INSERT INTO `array_test` VALUES (2, [6,7,8]), (3, []), (4, null);
选择数据示例:
mysql> SELECT * FROM `array_test`;
+------+-----------------+
| id | c_array |
+------+-----------------+
| 1 | [1, 2, 3, 4, 5] |
| 2 | [6, 7, 8] |
| 3 | [] |
| 4 | NULL |
+------+-----------------+
6、MAP
MAP<K, V>
一个K、V个项组成的Map,所以不能用作键列。现在MAP只能在Duplicate 和Unique 模型表中使用。
需要手动启用支持,默认为关闭。
admin set frontend config("enable_map_type" = "true");
K,V可以是:
BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, FLOAT, DOUBLE, DECIMAL, DECIMALV3, DATE,
DATEV2, DATETIME, DATETIMEV2, CHAR, VARCHAR, STRING
example
CREATE TABLE IF NOT EXISTS test.simple_map (
`id` INT(11) NULL COMMENT "",
`m` Map<STRING, INT> NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"storage_format" = "V2"
);
stream_load示例:参见STREAM TABLE了解语法细节。
# load the map data from json file
curl --location-trusted -uroot: -T events.json -H "format: json" -H "read_json_by_line: true" http://fe_host:8030/api/test/simple_map/_stream_load
# 返回结果
{
"TxnId": 106134,
"Label": "5666e573-9a97-4dfc-ae61-2d6b61fdffd2",
"Comment": "",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 10293125,
"NumberLoadedRows": 10293125,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 2297411459,
"LoadTimeMs": 66870,
"BeginTxnTimeMs": 1,
"StreamLoadPutTimeMs": 80,
"ReadDataTimeMs": 6415,
"WriteDataTimeMs": 10550,
"CommitAndPublishTimeMs": 38
}
选择所有数据示例:
mysql> SELECT * FROM simple_map;
+------+-----------------------------+
| id | m |
+------+-----------------------------+
| 1 | {'a':100, 'b':200} |
| 2 | {'b':100, 'c':200, 'd':300} |
| 3 | {'a':10, 'd':200} |
+------+-----------------------------+
选择map 列示例:
mysql> SELECT m FROM simple_map;
+-----------------------------+
| m |
+-----------------------------+
| {'a':100, 'b':200} |
| {'b':100, 'c':200, 'd':300} |
| {'a':10, 'd':200} |
+-----------------------------+
根据给定的键示例选择映射值:
mysql> SELECT m['a'] FROM simple_map;
+-----------------------------+
| %element_extract%(`m`, 'a') |
+-----------------------------+
| 100 |
| NULL |
| 10 |
+-----------------------------+
map functions examples:
# map construct
mysql> SELECT map('k11', 1000, 'k22', 2000)['k11'];
+---------------------------------------------------------+
| %element_extract%(map('k11', 1000, 'k22', 2000), 'k11') |
+---------------------------------------------------------+
| 1000 |
+---------------------------------------------------------+
mysql> SELECT map('k11', 1000, 'k22', 2000)['nokey'];
+-----------------------------------------------------------+
| %element_extract%(map('k11', 1000, 'k22', 2000), 'nokey') |
+-----------------------------------------------------------+
| NULL |
+-----------------------------------------------------------+
1 row in set (0.06 sec)
# map size
mysql> SELECT map_size(map('k11', 1000, 'k22', 2000));
+-----------------------------------------+
| map_size(map('k11', 1000, 'k22', 2000)) |
+-----------------------------------------+
| 2 |
+-----------------------------------------+
mysql> SELECT id, m, map_size(m) FROM simple_map ORDER BY id;
+------+-----------------------------+---------------+
| id | m | map_size(`m`) |
+------+-----------------------------+---------------+
| 1 | {"a":100, "b":200} | 2 |
| 2 | {"b":100, "c":200, "d":300} | 3 |
| 2 | {"a":10, "d":200} | 2 |
+------+-----------------------------+---------------+
3 rows in set (0.04 sec)
# map_contains_key
mysql> SELECT map_contains_key(map('k11', 1000, 'k22', 2000), 'k11');
+--------------------------------------------------------+
| map_contains_key(map('k11', 1000, 'k22', 2000), 'k11') |
+--------------------------------------------------------+
| 1 |
+--------------------------------------------------------+
1 row in set (0.08 sec)
mysql> SELECT id, m, map_contains_key(m, 'k1') FROM simple_map ORDER BY id;
+------+-----------------------------+-----------------------------+
| id | m | map_contains_key(`m`, 'k1') |
+------+-----------------------------+-----------------------------+
| 1 | {"a":100, "b":200} | 0 |
| 2 | {"b":100, "c":200, "d":300} | 0 |
| 2 | {"a":10, "d":200} | 0 |
+------+-----------------------------+-----------------------------+
3 rows in set (0.10 sec)
mysql> SELECT id, m, map_contains_key(m, 'a') FROM simple_map ORDER BY id;
+------+-----------------------------+----------------------------+
| id | m | map_contains_key(`m`, 'a') |
+------+-----------------------------+----------------------------+
| 1 | {"a":100, "b":200} | 1 |
| 2 | {"b":100, "c":200, "d":300} | 0 |
| 2 | {"a":10, "d":200} | 1 |
+------+-----------------------------+----------------------------+
3 rows in set (0.17 sec)
# map_contains_value
mysql> SELECT map_contains_value(map('k11', 1000, 'k22', 2000), NULL);
+---------------------------------------------------------+
| map_contains_value(map('k11', 1000, 'k22', 2000), NULL) |
+---------------------------------------------------------+
| 0 |
+---------------------------------------------------------+
1 row in set (0.04 sec)
mysql> SELECT id, m, map_contains_value(m, '100') FROM simple_map ORDER BY id;
+------+-----------------------------+------------------------------+
| id | m | map_contains_value(`m`, 100) |
+------+-----------------------------+------------------------------+
| 1 | {"a":100, "b":200} | 1 |
| 2 | {"b":100, "c":200, "d":300} | 1 |
| 2 | {"a":10, "d":200} | 0 |
+------+-----------------------------+------------------------------+
3 rows in set (0.11 sec)
# map_keys
mysql> SELECT map_keys(map('k11', 1000, 'k22', 2000));
+-----------------------------------------+
| map_keys(map('k11', 1000, 'k22', 2000)) |
+-----------------------------------------+
| ["k11", "k22"] |
+-----------------------------------------+
1 row in set (0.04 sec)
mysql> SELECT id, map_keys(m) FROM simple_map ORDER BY id;
+------+-----------------+
| id | map_keys(`m`) |
+------+-----------------+
| 1 | ["a", "b"] |
| 2 | ["b", "c", "d"] |
| 2 | ["a", "d"] |
+------+-----------------+
3 rows in set (0.19 sec)
# map_values
mysql> SELECT map_values(map('k11', 1000, 'k22', 2000));
+-------------------------------------------+
| map_values(map('k11', 1000, 'k22', 2000)) |
+-------------------------------------------+
| [1000, 2000] |
+-------------------------------------------+
1 row in set (0.03 sec)
mysql> SELECT id, map_values(m) FROM simple_map ORDER BY id;
+------+-----------------+
| id | map_values(`m`) |
+------+-----------------+
| 1 | [100, 200] |
| 2 | [100, 200, 300] |
| 2 | [10, 200] |
+------+-----------------+
3 rows in set (0.18 sec)
7、STRUCT
描述
STRUCT<field_name:field_type [COMMENT 'comment_string'], ... >
表示具有由多个字段描述的结构的值,可以将其视为多个列的集合。
需要手动启用支持,默认为关闭。
admin set frontend config("enable_struct_type" = "true");
它不能用作KEY列。现在STRUCT只能在 Duplicate 模型表中使用。
Struct中字段的名称和数量是固定的,并且总是可空的,一个字段通常由以下部分组成。
- field_name:指定字段的标识符,不可重复。
- field_type:数据类型。
- COMMENT:描述字段的可选字符串。(目前不支持)
目前支持的类型有:
BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, FLOAT, DOUBLE, DECIMAL, DECIMALV3, DATE,
DATEV2, DATETIME, DATETIMEV2, CHAR, VARCHAR, STRING
我们有一个未来版本的待办事项列表:
TODO: Supports nested Struct or other complex types
example
创建表示例:
CREATE TABLE `struct_test` (
`id` int(11) NULL,
`s_info` STRUCT<s_id:int(11), s_name:string, s_address:string> NULL
) ENGINE=OLAP
DUPLICATE KEY(`id`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"storage_format" = "V2",
"light_schema_change" = "true",
"disable_auto_compaction" = "false"
);
插入数据示例:
INSERT INTO `struct_test` VALUES (1, {1, 'sn1', 'sa1'});
INSERT INTO `struct_test` VALUES (2, struct(2, 'sn2', 'sa2'));
INSERT INTO `struct_test` VALUES (3, named_struct('s_id', 3, 's_name', 'sn3', 's_address', 'sa3'));
Stream load:
test.csv:
1|{"s_id":1, "s_name":"sn1", "s_address":"sa1"}
2|{s_id:2, s_name:sn2, s_address:sa2}
3|{"s_address":"sa3", "s_name":"sn3", "s_id":3}
curl --location-trusted -u root -T test.csv -H "label:test_label" http://host:port/api/test/struct_test/_stream_load
选择数据示例:
mysql> select * from struct_test;
+------+-------------------+
| id | s_info |
+------+-------------------+
| 1 | {1, 'sn1', 'sa1'} |
| 2 | {2, 'sn2', 'sa2'} |
| 3 | {3, 'sn3', 'sa3'} |
+------+-------------------+
3 rows in set (0.02 sec)
8、JSON
注意:在1.2.x 版本中,数据类型名称为
JSONB。它被重命名为JSON,以便与2.0.0版本更兼容。旧桌子还可以用。
描述
JSON (Binary) datatype.
Use binary JSON format for storage and json function to extract field.
Default support is 1048576 bytes (1M), adjustable up to 2147483643 bytes (2G),and the JSONB type is also limited by the be configuration `jsonb_type_length_soft_limit_bytes`.
注意
There are some advantanges for JSON over plain JSON STRING.
1. JSON syntax will be validated on write to ensure data quality
// JSON语法将在写入时进行验证,以确保数据质量
2. JSON binary format is more efficient. Using json_extract functions on JSON datatype is 2-4 times faster than get_json_xx on JSON STRING format.
// JSON二进制格式效率更高。在JSON数据类型上使用json_extract函数
// 比在JSON STRING格式上使用get_json_xx函数快2-4倍。
example
JSON数据类型教程,包括创建表、加载数据和查询。
创建数据库和表:
CREATE DATABASE testdb;
USE testdb;
CREATE TABLE test_json (
id INT,
j JSON
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 10
PROPERTIES("replication_num" = "1");
Load data
流加载test_json.csv测试数据
- 有两列,第一列是id,第二列是json字符串
- 有25行,前18行是有效的json,最后7行无效
1 \N
2 null
3 true
4 false
5 100
6 10000
7 1000000000
8 1152921504606846976
9 6.18
10 "abcd"
11 {}
12 {"k1":"v31", "k2": 300}
13 []
14 [123, 456]
15 ["abc", "def"]
16 [null, true, false, 100, 6.18, "abc"]
17 [{"k1":"v41", "k2": 400}, 1, "a", 3.14]
18 {"k1":"v31", "k2": 300, "a1": [{"k1":"v41", "k2": 400}, 1, "a", 3.14]}
19 ''
20 'abc'
21 abc
22 100x
23 6.a8
24 {x
25 [123, abc]
- 由于28%的行无效,使用默认配置的流加载将失败,并出现错误消息“筛选的行太多”。
curl --location-trusted -u root: -T test_json.csv http://127.0.0.1:8840/api/testdb/test_json/_stream_load
{
"TxnId": 12019,
"Label": "744d9821-9c9f-43dc-bf3b-7ab048f14e32",
"TwoPhaseCommit": "false",
"Status": "Fail",
"Message": "too many filtered rows",
"NumberTotalRows": 25,
"NumberLoadedRows": 18,
"NumberFilteredRows": 7,
"NumberUnselectedRows": 0,
"LoadBytes": 380,
"LoadTimeMs": 48,
"BeginTxnTimeMs": 0,
"StreamLoadPutTimeMs": 1,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 45,
"CommitAndPublishTimeMs": 0,
"ErrorURL": "http://172.21.0.5:8840/api/_load_error_log?file=__shard_2/error_log_insert_stmt_95435c4bf5f156df-426735082a9296af_95435c4bf5f156df_426735082a9296af"
}
设置报头配置max_filter_ratio: 0.3后,流加载将成功
curl --location-trusted -u root: -H 'max_filter_ratio: 0.3' -T test_json.csv http://127.0.0.1:8840/api/testdb/test_json/_stream_load
{
"TxnId": 12017,
"Label": "f37a50c1-43e9-4f4e-a159-a3db6abe2579",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 25,
"NumberLoadedRows": 18,
"NumberFilteredRows": 7,
"NumberUnselectedRows": 0,
"LoadBytes": 380,
"LoadTimeMs": 68,
"BeginTxnTimeMs": 0,
"StreamLoadPutTimeMs": 2,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 45,
"CommitAndPublishTimeMs": 19,
"ErrorURL": "http://172.21.0.5:8840/api/_load_error_log?file=__shard_0/error_log_insert_stmt_a1463f98a7b15caf-c79399b920f5bfa3_a1463f98a7b15caf_c79399b920f5bfa3"
}
使用SELECT来查看流加载的数据。具有JSON类型的列将显示为普通JSON字符串。
mysql> SELECT * FROM test_json ORDER BY id;
+------+---------------------------------------------------------------+
| id | j |
+------+---------------------------------------------------------------+
| 1 | NULL |
| 2 | null |
| 3 | true |
| 4 | false |
| 5 | 100 |
| 6 | 10000 |
| 7 | 1000000000 |
| 8 | 1152921504606846976 |
| 9 | 6.18 |
| 10 | "abcd" |
| 11 | {} |
| 12 | {"k1":"v31","k2":300} |
| 13 | [] |
| 14 | [123,456] |
| 15 | ["abc","def"] |
| 16 | [null,true,false,100,6.18,"abc"] |
| 17 | [{"k1":"v41","k2":400},1,"a",3.14] |
| 18 | {"k1":"v31","k2":300,"a1":[{"k1":"v41","k2":400},1,"a",3.14]} |
+------+---------------------------------------------------------------+
18 rows in set (0.03 sec)
使用insert into写入数据
- 插入1行后,行总数从18增加到19
mysql> INSERT INTO test_json VALUES(26, '{"k1":"v1", "k2": 200}');
Query OK, 1 row affected (0.09 sec)
{'label':'insert_4ece6769d1b42fd_ac9f25b3b8f3dc02', 'status':'VISIBLE', 'txnId':'12016'}
mysql> SELECT * FROM test_json ORDER BY id;
+------+---------------------------------------------------------------+
| id | j |
+------+---------------------------------------------------------------+
| 1 | NULL |
| 2 | null |
| 3 | true |
| 4 | false |
| 5 | 100 |
| 6 | 10000 |
| 7 | 1000000000 |
| 8 | 1152921504606846976 |
| 9 | 6.18 |
| 10 | "abcd" |
| 11 | {} |
| 12 | {"k1":"v31","k2":300} |
| 13 | [] |
| 14 | [123,456] |
| 15 | ["abc","def"] |
| 16 | [null,true,false,100,6.18,"abc"] |
| 17 | [{"k1":"v41","k2":400},1,"a",3.14] |
| 18 | {"k1":"v31","k2":300,"a1":[{"k1":"v41","k2":400},1,"a",3.14]} |
| 26 | {"k1":"v1","k2":200} |
+------+---------------------------------------------------------------+
19 rows in set (0.03 sec)
查询:
通过json_extract函数从json中提取一些字段
- 提取整个json, '$'代表json路径中的根
+------+---------------------------------------------------------------+---------------------------------------------------------------+
| id | j | json_extract(`j`, '$') |
+------+---------------------------------------------------------------+---------------------------------------------------------------+
| 1 | NULL | NULL |
| 2 | null | null |
| 3 | true | true |
| 4 | false | false |
| 5 | 100 | 100 |
| 6 | 10000 | 10000 |
| 7 | 1000000000 | 1000000000 |
| 8 | 1152921504606846976 | 1152921504606846976 |
| 9 | 6.18 | 6.18 |
| 10 | "abcd" | "abcd" |
| 11 | {} | {} |
| 12 | {"k1":"v31","k2":300} | {"k1":"v31","k2":300} |
| 13 | [] | [] |
| 14 | [123,456] | [123,456] |
| 15 | ["abc","def"] | ["abc","def"] |
| 16 | [null,true,false,100,6.18,"abc"] | [null,true,false,100,6.18,"abc"] |
| 17 | [{"k1":"v41","k2":400},1,"a",3.14] | [{"k1":"v41","k2":400},1,"a",3.14] |
| 18 | {"k1":"v31","k2":300,"a1":[{"k1":"v41","k2":400},1,"a",3.14]} | {"k1":"v31","k2":300,"a1":[{"k1":"v41","k2":400},1,"a",3.14]} |
| 26 | {"k1":"v1","k2":200} | {"k1":"v1","k2":200} |
+------+---------------------------------------------------------------+---------------------------------------------------------------+
19 rows in set (0.03 sec)
- 提取k1字段,如果不存在则返回NULL
mysql> SELECT id, j, json_extract(j, '$.k1') FROM test_json ORDER BY id;
+------+---------------------------------------------------------------+----------------------------+
| id | j | json_extract(`j`, '$.k1') |
+------+---------------------------------------------------------------+----------------------------+
| 1 | NULL | NULL |
| 2 | null | NULL |
| 3 | true | NULL |
| 4 | false | NULL |
| 5 | 100 | NULL |
| 6 | 10000 | NULL |
| 7 | 1000000000 | NULL |
| 8 | 1152921504606846976 | NULL |
| 9 | 6.18 | NULL |
| 10 | "abcd" | NULL |
| 11 | {} | NULL |
| 12 | {"k1":"v31","k2":300} | "v31" |
| 13 | [] | NULL |
| 14 | [123,456] | NULL |
| 15 | ["abc","def"] | NULL |
| 16 | [null,true,false,100,6.18,"abc"] | NULL |
| 17 | [{"k1":"v41","k2":400},1,"a",3.14] | NULL |
| 18 | {"k1":"v31","k2":300,"a1":[{"k1":"v41","k2":400},1,"a",3.14]} | "v31" |
| 26 | {"k1":"v1","k2":200} | "v1" |
+------+---------------------------------------------------------------+----------------------------+
19 rows in set (0.03 sec)
- 提取顶层数组的元素0
mysql> SELECT id, j, json_extract(j, '$[0]') FROM test_json ORDER BY id;
+------+---------------------------------------------------------------+----------------------------+
| id | j | json_extract(`j`, '$[0]') |
+------+---------------------------------------------------------------+----------------------------+
| 1 | NULL | NULL |
| 2 | null | NULL |
| 3 | true | NULL |
| 4 | false | NULL |
| 5 | 100 | NULL |
| 6 | 10000 | NULL |
| 7 | 1000000000 | NULL |
| 8 | 1152921504606846976 | NULL |
| 9 | 6.18 | NULL |
| 10 | "abcd" | NULL |
| 11 | {} | NULL |
| 12 | {"k1":"v31","k2":300} | NULL |
| 13 | [] | NULL |
| 14 | [123,456] | 123 |
| 15 | ["abc","def"] | "abc" |
| 16 | [null,true,false,100,6.18,"abc"] | null |
| 17 | [{"k1":"v41","k2":400},1,"a",3.14] | {"k1":"v41","k2":400} |
| 18 | {"k1":"v31","k2":300,"a1":[{"k1":"v41","k2":400},1,"a",3.14]} | NULL |
| 26 | {"k1":"v1","k2":200} | NULL |
+------+---------------------------------------------------------------+----------------------------+
19 rows in set (0.03 sec)
- 提取名称为a1的整个json数组
mysql> SELECT id, j, json_extract(j, '$.a1') FROM test_json ORDER BY id;
+------+---------------------------------------------------------------+------------------------------------+
| id | j | json_extract(`j`, '$.a1') |
+------+---------------------------------------------------------------+------------------------------------+
| 1 | NULL | NULL |
| 2 | null | NULL |
| 3 | true | NULL |
| 4 | false | NULL |
| 5 | 100 | NULL |
| 6 | 10000 | NULL |
| 7 | 1000000000 | NULL |
| 8 | 1152921504606846976 | NULL |
| 9 | 6.18 | NULL |
| 10 | "abcd" | NULL |
| 11 | {} | NULL |
| 12 | {"k1":"v31","k2":300} | NULL |
| 13 | [] | NULL |
| 14 | [123,456] | NULL |
| 15 | ["abc","def"] | NULL |
| 16 | [null,true,false,100,6.18,"abc"] | NULL |
| 17 | [{"k1":"v41","k2":400},1,"a",3.14] | NULL |
| 18 | {"k1":"v31","k2":300,"a1":[{"k1":"v41","k2":400},1,"a",3.14]} | [{"k1":"v41","k2":400},1,"a",3.14] |
| 26 | {"k1":"v1","k2":200} | NULL |
+------+---------------------------------------------------------------+------------------------------------+
19 rows in set (0.02 sec)
更多 查询请参考
9、AGG_STATE
描述
AGG_STATE cannot be used as a key column, and the signature of the aggregation function must be declared at the same time when creating the table.
//AGG_STATE不能用作键列,并且必须在创建表的同时声明聚合函数的签名。
User does not need to specify length and default value. The actual stored data size is related to the function implementation.
// 用户不需要指定长度和默认值。实际存储的数据大小与函数实现有关。
AGG_STATE 只能与state /merge/union函数组合使用。
需要注意的是,聚合函数的签名也是类型的一部分,不同签名的agg_state不能混合使用。例如,如果表创建语句的签名是max_by(int,int),则不能插入max_by(bigint,int)或group_concat(varchar)。这里的nullable属性也是签名的一部分。如果可以确认不输入空值,则可以将参数声明为非空,这样可以获得更小的存储大小并减少序列化/反序列化开销。
example
创建表示例:
-- after doris-2.1.1
create table a_table(
k1 int null,
k2 agg_state<max_by(int not null,int)> generic,
k3 agg_state<group_concat(string) generic
)
aggregate key (k1)
distributed BY hash(k1) buckets 3
properties("replication_num" = "1");
-- until doris-2.1.0
create table a_table(
k1 int null,
k2 agg_state max_by(int not null,int),
k3 agg_state group_concat(string)
)
aggregate key (k1)
distributed BY hash(k1) buckets 3
properties("replication_num" = "1");
这里k2和k3分别使用max_by和group_concat作为聚合类型。
插入数据示例:
insert into a_table values(1,max_by_state(3,1),group_concat_state('a'));
insert into a_table values(1,max_by_state(2,2),group_concat_state('bb'));
insert into a_table values(2,max_by_state(1,3),group_concat_state('ccc'));
对于agg_state列,插入语句必须使用state函数来生成相应的agg_state数据,其中的函数和输入参数类型必须完全对应于agg_state。
查询数据示例:
mysql [test]>select k1,max_by_merge(k2),group_concat_merge(k3) from a_table group by k1 order by k1;
+------+--------------------+--------------------------+
| k1 | max_by_merge(`k2`) | group_concat_merge(`k3`) |
+------+--------------------+--------------------------+
| 1 | 2 | bb,a |
| 2 | 1 | ccc |
+------+--------------------+--------------------------+
如果需要得到实际的结果,则需要使用相应的合并函数。
mysql [test]>select max_by_merge(u2),group_concat_merge(u3) from (
select k1,max_by_union(k2) as u2,group_concat_union(k3) u3 from a_table group by k1 order by k1
) t;
+--------------------+--------------------------+
| max_by_merge(`u2`) | group_concat_merge(`u3`) |
+--------------------+--------------------------+
| 1 | ccc,bb,a |
+--------------------+--------------------------+
如果您只想聚合agg_state,而不想在此过程中获得实际结果,那么可以使用union函数。
10、VARIANT
描述
在Doris 2.1中引入了一个新的数据类型VARIANT,它可以存储半结构化JSON数据。它允许存储包含不同数据类型(如整数、字符串、布尔值等)的复杂数据结构。无需事先在表结构中定义特定的列。VARIANT类型对于处理可能随时更改的复杂嵌套结构特别有用。在写入过程中,该类型可以根据列的结构和类型自动推断列信息,动态合并写入的模式。它将JSON键及其对应的值存储为列和动态子列。
注意
相对于JSON Type的优势:
- 不同的存储方式:
JSON类型以二进制JSONB格式存储,整个JSON逐行存储在段文件中。相反,VARIANT类型在写入期间推断类型并存储写入的JSON列。与JSON类型相比,它具有更高的压缩比,提供更好的存储效率。 - 查询:查询不需要解析。
VARIANT充分利用了Doris的列式存储、矢量化引擎、优化器等组件,为用户提供极高的查询性能。以下是基于clickbench数据的测试结果:
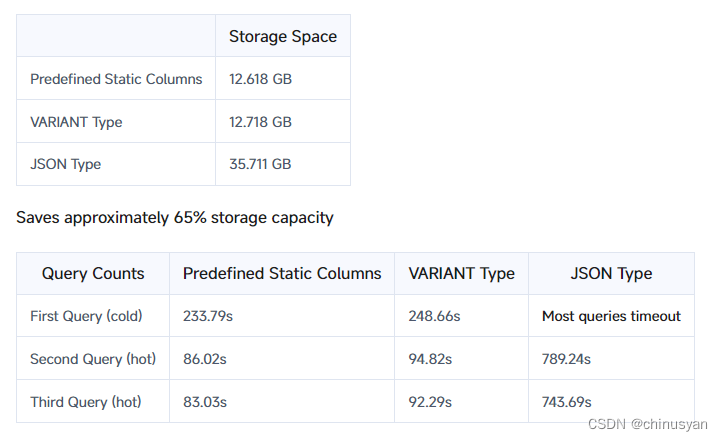
测试用例包含43个查询
查询速度快8倍,查询性能堪比静态列
例子
通过一个包含表创建、数据导入和查询周期的示例来演示VARIANT的功能和用法。
表创建语法使用语法中的VARIANT关键字创建表。
-- Without index
CREATE TABLE IF NOT EXISTS ${table_name} (
k BIGINT,
v VARIANT
)
table_properties;
-- Create an index on the v column, optionally specify the tokenize method, default is untokenized
CREATE TABLE IF NOT EXISTS ${table_name} (
k BIGINT,
v VARIANT,
INDEX idx_var(v) USING INVERTED [PROPERTIES("parser" = "english|unicode|chinese")] [COMMENT 'your comment']
)
table_properties;
-- Create an bloom filter on v column, to enhance query seed on sub columns
CREATE TABLE IF NOT EXISTS ${table_name} (
k BIGINT,
v VARIANT
)
...
properties("replication_num" = "1", "bloom_filter_columns" = "v");
查询语法
-- use v['a']['b'] format for example, v['properties']['title'] type is VARIANT
SELECT v['properties']['title'] from ${table_name}
基于GitHub事件数据集的示例
这里,github事件数据用于演示使用VARIANT创建表、导入数据和查询。下面是格式化的数据行:
{
"id": "14186154924",
"type": "PushEvent",
"actor": {
"id": 282080,
"login": "brianchandotcom",
"display_login": "brianchandotcom",
"gravatar_id": "",
"url": "https://api.github.com/users/brianchandotcom",
"avatar_url": "https://avatars.githubusercontent.com/u/282080?"
},
"repo": {
"id": 1920851,
"name": "brianchandotcom/liferay-portal",
"url": "https://api.github.com/repos/brianchandotcom/liferay-portal"
},
"payload": {
"push_id": 6027092734,
"size": 4,
"distinct_size": 4,
"ref": "refs/heads/master",
"head": "91edd3c8c98c214155191feb852831ec535580ba",
"before": "abb58cc0db673a0bd5190000d2ff9c53bb51d04d",
"commits": [""]
},
"public": true,
"created_at": "2020-11-13T18:00:00Z"
}
表创建
- 创建了
VARIANT类型的三列:actor,repo, 和payload。 - 在创建表的同时,为负载列创建了一个倒排索引
idx_payload。 - 使用
USING INVERTED将索引类型指定为倒排,目的是加速子列的条件过滤。 PROPERTIES("parser" = "english")指定采用英文标记化。
CREATE DATABASE test_variant;
USE test_variant;
CREATE TABLE IF NOT EXISTS github_events (
id BIGINT NOT NULL,
type VARCHAR(30) NULL,
actor VARIANT NULL,
repo VARIANT NULL,
payload VARIANT NULL,
public BOOLEAN NULL,
created_at DATETIME NULL,
INDEX idx_payload (`payload`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for payload'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(id) BUCKETS 10
properties("replication_num" = "1");
在
VARIANT列上创建索引,例如当有效负载中有许多子列时,可能会导致索引列数量过多,从而影响写性能。
同一VARIANT列的标记化属性是统一的。如果您有不同的标记化需求,请考虑创建多个VARIANT列,并分别为每个列指定索引属性。
使用流加载导入
导入gh_2022-11-07-3.json它包含一个小时的GitHub事件数据。
wget http://doris-build-hk-1308700295.cos.ap-hongkong.myqcloud.com/regression/variant/gh_2022-11-07-3.json
curl --location-trusted -u root: -T gh_2022-11-07-3.json -H "read_json_by_line:true" -H "format:json" http://127.0.0.1:18148/api/test_variant/github_events/_strea
m_load
{
"TxnId": 2,
"Label": "086fd46a-20e6-4487-becc-9b6ca80281bf",
"Comment": "",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 139325,
"NumberLoadedRows": 139325,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 633782875,
"LoadTimeMs": 7870,
"BeginTxnTimeMs": 19,
"StreamLoadPutTimeMs": 162,
"ReadDataTimeMs": 2416,
"WriteDataTimeMs": 7634,
"CommitAndPublishTimeMs": 55
}
确认导入成功。
-- View the number of rows.
mysql> select count() from github_events;
+----------+
| count(*) |
+----------+
| 139325 |
+----------+
1 row in set (0.25 sec)
-- Random select one row
mysql> select * from github_events limit 1;
+-------------+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------+---------------------+
| id | type | actor | repo | payload | public | created_at |
+-------------+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------+---------------------+
| 25061821748 | PushEvent | {"gravatar_id":"","display_login":"jfrog-pipelie-intg","url":"https://api.github.com/users/jfrog-pipelie-intg","id":98024358,"login":"jfrog-pipelie-intg","avatar_url":"https://avatars.githubusercontent.com/u/98024358?"} | {"url":"https://api.github.com/repos/jfrog-pipelie-intg/jfinte2e_1667789956723_16","id":562683829,"name":"jfrog-pipelie-intg/jfinte2e_1667789956723_16"} | {"commits":[{"sha":"334433de436baa198024ef9f55f0647721bcd750","author":{"email":"98024358+jfrog-pipelie-intg@users.noreply.github.com","name":"jfrog-pipelie-intg"},"message":"commit message 10238493157623136117","distinct":true,"url":"https://api.github.com/repos/jfrog-pipelie-intg/jfinte2e_1667789956723_16/commits/334433de436baa198024ef9f55f0647721bcd750"}],"before":"f84a26792f44d54305ddd41b7e3a79d25b1a9568","head":"334433de436baa198024ef9f55f0647721bcd750","size":1,"push_id":11572649828,"ref":"refs/heads/test-notification-sent-branch-10238493157623136113","distinct_size":1} | 1 | 2022-11-07 11:00:00 |
+-------------+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------+---------------------+
1 row in set (0.23 sec)
运行desc命令查看模式信息,子列将在存储层自动展开并进行类型推断。
mysql> desc github_events;
+------------------------------------------------------------+------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------------------------------------------------------+------------+------+-------+---------+-------+
| id | BIGINT | No | true | NULL | |
| type | VARCHAR(*) | Yes | false | NULL | NONE |
| actor | VARIANT | Yes | false | NULL | NONE |
| created_at | DATETIME | Yes | false | NULL | NONE |
| payload | VARIANT | Yes | false | NULL | NONE |
| public | BOOLEAN | Yes | false | NULL | NONE |
+------------------------------------------------------------+------------+------+-------+---------+-------+
6 rows in set (0.07 sec)
mysql> set describe_extend_variant_column = true;
Query OK, 0 rows affected (0.01 sec)
mysql> desc github_events;
+------------------------------------------------------------+------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------------------------------------------------------+------------+------+-------+---------+-------+
| id | BIGINT | No | true | NULL | |
| type | VARCHAR(*) | Yes | false | NULL | NONE |
| actor | VARIANT | Yes | false | NULL | NONE |
| actor.avatar_url | TEXT | Yes | false | NULL | NONE |
| actor.display_login | TEXT | Yes | false | NULL | NONE |
| actor.id | INT | Yes | false | NULL | NONE |
| actor.login | TEXT | Yes | false | NULL | NONE |
| actor.url | TEXT | Yes | false | NULL | NONE |
| created_at | DATETIME | Yes | false | NULL | NONE |
| payload | VARIANT | Yes | false | NULL | NONE |
| payload.action | TEXT | Yes | false | NULL | NONE |
| payload.before | TEXT | Yes | false | NULL | NONE |
| payload.comment.author_association | TEXT | Yes | false | NULL | NONE |
| payload.comment.body | TEXT | Yes | false | NULL | NONE |
....
+------------------------------------------------------------+------------+------+-------+---------+-------+
406 rows in set (0.07 sec)
DESC可用于指定分区和查看特定分区的模式。语法如下:
DESCRIBE ${table_name} PARTITION ($partition_name);
查询
当利用过滤和聚合功能查询子列时,需要对子列执行额外的强制转换操作(因为存储类型不一定是固定的,需要统一的SQL类型)。例如,
ELECT * FROM tbl where CAST(var['titile'] as text) MATCH "hello world"下面的简化示例说明了如何使用VARIANT进行查询:以下是三个典型的查询场景
- 根据github_events表中的星数检索前5个存储库。
SELECT
-> cast(repo['name'] as text) as repo_name, count() AS stars
-> FROM github_events
-> WHERE type = 'WatchEvent'
-> GROUP BY repo_name
-> ORDER BY stars DESC LIMIT 5;
+--------------------------+-------+
| repo_name | stars |
+--------------------------+-------+
| aplus-framework/app | 78 |
| lensterxyz/lenster | 77 |
| aplus-framework/database | 46 |
| stashapp/stash | 42 |
| aplus-framework/image | 34 |
+--------------------------+-------+
5 rows in set (0.03 sec)
- 检索包含“doris”的评论计数。
mysql> SELECT
-> count() FROM github_events
-> WHERE cast(payload['comment']['body'] as text) MATCH 'doris';
+---------+
| count() |
+---------+
| 3 |
+---------+
1 row in set (0.04 sec)
- 查询评论数量最多的问题号及其相应的存储库。
SELECT
-> cast(repo['name'] as string) as repo_name,
-> cast(payload['issue']['number'] as int) as issue_number,
-> count() AS comments,
-> count(
-> distinct cast(actor['login'] as string)
-> ) AS authors
-> FROM github_events
-> WHERE type = 'IssueCommentEvent' AND (cast(payload["action"] as string) = 'created') AND (cast(payload["issue"]["number"] as int) > 10)
-> GROUP BY repo_name, issue_number
-> HAVING authors >= 4
-> ORDER BY comments DESC, repo_name
-> LIMIT 50;
+--------------------------------------+--------------+----------+---------+
| repo_name | issue_number | comments | authors |
+--------------------------------------+--------------+----------+---------+
| facebook/react-native | 35228 | 5 | 4 |
| swsnu/swppfall2022-team4 | 27 | 5 | 4 |
| belgattitude/nextjs-monorepo-example | 2865 | 4 | 4 |
+--------------------------------------+--------------+----------+---------+
3 rows in set (0.03 sec)
使用限制和最佳实践
使用VARIANT类型有几个限制:VARIANT的动态列几乎和预定义的静态列一样高效。当处理像日志这样的数据时,字段通常是动态添加的(比如Kubernetes中的容器标签),解析JSON和推断类型会在写操作期间产生额外的成本。因此,建议将单个导入的列数控制在1000列以下。
尽可能确保类型的一致性。Doris自动执行兼容的类型转换。当一个字段不能进行兼容类型转换时,将其统一转换为JSONB类型。与int或text等列相比,JSONB列的性能可能会下降。
- tinyint -> smallint -> int -> bigint,整数类型可以按照箭头方向提升。
- Float -> double,浮点数可以按照箭头方向提升。
- text, string type.
- JSON, binary JSON type.
当上述类型不能兼容时,将其转换为JSON类型,以防止类型信息的丢失。如果您需要在VARIANT中设置严格的模式,稍后将引入VARIANT MAPPING机制。
其他限制包括:
VARIANT列只能创建倒排索引或bloom过滤器来加快查询速度。- 为了提高写性能,建议使用
RANDOM模式或组提交模式。 - 非标准JSON类型,如日期和十进制,理想情况下应该使用静态类型以获得更好的性能,因为这些类型被推断为文本类型
- 维度为2或更高的数组将存储为
JSONB编码,这可能比本地数组执行效率低。 - 不支持作为主键或排序键。
- 带有过滤器或聚合的查询需要强制转换。存储层消除了基于存储类型和强制转换的目标类型的强制转换操作,从而加快了查询速度。
11、IPV4
描述
IPv4类型,以4字节的UInt32形式存储,用于表示IPv4地址。取值范围为['0.0.0.0','255.255.255.255']。
超出值范围或格式无效的输入将返回NULL
example
创建表示例:
CREATE TABLE ipv4_test (
`id` int,
`ip_v4` ipv4
) ENGINE=OLAP
DISTRIBUTED BY HASH(`id`) BUCKETS 4
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
插入数据示例:
insert into ipv4_test values(1, '0.0.0.0');
insert into ipv4_test values(2, '127.0.0.1');
insert into ipv4_test values(3, '59.50.185.152');
insert into ipv4_test values(4, '255.255.255.255');
insert into ipv4_test values(5, '255.255.255.256'); // invalid data
选择数据示例:
mysql> select * from ipv4_test order by id;
+------+-----------------+
| id | ip_v4 |
+------+-----------------+
| 1 | 0.0.0.0 |
| 2 | 127.0.0.1 |
| 3 | 59.50.185.152 |
| 4 | 255.255.255.255 |
| 5 | NULL |
+------+-----------------+
12、IPV6
描述
IPv6类型,以UInt128格式存储,16字节,用于表示IPv6地址。取值范围为['::','ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffff']。
超出值范围或格式无效的输入将返回NULL
example
创建表示例:
CREATE TABLE ipv6_test (
`id` int,
`ip_v6` ipv6
) ENGINE=OLAP
DISTRIBUTED BY HASH(`id`) BUCKETS 4
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
插入数据示例:
insert into ipv6_test values(1, '::');
insert into ipv6_test values(2, '2001:16a0:2:200a::2');
insert into ipv6_test values(3, 'ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffff');
insert into ipv6_test values(4, 'ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffffg'); // invalid data
查询数据示例:
mysql> select * from ipv6_test order by id;
+------+-----------------------------------------+
| id | ip_v6 |
+------+-----------------------------------------+
| 1 | :: |
| 2 | 2001:16a0:2:200a::2 |
| 3 | ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffff |
| 4 | NULL |
+------+-----------------------------------------+