【PyTorch 新手基础】Regularization -- 减轻过拟合 overfitting
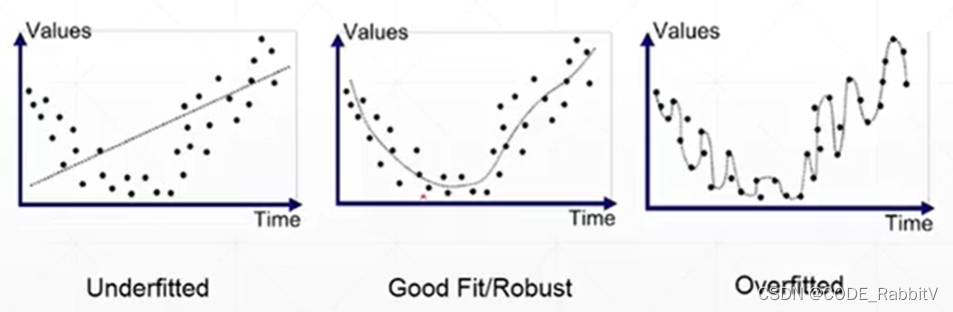
Overfit 过拟合,效果如最右图所示增大数据集 入手:More data or data argumentation简化模型参数 入手:Constraint model complexity (shallow model, regularization) or dropout
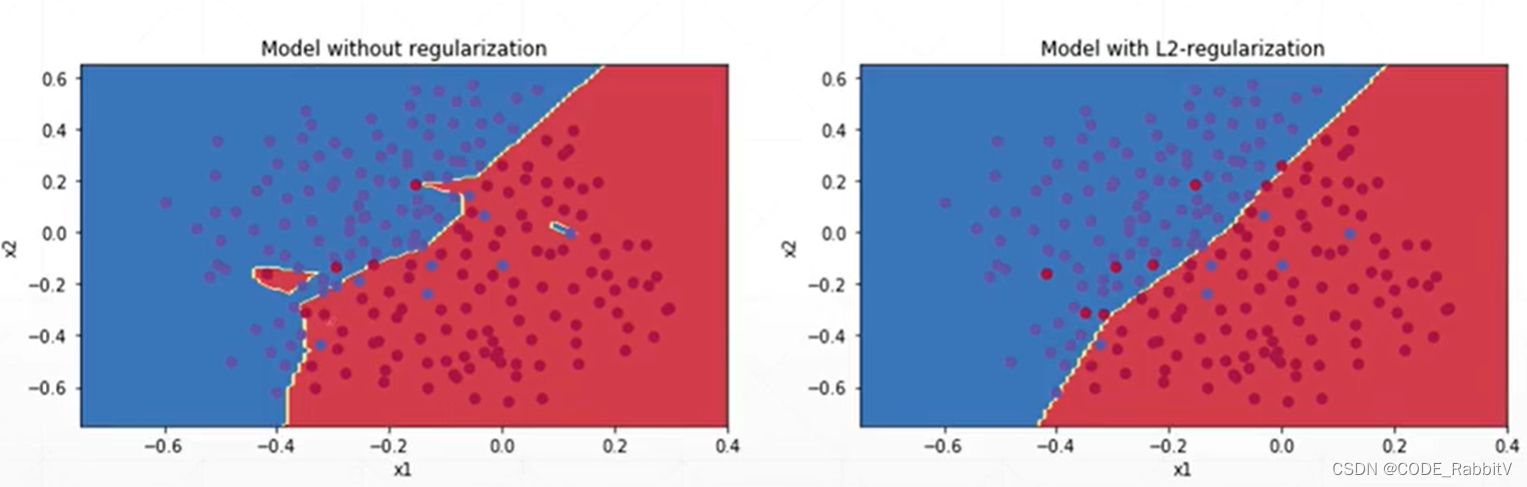
dropout: torch.nn.Dropout(0.1) 加一层 dropout 层, 设 dropout_prob = 0.1 注意 1) 区别和 tensorflow 中 tf.nn.dropout(keep_prob) 设置的相反; 2) 只在 train 的时候 dropout,测试的时候要 model.eval() 切换评估模式无 dropout 减少训练时间 入手:early stopping (用 validation set 做提前的训练终止),是一个 trickRegularization / weight decay : 使得在保持很好的 performance 的情况下用尽可能小的 weights
L1-regularization:
Loss
+
=
λ
∑
∣
θ
i
∣
\text{Loss} += \lambda\sum|\theta_i|
Loss + = λ ∑ ∣ θ i ∣ L2-regularization:
Loss
+
=
1
2
λ
∑
θ
i
2
\text{Loss} +=\frac{1}{2}\lambda\sum\theta_i^2
Loss + = 2 1 λ ∑ θ i 2 optimizer 设置 weight decay=
λ
\lambda
λ optim.SGD(net.parameters(), lr=learning_rate, weight_decay=0.01) 注:如果没有 overfitting 但是设置了 weight decay 可能会导致性能下降,要先判断清楚是否要使用
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1819988.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!