- 绪论
1.1 计算机管理信息系统的发展情况
1958 年美国首先提出了 “管理信息系统 ”(即 MIS:Management Information Systems),从而也引出了另外一个概念 ——“管理信息系统 ”。综合其多种定义以及根据在实际中的应用,管理信息系统可以定义为是一个由人、计算机系统等组成的,能进行信息处理的人机系统,
它反映企业的生产经营情况,利用过去、当前的数据预测未来,从企业全局出发辅助企业进行管理与决策。它具有以下特征:
现代管理信息系统是一个以计算机为基础的一个人机系统。
管理信息系统是一个集成化的系统。
管理信息系统是一个以数据库为中心的系统。
管理信息系统是一个网络化的系统。
管理信息系统不同于一般的数据处理系统
由于企业类型不同,企业的战略计划不同,企业的管理模式不径相同等因素,实际的管理信息系统的动能会不同。但是从抽象意义上来说,无论什么企业,其管理信息系统的功能相同。一般分为数据处理、辅助管理决策两大功能。管理信息系统的数据处理功能以完成企业相关数据的收集、存储、加工、传输和输出,提供信息服务。它是管理信息系统的基本功能;辅助管理决策功能即指对企业生产经营中的结构化决策问题,采用管理信息系统相关学科中提出的定量方法,建立问题的模型,求解问题,获得解决问题的方法。斯隆认为用户对管理信息系统的需求分为四类:
事务型:是一种例行处理要求,辅助日常事务。例如商业企业的商品进销存的管理。
异常型:其处理要求是当某状态超出事先设置的阈值,则系统能够发出警报。例如财务中对某些科目设置报警值,一旦超值则对该科目的开支进行控制。
查询型:要求管理信息系统具有灵活的查询能力,满足用户的信息需要。
分析型: 提供强有力的分析能力, 借助数据、 模型支持决策, 以回答 “如果 …… 那么 ……”
诸如此类的问题。
自从管理信息系统这一新兴的管理方法引入我国,在我国企业管理中已有 20 多年时间。而且,管理信息系统已经广泛应用于各行各业。虽然,我国的企业计算机管理信息系统建设在 20 世纪 80 年代就已经开始起步,但发展极不平衡,也就是说大部分企业目前仍处于低水平开发和应用阶段。随着经济体制的改革和市场经济的发展,企业机制有了很大变化。企业的生产更多地依赖于市场的竞争,信息从而成为企业的重要资源,企业信息系统的建设已成为企业走向现代化的重要标志,企业信息系统对于企业的运作以及在市场中的竞争具有重要作用。在当前形势下,信息化是企业发展的必由之路。
1.2 宠物医院信息管理系统的现状
目前,国内外宠物医院信息管理管理一般采用两种方式:一种纯手工管理;另一种则是利用一些较老的或是以别 的系统为底板改版而成的系统来进行管理。但这两种方法都有各自的弊端:前一种方法由于参与管理者的文化水平不一,字迹不一,互相之间会导致信息传达不便,而且纸质信息传载媒体有着一个很大的弱点就是容易损坏,造成信息丢失;后一种方法虽然解决了信息传达、信息保存的问题。但存在一个更致命的缺点:系统安全问题得不到保证 [3]。在当前的信息化时代中, 任何宠物医院, 都需要一个实用的宠物医院信息管理系统来规范宠物医院信息管理管理,这将会大大提高宠物医院的管理水平,优化资源,实现效益的最大化。现在国内外也有很多宠物医院信息管理管理的软件,采用的技术也是多种多样,如基于JSP、FTP 模式,但大多数宠物医院信息管理系统主要用于大型宠物医院的关键部门。至于小型宠物医院,利用宠物医院信息管理系统组织管理教学活动的并不多。针对国内外对宠物
医院信息管理软件的巨大需要和基本需要, 一个好的宠物医院信息管理软件, 必须功能齐全,操作简便,向用户展示友善的操作界面。在完善功能的同时又必须兼顾系统的灵活性,安全性,健壮性。一个好的教学管理系统,不管是计算机专业人员还是其他用户都能很快上手,操作简单,便于安装,容易普及。
1.3 宠物医院信息管理系统的优势
由于宠物医院教学功能的特殊定位,致使医生和患者必须在除了简单的医患区别外,还有合作意味的关系。所以,这其中的信息管理流程,需要以一个规范的 MIS 来管理。宠物医院信息管理系统的优势主要表现在三个方面:
- 宠物医院信息管理无纸化,环保又方便。传统的宠物医院信息管理方式,都是经由工作从员手工记录存档。这种传统的纸质宠物医院信息管理管理,一是会有很大的体力消耗,二是在精力上也是不小的付出,而且这种辛苦在很多时候往往没能得到满意的回复。而无纸化宠物医院信息管理,只需在电脑前点点鼠标,在体力上几乎没有多大的消耗,而且在环保、效率、针对性教学指导方面做得要比传统的宠物医院信息管理管理科学得多。
2、科学管理,安全可靠。传统的宠物医院信息管理管理方式,都是一份份独立的宠物医院信息管理,一个部门对应一份,而这么一撂的设计,经常会由于各种原因,丢失或是污损,给宠物医院信息管理管理和教学进程带来很大的麻烦和不便。而宠物医院信息管理系统的动作,只需做好系统数据库的保护,以上问题可以迎刃而解了。
3、简化工作,促进其他方面的综合发展。由于宠物医院信息管理系统的介入运行,可以使医生腾出更多的时间,做更多针对性的个性化医疗服务,从而使每个病人都有机会享受更多的服务
1.3项目的可行性研究设计
此系统需要java面向对象编程基础,数据库应用知识以及功能分析。根据目前阶段所掌握的知识,根据这学期以及之前学习掌握的java编程知识和数据库应用知识以及前端知识做出一个这样的基于Javaweb、springboot轻量级框架网页版的宠物医院信息管理系统。
1.4技术可行性
spring
Spring框架是Java平台上的一种开源应用框架,提供具有控制反转特性的容器。尽管Spring框架自身对编程模型没有限制,但其在Java应用中的频繁使用让它备受青睐,以至于后来让它作为EJB(EnterpriseJavaBeans)模型的补充,甚至是替补。Spring框架为开发提供了一系列的解决方案,比如利用控制反转的核心特性,并通过依赖注入实现控制反转来实现管理对象生命周期容器化,利用面向切面编程进行声明式的事务管理,整合多种持久化技术管理数据访问,提供大量优秀的Web框架方便开发等等。Spring框架具有控制反转(IOC)特性,IOC旨在方便项目维护和测试,它提供了一种通过Java的反射机制对Java对象进行统一的配置和管理的方法。Spring框架利用容器管理对象的生命周期,容器可以通过扫描XML文件或类上特定Java注解来配置对象,开发者可以通过依赖查找或依赖注入来获得对象。Spring框架具有面向切面编程(AOP)框架,SpringAOP框架基于代理模式,同时运行时可配置;AOP框架主要针对模块之间的交叉关注点进行模块化。Spring框架的AOP框架仅提供基本的AOP特性,虽无法与AspectJ框架相比,但通过与AspectJ的集成,也可以满足基本需求。Spring框架下的事务管理、远程访问等功能均可以通过使用SpringAOP技术实现。Spring的事务管理框架为Java平台带来了一种抽象机制,使本地和全局事务以及嵌套事务能够与保存点一起工作,并且几乎可以在Java平台的任何环境中工作。Spring集成多种事务模板,系统可以通过事务模板、XML或Java注解进行事务配置,并且事务框架集成了消息传递和缓存等功能。Spring的数据访问框架解决了开发人员在应用程序中使用数据库时遇到的常见困难。它不仅对Java:JDBC、iBATS/MyBATIs、Hibernate、Java数据对象(JDO)、ApacheOJB和ApacheCayne等所有流行的数据访问框架中提供支持,同时还可以与Spring的事务管理一起使用,为数据访问提供了灵活的抽象。Spring框架最初是没有打算构建一个自己的WebMVC框架,其开发人员在开发过程中认为现有的StrutsWeb框架的呈现层和请求处理层之间以及请求处理层和模型之间的分离不够,于是创建了SpringMVC。
Spring MVC
Spring MVC框架是有一个MVC框架,通过实现Model-View-Controller模式来很好地将数据、业务与展现进行分离。从这样一个角度来说,Spring MVC和Struts、Struts2非常类似。Spring MVC的设计是围绕DispatcherServlet展开的,DispatcherServlet负责将请求派发到特定的handler。通过可配置的handler mappings、view resolution、locale以及theme resolution来处理请求并且转到对应的视图。Spring MVC请求处理的整体流程如图: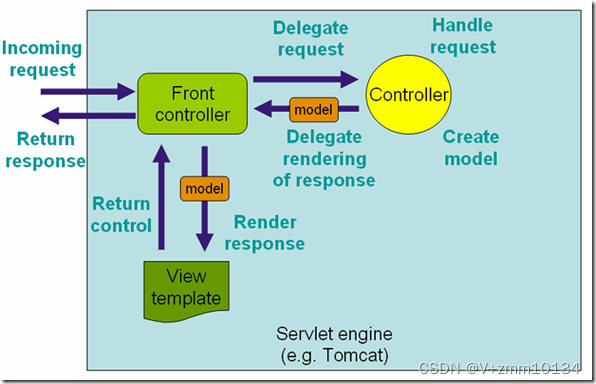

mybatis
mybatis是对jdbc的封装,它让数据库底层操作变的透明。mybatis的操作都是围绕一个sqlSessionFactory实例展开的。mybatis通过配置文件关联到各实体类的Mapper文件,Mapper文件中配置了每个类对数据库所需进行的sql语句映射。在每次与数据库交互时,通过sqlSessionFactory拿到一个sqlSession,再执行sql命令。
页面发送请求给控制器,控制器调用业务层处理逻辑,逻辑层向持久层发送请求,持久层与数据库交互,后将结果返回给业务层,业务层将处理逻辑发送给控制器,控制器再调用视图展现数据
Shiro权限框架
shiro是一个安全框架,是Apache的一个子项目。shiro提供了:认证、授权、加密、会话管理、与web集成、缓存等模块。

1.1、模块介绍
Authentication:用户身份识别,可以认为是登录;
Authorization:授权,即权限验证,验证某个已认证的用户是否拥有某个权限;即判断用户是否能做事情,常见的如:验证某个用户是否拥有某个角色。或者细粒度的验证某个用户对某个资源是否具有某个权限。
Session Manager:会话管理,即用户登录后就是一次会话,在没有退出之前,它的所有信息都在会话中;会话可以是普通 JavaSE 环境的,也可以是如 Web 环境的。
Cryptography:加密,保护数据的安全性,如密码加密存储到数据库,而不是明文存储。
Web Support:Web支持,可以非常容易的集成到 web 环境。
Caching:缓存,比如用户登录后,其用户信息、拥有的角色/权限不必每次去查,这样可以提高效率。
Concurrency:shiro 支持多线程应用的并发验证,即如在一个线程中开启另一个线程,能把权限自动传播过去。
Testing:提供测试支持。
Run As:允许一个用户假装为另一个用户(如果他们允许)的身份进行访问。
Remember Me:记住我,这个是非常常见的功能,即一次登录后,下次再来的话不用登录了。
注意:shiro不会去维护用户和权限之间的关系,需要我们自己去设计、提供;然后通过相应的接口注入给shiro即可。
2、核心概念
Subject:主体,代表了当前操作“用户”,这个用户不一定是具体的人,与当前应用交互的任何东西都是subject,即一个抽象概念。所有Subject都绑定到SecurityManager,与Subject交互都会委托给SercurityManager;
SecurityManager:安全管理器;即所有与subject安全有关的操作都会与SecurityManager交互;且它管理着所有的Subject;它负责与里面的各个组件的交互,也可以把它理解成springmvc中的DispatcherServlet前端控制器。
Realm:域,安全数据源。shiro从Realm获取安全数据(如用户、权限、角色),就是说SecurityManager要验证用户身份,那么它需要从Realm得到用户相应的角色、权限进行验证用户是否能进行操作;可以把Realm看成DataSource,即安全数据源。

从上图可以看出:
1、应用代码通过Subject来进行认证和授权,而Subject又委托给SecurityManager;
2、SecurityManager要验证用户身份,那么它需要从Realm中获取相对应的用户、角色、权限进行比较以确定用户身份是否合法。
总结:shiro不提供维护用户、权限,而是通过Realm让开发人员自己注入。

3、shiro内部架构介绍

1) Subject:主体,可以看到主体可以是任何与应用交互的“用户”。
2) SecurityManager:相当于 SpringMVC 中的 DispatcherServlet 或者 Struts2 中的FilterDispatcher。它是 Shiro 的核心,所有具体的交互都通过 SecurityManager 进行控制。它管理着所有 Subject、且负责进行认证和授权、及会话、缓存的管理。
3) Authenticator:认证器,负责主体认证的,这是一个扩展点,如果用户觉得 Shiro 默认的不好,我们可以自定义实现。其需要认证策略(Authentication Strategy),即什么情况下算用户认证通过了。
4) Authrizer:授权器,或者访问控制器。它用来决定主体是否有权限进行相应的操作,即控制着用户能访问应用中的哪些功能。
5) Realm:可以有1个或多个 Realm,可以认为是安全实体数据源,即用于获取安全实体的。它可以是 JDBC 实现,也可以是 LDAP 实现,或者内存实现等。
6) SessionManager:如果写过 Servlet 就应该知道 Session 的概念,Session 需要有人去管理它的生命周期,这个组件就是 SessionManager。而 Shiro 并不仅仅可以用在 Web 环境,也可以用在如普通的 JavaSE 环境。
7) SessionDAO:DAO 大家都用过,数据访问对象,用于会话的 CRUD。我们可以自定义 SessionDAO 的实现,控制 session 存储的位置。如通过 JDBC 写到数据库或通过 jedis 写入 redis 中。另外 SessionDAO 中可以使用 Cache 进行缓存,以提高性能。
8) CacheManager:缓存管理器。它来管理如用户、角色、权限等的缓存的。因为这些数据基本上很少去改变,放到缓存中后可以提高访问的性能。
9) Cryptography:密码模块,Shiro 提高了一些常见的加密组件用于如密码加密/解密的。
4、过滤器
当 Shiro 被运用到 web 项目时,Shiro 会自动创建一些默认的过滤器对客户端请求进行过滤。以下是 Shiro 提供的过滤器:
| 过滤器简称 | 对应的 Java 类 |
| anon | org.apache.shiro.web.filter.authc.AnonymousFilter |
| authc | org.apache.shiro.web.filter.authc.FormAuthenticationFilter |
| authcBasic | org.apache.shiro.web.filter.authc.BasicHttpAuthenticationFilter |
| perms | org.apache.shiro.web.filter.authz.PermissionsAuthorizationFilter |
| port | org.apache.shiro.web.filter.authz.PortFilter |
| rest | org.apache.shiro.web.filter.authz.HttpMethodPermissionFilter |
| roles | org.apache.shiro.web.filter.authz.RolesAuthorizationFilter |
| ssl | org.apache.shiro.web.filter.authz.SslFilter |
| user | org.apache.shiro.web.filter.authc.UserFilter |
| logout | org.apache.shiro.web.filter.authc.LogoutFilter |
| noSessionCreation | org.apache.shiro.web.filter.session.NoSessionCreationFilter |
解释:
| /admins/**=anon # 表示该 uri 可以匿名访问 /admins/**=auth # 表示该 uri 需要认证才能访问 /admins/**=authcBasic # 表示该 uri 需要 httpBasic 认证 /admins/**=perms[user:add:*] # 表示该 uri 需要认证用户拥有 user:add:* 权限才能访问 /admins/**=port[8081] # 表示该 uri 需要使用 8081 端口 /admins/**=rest[user] # 相当于 /admins/**=perms[user:method],其中,method 表示 get、post、delete 等 /admins/**=roles[admin] # 表示该 uri 需要认证用户拥有 admin 角色才能访问 /admins/**=ssl # 表示该 uri 需要使用 https 协议 /admins/**=user # 表示该 uri 需要认证或通过记住我认证才能访问 /logout=logout # 表示注销,可以当作固定配置 |
SpringBoot
SpringBoot是由Pivotal团队在2013年开始研发、2014年4月发布第一个版本的全新开源的轻量级框架。它基于Spring4.0设计,不仅继承了Spring框架原有的优秀特性,而且还通过简化配置来进一步简化了Spring应用的整个搭建和开发过程。另外SpringBoot通过集成大量的框架使得依赖包的版本冲突,以及引用的不稳定性等问题得到了很好的解决。
SpringBoot所具备的特征有:
(1)可以创建独立的Spring应用程序,并且基于其Maven或Gradle插件,可以创建可执行的JARs和WARs;
(2)内嵌Tomcat或Jetty等Servlet容器;
(3)提供自动配置的“starter”项目对象模型(POMS)以简化Maven配置;
(4)尽可能自动配置Spring容器;
(5)提供准备好的特性,如指标、健康检查和外部化配置;
SpringBoot框架中还有两个非常重要的策略:开箱即用和约定优于配置。开箱即用,Outofbox,是指在开发过程中,通过在MAVEN项目的pom文件中添加相关依赖包,然后使用对应注解来代替繁琐的XML配置文件以管理对象的生命周期。这个特点使得开发人员摆脱了复杂的配置工作以及依赖的管理工作,更加专注于业务逻辑。约定优于配置,Convention over configuration,是一种由SpringBoot本身来配置目标结构,由开发者在结构中添加信息的软件设计范式。这一特点虽降低了部分灵活性,增加了BUG定位的复杂性,但减少了开发人员需要做出决定的数量,同时减少了大量的XML配置,并且可以将代码编译、测试和打包等工作自动化。
SpringBoot应用系统开发模板的基本架构设计从前端到后台进行说明:前端常使用模板引擎,主要有FreeMarker和Thymeleaf,它们都是用Java语言编写的,渲染模板并输出相应文本,使得界面的设计与应用的逻辑分离,同时前端开发还会使用到Bootstrap、AngularJS、JQuery等;在浏览器的数据传输格式上采用Json,非xml,同时提供RESTfulAPI;SpringMVC框架用于数据到达服务器后处理请求;到数据访问层主要有Hibernate、MyBatis、JPA等持久层框架;数据库常用MySQL;开发工具推荐IntelliJIDEA。
jQuery
jQuery是一个快速、简洁的JavaScript框架,是继Prototype之后又一个优秀的JavaScript代码库(或JavaScript框架)。jQuery设计的宗旨是“write Less,Do More”,即倡导写更少的代码,做更多的事情。它封装JavaScript常用的功能代码,提供一种简便的JavaScript设计模式,优化HTML文档操作、事件处理、动画设计和Ajax交互。
jQuery的核心特性可以总结为:具有独特的链式语法和短小清晰的多功能接口;具有高效灵活的css选择器,并且可对CSS选择器进行扩展;拥有便捷的插件扩展机制和丰富的插件。jQuery兼容各种主流浏览器,如IE 6.0+、FF 1.5+、Safari 2.0+、Opera 9.0+等
Mysql
MySQL 是一款安全、跨平台、高效的,并与 PHP、Java 等主流编程语言紧密结合的数据库系统。该数据库系统是由瑞典的 MySQL AB 公司开发、发布并支持,由 MySQL 的初始开发人员 David Axmark 和 Michael Monty Widenius 于 1995 年建立的。
MySQL 的象征符号是一只名为 Sakila 的海豚,代表着 MySQL 数据库的速度、能力、精确和优秀本质。

图:MySQL 图标
目前 MySQL 被广泛地应用在 Internet 上的中小型网站中。由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,使得很多公司都采用 MySQL 数据库以降低成本。
MySQL 数据库可以称得上是目前运行速度最快的 SQL 语言数据库之一。除了具有许多其他数据库所不具备的功能外,MySQL 数据库还是一种完全免费的产品,用户可以直接通过网络下载 MySQL 数据库,而不必支付任何费用。
MySQL 特点
下面总结了一下 MySQL 具备的特点。
1) 功能强大
MySQL 中提供了多种数据库存储引擎,各引擎各有所长,适用于不同的应用场合,用户可以选择最合适的引擎以得到最高性能,可以处理每天访问量超过数亿的高强度的搜索 Web 站点。MySQL5 支持事务、视图、存储过程、触发器等。
2) 支持跨平台
MySQL 支持至少 20 种以上的开发平台,包括 Linux、Windows、FreeBSD 、IBMAIX、AIX、FreeBSD 等。这使得在任何平台下编写的程序都可以进行移植,而不需要对程序做任何的修改。
3) 运行速度快
高速是 MySQL 的显著特性。在 MySQL 中,使用了极快的 B 树磁盘表(MyISAM)和索引压缩;通过使用优化的单扫描多连接,能够极快地实现连接;SQL 函数使用高度优化的类库实现,运行速度极快。
4) 支持面向对象
PHP 支持混合编程方式。编程方式可分为纯粹面向对象、纯粹面向过程、面句对象与面向过程混合 3 种方式。
5) 安全性高
灵活和安全的权限与密码系统,允许基本主机的验证。连接到服务器时,所有的密码传输均采用加密形式,从而保证了密码的安全。
6) 成本低
MySQL 数据库是一种完全免费的产品,用户可以直接通过网络下载。
7) 支持各种开发语言
MySQL 为各种流行的程序设计语言提供支持,为它们提供了很多的 API 函数,包括 PHP、ASP.NET、Java、Eiffel、Python、Ruby、Tcl、C、C++、Perl 语言等。
8) 数据库存储容量大
MySQL 数据库的最大有效表尺寸通常是由操作系统对文件大小的限制决定的,而不是由 MySQL 内部限制决定的。InnoDB 存储引擎将 InnoDB 表保存在一个表空间内,该表空间可由数个文件创建,表空间的最大容量为 64TB,可以轻松处理拥有上千万条记录的大型数据库。
9) 支持强大的内置函数
PHP 中提供了大量内置函数,几乎涵盖了 Web 应用开发中的所有功能。它内置了数据库连接、文件上传等功能,MySQL 支持大量的扩展库,如 MySQLi 等,可以为快速开发 Web 应用提供便利。
数据库的应用
数据库是计算机应用系统中的一种专门管理数据资源的系统。数据有多种形式,如文字、数码、符号、图形、图像及声音等,数据是所有计算机系统所要处理的对象。我们所熟知的一种处理办法是制作文件,即将处理过程编成程序文件,将所涉及的数据按程序要求组成数据文件,再用程序来调用,数据文件与程序文件保持着一定的关系。
在计算机应用迅速发展的情况下,这种文件式管理方法便显出它的不足。比如,它使得数据通用性差、不便于移植、在不同文件中存储大量重复信息、浪费存储空间、更新不便等。
而数据库系统便能解决上述问题。数据库系统不从具体的应用程序出发,而是立足于数据本身的管理,它将所有数据保存在数据库中,进行科学的组织,并借助于数据库管理系统,以它为中介,与各种应用程序或应用系统接口,使之能方便地使用数据库中的数据。
其实简单地说,数据库就是一组经过计算机整理后的数据,存储在一个或多个文件中,而管理这个数据库的软件就称为数据库管理系统。一般一个数据库系统(Database System)
可以分为数据库(Database)与数据管理系统(Database Management System,DBMS)两个部分。主流的数据库软件有 Oracle、Informix、Sybase、SQL Server、PostgreSQL、MySQL、Access、FoxPro 和 Teradata 等等。
数据库在 Web 开发中的重要地位
归根结底,动态网站都是对数据进行操作,我们平时浏览网页时,会发现网页的内容会经常变化,而页面的主体结构框架没变,新闻就是一个典型。这是因为我们将新闻存储在了数据库中,用户在浏览时,程序就会根据用户所请求的新闻编号,将对应的新闻从数据库中读取出来,然后再以特定的格式响应给用户。
Web 系统的开发基本上是离不开数据库的,因为任何东西都要存放在数据库中。所谓的动态网站就是基于数据库开发的系统,最重要的就是数据管理,或者说我们在开发时都是在围绕数据库在写程序。所以作为一个 Web 程序员,只有先掌握一门数据库,才可能去进行软件开发。
- 需求分析
2.1系统功能概述
1.用户模块管理:用户登录、用户注册、用户的查询、添加、删除操作、
2.页面模块管理:页面菜单的展示、添加操作、修改操作、删除操作、
3.角色模块管理:用户角色列表的查看、删除等操作、
4.宠物列表模块管理:宠物信息的查看、添加、删除、预约就诊、查看病历操作、
5.宠物健康历史:宠物健康历史查看、添加、修改、删除操作、
6.预约模块管理:预约模块查询、添加、删除、通过、不通过操作以及状态信息查看、
7.医生日期模块管理:医生日期的信息查看、
8.宠物日常健康模块管理:宠物的健康指南、健康标准的信息查看、修改、删除操作等、
9.宠物档案管理模块:宠物的数据录入、查看、修改等
10.医院信息管理:医院的公告信息管理以及制定宠物健康备注等操作
2.2系统运行环境
JavaJDK1.8环境配置、
Java运行在idea软件上,
数据库用mysql5版本数据库、
数据库采用Nacicat Mysql可视化工具、
基于主流的谷歌浏览器运行展示以及F12控制台调试样式、
2.4技术难点
- 系统设计
3.1系统设计
系统主要设计采用Java语言开发、采用springboot为后台框架、数据库框架采用mybatis、前端采用jquery、layui框架等
主要模块设计如下:
1.用户模块管理:用户登录、用户注册、用户的查询、添加、删除操作、
2.页面模块管理:页面菜单的展示、添加操作、修改操作、删除操作、
3.角色模块管理:用户角色列表的查看、删除等操作、
4.宠物列表模块管理:宠物信息的查看、添加、删除、预约就诊、查看病历操作、
5.宠物健康历史:宠物健康历史查看、添加、修改、删除操作、
6.预约模块管理:预约模块查询、添加、删除、通过、不通过操作以及状态信息查看、
7.医生日期模块管理:医生日期的信息查看、
8.宠物日常健康模块管理:宠物的健康指南、健康标准的信息查看、修改、删除操作等、
9.宠物档案管理模块:宠物的数据录入、查看、修改等
10.医院信息管理:医院的公告信息管理以及制定宠物健康备注等操作
11.注销退出
3.3模块设计
系统主要设计有:用户模块管理、页面模块管理、角色模块管理、宠物列表模块管理、宠物健康历史、预约模块管理、医生日期模块管理、宠物日常健康模块管理、医院信息管理和注销退出等具体功能、每个模块有对应的功能、比如:添加、修改、删除、等功能设置。
3.4系统流程描述

- 5项目源码架构


- 系统实现
4.1 程序主要类
4.1.1用户实体类
package com.phms.pojo;
import java.util.Date;
public class User {
private Long id;
private Integer age;
private String name;
private String password;
private String email;
private String idCard;
private String idName;
private String qualification;
private String hospitalName;
private String hospitalAddress;
private String department;
private String info;
private String img;
private String phone;
private String address;
private Date createTime;
4.1.4预约诊断类
package com.phms.pojo;
import java.util.Date;
public class Diagnosis extends BaseBean {
private Long id;
private Long petId;
private Long userId;
private Long doctorId;
private String info;
private String name;
private String doctorName;
private String userName;
4.1.4宠物类
package com.phms.pojo;
import org.springframework.format.annotation.DateTimeFormat;
import java.util.Date;
public class Pet extends BaseBean{
private Long id;
private Long userId;
private String name;
private Double weight;
private Double height;
private String type;
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private Date birthday;
private String img;
private Date createTime;
4.1.4菜单配置类
package com.phms.pojo;
public class Page {
private Integer pageId;
private Integer parentId;
private String name;
private String url;
private Integer levelType;
private Integer levelIndex;
private Integer deleteFlag;
private String desc;
4.3系统功能主要实现模块截图
4.3.1登陆页面
登录地址:http://localhost:8080/ssm_company_yg_sys/login
用户输入账号和密码和登录进行登录

4.3.1登录关键代码:
$.ajax({
type:"POST",
async:true, //默认true,异步
data:param,
dataType:'json',
url:"/login",
success:function(data){
if(data.result == "success"){
window.location.href = "/main";
}else if(data.message == "PASSWORD_ERR" || data.message == "USERNAME_NOT_EXIST"){
layer.alert('用户名或密码错误', {icon: 2});
$("#name").val("");
$("#password").val("")
}else{
layer.alert('登陆失败!请找管理员授权!', {icon: 2});
}
},
error:function() {
layer.alert('系统错误,服务器正忙!', {icon: 2});
}
});
@Override
public ResultMap login(String username, String password) {
// 从SecurityUtils里边创建一个 subject
Subject subject = SecurityUtils.getSubject();
// 在认证提交前准备 token(令牌)
UsernamePasswordToken token = new UsernamePasswordToken(username, MD5.md5(password));
// 执行认证登陆
try {
subject.login(token);
}catch (Exception e) {
return resultMap.fail().message(e.getMessage());
}
User user = (User) subject.getPrincipal();
// 根据权限,指定返回数据
List<String> role = userRoleMapper.getRoles(user.getId()+"");
if (!role.isEmpty()) {
logger.info("欢迎登录------您的权限是{}", role);
return resultMap.success().message("欢迎登陆");
}
return resultMap.fail().message("权限错误!");
}
4.3.2注册页面:

@RequestMapping(value = "/doRegist")
@ResponseBody
public ResultMap doRegist(User user) {
System.out.println(user);
User u = userService.getUserByPhoneAndName(user.getPhone(), null);
if (u != null){
return resultMap.success().message("该手机号已注册!");
}
try {
user.setPassword(MD5.md5(user.getPassword()));
user.setCreateTime(new Date());
userService.save(user);
String[] ids = new String[1];
ids[0] = user.getId()+"";
// 普通用户
userRoleService.addUserRole(2, ids);
return resultMap.success().message("注册成功");
}catch (Exception e){
e.printStackTrace();
return resultMap.fail().message("注册失败");
}
}
4.3.2 主页面
登录后进入系统首页,主要模块有:用户模块管理、页面模块管理、角色模块管理、宠物列表模块管理、宠物健康历史、预约模块管理、医生日期模块管理、宠物日常健康模块管理、医院信息管理和注销退出等具体功能、每个模块有对应的功能、比如:添加、修改、删除、等功能设置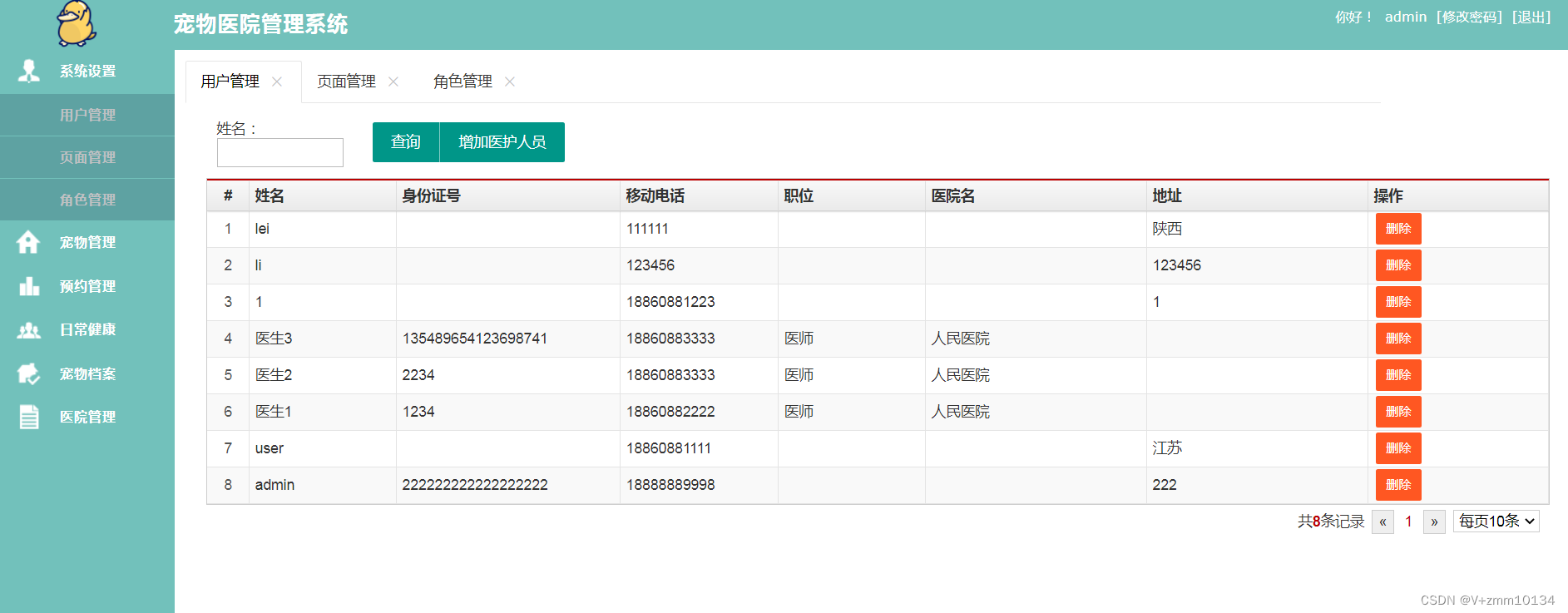

4.3.2.1 用户信息管理
展示用户医护人员的个人信息、对用户进行列表查询、添加以及删除操作

添加用户: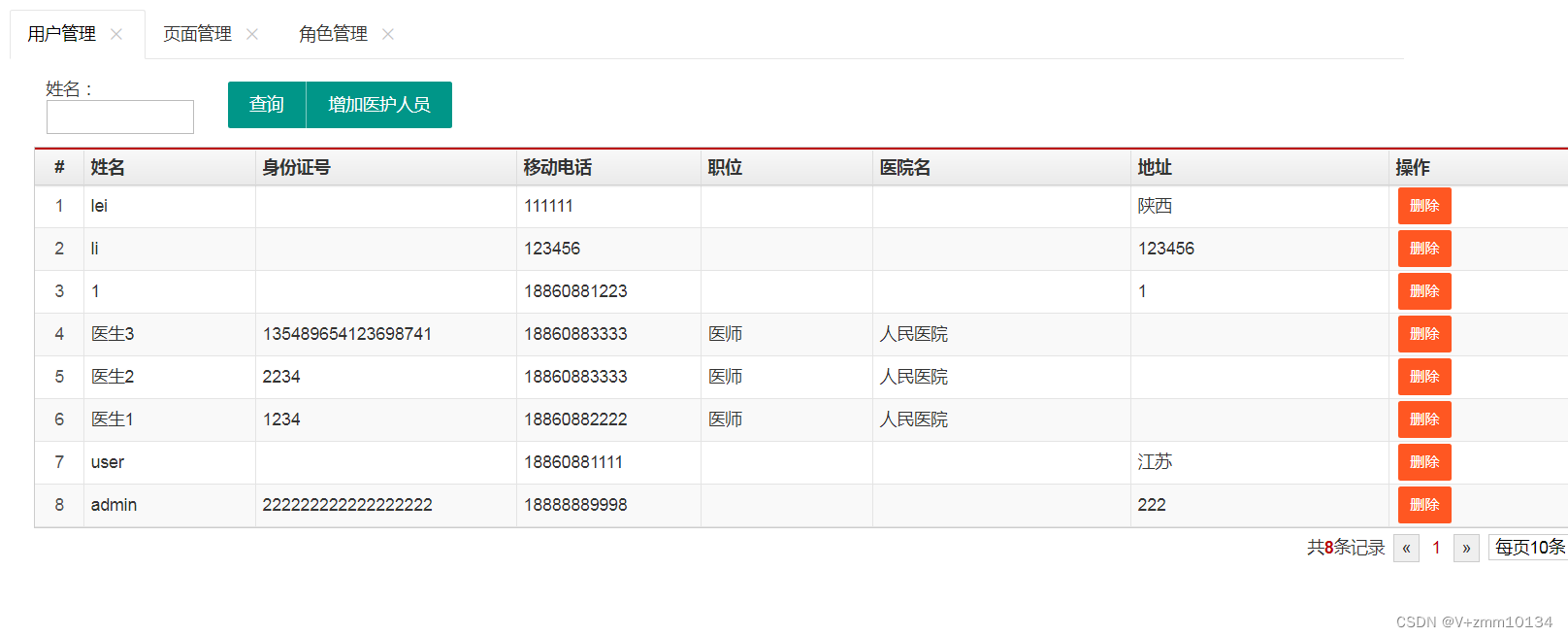

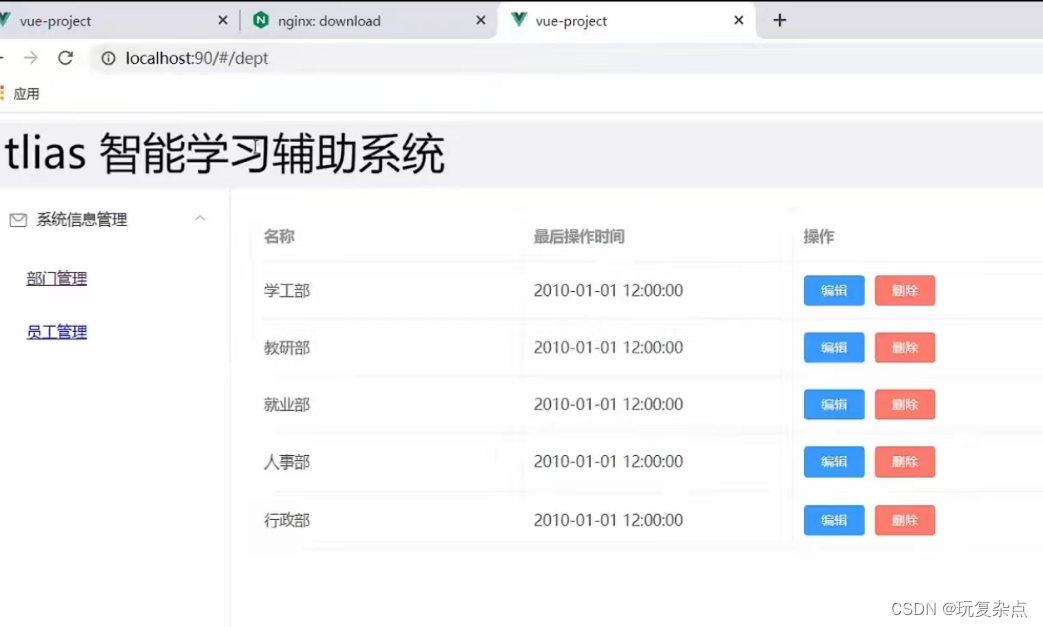
4.3.2.2 页面信息查看
点击按钮进入页面管理、管理员可对职位进行添加、修改、删除操作、

添加页面菜单:
输入菜单名称、URL进行保存添加。

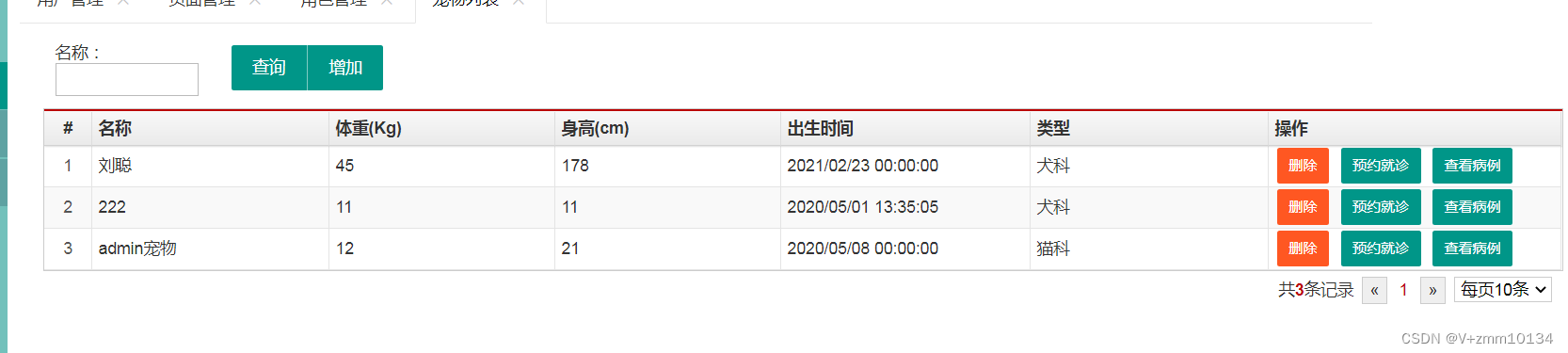
4.3.2.3 宠物信息管理
点击看查看宠物列表信息、体重、身高、类型、也可以对列表信息进行修改删除操作。

添加宠物信息:

删除宠物信息: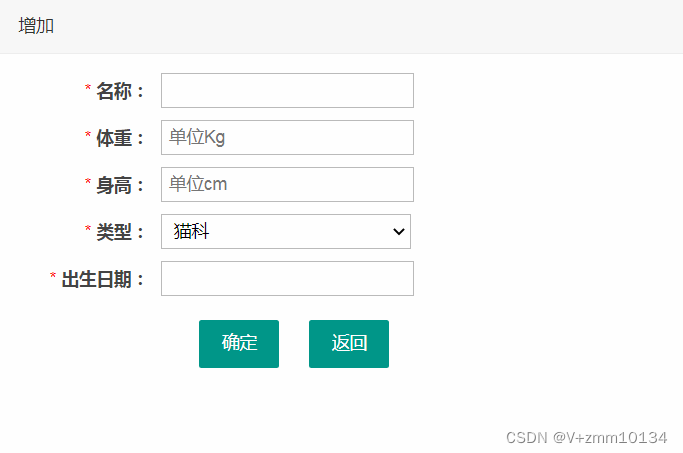

4.3.2.5 预约信息管理
点击看查看预约列表信息、预约时间、电话、地址、内容等信息、医生可以对申请的预约进行审核操作、


4.3.2.6 宠物健康指南信息管理
点击看查看宠物健康指南列表信息


查看详情


4.3.2.4 数据检测分析

4.3.4部分关键源码展示:
4.3.4.1登录模块:
@Override
public ResultMap login(String username, String password) {
// 从SecurityUtils里边创建一个 subject
Subject subject = SecurityUtils.getSubject();
// 在认证提交前准备 token(令牌)
UsernamePasswordToken token = new UsernamePasswordToken(username, MD5.md5(password));
// 执行认证登陆
try {
subject.login(token);
}catch (Exception e) {
return resultMap.fail().message(e.getMessage());
}
User user = (User) subject.getPrincipal();
// 根据权限,指定返回数据
List<String> role = userRoleMapper.getRoles(user.getId()+"");
if (!role.isEmpty()) {
logger.info("欢迎登录------您的权限是{}", role);
return resultMap.success().message("欢迎登陆");
}
return resultMap.fail().message("权限错误!");
}
4.3.4.2 springboot全局配置文件:
server.port=8086
debug=true
##��sqlִ������ӡ��־
logging.level.com.phms.mapper=debug
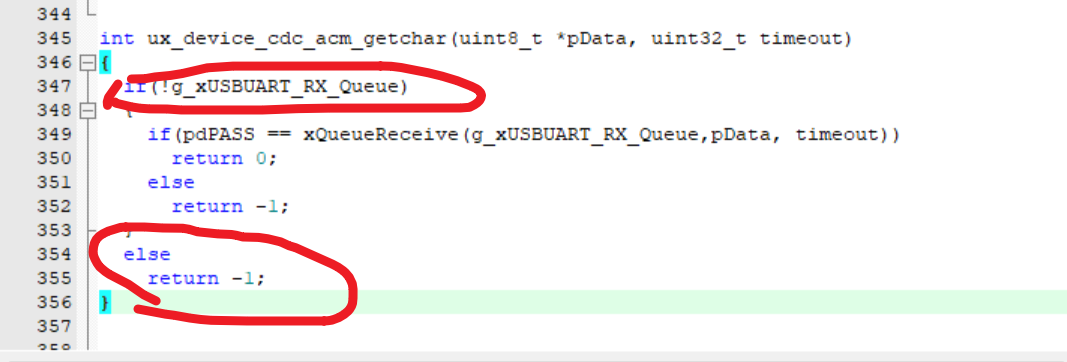
###############################MySQL���ݿ�����###############################
spring.datasource.name=test
spring.datasource.url=jdbc:mysql://localhost:3306/phms?characterEncoding=UTF-8&serverTimezone=GMT%2b8&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driverClassName=com.mysql.jdbc.Driver
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
###########################Mapper����###############################
logging.level.org.springframework.web=DEBUG
#Mybatis����
mybatis.type-aliases-package=com.phms
mybatis.mapper-locations=classpath:mapper/*.xml
###########################Mybatis����###############################
spring.datasource.druid.initial-size=10
spring.datasource.druid.min-idle=10
spring.datasource.druid.max-active=200
spring.datasource.druid.max-wait=60000
spring.datasource.druid.time-between-eviction-runs-millis=60000
spring.datasource.druid.min-evictable-idle-time-millis=300000
spring.datasource.druid.validation-query=SELECT 1 FROM DUAL
spring.datasource.druid.test-while-idle=true
spring.datasource.druid.test-on-borrow=false
spring.datasource.druid.test-on-return=false
spring.datasource.druid.pool-prepared-statements=true
spring.datasource.druid.max-pool-prepared-statement-per-connection-size=20
spring.datasource.druid.filters=stat,wall,log4j
#spring.profiles.active=prod#���IE ��ʾ����ΪNaN
spring.jackson.date-format=yyyy/MM/dd HH:mm:ss
logging.level.org.springframework.boot.autoconfigure=ERROR
#spring.jackson.time-zone=GMT+8# Freemarker ģ������#��ʾ���еķ��ʶ�������̬��Դ·����
spring.mvc.static-path-pattern=/**#�������ʾ���þ�̬��Դ��·��
spring.resources.static-locations=classpath:/static/
spring.thymeleaf.cache=false
spring.thymeleaf.prefix=classpath:/html/
spring.thymeleaf.suffix=.html
spring.thymeleaf.mode=HTML
spring.thymeleaf.encoding=UTF-8
spring.thymeleaf.servlet.content-type=text/html
pagehelper.helperDialect=mysql
pagehelper.reasonable=true
pagehelper.supportMethodsArguments=true
pagehelper.params = count=countSql
pagehelper.pageSize=10
spring.servlet.multipart.maxFileSize=10MB
spring.servlet.multipart.maxRequestSize=10MB
log4j.logger.com.ibatis=DEBUG
log4j.logger.com.ibatis.common.jdbc.SimpleDataSource=DEBUG
log4j.logger.com.ibatis.common.jdbc.ScriptRunner=DEBUG
log4j.logger.com.ibatis.sqlmap.engine.impl.SqlMapClientDelegate=DEBUG
log4j.logger.Java.sql.Connection=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.PreparedStatement=DEBUG
4.3.4.3 config.properties:
#文件上传路径,文件存放的真实路径
FILEPATH=/tmp/files/
#资源映射地址为file:D://User/
file.location=file:/tmp/files/
4.3.4.4 logback-spring日志配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 彩色日志 -->
<!-- 彩色日志依赖的渲染类 -->
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter" />
<conversionRule conversionWord="wex" converterClass="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter" />
<!-- 彩色日志格式 -->
<property name="CONSOLE_LOG_PATTERN" value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(%5p) %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n%wex"/>
<property name="FILE_LOG_PATTERN" value="%d{yyyy-MM-dd HH:mm:ss.SSS} %5p ${PID:- } --- [%t] %-40.40logger{39} : %m%n%wex"/>
<!--多环境的日志输出-->
<!--根据不同环境(prod:生产环境,test:测试环境,dev:开发环境)来定义不同的日志输出,-->
<!--在 logback-spring.xml中使用 springProfile 节点来定义,方法如下:-->
<property name="LOG_HOME" value="E:/logs/phms" />
<!--输出到控制台-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!--info 级别的日志-->
<!-- 按照每天生成日志文件 -->
<appender name="INFO" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>INFO</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--日志文件输出的文件名-->
<fileNamePattern>${LOG_HOME}/info.%d{yyyy-MM-dd}.log</fileNamePattern>
<!--日志文件保留天数-->
<MaxHistory>30</MaxHistory>
</rollingPolicy>
</appender>
<!--WARN 级别的日志-->
<appender name="WARN" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>WARN</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/warn.%d{yyyy-MM-dd}.log</fileNamePattern>
<MaxHistory>60</MaxHistory>
</rollingPolicy>
</appender>
<!--ERROR 级别的日志-->
<appender name="ERROR" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/error.%d{yyyy-MM-dd}.log</fileNamePattern>
<MaxHistory>120</MaxHistory>
</rollingPolicy>
</appender>
<!-- 日志输出级别 -->
<root level="INFO">
<appender-ref ref="CONSOLE" />
<appender-ref ref="INFO"/>
<appender-ref ref="WARN"/>
<appender-ref ref="ERROR"/>
</root>
</configuration>
4.3.4.5代码主启动类:
package com.phms;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@SpringBootApplication
// 开启注解事务管理
@EnableTransactionManagement
@MapperScan("com.phms.mapper")
public class PhmsApp {
public static void main(String[] args) {
SpringApplication.run(PhmsApp.class, args);
}
}
4.3.4.7 过滤器实现类:
package com.phms.filter;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.servlet.*;
import java.io.IOException;
/**
* class name:TimeFilter <BR>
* class description: 过滤器实现类<BR>
*/
public class TimeFilter implements Filter {
/** 日志记录 */
private final Logger logger = LoggerFactory.getLogger(TimeFilter.class);
@Override
public void init(FilterConfig filterConfig) throws ServletException {
logger.info("=======初始化过滤器=========");
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain)
throws IOException, ServletException {
// long start = System.currentTimeMillis();
filterChain.doFilter(request, response);
// logger.info("filter 耗时:{}",(System.currentTimeMillis() - start));
}
@Override
public void destroy() {
logger.info("=======销毁过滤器=========");
}
}
4.3.4.7 权限拦截控制器:
@Bean
public ShiroFilterFactoryBean shirFilter(SecurityManager securityManager) {
ShiroFilterFactoryBean shiroFilterFactoryBean = new ShiroFilterFactoryBean();
shiroFilterFactoryBean.setSecurityManager(securityManager);
// 自定义拦截器
Map<String, Filter> filtersMap = new LinkedHashMap<>();
filtersMap.put("roleOrFilter", new CustomRolesAuthorizationFilter());
shiroFilterFactoryBean.setFilters(filtersMap);
// 必须设置 SecurityManager
// setLoginUrl 如果不设置值,默认会自动寻找Web工程根目录下的"/login.jsp"页面 或 "/login" 映射
shiroFilterFactoryBean.setLoginUrl("/");
// 设置无权限时跳转的 url;
shiroFilterFactoryBean.setUnauthorizedUrl("/notRole");
/*
* anon 表示匿名访问,不需要认证以及授权 authc表示需要认证 没有进行身份认证是不能进行访问的
* authc,roles[admin]表示是admin角色的用户才能访问
*/
// 设置拦截器
Map<String, String> filterChainDefinitionMap = new LinkedHashMap<>();
// 用户,需要角色权限 “user”
//filterChainDefinitionMap.put("/user/**", "roleOrFilter[家长|老师|超级管理员]");
// 这样写必须同时拥有两个角色才能访问
// filterChainDefinitionMap.put("/user/**", "roles[\"组员, 管理员\"]");
// 管理员,需要角色权限 “admin”
//filterChainDefinitionMap.put("/sa/**", "roles[超级管理员]");
//filterChainDefinitionMap.put("/jz/**", "roleOrFilter[家长|教师|超级管理员]");
//filterChainDefinitionMap.put("/ls/**", "roleOrFilter[教师|超级管理员]");
// 开放登陆接口
filterChainDefinitionMap.put("/login", "anon");
filterChainDefinitionMap.put("/index", "anon");
filterChainDefinitionMap.put("/home", "anon");
filterChainDefinitionMap.put("/open/**", "anon");
filterChainDefinitionMap.put("/upload/**", "anon");
filterChainDefinitionMap.put("/file/**", "anon");
filterChainDefinitionMap.put("/regist", "anon");
filterChainDefinitionMap.put("/doRegist", "anon");
// 静态资源设置为可访问
filterChainDefinitionMap.put("/css/**", "anon");
filterChainDefinitionMap.put("/imgs/**", "anon");
filterChainDefinitionMap.put("/js/**", "anon");
filterChainDefinitionMap.put("/plug/**", "anon");
filterChainDefinitionMap.put("/samples/**", "anon");
// 其余接口一律拦截
// 主要这行代码必须放在所有权限设置的最后,不然会导致所有 url 都被拦截
filterChainDefinitionMap.put("/**", "anon");
shiroFilterFactoryBean.setFilterChainDefinitionMap(filterChainDefinitionMap);
return shiroFilterFactoryBean;
}
4.4数据库表设计
4.4.0数据库三范式要求:
一、第一范式
1NF是对属性的原子性,要求属性具有原子性,不可再分解;
表:字段1、 字段2(字段2.1、字段2.2)、字段3 ......
如学生(学号,姓名,性别,出生年月日),如果认为最后一列还可以再分成(出生年,出生月,出生日),它就不是一范式了,否则就是;
二、第二范式
2NF是对记录的唯一性,要求记录有唯一标识,即实体的唯一性,即不存在部分依赖;
表:学号、课程号、姓名、学分;
这个表明显说明了两个事务:学生信息, 课程信息;由于非主键字段必须依赖主键,这里学分依赖课程号,姓名依赖与学号,所以不符合二范式。
可能会存在问题:
数据冗余:,每条记录都含有相同信息;
删除异常:删除所有学生成绩,就把课程信息全删除了;
插入异常:学生未选课,无法记录进数据库;
更新异常:调整课程学分,所有行都调整。
正确做法:
学生:Student(学号, 姓名);
课程:Course(课程号, 学分);
选课关系:StudentCourse(学号, 课程号, 成绩)。
三、第三范式
3NF是对字段的冗余性,要求任何字段不能由其他字段派生出来,它要求字段没有冗余,即不存在传递依赖;
表: 学号, 姓名, 年龄, 学院名称, 学院电话
因为存在依赖传递: (学号) → (学生)→(所在学院) → (学院电话) 。
可能会存在问题:
数据冗余:有重复值;
更新异常:有重复的冗余信息,修改时需要同时修改多条记录,否则会出现数据不一致的情况 。
正确做法:
学生:(学号, 姓名, 年龄, 所在学院);
学院:(学院, 电话)。
四、反范式化
一般说来,数据库只需满足第三范式(3NF)就行了。
没有冗余的数据库设计可以做到。但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是:在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余,达到以空间换时间的目的。
〖例〗:有一张存放商品的基本表,“金额”这个字段的存在,表明该表的设计不满足第三范式,因为“金额”可以由“单价”乘以“数量”得到,说明“金额”是冗余字段。但是,增加“金额”这个冗余字段,可以提高查询统计的速度,这就是以空间换时间的作法。
在Rose 2002中,规定列有两种类型:数据列和计算列。“金额”这样的列被称为“计算列”,而“单价”和“数量”这样的列被称为“数据列”。
五、范式化设计和反范式化设计的优缺点
5.1 范式化
优点:

缺点:

5.2 反范式化
优点:

缺点:

数据库采用mysql5版本、满足数据库设计三范式。
编码采用utf8 -- UTF-8 Unicode
排序规则采用utf8_general_ci
4.4.1数据库表ER图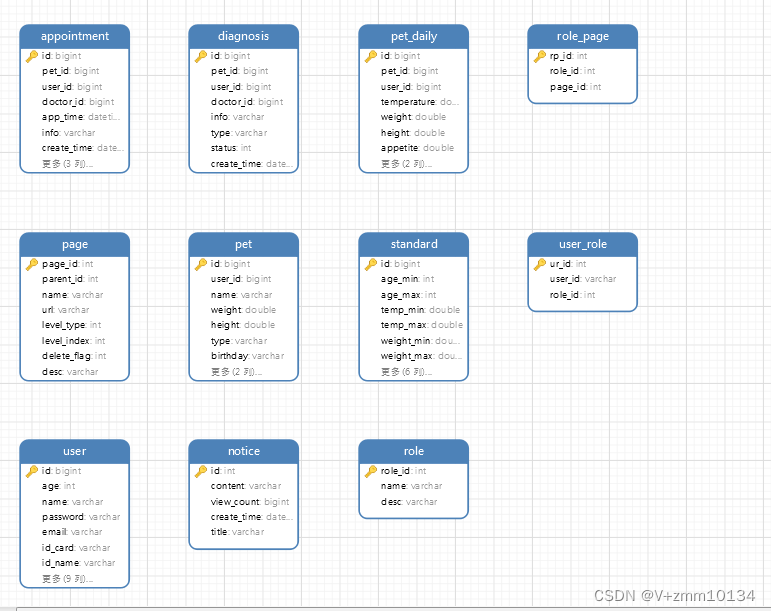

4.4.2用户表设计
主要字段有:用户名、密码、年龄、性别、邮箱、家庭地址、个人信息、头像、手机号等信息

4.4.3角色表设计
主要字段有:角色id、用户名

4.4.4菜单表设计
主要字段有:菜单id、pid、菜单名称、菜单路径、类型、等级、状态标识等字段

4.4.5宠物表设计
主要字段有:id、用户id、姓名、宠物名称、身高、类型、生日、时间、宠物照片等

4.4.5宠物诊断表设计
主要字段有:id、用户id、姓名、宠物id、宠物状态、类型等

4.4.6数据库sql文件
/*
Navicat Premium Data Transfer
Source Server : 139.155.39.185
Source Server Type : MySQL
Source Server Version : 50729
Source Host : 139.155.39.185:3306
Source Schema : phms
Target Server Type : MySQL
Target Server Version : 50729
File Encoding : 65001
Date: 15/07/2020 15:46:00
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for appointment
-- ----------------------------
DROP TABLE IF EXISTS `appointment`;
CREATE TABLE `appointment` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT,
`pet_id` bigint(20) DEFAULT NULL,
`user_id` bigint(20) DEFAULT NULL,
`doctor_id` bigint(20) DEFAULT NULL,
`app_time` datetime(0) DEFAULT NULL,
`info` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`create_time` datetime(0) DEFAULT NULL,
`status` int(5) DEFAULT NULL,
`phone` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`address` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 39 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of appointment
-- ----------------------------
INSERT INTO `appointment` VALUES (1, 1, 1, 1, '2020-04-23 20:33:08', '555', '2020-04-23 20:33:11', 4, NULL, NULL);
INSERT INTO `appointment` VALUES (2, 1, 1, 1, '2020-04-25 00:00:00', 'hhh', '2020-04-25 20:20:25', 4, '1776222', '555');
INSERT INTO `appointment` VALUES (3, 2, 1, 5, '2020-04-25 21:23:56', '6666', '2020-04-25 21:23:59', 4, '17788885555', '5555');
INSERT INTO `appointment` VALUES (4, 3, 6, 5, '2020-04-03 00:00:00', '555', '2020-04-25 22:51:43', 2, '17768583634', '8888');
INSERT INTO `appointment` VALUES (6, 3, 6, 9, '2020-04-25 00:00:00', '11', '2020-04-25 22:58:15', 4, '18899998888', '1111');
INSERT INTO `appointment` VALUES (7, 3, 6, 9, '2020-04-25 00:00:00', '111', '2020-04-25 23:03:26', 4, '11', '11');
INSERT INTO `appointment` VALUES (10, 6, 13, 5, '2020-04-28 00:00:00', '就医', '2020-04-26 08:17:33', 4, '18860887816', '江苏宜兴');
INSERT INTO `appointment` VALUES (11, 6, 13, 5, '2020-04-26 08:30:40', '宠物异常', '2020-04-26 08:30:43', 2, '18860887816', '江苏宜兴');
INSERT INTO `appointment` VALUES (12, 7, 13, 5, '2020-04-26 08:40:30', '就医', '2020-04-26 08:40:33', 2, '18860887816', '东北');
INSERT INTO `appointment` VALUES (13, 5, 11, 5, '2020-04-26 08:50:38', '发烧', '2020-04-26 08:50:40', 4, '18860777777', '天津');
INSERT INTO `appointment` VALUES (14, 8, 17, 5, '2020-04-26 14:05:52', '热热热', '2020-04-26 14:05:57', 4, '18860887816', '江苏宜兴');
INSERT INTO `appointment` VALUES (15, 9, 18, 5, '2020-04-26 16:46:36', '发烧', '2020-04-26 16:46:39', 2, '18860887711', '江苏');
INSERT INTO `appointment` VALUES (17, 11, 18, 26, '2020-04-26 17:20:55', '人人', '2020-04-26 17:20:58', 3, '18860887816', '人人');
INSERT INTO `appointment` VALUES (18, 12, 20, 21, '2020-04-26 17:34:04', 'qq', '2020-04-26 17:34:06', 4, '18860887816', '江苏宜兴');
INSERT INTO `appointment` VALUES (19, 12, 20, 26, '2020-04-26 17:34:04', 'qq', '2020-04-26 17:34:07', 3, '18860887816', '江苏宜兴');
INSERT INTO `appointment` VALUES (20, 14, 23, 21, '2020-04-26 19:12:33', '发烧', '2020-04-26 19:12:36', 4, '18860887711', '江苏');
INSERT INTO `appointment` VALUES (21, 16, 24, 21, '2020-04-26 19:42:43', '发烧', '2020-04-26 19:42:46', 4, '18860887711', '江苏');
INSERT INTO `appointment` VALUES (22, 17, 24, 26, '2020-04-26 21:35:13', '66666', '2020-04-26 21:35:16', 3, '18899998888', '555');
INSERT INTO `appointment` VALUES (23, 19, 25, 26, '2020-04-29 11:17:27', '感冒', '2020-04-29 11:17:29', 4, '18860887711', '江苏');
INSERT INTO `appointment` VALUES (24, 20, 1, 26, '2020-04-29 20:39:14', '生病', '2020-04-29 20:39:17', 3, '18888889998', '南京');
INSERT INTO `appointment` VALUES (25, 20, 1, 1, '2020-04-23 20:22:34', 'dd', '2020-05-01 13:34:48', 4, '1889999999', 'dd');
INSERT INTO `appointment` VALUES (26, 21, 1, 1, '2020-05-01 00:00:00', 'ddd', '2020-05-01 13:35:19', 4, '18899998888', '8888');
INSERT INTO `appointment` VALUES (27, 24, 25, 26, '2020-05-10 22:12:35', '1', '2020-05-10 22:12:38', 4, '18860882222', '江苏');
INSERT INTO `appointment` VALUES (28, 24, 25, 26, '2020-05-15 14:30:00', '发烧', '2020-05-15 20:57:16', 4, '18860883333', '江苏');
INSERT INTO `appointment` VALUES (29, 27, 25, 26, '2020-05-21 16:41:39', '发烧', '2020-05-21 16:41:42', 4, '18860884444', '江苏');
INSERT INTO `appointment` VALUES (30, 27, 25, 26, '2020-05-21 17:07:01', '感冒', '2020-05-21 17:07:04', 4, '18860882222', '江苏');
INSERT INTO `appointment` VALUES (31, 28, 25, 26, '2020-05-21 19:11:30', '感冒', '2020-05-21 19:11:32', 4, '18860881111', '江苏');
INSERT INTO `appointment` VALUES (32, 28, 25, NULL, '2020-04-26 00:00:00', '发烧', '2020-05-26 13:56:06', 1, '18860882222', '江苏');
INSERT INTO `appointment` VALUES (33, 28, 25, 26, '2020-05-03 00:00:00', '1', '2020-05-28 10:23:55', 3, '18860882222', '1');
INSERT INTO `appointment` VALUES (34, 28, 25, 26, '2020-05-03 00:00:00', '1', '2020-05-28 10:24:36', 3, '18860882222', '江苏');
INSERT INTO `appointment` VALUES (35, 28, 25, NULL, '2020-04-26 00:00:00', '1', '2020-05-28 10:29:33', 1, '18860882222', '江苏');
INSERT INTO `appointment` VALUES (36, 28, 25, 26, '2020-05-29 23:05:43', '感冒', '2020-05-29 23:05:45', 2, '18860882222', '江苏');
INSERT INTO `appointment` VALUES (37, 30, 25, 26, '2020-05-30 10:33:29', '感冒', '2020-05-30 10:33:33', 4, '18860882222', '江苏');
INSERT INTO `appointment` VALUES (38, 31, 38, NULL, '2020-07-02 00:00:00', '111', '2020-07-02 19:13:10', 1, '123', '111');
-- ----------------------------
-- Table structure for diagnosis
-- ----------------------------
DROP TABLE IF EXISTS `diagnosis`;
CREATE TABLE `diagnosis` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT,
`pet_id` bigint(20) DEFAULT NULL,
`user_id` bigint(20) DEFAULT NULL,
`doctor_id` bigint(20) DEFAULT NULL,
`info` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`type` int(5) DEFAULT NULL,
`status` int(5) DEFAULT NULL,
`create_time` datetime(0) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 21 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of diagnosis
-- ----------------------------
INSERT INTO `diagnosis` VALUES (15, 19, 25, 26, '注射疫苗', 2, 1, '2020-04-29 11:27:19');
INSERT INTO `diagnosis` VALUES (17, 20, 1, 1, 'ddd', 1, 1, '2020-05-01 13:37:02');
INSERT INTO `diagnosis` VALUES (18, 27, 25, 26, '就诊', 3, 1, '2020-05-21 17:07:43');
INSERT INTO `diagnosis` VALUES (19, 28, 25, 26, '感冒', 2, 1, '2020-05-21 19:12:05');
INSERT INTO `diagnosis` VALUES (20, 30, 25, 26, '治疗', 1, 1, '2020-05-30 10:35:01');
-- ----------------------------
-- Table structure for notice
-- ----------------------------
DROP TABLE IF EXISTS `notice`;
CREATE TABLE `notice` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT,
`content` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`view_count` bigint(20) DEFAULT NULL,
`create_time` datetime(0) DEFAULT NULL,
`title` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 9 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of notice
-- ----------------------------
INSERT INTO `notice` VALUES (2, '<p>狗狗大些才能打狂犬疫苗,每年打一次。而且必须在狗狗熟悉了新环境,身体健康的情况下才能打,疫苗期间不能洗澡。狗狗还要定期驱虫,吃驱虫药就行。驱虫和疫苗不要同时进行,间隔一两个礼拜比较好。驱虫幼犬隔3个月一次,成年犬隔半年一次。</p>\n\n<p>如果确定要给狗狗打疫苗,那每年注射是必要的,而且一般来说次年的疫苗应该比上一年的注射时间提早半个月到一个月,避免在疫苗快要失效的时候发生意外。</p>', 3, '2020-04-25 22:10:52', '宠物预防针多久打一次');
INSERT INTO `notice` VALUES (3, '<p>请填写文字内容</p>\n\n<p>如果你的小狗已经出现了一定情况的问题,那么请先从自己/现有环境的身上找原因——毕竟养狗行为课程,其实最重要的不是小狗,而是小狗的主人。</p>\n\n<p>我们对待小狗的方式,就是我们对待小孩,或者说是童年的自己的方式。是选择恐吓训斥,让他们永远失去好奇心,对周围充满恐惧?还是选择给小孩以积极尊重,探索周边,予以互动?培养小狗的自信心和成就感,也是重要的课程内容。</p>\n\n<p> </p>', 5, '2020-04-26 11:35:09', '养犬最重要的是什么?');
INSERT INTO `notice` VALUES (4, '<p>宠物........</p>', 2, '2020-04-26 19:15:57', '养犬');
INSERT INTO `notice` VALUES (5, '<p>怎么养宠物....</p>', 1, '2020-04-26 19:46:22', '养犬重要的是什么?');
INSERT INTO `notice` VALUES (6, '<p>怎么养宠物....</p>', 12, '2020-04-26 19:46:28', '养犬重要的是什么?');
INSERT INTO `notice` VALUES (8, '<p>宠物</p>', 1, '2020-05-30 10:37:36', '宠物');
-- ----------------------------
-- Table structure for page
-- ----------------------------
DROP TABLE IF EXISTS `page`;
CREATE TABLE `page` (
`page_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`parent_id` int(11) DEFAULT NULL COMMENT '父页面id',
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '页面名称',
`url` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '页面地址',
`level_type` int(11) DEFAULT NULL COMMENT '页面层级',
`level_index` int(11) DEFAULT NULL COMMENT '页面索引',
`delete_flag` int(1) UNSIGNED ZEROFILL NOT NULL DEFAULT 0 COMMENT '是否删除',
`desc` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '描述',
PRIMARY KEY (`page_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 39 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;