序列是一种数据存储方式 , 用来存储一系列的数据 .
在内存中 , 序列使用连续的内存空间用来存放多个值 .
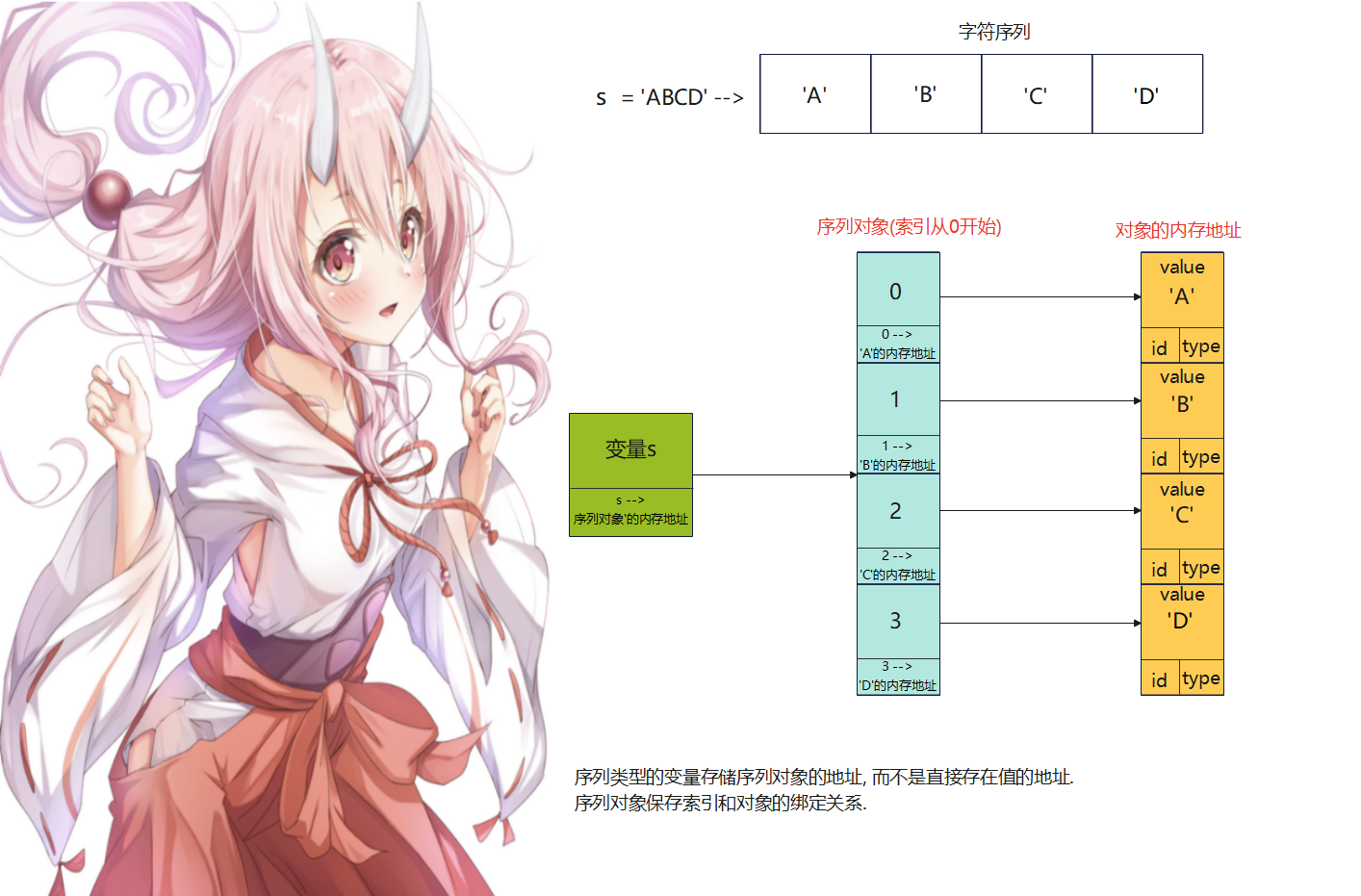
序列类型的变量存储序列对象的地址 , 而不是直接存在值的地址 .
序列对象保存索引和对象的绑定关系 .
s = 'ABCD'
print ( id ( s) , type ( s) , s)
print ( id ( s[ 0 ] ) , type ( s[ 0 ] ) , s[ 0 ] )
print ( id ( s[ 1 ] ) , type ( s[ 1 ] ) , s[ 1 ] )
print ( id ( s[ 2 ] ) , type ( s[ 2 ] ) , s[ 2 ] )
print ( id ( s[ 3 ] ) , type ( s[ 3 ] ) , s[ 3 ] )
特征 : 使用引号引起来的字符称为字符串 , 字符串可以是中文 , 英文 , 数字 , 符号等混合组成 .
Python 中可以使用的引号 :
* 1. 单引号 'x'
* 2. 双引号 "x"
* 3. 三单引号 '' 'x' ''
* 4. 三双引号 "" "x" ""
str1 = 'x'
str2 = "x"
str3 = '''x'''
str4 = """x"""
print ( str1, str2, str3, str4, type ( str1) )
反斜杠在字符串中有两个作用 :
* 1. 换行 , 使用反斜杠对字符串的内存进行换行 , 把字符串分割成多行 .
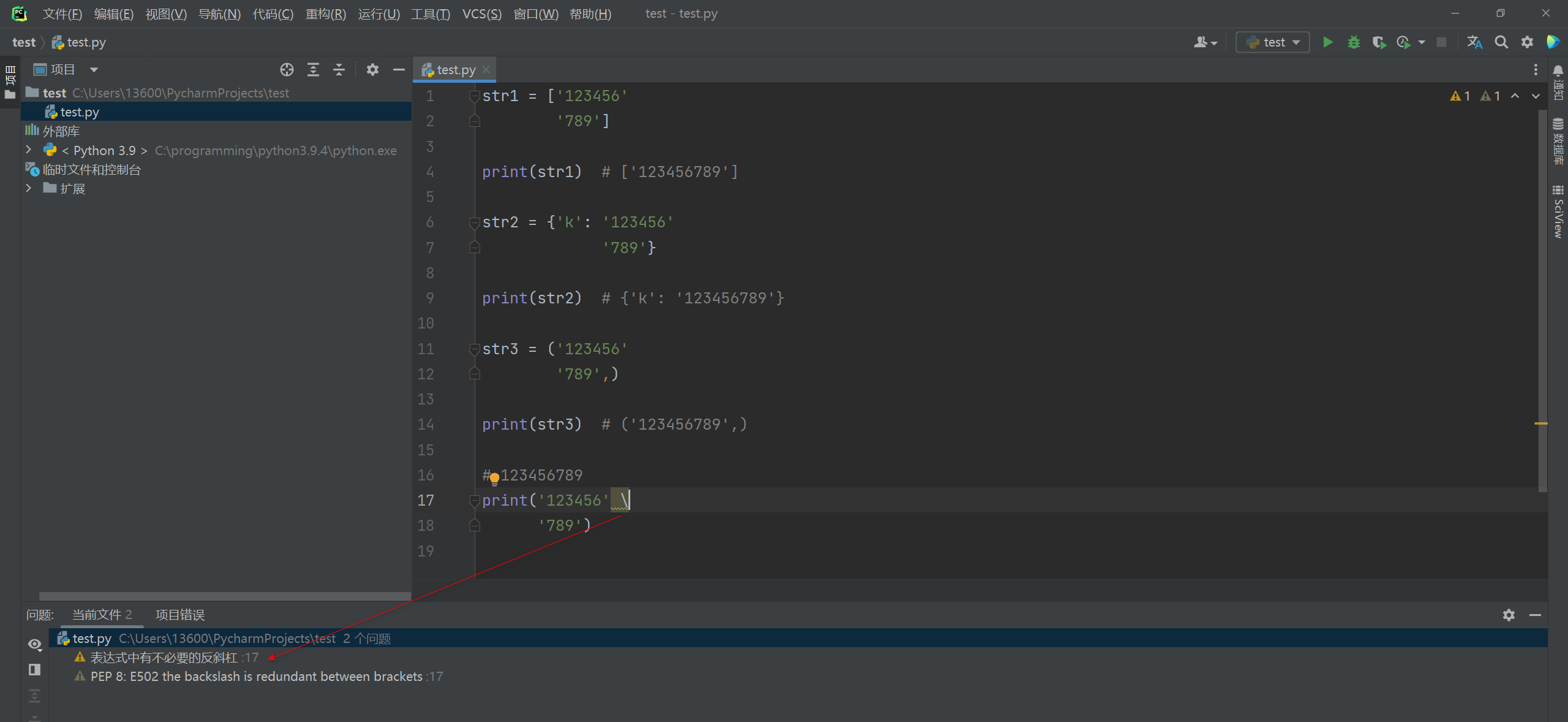
在每行的末尾使用 , 在处于括号 ( ) , 中括号 [ ] , 花括号 { } 中是反斜杠是可以省略的 .
* 2. 转义 , 反引号与某个字符组合成转义字符 .
编辑界面中一行无法写完一句话 , 可以采用分行书写 , 代码看上去也整洁 .
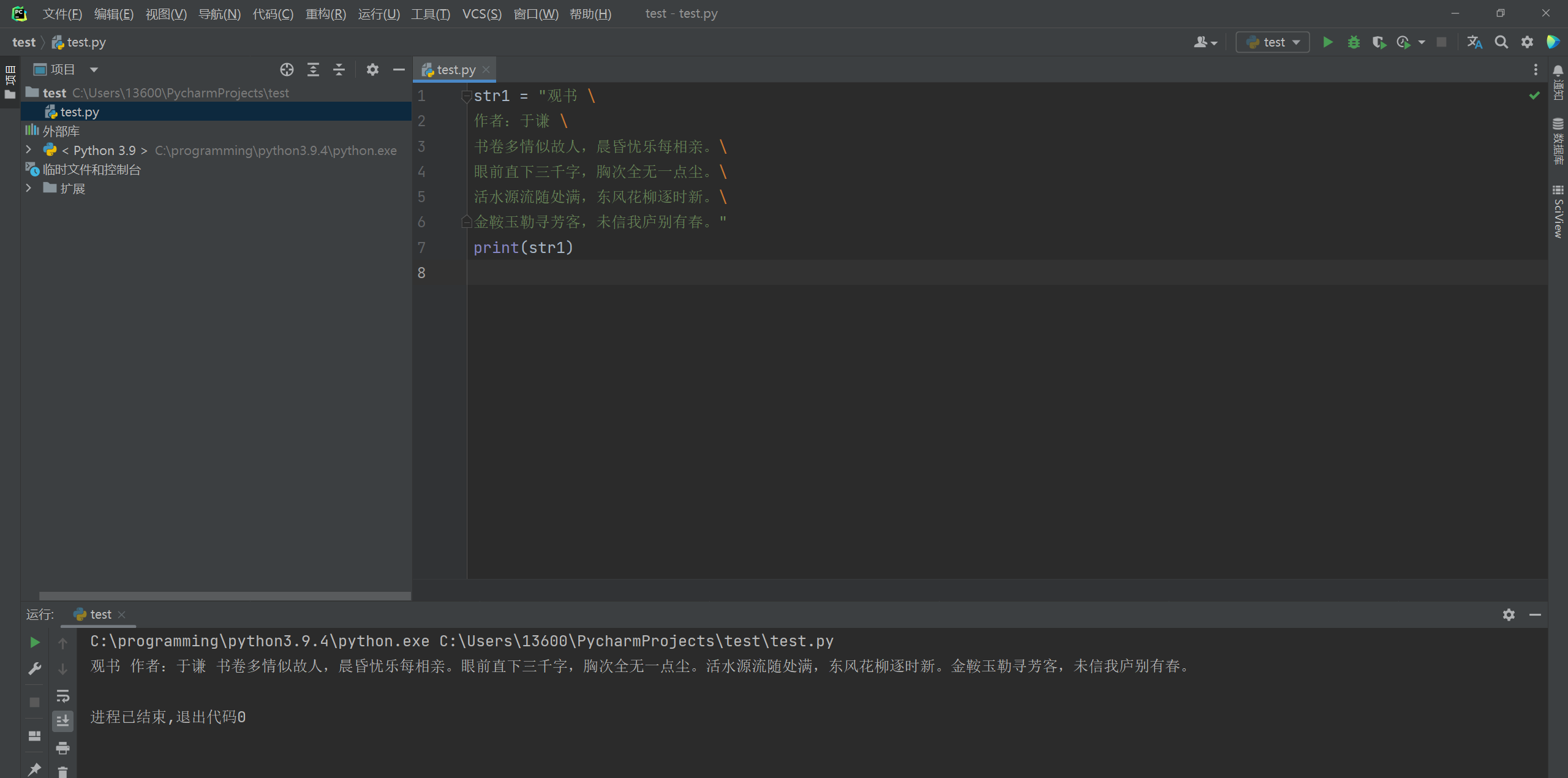
用 \ 斜杠 续行符 , 在下一行继续书写字符串 , 按一个段落输出 .
* 在跨行书写的时候不能在续行符后加 # 号注释 .
str1 = "观书 \
作者:于谦 \
书卷多情似故人, 晨昏忧乐每相亲。\
眼前直下三千字, 胸次全无一点尘。\
活水源流随处满, 东风花柳逐时新。\
金鞍玉勒寻芳客, 未信我庐别有春。"
print ( str1)
在处于括号 ( ) , 中括号 [ ] , 花括号 { } 中是反斜杠是可以省略的 .
如果不省略会提示PEP8规范问题 .
PEP 8 : E502 the backslash is redundant between brackets .
str1 = [ '123456'
'789' ]
print ( str1)
str2 = { 'k' : '123456'
'789' }
print ( str2)
str3 = ( '123456'
'789' , )
print ( str3)
print ( '123456' \
'789' )
转义字符 ( Escape character ) : 定义一些字母前加 " \ " 来表示特殊的含义 , 如 : \ n表示换行 .
转义字符 意义 ASCII码值(十进制) \a 响铃(BEL), 不是喇叭响, 蜂鸣器响, 现在的计算机没了. 007 \b 退格(BS) , 将当前位置移到前一列 008 \f 换页(FF), 将当前位置移到下页开头 012 \n 换行(LF) , 将当前位置移到下一行开头 010 \r 回车(CR) , 将当前位置移到本行开头 013 \t 水平制表(HT) (跳到下一个TAB位置) 009 \v 垂直制表(VT) 011 \\ 代表一个反斜线字符’ 092 \’ 代表一个单引号字符 039 \" 代表一个双引号字符 034 ? 代表一个问号 063 \0 空字符(NUL) 000 \o 英文o, 以\o开头表示八进制 \x 以\x开头表示十六进制
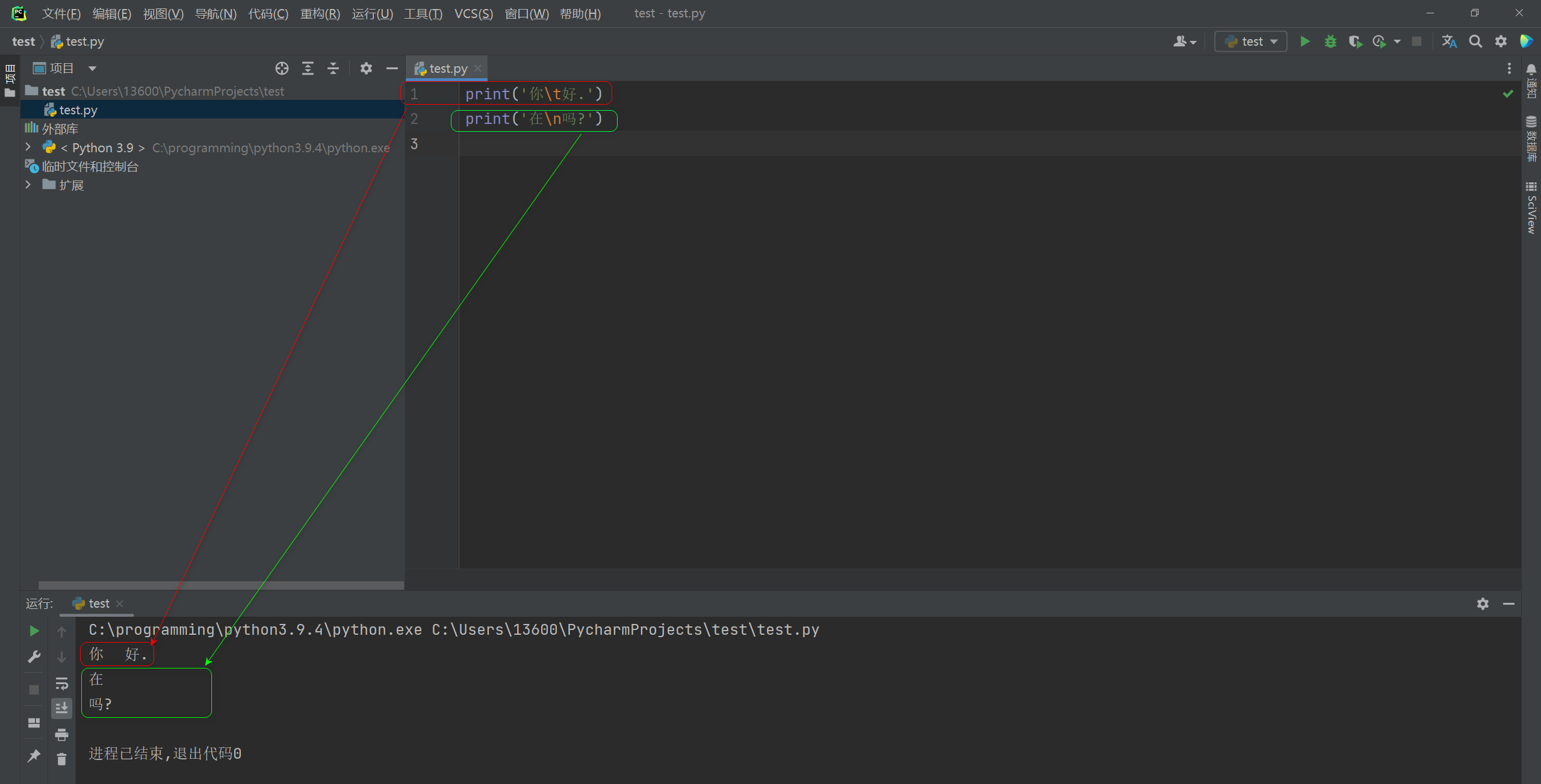
print ( '你\t好.' )
print ( '在\n吗?' )
运行工具窗口显示 :
你 好 .
在
吗?
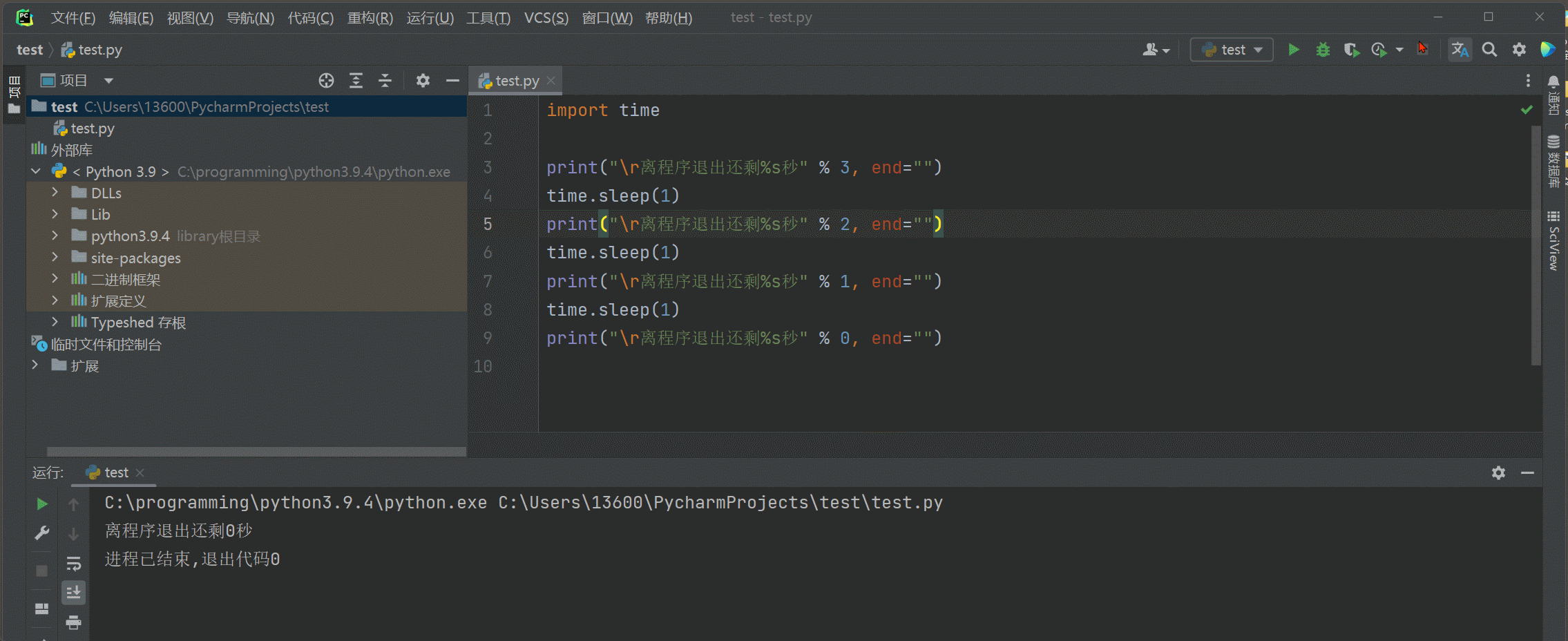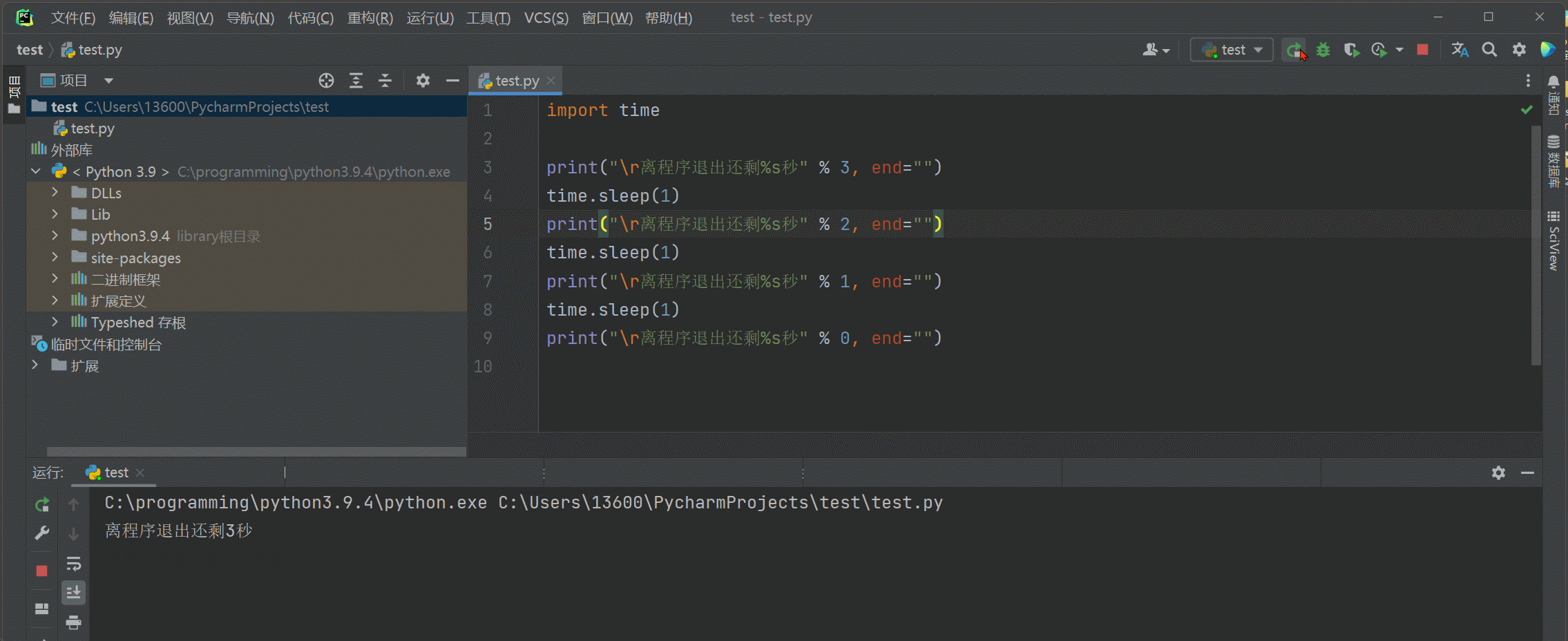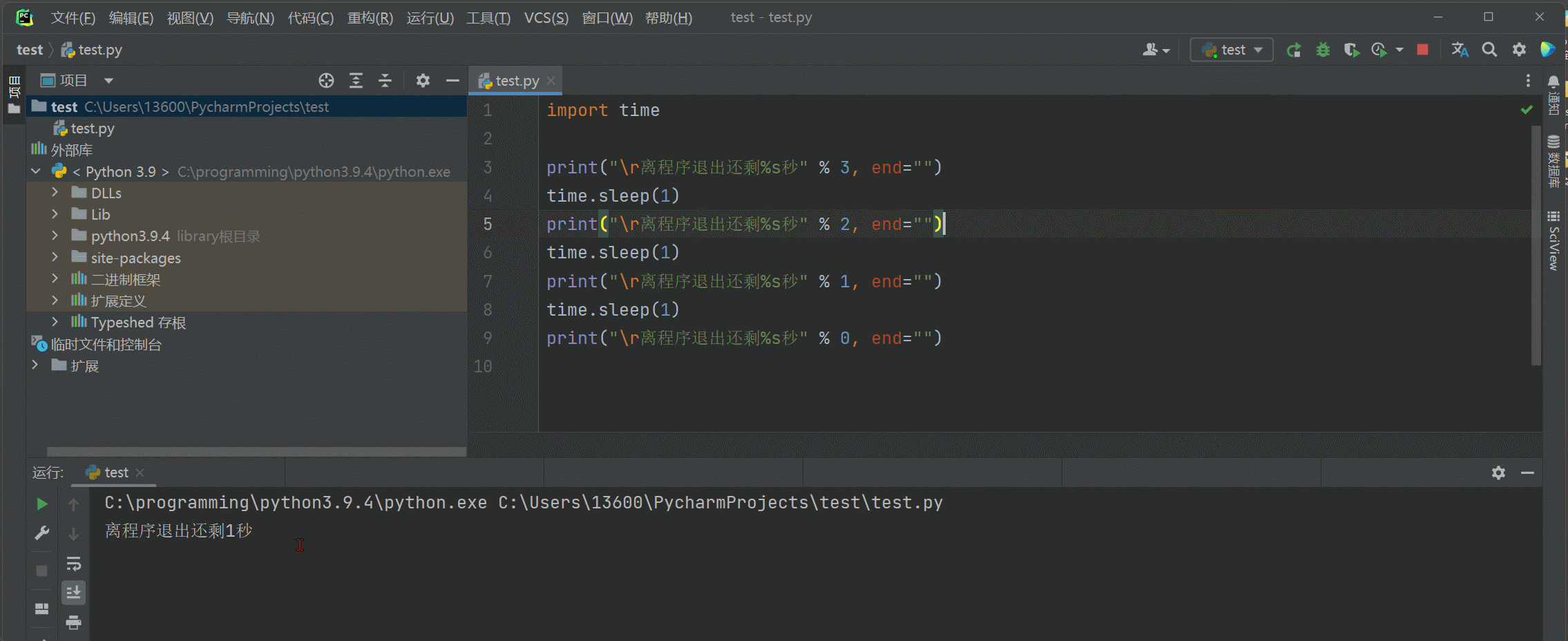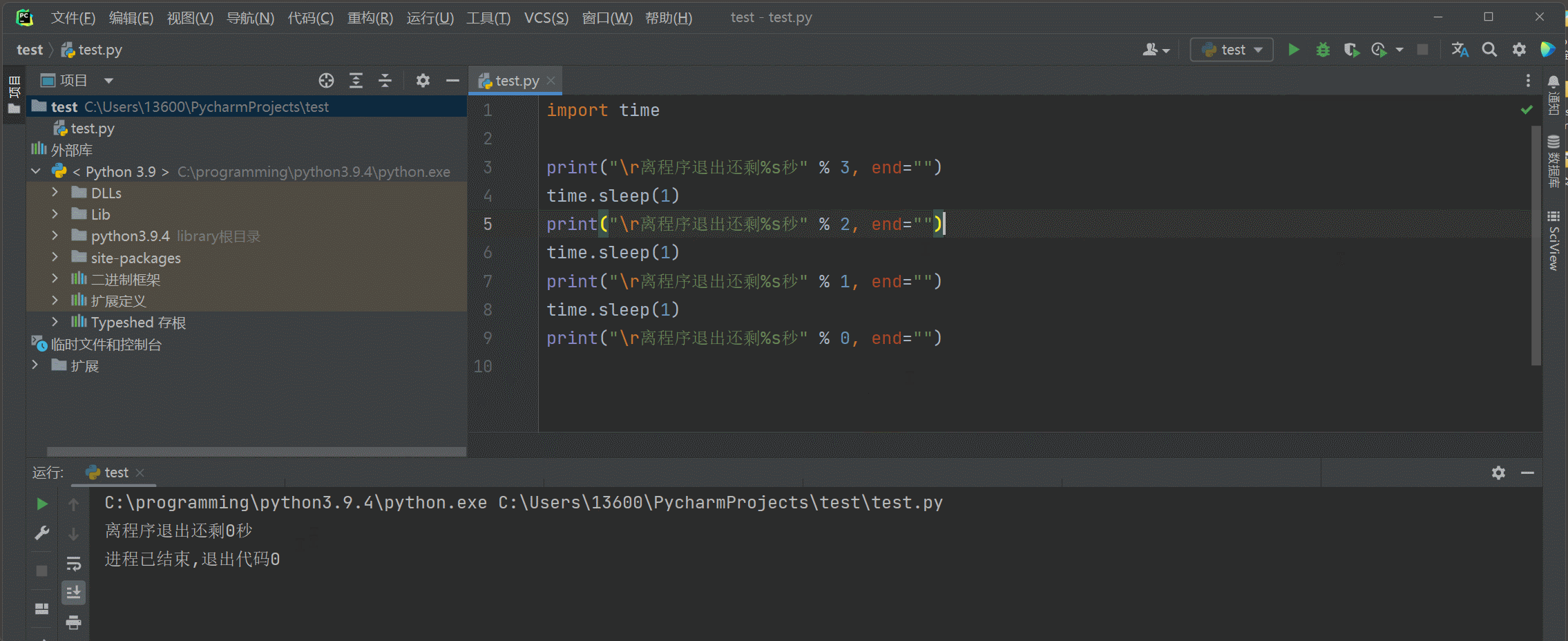
覆盖打印 : 打印一次 , 延时 1 秒 , 在打印 ,
sed = "" 设置print不换行打印 .
\ r将光标位置移到本行开头 , 再次打印的话将上次的内容覆盖 .
time . sleep ( 1 ) 延时一秒 .
import time
print ( "\r离程序退出还剩%s秒" % 3 , end= "" )
time. sleep( 1 )
print ( "\r离程序退出还剩%s秒" % 2 , end= "" )
time. sleep( 1 )
print ( "\r离程序退出还剩%s秒" % 1 , end= "" )
time. sleep( 1 )
print ( "\r离程序退出还剩%s秒" % 0 , end= "" )
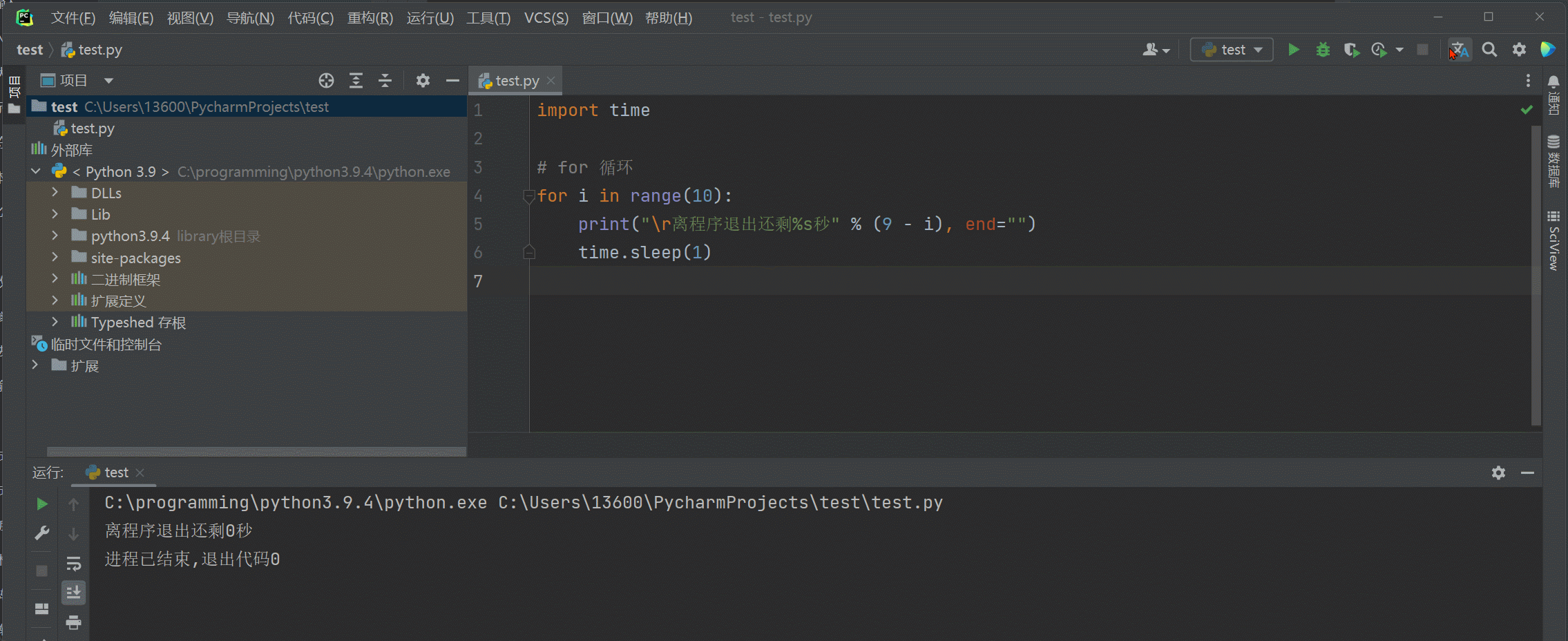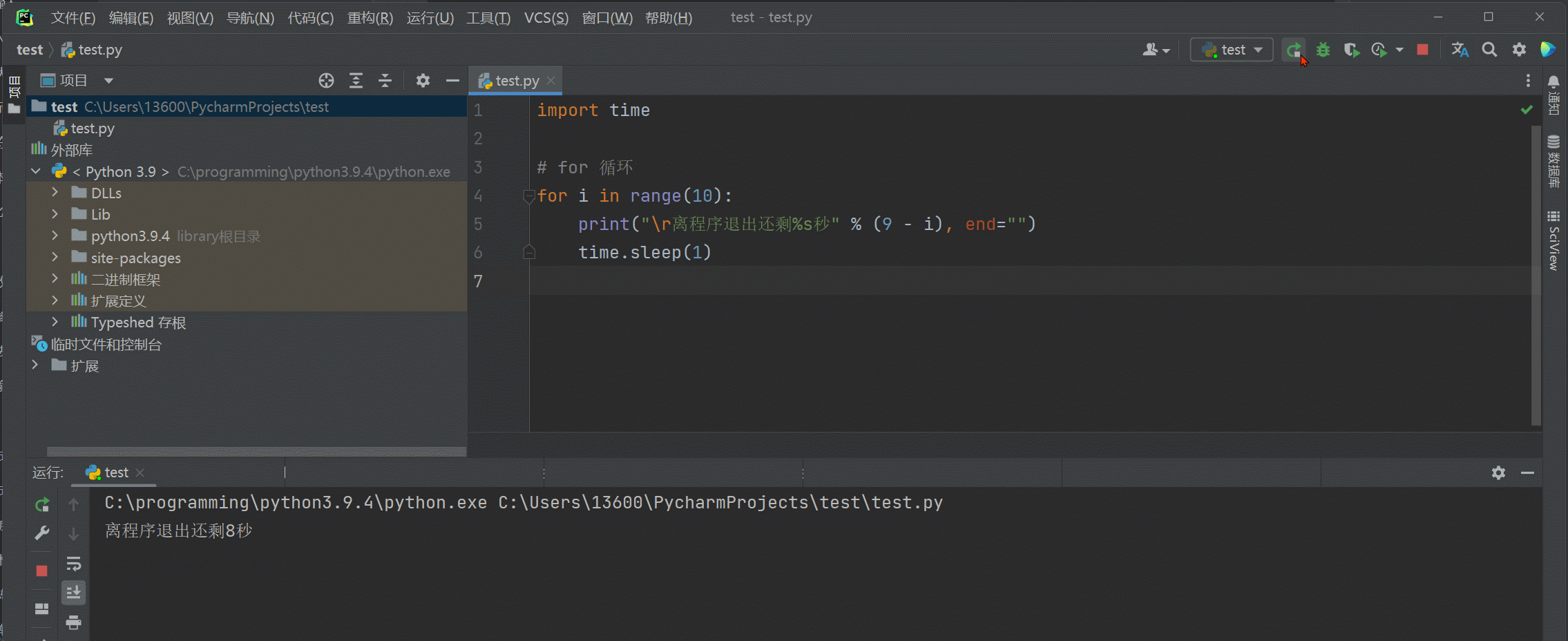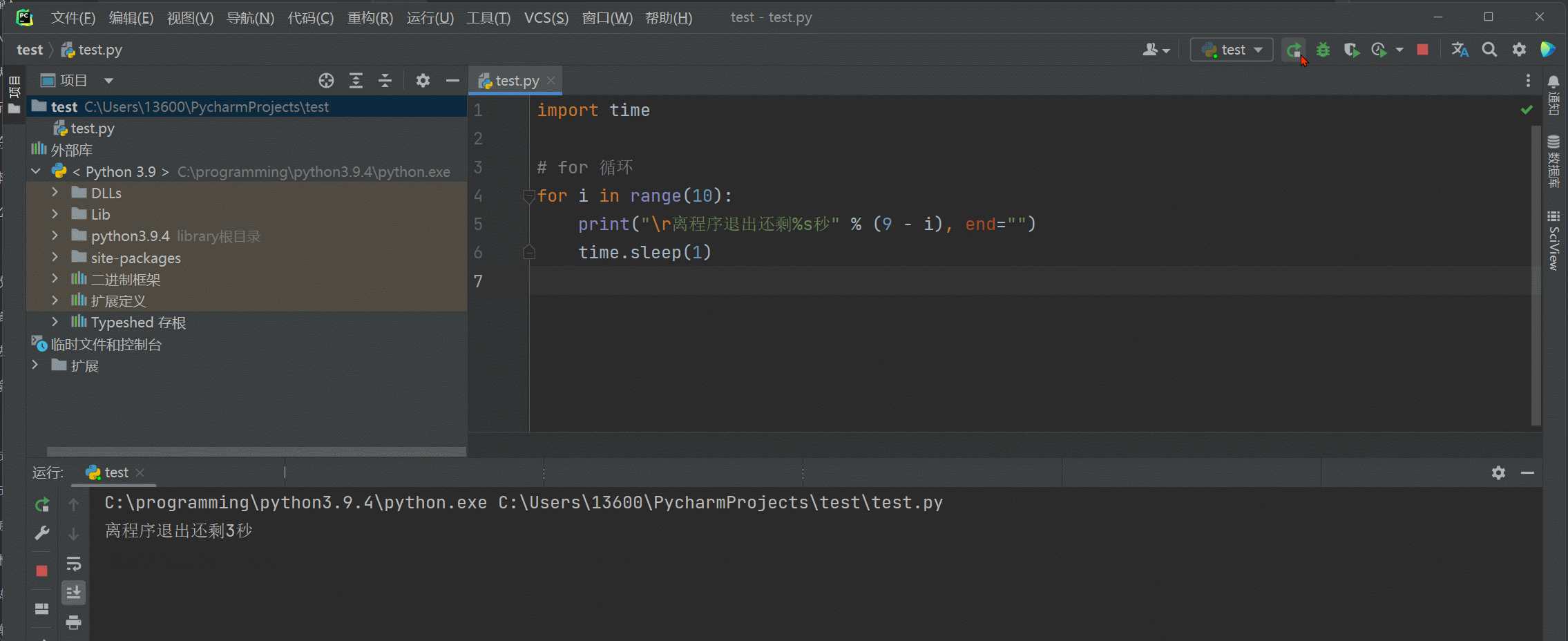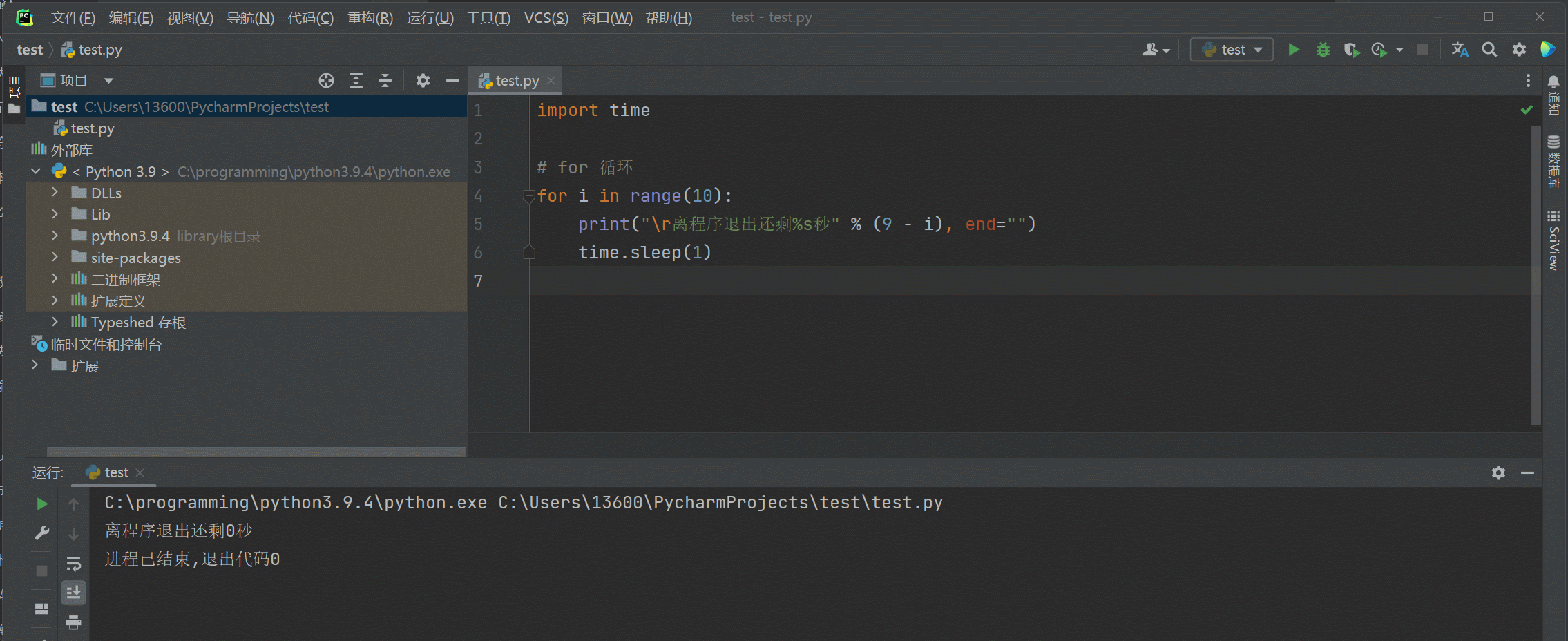
import time
for i in range ( 10 ) :
print ( "\r离程序退出还剩%s秒" % ( 9 - i) , end= "" )
time. sleep( 1 )
字符串以某种引号开始 , 在往后再遇到自己就会中断 .
Pychon解释器在解释时会报错 .
str1 = "有人说:" 这个世界上他是最厉害了!" "
print ( str1)
运行工具窗口显示 :
File "C:\Users\13600\PycharmProjects\test\test.py" , line 2
str1 = "有人说:" 这个他是最厉害了 ! " "
^
语法错误:无效语法
SyntaxError : invalid syntax
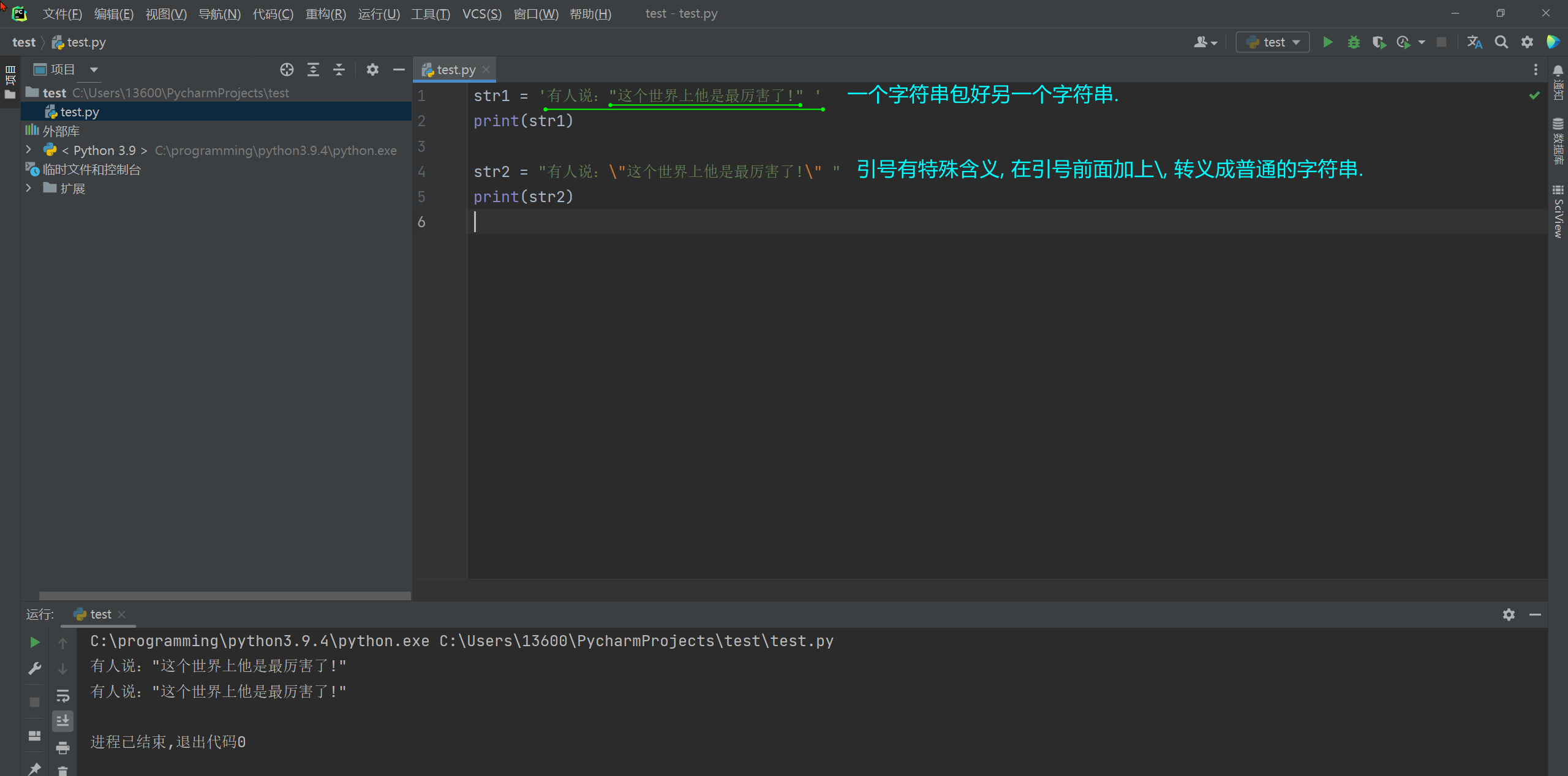
解决方法 :
* 1. 在字符串中使用引号 , 外层需要用不同类型的引号 .
* 2. 使用转义字符 .
str1 = '有人说:"这个世界上他是最厉害了!" '
print ( str1)
str2 = "有人说:\"这个世界上他是最厉害了!\" "
print ( str2)
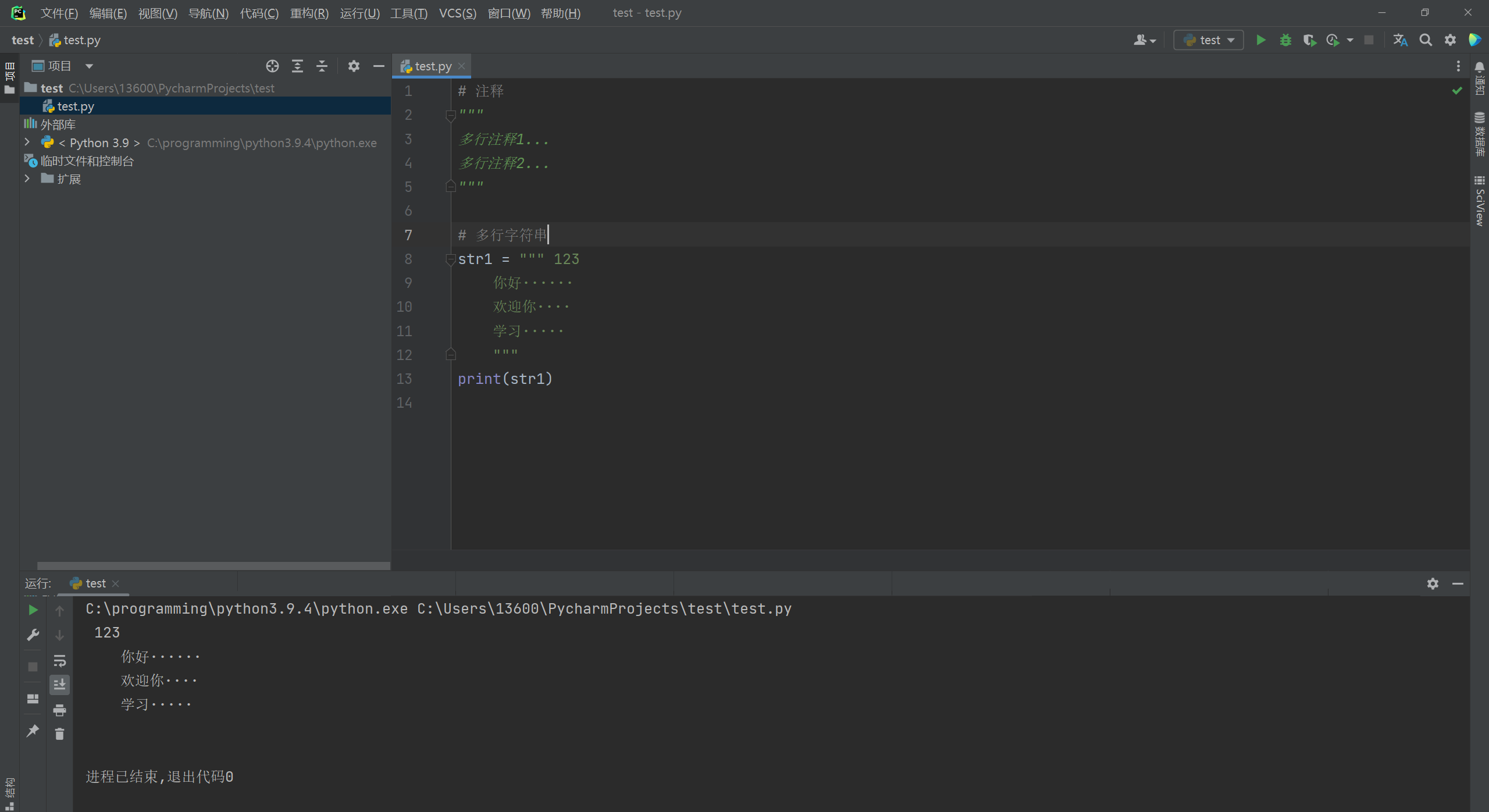
三引号引起来的字符 , 当它的左边有赋值符号的时候是一个字符串对象 ,
按书写时的样式原样输出 , 书写几行就是以行行显示 .
很多人将没有赋值的多行语句当做是 '注释语句' .
三引号在定义函数内顶行书写时是块注释 ,
对一块代码的作用或整个程序文件的功能进行说明与解释 .
"""
多行注释1...
多行注释2...
"""
str1 = """ 123
你好······
欢迎你····
学习·····
"""
print ( str1)
Python中使用三引号可以进行多行注释 , 这种注释也被称为文档字符串 ( docstring ) ,
它可以用来描述模块、类或函数的作用、参数、返回值等详细信息 .
虽然文档字符串会被存储在内存中 ,
但它们通常只占用很小的空间 , 并不会对程序的性能和内存使用造成显著的影响 .
例如 , 以下代码中的文档字符串不会占用太多的内存 :
add( x, y) :
"""
此函数用于添加两个数字。
参数:
x(int): 第一个数字.
y(int): 第二个数字.
返回:
int: x和y的和.
"""
return x + y
虽然文档字符串会占用一些内存 , 但它们对于代码的可读性和可维护性非常重要 ,
因此应该在适当的位置添加文档字符串 .
使用三引号来创建注释或多行字符串时 , 这些字符串实际上会被当作常量处理 , 并被存储在内存中 .
在函数外定义的字符串常量会一直存在于程序运行期间 ( 函数内 , 函数结束销毁 ) , 因此会占用一定的内存 .
通常情况下 , 注释所占用的内存非常小 , 并且在运行程序时不会影响程序的性能 .
因此 , 除非你需要定义非常大的注释或字符串常量 , 否则不需要担心它们会对程序的性能产生任何影响 .
在Python中 , 当一个对象不再被任何变量引用时 , 它就会变成垃圾 , Python的垃圾回收机制会将其回收 .
Python中的垃圾回收机制使用引用计数和循环垃圾收集两种方式来判断对象是否可以被回收。
对于字面常量这样的不可变对象 , 如果没有任何变量引用它们 , 那么它们就会被判定为可以被回收 ,
Python的垃圾回收机制会在适当的时候回收它们 .
字符串中 , 反斜杠 ' \ ' 有着转义功能 , 某个情况出现的下转义让解释器无法解析 , 从而导致程序异常 .
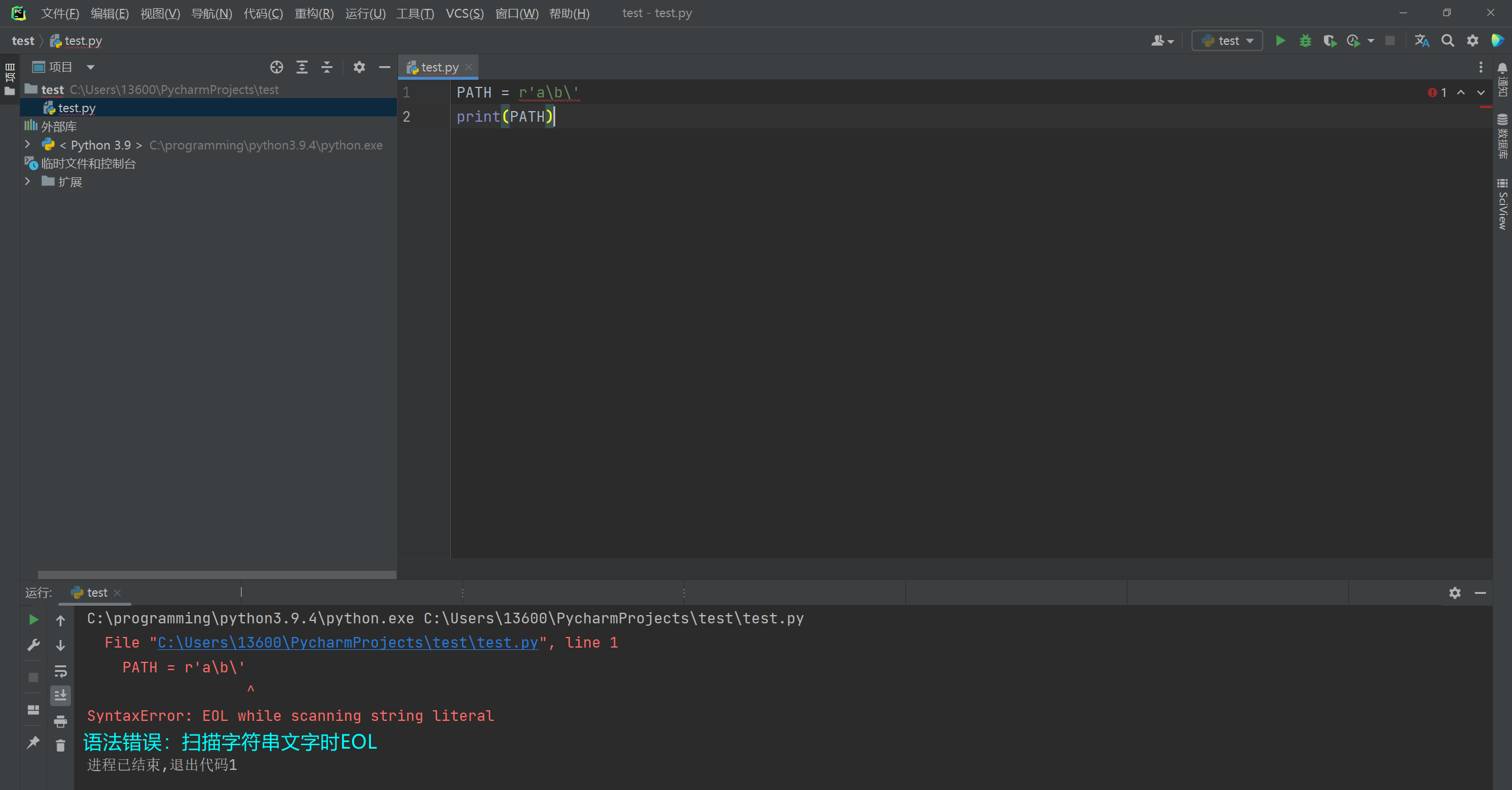
在字符串前面添加字母r , 转为原始字符串 , 原始字符串让字符串原样输出 . 取消掉部分部分 ' \ ' 的转义功能 .
* 原始字符串末尾也不能带奇数个反斜杠 , 因为这会引起后续引号的转义!
正确的样式 : r 'a\b\c'
错确的样式 : r ' a \ b \ ' -- > SyntaxError : EOL while scanning string literal
PATH = r'a\b\c'
print ( PATH)
PATH = r'a\b\'
print ( PATH)
运行工具窗口显示 :
File "C:\Users\13600\PycharmProjects\test\test.py" , line 1
PATH = r ' a \ b \ '
^
# 语法错误:扫描字符串文字时EOL
SyntaxError : EOL while scanning string literal
Python2中字符串使用的是ascii编码 , 可以用前缀u '' 表示Unicode的字符串 .
Python3中字符串是Unicode字符串 , 后续会详细说明 .
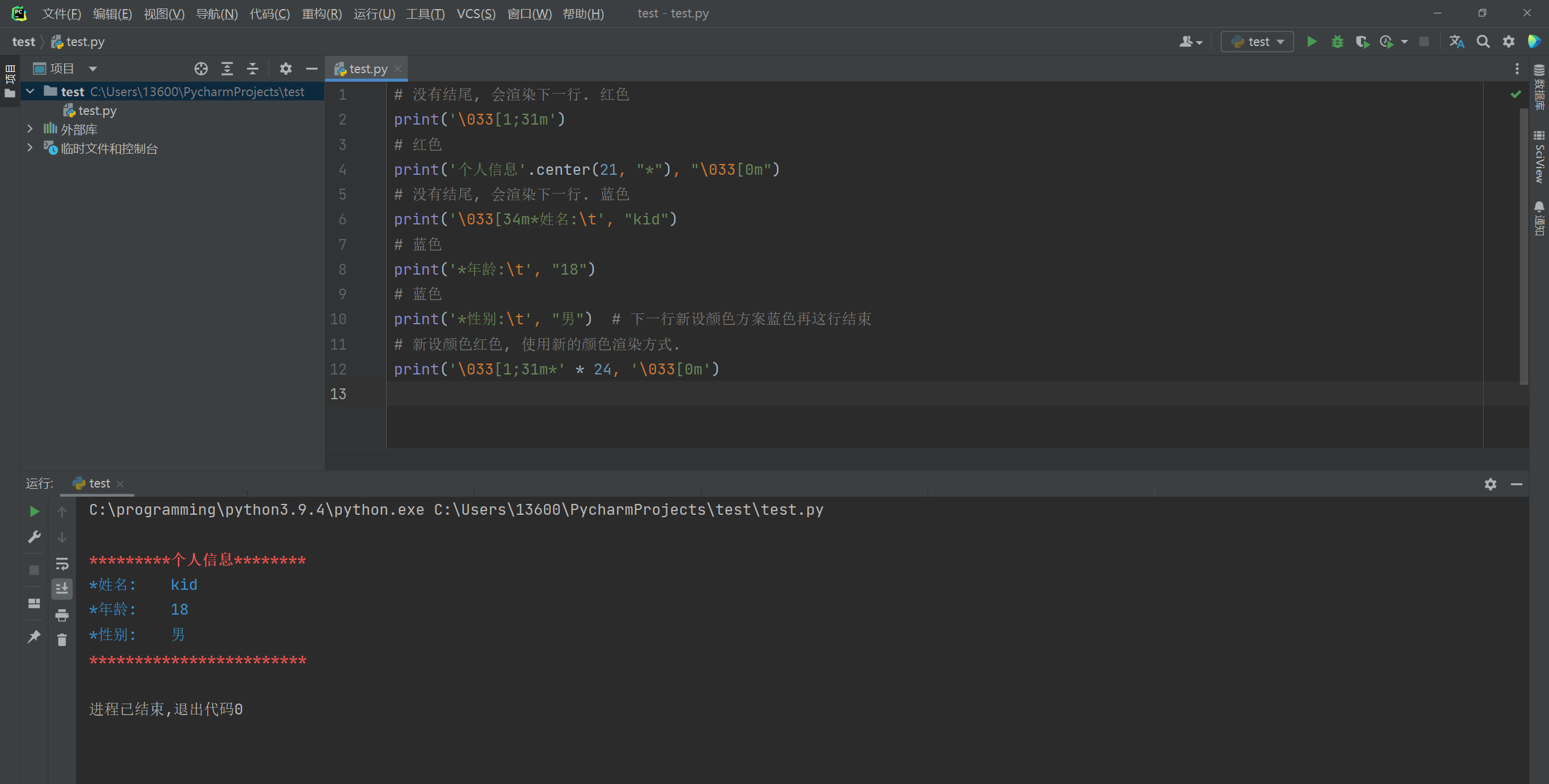
对终端输出的字符串设置颜色 , 颜色是用转义序列控制的 , 转义序列是以ESC开头 ,
在代码中用 \ 033 表示 ( ESC的ASCII码用十进制表示就是 27 , 等于用八进制表示的 33 , \ 0 表示八进制 ) .
格式 : \ 033 [ 显示方式 ; 前景色 ; 背景色m正文 \ 033 [ 0 m
显示方式 意义 0 终端默认设置 1 高亮显示 4 使用下划线 5 闪烁 7 反白显示 8 不可见
前景色 背景色 颜色 30 40 黑色 31 41 红色 32 42 绿色 33 43 黃色 34 44 蓝色 35 45 紫红色 36 46 青蓝色 37 47 白色
print ( '\033[1;31m' )
print ( '个人信息' . center( 21 , "*" ) , "\033[0m" )
print ( '\033[34m*姓名:\t' , "kid" )
print ( '*年龄:\t' , "18" )
print ( '*性别:\t' , "男" )
print ( '\033[1;31m*' * 24 , '\033[0m' )
Python内置str ( ) 函数 : 将括号内的数据转为字符串类型数据 . 任意类型的数据都可以被转为字符串 .
str1 = str ( 'abc' )
print ( str1, type ( str1) )
print ( str ( 123 ) )
print ( str ( 123.4 ) )
print ( str ( [ 1 , 2 , 3 ] ) )
print ( str ( ( 'hello' , ) ) )
print ( str ( { 'a' : 123 , 'b' : 456 } ) )
字符串的本质是字符序列 , 可以在字符串的后面添加中括号 [ 索引值 ] 的方式取该位置的单个字符 .
索引取值 : 取一个元素 .
字符串中每个字符占一个索引 , 索引从 0 开始 .
切片取值 : 取多个元素 .
取值格式 : 字符串 [ start: stop: step ] start 起始值参数 : 起始位置 , 从第几位开始取值 .
stop 上限值参数 : 上限的位置 , 只能获取到它的前一索引的值 , 不包含它本身 .
step 步长参数 : 从左往右正向取值 , 步长是负数从右往左反向取值 ( start与stop参数对换 ) .
省略索引 :
省略第一个参数 : 默认参数为 0 , 从索引 0 开始截取 .
省略第二个参数 : 默认惨为列表的长度 , 意味着切片直至列表的末尾 .
省略第三个参数 : 默认为 1 , 从左往右正向取值 .
str1 = '0123456789'
print ( str1[ 0 ] )
print ( str1[ 0 : 9 ] )
print ( str1[ 0 : 30 ] )
print ( str1[ 0 : ] )
print ( str1[ : 9 ] )
print ( str1[ - 10 : - 1 ] )
print ( str1[ 0 : - 1 ] )
print ( str1[ - 30 : - 1 ] )
print ( str1[ - 1 : - 11 : - 1 ] )
print ( str1[ : : - 1 ] )
for循环语句可以依次获取字符串中的单个字符 .
str1 = '0123456789'
for i in str1:
print ( i, end= '--' )
运行工具窗口提示 :
0 -- 1 -- 2 -- 3 -- 4 -- 5 -- 6 -- 7 -- 8 -- 9 --
Python内置len ( ) 函数 : 统计序列类型的元素个数 .
str1 = '0123456789'
print ( len ( str1) )
符号 作用 示例 + 加号 拼接字符串. ‘a’ + ‘b’ = ‘ab’ * 乘号 复制字符串. ‘a’ * 3 = ‘aaa’
Python属于强类型语言 , 不能类型的数据是无法互相操作的 .
Python中为了方便程序员的使用 :
使用 + 号 , 让字符串与整型将加时 , 使其不再表示加法 , 而是拼接字符串 .
使用 * 号 , 让字符串与整型将乘时 , 使其不再表示乘法 , 而是重复n次 .
str1 = 'abc'
print ( str1 + 'def' )
str1 += 'def'
print ( str1)
Python中字符串的拼接使用 '+' 的效率很低问题 .
问题阐述 : 假如现在有两个字符串 'Python' 和 'Ruby' , 需要将这两个字符串连接起来 ,
在Java或者C # 中都可以通过使用 '+' 操作符将两个字符串连接一起 , 得到一个新的字符串 'PythonRuby' .
当然 , Python中同样提供了利用 '+' 操作符连接字符串的功能 , 然而很不幸的是 , 这样的做法正是万恶之源 .
* PyStringObject 是Python的C源码中的字符串对象 .
'+' 低效的原因 : Python中通过 '+' 进行字符串连接的方法效率极其低下 ,
其根源在于Python中的PyStringObject对象是一个不可变对象 .
当任意两个PyStringObject对象的连接时都会进行一次内存申请的动作 .
这就意味着当进行字符串连接时 , 实际上是必须要创建一个新的PyStringObject对象 .
这样 , 如果要连接N个PyStringObject对象 , 那么就必须进行 N- 1 次的内存申请及内存搬运的工作 .
毫无疑问 , 这将严重影响Python的执行效率 .
官方推荐 : 做法是通过利用PyStringObject对象的join操作来对存储在
list或者tuple中的一组PyStringObject对象进行连接操作 ,
这种做法只需要分配一次内存 , 执行效率将大大提高 .
join执行过程 : 执行join操作时 , 会首先统计出在list中一共有多少个PyStringObject对象 ,
并统计这些PyStringObject对象所维护的字符串一共有多长 ,
然后申请内存 , 将list中所有的PyStringObject对象维护的字符串都拷贝到新开辟的内存空间中 .
注意 : 这里只进行了一次内存空间的申请 , 就完成了N个PyStringObject对象的连接操作 .
相比于 '+' 操作符 , 待连接的PyStringObject对象越多 , 效率的提升也会越明显 .
from time import time
count = 1000000
str1 = ''
old_time = time( )
for i in range ( count) :
str1 += 'hello'
new_time = time( )
print ( f'消耗时间 { new_time - old_time} ' )
list1 = [ ]
old_time = time( )
for i in range ( count) :
list1. append( 'hello' )
'' . join( list1)
new_time = time( )
print ( f'消耗时间 { new_time - old_time} ' )
使用字符串拼接符 + , 会生成新的字符串对象 , 因此不推荐使用 + 来拼接字符 .
join方法在拼接字符串前会极端所有的字符串长度 , 然后逐一拷贝 , 仅创建一次对象 .
str1 = 'abc'
print ( str1 * 2 )
str1 *= 2
print ( str1)
涉及字符串的比较 , 会将字符转为Unicode编码表对应的十进制数来比较 .
常用字符的编码与十进制对象关系 :
字符 | 十进制
0 - 9 : 30 - 39
A-Z : 65 - 90
a-z : 95 - 122
str1 = 'ABC'
str2 = 'ABD'
print ( str1 > str2)
print ( str1 < str2)
str1 = 'a'
str2 = 'b'
print ( str1 > str2)
input_str = input ( '输入字符串>>>:' )
print ( str1 == input_str)
print ( str1 is input_str)
in 判断某个个体是否在某个群体当中 , 返回布尔值 .
not in 判断某个个体是否不在某个群体当中 , 返回布尔值 .
str1 = '0123456789'
print ( '0' in str1)
print ( '0' not in str1)
* 字符串属于不可变类型 , 不可变类型的方法不会修改原值 , 而是得到一个新值 , 可以使用变量接收 .
. join ( 可迭代对象 ) 方法 : 适用于列表中的字符串元素相加 , 拼接的列表中存在不是字符串的元素会报错 .
str1 = 'abc'
str2 = 'def'
list1 = [ str1, str2]
print ( '' . join( list1) )
print ( '-' . join( list1) )
. format ( ) 方法 : Python官方推荐的使用的格式化输入 .
. format ( ) 方法使用 { } 占位 , . format ( ) 方法可以接送任意类型参数 , 参数不能是变量 .
使用方式一 : { } 默认按传递的参数依次获取值 .
使用方式二: { } 中写索引 , 可以对参数进行多次调用 . 索引是来源于format ( ) 的参数 .
使用方式三 : { } 中写上变量名 , . format ( ) 以关键字参数 变量名 = xxx 传参 .
* { } 内不可是的位置参数不能是变量 .
print ( '今天星期{}, 天气{}, 温度{}℃!' . format ( '一' , '晴' , 28 ) )
print ( '现在时间是: {0}点{0}分{0}秒.'
'距离下班时间还有{1}个小时{1}分{1}秒!' . format ( 13 , 1 ) )
print ( '{name}独断万古!' . format ( name= '荒天帝' ) )
name = '王腾'
print ( '吾儿{name}有大帝之姿!' . format ( name= name) )
"""
# 错误使用方法
name ='王腾'
print('吾儿{name}有大帝之姿!'.format(name))
"""
运行工具窗口提示 :
今天星期一 , 天气晴 , 温度 28 ℃!
现在时间是 : 13 点 13 分 13 秒 . 距离下班时间还有 1 个小时 1 分 1 秒!
荒天帝独断万古 !
吾儿王腾有大帝之姿 !
. split ( '字符' ) 方法 : 指定一个字符为分割点进行切分 , 被切分的的字符串会以列表类型存放 .
指定切割的字符不会保留 , 不写默认指定为空字符 , 指定的字符必须存在字符串中 .
切割方向 :
从左往右 . split ( '指定字符' , maxsplit = _ )
从右往左 . rsplit ( '指定字符' , maxsplit = _ )
'' . join ( ) 将列表多个字符串元素拼接成字符串 .
引号内指定一个拼接符号 , 引号内默认不写则不使用分隔符 .
split 切分 , join还原 .
str1 = 'abc and acg adf'
print ( str1. split( ) )
str1 = '1 | 2 | 3| 4 | 5'
print ( str1. split( '|' ) )
print ( str1. split( '|' , maxsplit= 1 ) )
print ( str1. split( '|' , maxsplit= 2 ) )
print ( str1. rsplit( '|' , maxsplit= 1 ) )
print ( str1. rsplit( '|' , maxsplit= 2 ) )
list1 = [ '1 ' , ' 2 ' , ' 3' , ' 4 ' , ' 5' ]
print ( '' . join( list1) )
print ( '|' . join( list1) )
. strip ( ) 方法 : 移除指定的首尾字符 , 字符是一样的会连续删除 .
. lstrip ( ) 方法 : 移除首部 , 指定的的字符 .
. rstrip ( ) 方法 : 移除尾部 , 指定的的字符 .
不写都默认移除空字符 . 需要移除的字符用引号引起来 , 中间的无法移除 .
注意点 :
aipoo移除 'ao' : ao 中的字符是每个字符依次去 aipoo 前后匹配 , 如果存在则移除 .
str1 = ' 01234 56789 '
print ( str1. strip( ) )
str2 = '###123 456@@@'
print ( str2. strip( '#' ) )
print ( str2. strip( '@' ) )
str3 = '###123 4566###'
print ( str3. lstrip( '#' ) )
print ( str3. rstrip( '#' ) )
print ( 'aipoo' . strip( 'aoa' ) )
将纯字母字符转为 大写或者小写 其他的字符原样输出 .
. upper ( ) 方法 : 将字符串中的字母全转为大写 .
. lower ( ) 方法 : 将字符串中的字母全转为小写 .
str1 = 'AbCdEfG'
print ( str1. upper( ) )
print ( str1. lower( ) )
设计一个程序 , 将输入的字母 与 验证码 全转为大写或小写 在做比较 .
code = 'sAD8'
print ( f'xx验证码是: { code} ' )
input_code = input ( '输入验证码>>:' )
if input_code. upper( ) == code. upper( ) :
print ( '验证成功!' )
else :
print ( '验证失败!' )
运行工具窗口提示 :
xx验证码是 : sAD8
输入验证码 > > : ( sad8 )
验证成功 !
. isupper ( '字符串' ) 方法 : 判断字符串中的字母是否为全大写 , 其它字符不会影响判断 .
. islower ( '字符串' ) 方法 : 判断字符串中的字母是否为全小写 , 其它字符不会影响判断 .
* 凡是方法描述信息带判断的 , 返回的结果为布尔值 .
str1 = 'AbCdEfG'
str2 = 'ABC'
str3 = 'abc'
print ( str1. isupper( ) , str1. islower( ) )
print ( str2. isupper( ) , str3. islower( ) )
str4 = 'a我'
print ( str4. islower( ) )
运行工具窗口提示 :
False False
True True
True
. startswith ( '字符串' ) 方法 : 判断字符串是否以某个字符串开头 , 区分大小写 .
. endswith ( '字符串' ) 方法 : 判断字符串是否以某个字符串结尾 , 区分大小写 .
str1 = 'Hello world!'
print ( str1. startswith( 'h' ) )
print ( str1. startswith( 'H' ) )
print ( str1. startswith( 'Hello' ) )
print ( str1. endswith( '!' ) )
运行工具窗口提示 :
False
True
True
True
. replace ( ) 方法 : 将指定字符替换 , 返回一个修改后的对象 .
格式 : . replace ( old , new , count = None )
参数 :
old : 需要替换的字符参数 , 参数必须写 .
new : 替换的字符参数 , 参数必须写 .
count : 替换的次数 , 默认全部替换 .
str1 = 'aaaa aaaa aaaa'
print ( str1. replace( 'a' , 'b' ) )
print ( str1. replace( 'a' , 'b' , 4 ) )
. isdigit ( '字符串' ) 方法判断字符串是否为纯整数字字符串 , 浮点型不行 .
str1 = '123456'
str2 = '12.3'
str3 = 'a123'
str4 = ' 123'
print ( str1. isdigit( ) )
print ( str2. isdigit( ) )
print ( str3. isdigit( ) )
print ( str4. isdigit( ) )
设计一个程序 , 模拟登录 , 密码是 6 位数整型 . 要求用户输入密码 ,
程序对输入进行类型转换 , 对密码进行校验 , 避免字符串转整型报错 .
验证成功退出程序 , 否则要求继续输入 .
* 设计程序的时候先写所条件为 False 的代码块 , 可以提高代码的可读性 .
pwd = 123456
while True :
input_pwd = input ( '输入6位数的密码>>>:' )
if not input_pwd. isdigit( ) :
print ( '密码是纯数字!, 请重新输入!' )
continue
input_pwd = int ( input_pwd)
if input_pwd != pwd:
print ( '密码错误!, 请重新输入!' )
continue
print ( '登录成功!' )
break
运行工具窗口提示 :
输入 6 位数的密码 > > > : ( qwe )
密码是纯数字 ! , 请重新输入 !
输入 6 位数的密码 > > > : ( 123 )
密码错误 ! , 请重新输入 !
输入 6 位数的密码 > > > : ( 123456 )
登录成功 !
. isalpha ( ) 方法 : 判断字符串中是否为纯字母 .
str1 = 'asd123'
str2 = 'asd'
print ( str1. isalpha( ) )
print ( str2. isalpha( ) )
. isalnum ( ) 方法 : 判断字符串中是否只有字母和数字 .
str1 = 'asd123'
str2 = 'asd1.23'
print ( str1. isalnum( ) )
print ( str2. isalnum( ) )
设计一个程序 , 统计下列字符串中的符号 , 除数字和字母都是符号 , 空格也是符号 .
str1 = 'a1sd564ew9r/7wa/*7sd49c8aw4ea1r98""":::~!@#17*/ 29e7w+91w49d '
count = 0
for i in str1:
if not i. isalnum( ) :
count += 1
print ( count)
. title ( ) 方法 : 将字符串中所有单词的首字母转为大写 .
. capitalize ( ) 方法 : 将字符串中第一个单词首字母转为大写 .
str1 = 'my name is kid my age is 18.'
print ( str1. title( ) )
print ( str1. capitalize( ) )
. swapcase ( ) 方法 : 将字符串中的大写字母转为小写 , 将小写字母转为大写 .
str2 = 'AbCd'
print ( str2. swapcase( ) )
. find ( ) 方法 : 从左往右查找指定字符对应的索引 , 找到就返回索引的值 , 如果查找的字符不存在则返回- 1.
. rfind ( ) 方法 : 从右往左查找指定字符对应的索引 , 找到就返回索引的值 , 如果查找的字符不存在则返回- 1.
. index ( ) 方法 : 从左往右查找指定字符对应的索引 , 找到就返回索引的值 , 找不到就报错 .
. rindex ( ) 方法 : 从右往左查找指定字符对应的索引 , 找到就返回索引的值 , 找不到就报错 .
* 提供的参数使一个字符串 , 只对首个字符进行查询 .
str1 = 'My name is kid my age is 18.'
print ( str1. find( 'm' ) )
print ( str1. rfind( 'm' ) )
print ( str1. index( 'm' ) )
print ( str1. rindex( 'm' ) )
. count ( ) 方法 : 统计某个字符组合在字符串中出现的次数 .
str1 = 'My name is kid my age is 18.'
print ( str1. count( 'm' ) )
print ( str1. count( 'my' ) )
. center ( 字符宽度 , '字符' ) 方法 : 指定字符与字符宽度 , 让字符串居中 .
. ljust ( 字符宽度 , '字符' ) 方法 : 指定字符与字符宽度 , 让字符串左对齐 .
. rjust ( 字符宽度 , '字符' ) 方法 : 指定字符与字符宽度 , 让字符串右对齐 .
message = '输出'
print ( message. center( 16 , '-' ) )
print ( message. ljust( 16 , '-' ) )
print ( message. rjust( 16 , '-' ) )
运行工具窗口提示 :
-------输出-------
输出--------------
--------------输出
name = " kiD"
1. 移除 name 变量对应的值两边的空格 , 并输出处理结果
print ( name . strip ( ) )
2. 判断 name 变量对应的值是否以 "ki" 开头 , 并输出结果
print ( name . startswith ( 'ki' ) )
3. 判断 name 变量对应的值是否以 "d" 结尾 , 并输出结果
print ( name . endswith ( 'd' ) )
4. 将 name 变量对应的值中的 “i” 替换为 “p” , 并输出结果
print ( name . replace ( 'i' , 'p' ) )
5. 将 name 变量对应的值根据 “i” 分割 , 并输出结果 .
print ( name . split ( 'i' ) )
6. 将 name 变量对应的值变大写 , 并输出结果
print ( name . upper ( ) )
7. 将 name 变量对应的值变小写 , 并输出结果
print ( name . lower ( ) )
8. 请输出 name 变量对应的值的第 2 个字符?
print ( name [ 1 ] )
9. 请输出 name 变量对应的值的前 3 个字符?
print ( name [ : 3 ] )
10. 请输出 name 变量对应的值的后 2 个字符?
print ( name [ 2 : ] )
11. 请输出 name 变量对应的值中 “d” 所在索引位置?
print ( name . index ( 'i' ) )
12. 获取子序列 , 去掉最后一个字符 . 如 : kid 则获取 ki .
print ( name [ 0 : len ( name ) - 1 ] )