一、MNIST数据集介绍
MNIST 数据集(手写数字数据集)是一个公开的公共数据集,任何人都可以免费获取它。目前,它已经是一个作为机器学习入门的通用性特别强的数据集之一,所以对于想要学习机器学习分类的、深度神经网络分类的、图像识别与处理的小伙伴,都可以选择MNIST数据集入门。
二、MNIST数据集结构
MNIST 数据集包含70000(60000+10000)个样本,其中有60000个训练样本和10000个测试样本,每个样本的像素大小为28*28。
1.MNIST数据集下载方式
方法一
下载地址:http://yann.lecun.com/exdb/mnist/

可以直接下载这四个文件,这四个文件分别为:
①训练样本的图像(60000个)
②对应训练样本上每一张图像上数字的标签(0~9)(60000个)
③测试样本的图像(10000个)
④对应测试样本上每一张图像上数字的标签(0~9)(10000个)
方法二
在Keras中已经内置了多种公共数据集,其中就包含MNIST数据集,如图所示。

所以可以直接调用 tf.keras.datasets.mnist,直接下载数据集。
2.开始训练
可以跟着一步一步做,不会出错
(1)导包
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import time(2)打印开始时间
print('--------------')
nowtime = time.strftime('%Y-%m-%d %H:%M:%S')
print(nowtime)
效果展示:

(3)预处理
#初始化
plt.rcParams['font.sans-serif'] = ['SimHei']
#加载数据
mnist = tf.keras.datasets.mnist
(train_x,train_y),(test_x,test_y) = mnist.load_data()
print('\n train_x:%s, train_y:%s, test_x:%s, test_y:%s'%(train_x.shape,train_y.shape,test_x.shape,test_y.shape))
#数据预处理
#X_train = train_x.reshape((60000,28*28))
#Y_train = train_y.reshape((60000,28*28)) #后面采用tf.keras.layers.Flatten()改变数组形状
X_train,X_test = tf.cast(train_x/255.0,tf.float32),tf.cast(test_x/255.0,tf.float32) #归一化
y_train,y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)效果展示:
 (4)建立模型查看结构
(4)建立模型查看结构
# 建立模型
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
print('\n',model.summary()) #查看网络结构和参数信息效果展示:

(5)开始训练
#配置模型训练方法
#adam算法参数采用keras默认的公开参数,损失函数采用稀疏交叉熵损失函数,准确率采用稀疏分类准确率函数
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['sparse_categorical_accuracy'])
#训练模型
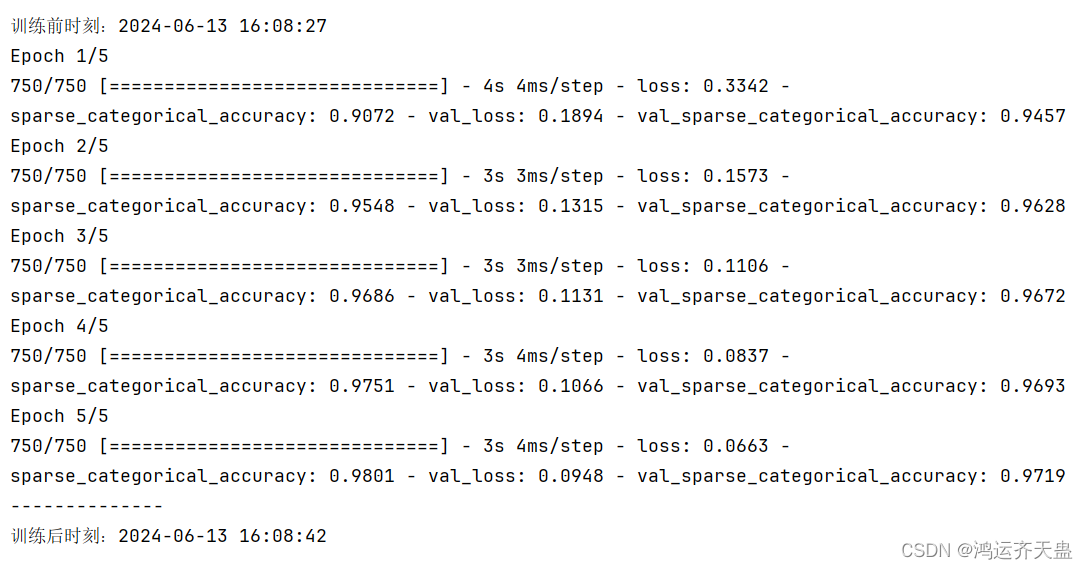
#批量训练大小为64,迭代5次,测试集比例0.2(48000条训练集数据,12000条测试集数据)
print('--------------')
nowtime = time.strftime('%Y-%m-%d %H:%M:%S')
print('训练前时刻:'+str(nowtime))
history = model.fit(X_train,y_train,batch_size=64,epochs=5,validation_split=0.2)
print('--------------')
nowtime = time.strftime('%Y-%m-%d %H:%M:%S')
print('训练后时刻:'+str(nowtime))效果展示:
(6)评估模型
#评估模型
model.evaluate(X_test,y_test,verbose=2) #每次迭代输出一条记录,来评价该模型是否有比较好的泛化能力效果展示:

(7)结果可视化
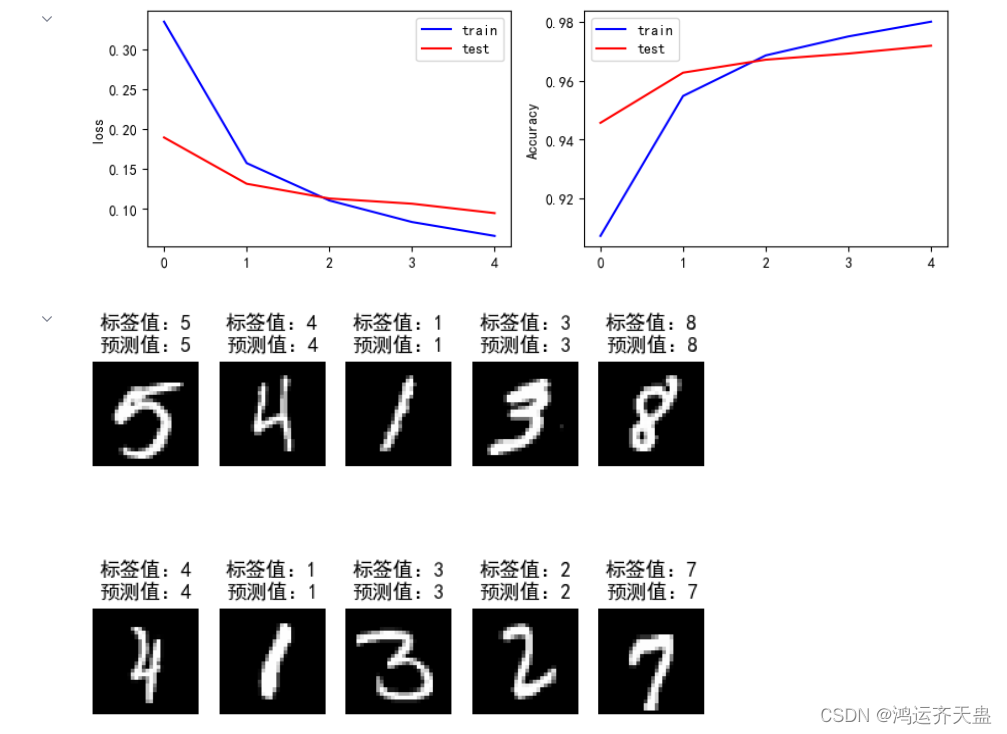
#结果可视化
print(history.history)
loss = history.history['loss'] #训练集损失
val_loss = history.history['val_loss'] #测试集损失
acc = history.history['sparse_categorical_accuracy'] #训练集准确率
val_acc = history.history['val_sparse_categorical_accuracy'] #测试集准确率
plt.figure(figsize=(10,3))
plt.subplot(121)
plt.plot(loss,color='b',label='train')
plt.plot(val_loss,color='r',label='test')
plt.ylabel('loss')
plt.legend()
plt.subplot(122)
plt.plot(acc,color='b',label='train')
plt.plot(val_acc,color='r',label='test')
plt.ylabel('Accuracy')
plt.legend()
#暂停5秒关闭画布,否则画布一直打开的同时,会持续占用GPU内存
#根据需要自行选择
#plt.ion() #打开交互式操作模式
#plt.show()
#plt.pause(5)
#plt.close()
#使用模型
plt.figure()
for i in range(10):
num = np.random.randint(1,10000)
plt.subplot(2,5,i+1)
plt.axis('off')
plt.imshow(test_x[num],cmap='gray')
demo = tf.reshape(X_test[num],(1,28,28))
y_pred = np.argmax(model.predict(demo))
plt.title('标签值:'+str(test_y[num])+'\n预测值:'+str(y_pred))
#y_pred = np.argmax(model.predict(X_test[0:5]),axis=1)
#print('X_test[0:5]: %s'%(X_test[0:5].shape))
#print('y_pred: %s'%(y_pred))
#plt.ion() #打开交互式操作模式
plt.show()
#plt.pause(5)
#plt.close()展示效果:
3.测试模型
1.修改测试图片的路径
2.修改保存模型的路径
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import cv2
# 建立模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28))) # 添加Flatten层说明输入数据的形状
model.add(tf.keras.layers.Dense(128, activation='relu')) # 添加隐含层,为全连接层,128个节点,relu激活函数
model.add(tf.keras.layers.Dense(10, activation='softmax')) # 添加输出层,为全连接层,10个节点,softmax激活函数
# 加载模型参数
model.load_weights('mnist_weights.h5') # 路径根据文件实际位置修改,不然会报错
# 定义一个函数来预处理图片
def preprocess_image(image_path):
# 读取图片,转换为灰度图
img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
if img is None:
print(f"无法加载图片:{image_path}")
return None
# 调整图片大小为28x28像素
img = cv2.resize(img, (28, 28))
# 归一化图片像素值到0-1范围
img = img / 255.0
# 转换图片形状以匹配模型输入
img = img.reshape(1, 28, 28)
return img
# 使用模型进行预测
plt.figure()
# 这里替换为你的图片路径列表
image_paths = ['shouxieti_img/test/0_10.jpg']
for i, image_path in enumerate(image_paths):
# 预处理图片
img = preprocess_image(image_path)
if img is not None:
# 使用模型进行预测
y_pred = np.argmax(model.predict(img))
# 显示图片和预测结果
plt.subplot(1, len(image_paths), i+1)
plt.imshow(img[0], cmap='gray')
plt.axis('off')
plt.title('预测值:' + str(y_pred))
plt.show()
效果展示:

话不多说 源码奉上!
4.全部代码
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import time
print('--------------')
nowtime = time.strftime('%Y-%m-%d %H:%M:%S')
print(nowtime)
#初始化
plt.rcParams['font.sans-serif'] = ['SimHei']
#加载数据
mnist = tf.keras.datasets.mnist
(train_x,train_y),(test_x,test_y) = mnist.load_data()
print('\n train_x:%s, train_y:%s, test_x:%s, test_y:%s'%(train_x.shape,train_y.shape,test_x.shape,test_y.shape))
#数据预处理
#X_train = train_x.reshape((60000,28*28))
#Y_train = train_y.reshape((60000,28*28)) #后面采用tf.keras.layers.Flatten()改变数组形状
X_train,X_test = tf.cast(train_x/255.0,tf.float32),tf.cast(test_x/255.0,tf.float32) #归一化
y_train,y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)
# 建立模型
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
print('\n',model.summary()) #查看网络结构和参数信息
#配置模型训练方法
#adam算法参数采用keras默认的公开参数,损失函数采用稀疏交叉熵损失函数,准确率采用稀疏分类准确率函数
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['sparse_categorical_accuracy'])
#训练模型
#批量训练大小为64,迭代5次,测试集比例0.2(48000条训练集数据,12000条测试集数据)
print('--------------')
nowtime = time.strftime('%Y-%m-%d %H:%M:%S')
print('训练前时刻:'+str(nowtime))
history = model.fit(X_train,y_train,batch_size=64,epochs=5,validation_split=0.2)
print('--------------')
nowtime = time.strftime('%Y-%m-%d %H:%M:%S')
print('训练后时刻:'+str(nowtime))
#评估模型
model.evaluate(X_test,y_test,verbose=2) #每次迭代输出一条记录,来评价该模型是否有比较好的泛化能力
#结果可视化
print(history.history)
loss = history.history['loss'] #训练集损失
val_loss = history.history['val_loss'] #测试集损失
acc = history.history['sparse_categorical_accuracy'] #训练集准确率
val_acc = history.history['val_sparse_categorical_accuracy'] #测试集准确率
plt.figure(figsize=(10,3))
plt.subplot(121)
plt.plot(loss,color='b',label='train')
plt.plot(val_loss,color='r',label='test')
plt.ylabel('loss')
plt.legend()
plt.subplot(122)
plt.plot(acc,color='b',label='train')
plt.plot(val_acc,color='r',label='test')
plt.ylabel('Accuracy')
plt.legend()
#暂停5秒关闭画布,否则画布一直打开的同时,会持续占用GPU内存
#根据需要自行选择
#plt.ion() #打开交互式操作模式
#plt.show()
#plt.pause(5)
#plt.close()
#使用模型
plt.figure()
for i in range(10):
num = np.random.randint(1,10000)
plt.subplot(2,5,i+1)
plt.axis('off')
plt.imshow(test_x[num],cmap='gray')
demo = tf.reshape(X_test[num],(1,28,28))
y_pred = np.argmax(model.predict(demo))
plt.title('标签值:'+str(test_y[num])+'\n预测值:'+str(y_pred))
#y_pred = np.argmax(model.predict(X_test[0:5]),axis=1)
#print('X_test[0:5]: %s'%(X_test[0:5].shape))
#print('y_pred: %s'%(y_pred))
#plt.ion() #打开交互式操作模式
plt.show()
#plt.pause(5)
#plt.close()转载于:【神经网络与深度学习】使用MNIST数据集训练手写数字识别模型——[附完整训练代码]_使用mnist数据集进行模型训练时-CSDN博客
谢谢支持!