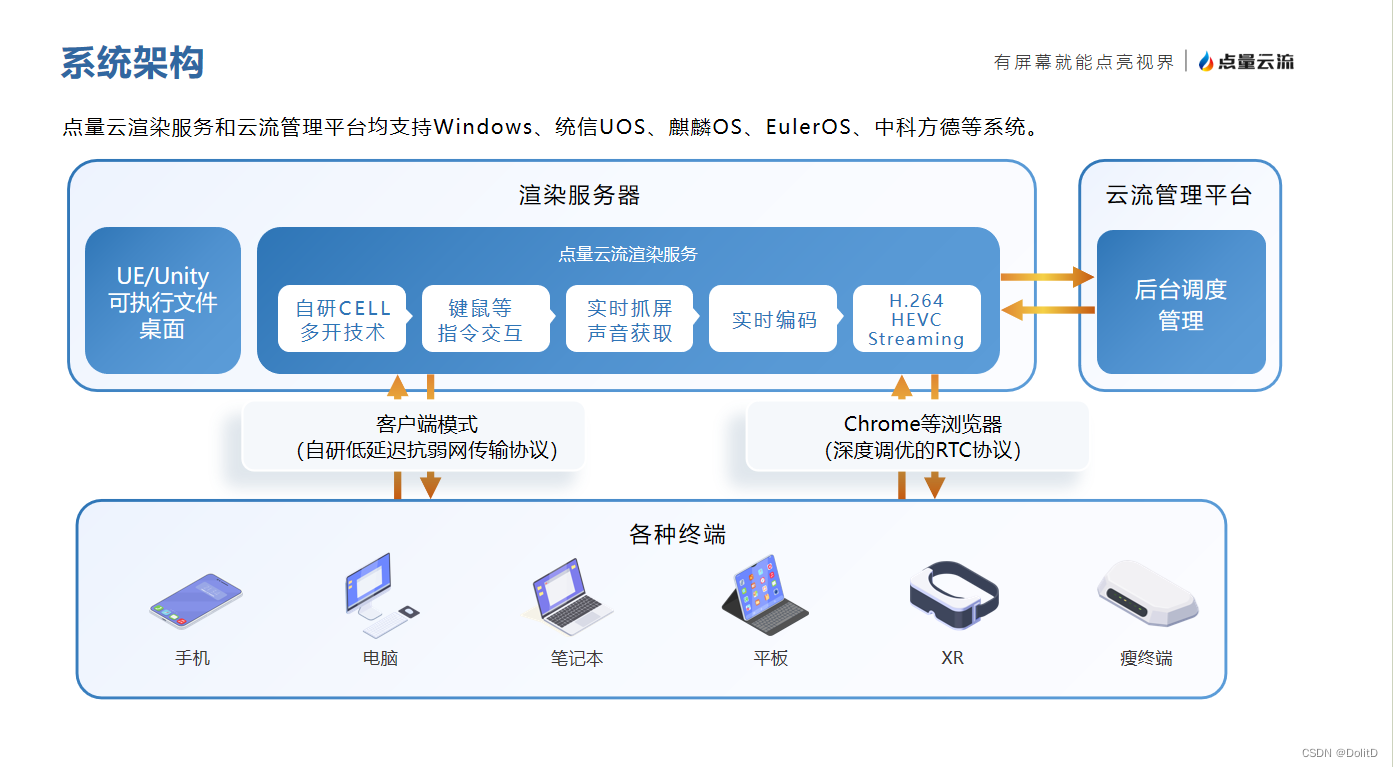
使用距离传感器数据预测驾驶路线
Werner Uhler, Michael Scherl and Bernd Lichtenberg
Robert Bosch GmbH
ABSTRACT
将距离传感器检测到的车辆分配到相对于本车的车道是未来驾驶辅助系统(如自适应巡航控制 (ACC))的一项重要且必要的任务。通过车辆前方物体的集体运动可以预测车辆自身的行驶路线。该方法不仅使用主车的数据来确定其自身的轨迹,还使用距离传感器的数据(提供车辆前方物体的距离和角度)来确定这些物体的轨迹。算法是使用离线模拟开发的,该模拟由从真实 ACC 车辆获得的记录数据提供。结果显示,与仅基于主车数据的其他方法相比,预测的行驶路线质量显著提高。特别是在曲率变化的情况下,例如弯道的起点,该算法有助于提高 ACC 的整体系统性能。
INTRODUCTION
当前和未来的驾驶员辅助系统(例如 ACC 或碰撞警告/避免系统)在评估当前交通状况方面面临共同的挑战。它们使用某种距离传感器检测车辆周围的车辆和其他物体。该传感器提供有关检测到的物体相对于车辆的位置的信息。然而,了解它们相对于车道的位置意味着更多地了解这些车道在汽车前方的走向。这个问题在 /1/ 中进行了描述。
有几种方法可以获得缺少的信息。一大类方法确定了汽车轨迹的实际曲率。当今的系统大多使用标准的车载传感器,例如车轮速度传感器,它根据车轮速度的差异和平均值生成曲率。或者,偏航率传感器和车速可以提供相同的信息。转向角传感器可用于辅助这两种方法。基本假设是两个。首先,假设汽车的轨迹与其车道密切相关。其次,假设车道的实际曲率是恒定的。违反第一个假设的后果很小,因为在许多情况下,预测车辆的轨迹比预测车道更重要,例如在变道时。然而,对于第二个假设来说,这并不正确。在曲线的开始或结束处,预测汽车的轨迹和车道都会出现严重错误。显然,这些系统误差不能仅通过局部确定曲率来克服。
第二类方法是使用传感器来观察汽车前方。通常使用视频传感器检测车道边界,例如参见 /2/。这样可以测量车道的曲率,而不必进行预测。提供有关汽车在车道中的位置、车道宽度、车道边界类型等的附加信息。然而,由于摄像机光学系统和摄像机分辨率迫使系统预测更大距离的值,因此测量距离被限制在 50-80 米左右。此外,视频传感器的性能很容易受到天气条件和白天(例如黄昏或黎明)的影响。同样众所周知的是检测道路边界的雷达传感器,例如参见 /3/ 和 /4/。使用这种方法进行车道预测需要传感器具有良好的横向分辨率,这使得它们更加昂贵。此外,知道道路边界附近站立物体的位置并不意味着知道车道的走向,因为缺乏有关它们的数量和宽度的信息。这些真正具有预测性的系统的一个共同特点似乎是相当多的额外成本。
第三,可以使用导航系统来预测车道。很容易估计,确定本车位置的精度必须在典型车道宽度范围内,以便将其他车辆分配到正确的车道。如今,标准导航系统即使基于 GPS,最差情况下的精度也约为 50 米。使用差分 GPS 确实意味着相当大的改进。尽管如此,这些系统在城市地区和使用最新地图时仍存在困难。然而,使用导航数据来增强车道预测并提供有关交叉路口等的信息似乎很有希望。
支持车道预测的一个非常有前途的方法是整合有关其他车辆轨迹的信息。/5/ 中给出了一个例子。当然,这些轨迹通常与车道的走向不同,就像自己的车的轨迹一样。但在这里我们有机会使用许多轨迹来进行统计评估。通过这种方法,可以将变道或离开道路的汽车与其他数据区分开来。在本文中,我们描述了一种从记录的其他车辆位置数据中获取预测车道信息的方法。
DESCRIPTION OF THE ALGORITHM
基础知识 — 此处介绍的方法的基本思想是测量本车前方沿同一方向行驶的其他车辆的位置。这些车辆的每辆车的位置都单独记录。在每个时间步骤中,这些位置都会转换为实际车辆坐标系。因此,对于每个物体,我们在任何时候都有多个位置,代表其相对于主车当前位置和坐标系的轨迹。
让我们对其他车辆相对于主车辆的横向偏移做出一些基本定义。这些定义如图 1 所示。
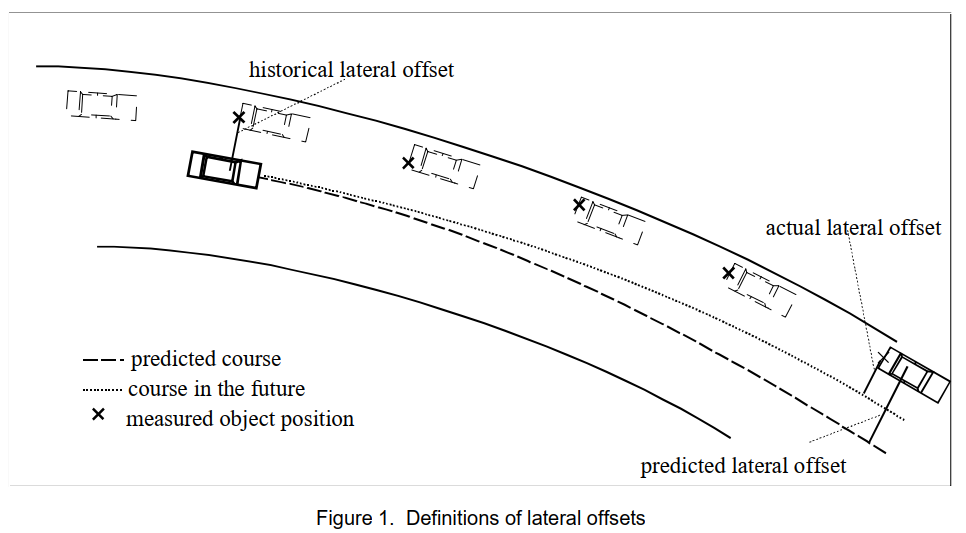
1.实际横向偏移是到达主车所在位置时,对方车辆当前位置与主车所在位置之间的横向距离。此值无法在当前测量,因为您必须知道主车未来的准确轨迹。
2.历史横向偏移定义为主车当前位置处 主车与其他车辆记录位置之间的横向距离。
历史横向偏移,说的应该是其他车辆记录的历史位置在自车所在的s处的 l 值吧,也就是拿自车的当前位置和其他车辆的历史位置对比
3.预测横向偏移量是指在其他车辆的距离处,其他车辆的当前位置与主车辆的预测位置之间的横向距离。
由于无法测量实际横向偏移,因此可以用预测横向偏移来近似,然后使用预测横向偏移来确定其他车辆与主车运动的相关性。预测横向偏移大于车道宽度一半的车辆被认为与主车运动无关1。然而,这需要对主车的轨迹进行精确预测。如上所述,局部预测在曲线的开始和结束处会受到系统误差的影响。
另一方面,也可以使用历史横向偏移。可以使用其他车辆的记录数据轻松确定。基本假设是,其值的显著变化(即变化约半个车道宽度或更多)很少发生。很明显,其他车辆的车道变换会导致系统误差,而该方法不受车道曲率变化的影响。
基本假设是车辆沿着车道走,当前车变道的话估算会变差吗???在这个过程中自车的状态传感器需要非常准吧,如果不准那自车的状态轨迹就不准确了,坐标转换也会不准确吧。。。
应该提到单独使用历史横向偏移的一个主要缺点:远距离范围内的新物体进入距离传感器的检测区域需要很长时间才能为其分配历史横向偏移,即主车辆必须先到达原始位置。当接近速度明显较慢的车辆时,这会产生严重后果。举例来说,假设一辆汽车以自己汽车一半的速度行驶,在 100 米的范围内被检测到。到达这个位置时,另一辆车的距离缩短到 50 米。ACC 或碰撞警告/避让系统必须更早地决定另一辆车对其自身安全舒适行驶的相关性。因此,必须考虑有关前方车道走向的额外预测信息,以实现可靠的系统性能。
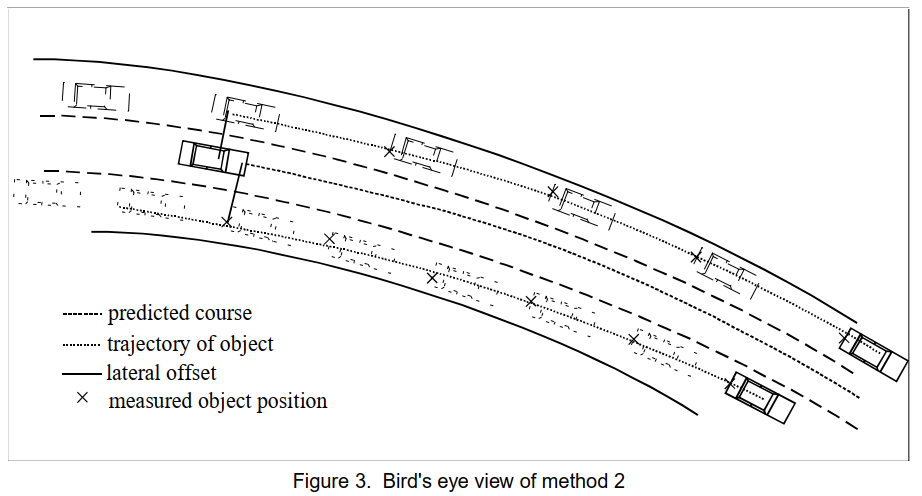
幸运的是,我们可以获得缺少的信息。图2和图3说明了两种不同的方法。
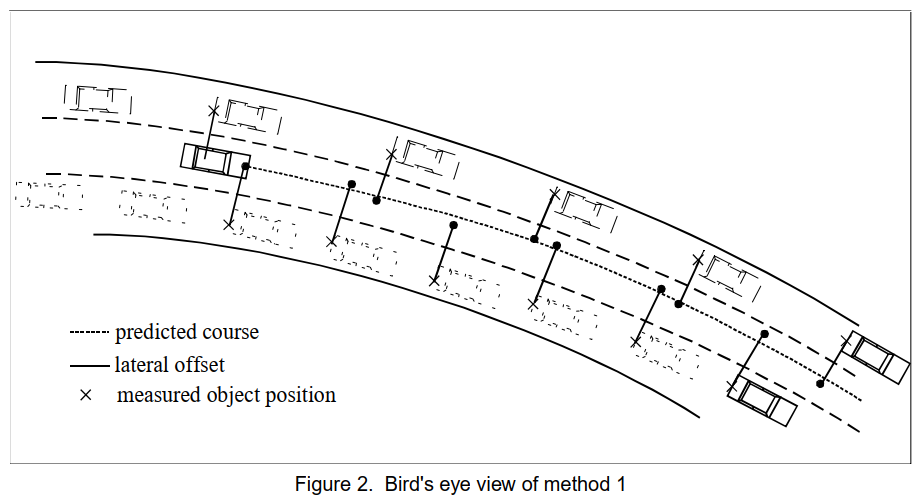
第一种方法的基本思想是使用有关其他车辆的所有数据构建一条预测轨迹。如果没有发生车道变换,则其他车辆的轨迹与主车的预期轨迹相同,只是横向偏移。因此,已确定历史横向偏移的每辆车的测量位置将横向偏移其历史横向偏移的负值。这给出了主车前方的多个点,这些点代表了所有测量轨迹的叠加,这些轨迹移动到主车坐标系的原点。现在,可以将模型轨迹拟合到这些点,从而得到主车的预测轨迹。只要测量了足够数量的车辆,就可以预期统计波动会得到补偿。在这种情况下,车道变换引起的系统误差也将得到一定程度的抑制。
我们认为第二种方法更有效,它分别考虑其他车辆的轨迹。该方法如图 3 所示。
在第二种方法中的意思应该是障碍物的轨迹和自车比较近时(半个车身之类的)认为是要跟踪的目标,如果是新出现的一个障碍物,那是不是可以让他和之前跟踪过的障碍物进行横向距离l1的计算,自车和跟踪过的障碍物进行横向l2计算,在通过abs(l1-l2) 来计算自车和短时间跟踪过的障碍物之间的横向距离。
根据每辆车的测量位置拟合出模型轨迹。从该拟合中可以得出该轨迹的相关参数,如横向偏移和曲率。可以对这些参数进行统计处理,以消除极端值或不合理的值。这会产生参数的平均值,在大多数情况下,这允许通过真实预览预测主车的轨迹。
两种方法之间最显著的区别显而易见。一方面,第二种方法要求每条轨迹的测量位置数量最少,以便进行可靠的拟合。在第一种方法中,甚至可以使用单个测量点,只要已经测量了该物体的历史横向偏移。另一方面,这是该方法最严重的限制:测量数据的使用仅限于那些已经确定了历史横向偏移的物体。
数据采集 – 在每个时间步骤中,距离传感器检测到的所有车辆的位置数据都会被收集起来。距离传感器的跟踪为每个物体分配一个识别号。属于一个识别号的数据被组合在一起,形成相应物体的轨迹。为了说明这一点,想象一下其他车辆在不同时间在道路上的各自位置放置“标记”。然后,轨迹由属于一个物体的这些标记的位置定义。创建新标记时,数据会添加到轨迹中。当主车辆经过其中一个标记时,数据会从轨迹中删除。
当主车辆经过其中一个标记时,数据会从轨迹中删除
存储这些数据的一种有效方法是使用环形缓冲区,每个对象一个。这些环形缓冲区可以看作是一个“数据矩阵”,每行都有一个起始指针和一个结束指针,见图 4。
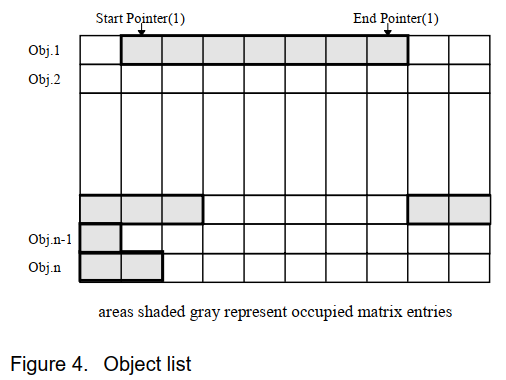
输入新对象数据意味着将相应行的结束指针移动一个条目,并将数据存储在此位置。删除对象的数据通过将起始指针移动一个条目来反映
对于新物体,将使用数据矩阵中的空行。如果没有空行,则必须决定是否清除已占用的行或是否必须拒绝新物体(见下文)。如果物体突然消失(例如离开距离传感器的检测区域),则可以使用其相应的数据,直到主车辆到达最后测量的位置。
数据是在主车运动过程中收集的。这意味着测量的物体相对位置对应于不同的车辆坐标系。主车会从一个时间步骤平移和旋转。在较早的时间步骤收集的数据必须转换到实际的车辆坐标系。这可以通过补偿主车平移和旋转的变换来实现,见图5。
对这么多历史数据进行坐标转换会不会很耗费计算资源呢???
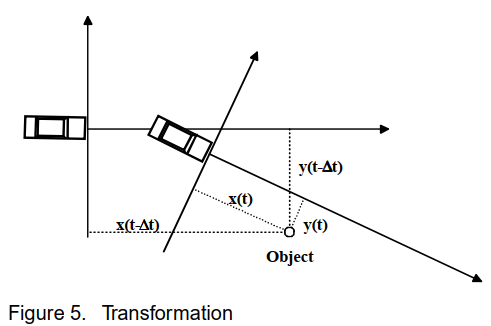
对于小的时间步长 ∆t,可以显示[2]
[2]. In this approximation sine and cosine can well be replaced by their quadratic approximations.
[2]. 在这个近似中,正弦和余弦可以用它们的二次近似来代替。
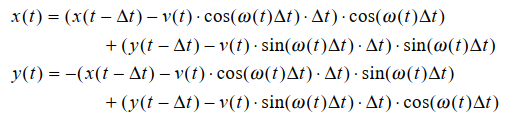
其中 x(t)、y(t) 表示固定位置(道路上的“标记”)相对于主车坐标系在时间 t 的分量,v(t) 表示主车在时间 t 的速度,ω(t) 表示主车的偏航率。因此,在任何时间步骤中,都会测量 v(t) 和 ω(t) 的值,并将 x(t-∆t)、y(t-∆t) 的值更新为 x(t)、y(t)
所用偏航率信号的质量至关重要。恒定偏移会导致严重影响 y(t) 的误差,而 x(t) 则相对稳健。加性白噪声导致的困难较少,因为这种噪声的贡献会随着时间步骤而部分补偿。这可以通过计算闭合路径的轨迹很好地说明,请参阅本文的“测量”部分。
如果偏航率(yawrate)信号质量不好是不是就没法用了?有办法进行矫正吗?
ACC 所需的最大前视距离约为 5 秒。**使用优化的偏航率信号,我们可以估算出在此时间内计算主车横向位置的最大误差约为 0.5 米**。在大多数情况下,实际误差会明显低于这个数字。
是怎么优化的???
另一个关键点是距离传感器提供的物体横向偏移的质量。通常,新物体是在距离传感器的远距离范围内检测到的,特别是横向偏移测量的质量相对较差。上述两种方法都必须使用这些首次测量来尽早确定物体的横向偏移。因此,很明显,距离传感器的精度决定了这两种方法对新物体的反应时间和质量。
曲率和横向偏移的统计评估——在本章中,我们将描述如何根据测量和转换的位置数据计算车道预测数据。
方法 1 使用所有车辆的数据,并计算出历史横向偏移。每个位置在 y 方向上移动相应历史横向偏移的负值。换句话说,所有轨迹都向主车辆移动。现在,模型轨迹通过最小均方拟合拟合到所有这些数据位置[3] ,见图 2。为简单起见,我们忽略侧偏角,使用
y
(
x
)
=
c
0
+
c
2
x
2
y(x) = c_0 + c_2 x^2
y(x)=c0+c2x2 作为拟合曲线,拟合参数为
c
2
c_2
c2 ,但需要令
c
0
=
0
c_0 = 0
c0=0,因为这在我们调查的所有情况下都被证明是足够的。若也将
c
0
c_0
c0 作为拟合参数会使
c
2
c_2
c2 的确定对测量误差(例如由于传感器噪声)的稳定性降低。最后,前方车道的曲率
κ
κ
κ 通过
κ
=
2
c
2
κ = 2 c_2
κ=2c2 确定。
[3]. If qualities for the measured positions are available, e.g. if provided by the distance sensor, they can be taken into account during the fit procedure.
[3]. 如果测量位置的质量可用,例如如果由距离传感器提供,则可以在拟合过程中将其考虑在内。
方法 2 更为复杂。每辆车的位置数据被单独处理,即为每辆车的轨迹拟合一条模型曲线 [3] ,见图 3。该模型曲线再次为
y
k
(
x
)
=
c
k
,
0
+
c
k
,
2
x
2
y_k(x) = c_{k,0} + c_{k,2} x^2
yk(x)=ck,0+ck,2x2,但现在
c
k
,
0
和
c
k
,
2
c_{k,0} 和 c_{k,2}
ck,0和ck,2 都被视为拟合参数。索引
k
k
k 表示轨迹的编号,代表相应车辆的编号。
拟合参数
c
k
,
0
c_{k,0}
ck,0 可视为车辆
k
k
k 的横向偏移。这是方法 2 相对于方法 1 的主要优势:如果主车尚未到达另一辆车的第一个位置,则可以预测性地确定车辆的横向偏移。此外,应注意的是,该横向偏移是汽车当前位置与许多测量值的拟合曲线之间的横向距离。因此,该值对于单个测量误差具有相对稳健性。
方法2的优势:主车未到达前车的历史位置时就可以计算得到横向偏移
很容易想象,不同轨迹的拟合参数具有不同的质量。质量受****测量位置的距离和分布、属于相应轨迹的测量值的数量和变化、参数值的合理性等影响。这将通过图 6 中的示例说明距离和测量值的分布。
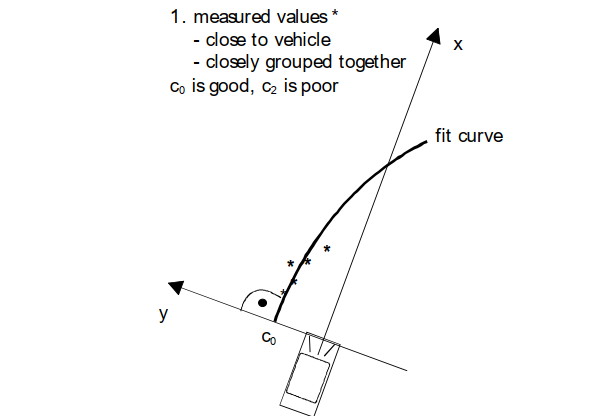
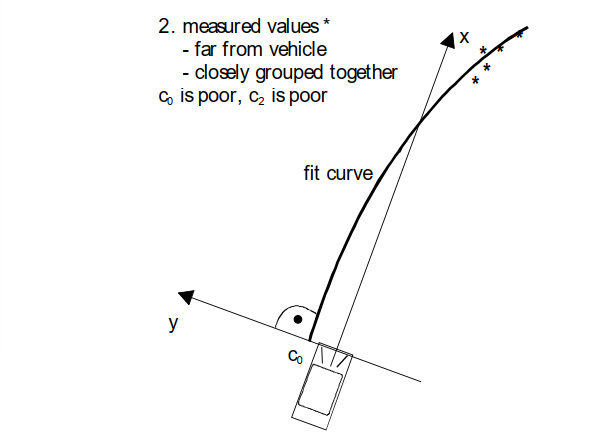
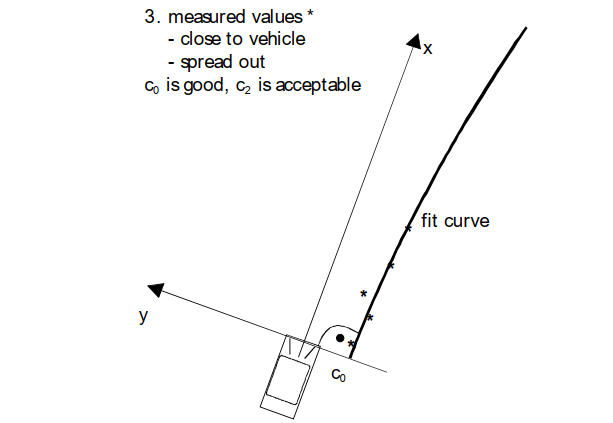
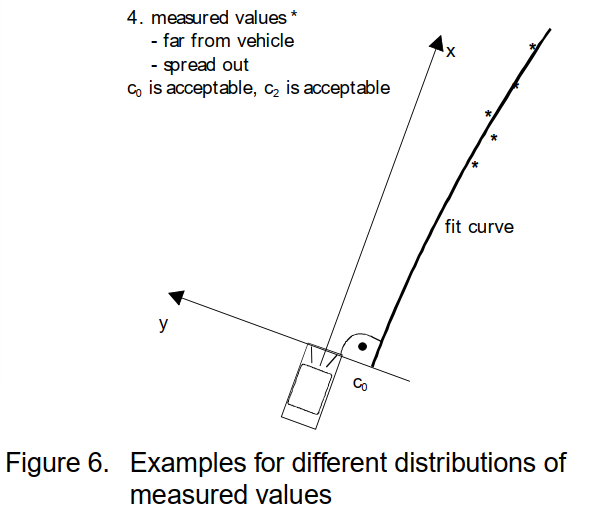
这种推理可以扩展到所有其他情况
因此,每个值
c
k
,
0
和
c
k
,
2
c_{k,0} 和 c_{k,2}
ck,0和ck,2 都分配了一个质量。这有助于将
c
k
,
0
c_{k,0}
ck,0 与从其他方法(例如介绍中所述的方法)得出的值进行比较。此外,这些质量允许合并这些值以具有与特定辅助系统的统一接口。
关于
c
k
,
2
c_{k,2}
ck,2,可以使用相应的质量得出前方车道曲率的最佳值。特定
c
k
,
2
c_{k,2}
ck,2 的贡献应取决于其质量,即质量低的值贡献很小。此外,曲率必须对变道车辆的值具有鲁棒性。所有这些都可以通过使用加权中值滤波器过滤
c
k
,
2
c_{k,2}
ck,2 来实现,质量用作权重。众所周知,中值滤波器对极端值具有鲁棒性。在我们的案例中,这意味着如果其他被测车辆保持在自己的车道上,则车辆的变道将被忽略。
对于 c k , 2 c_{k,2} ck,2 按照其拟合的质量来做加权中值滤波,把高质量的轨迹用起来
内存管理 – 要在 ECU 中实施该方法,应限制计算机内存的使用。因此,数据矩阵应保持较小。这意味着一次只能管理少量车辆轨迹。如果测量的车辆数量多于数据矩阵中可存储的数量,则必须决定使用哪些轨迹。
一般来说,新对象会被写入数据矩阵的空行。但如果数据矩阵已满,并且出现了新车辆,我们必须估计所有轨迹对未来车道预测的有用性。想象一下新车以较高的相对速度超越主车。可以预期这辆车会在相对较短的时间内产生一条较长的前方轨迹。因此,它对车道预测非常有价值。相比之下,速度慢得多的车辆不会给出延伸到整个传感器范围的轨迹,从而大大降低了其价值。
快车由于短时间内的行驶轨迹比较长,拟合的价值较高,
相反慢车拟合轨迹的价值很低
必须将这种有用性的评估应用于数据矩阵中的所有轨迹以及新车辆的预测轨迹。换句话说,我们必须预测轨迹的相应质量。然而,对于新车来说,只有与其运动相关的质量贡献才是可直接预测的。因此,在将新车与现有车辆进行比较时,只需考虑这些贡献。
在每个时间步骤中,计算并比较所有现有轨迹的预测质量和可能的新车辆的预测质量。如果后者超过前者,则数据矩阵中预测质量最低的条目将被新对象替换。
这里介绍了一些在有限内存空间中有效和合理存储和计算障碍车辆轨迹的方法
另一方面,当物体到达最后一个位置后,或者当记录的位置数少于最小值时,物体就会从数据矩阵中删除。
如果障碍物丢失的话,是不是判断几次还没有出现是不是就可以清空了,因为再出来的时候和之前的数据可能也差距较大了,导致拟合出现异常???
MEASUREMENTS
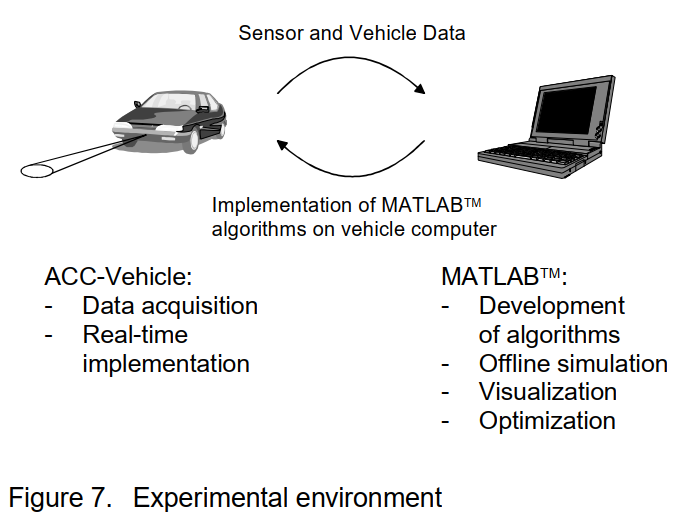
实验环境 – 为了开发和优化所有算法,我们使用了合成数据和真实交通数据。后者记录在一辆配备雷达传感器的真实 ACC 车辆中,该雷达传感器提供最远 150 米的物体距离和约 ± 5 度范围内的横向位置。附加传感器提供主车辆数据,如速度、偏航率等。车辆和距离传感器数据使用 CAN(控制器局域网)接口实时记录并存储在数据文件中。此外,所有交通场景均由视频系统记录。
第二步,将数据文件用作 Matlab中实现的驾驶路线预测算法的离线模拟的输入。所有算法的开发、优化和结果可视化均使用 Matlab完成。
优化算法使用 C 编程语言进行编码,并在车载计算机上执行,以在实时条件下测试系统。我们的实验装置如图 7 所示。
测量结果 – 驾驶路线预测算法使用主车的传感器数据来计算其自身轨迹。这需要将所有记录的位置转换为实际车辆坐标系。由于有几种不同的传感器可以确定偏航率,因此对 4 种可能性进行了评估。
偏航率可从以下传感器获得:
• 偏航率传感器,
• 横向加速度传感器,
• 转向角传感器,
• 前(非动力)轴的车轮速度差。
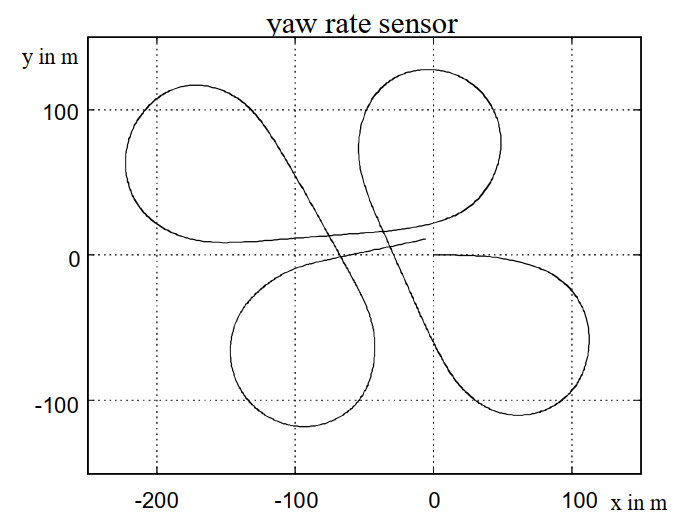
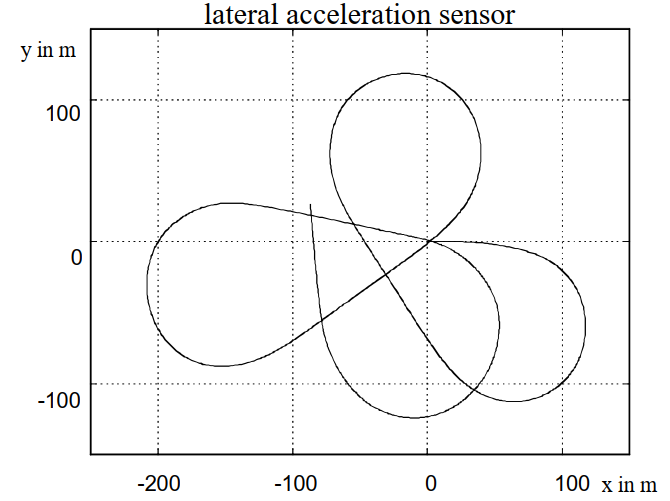
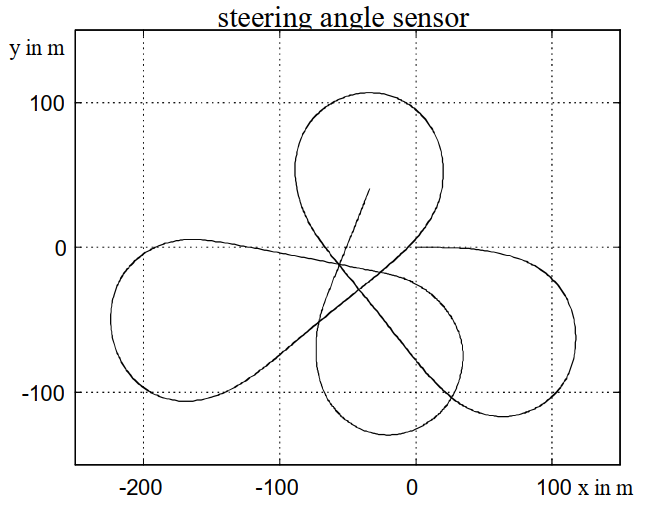
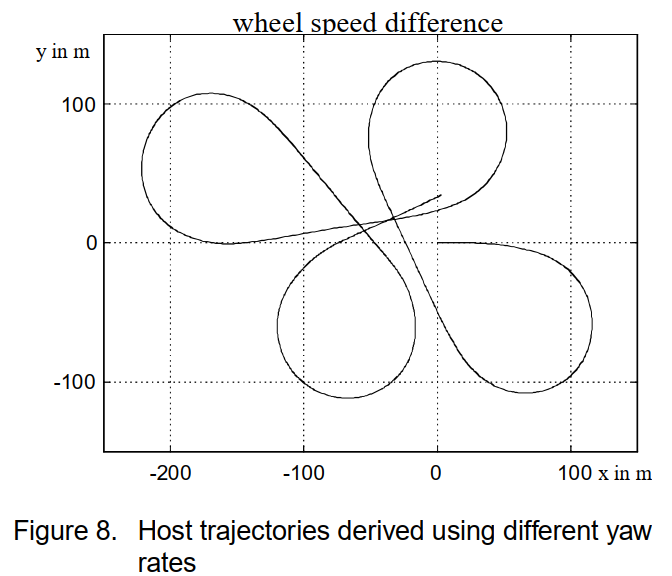
沿着高速公路的苜蓿叶形车道进行了试驾。车辆轨迹形成一条封闭的轨道,耗时约 120 秒。在试驾期间,记录了上述所有信号。图 8 显示了基于来自四个源的偏航率信号计算出的轨迹。在每种情况下,汽车都从原点出发,朝着正 x 方向行驶。很容易看出,偏航率传感器提供的信号具有最佳的长期稳定性。在约 120 秒的积分时间后,测量结束时的位置和方向与起点最吻合。考虑到主轨迹的通常积分时间短于 5 秒,获得的横向位置精度小于 0.5 米。由于距离传感器对横向位置的测量误差处于同一数量级,因此这被认为是足够的。因此,两种驾驶路线预测方法均基于偏航率传感器。
可以通过这种方法测试一下我们的横摆角速度传感器的精度,看看画几个圈回到起点之后轨迹能不能对的上
为了说明驾驶路线预测的潜力和稳健性,图 9 显示了两种方法的结果。记录的交通状况是交通相当密集的 3 车道高速公路上右转弯的起点。主车行驶在中间车道。绘制了方法 1 和 2 的预测曲率随时间的变化图。此外,还显示了从偏航率信号得出的曲率以及参考曲率。参考曲率是通过使用主车的综合轨迹进行离线计算获得的。它是相对于当前位置在 ± 1.0 s 的时间间隔内曲率值的平均值。参考和偏航率曲率之间约 0.2 s 的时间偏移是由于后者的滤波延迟。将预测曲率的结果与参考曲率进行比较,可以看出两种方法都可以明显更早地识别曲线,即大约 1 s。 (方法 1 在大于 48.5 秒时失败的原因将在下面讨论。)这一事实清楚地表明了这两种方法都有可能提前识别曲率的变化,从而有助于避免其他车辆分配错误的车道。
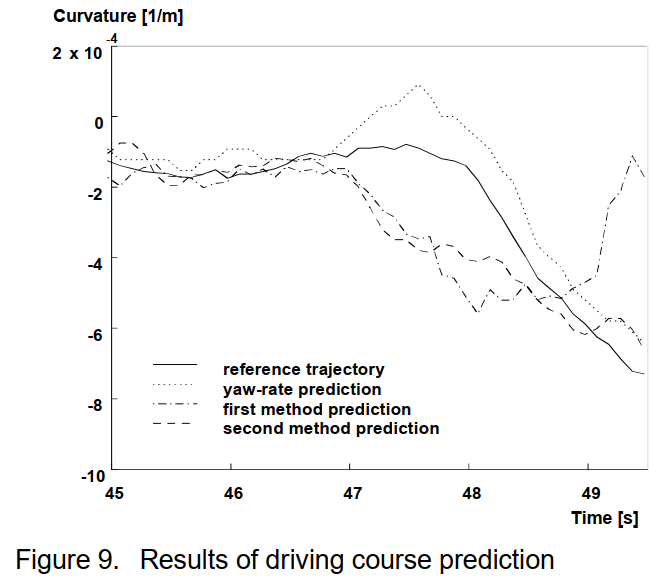
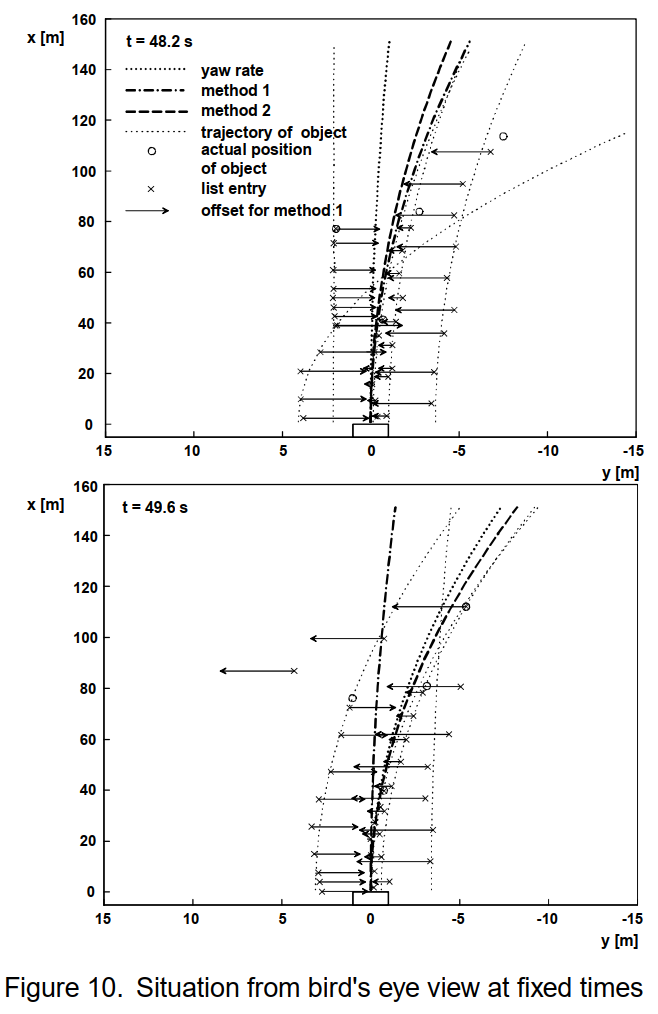
图 10 显示了 t = 48.2 s 和 t = 49.6 s 时车辆坐标系中的鸟瞰图情况。记录的本车前方物体的所有位置均以 “x” 标记。方法 1 中所有相关物体的移动位置均以相应箭头表示。不同物体的实际位置以 “o” 标记。虚线表示每个物体的轨迹。在 t = 48.2 s 时,可以看出两种方法均提供了右弯曲率,而偏航率仍可产生如上所述的直线路线预测。在 t = 49.6 s 时,本车已进入弯道,基于偏航率的曲率符合方法 2 的结果。令人惊讶的是,方法 1 现在与现实有很大偏差。这是由于雷达传感器在测量右车道上车辆的横向位置时出现严重误差。测量距离约为 88 米,测量横向位置约为 4 米,位于左侧车道。由于方法 1 将此点包含在最小二乘拟合中,因此结果相当差。另一方面,方法 2 使用中值滤波器。位置错误的轨迹会产生完全不同的曲率,与所有其他轨迹相比质量较低。因此,中值滤波器会忽略它。因此,方法 2 对传感器误差的鲁棒性比方法 1 好得多。
基于偏航率的曲率怎么理解???
位置错误的轨迹和其他轨迹相比 “质量较低”,中值滤波器会忽略它。
同样的论点也适用于对其他车辆变道的鲁棒性。变道车辆的轨迹产生的曲率与其他物体的曲率大不相同。同样,方法 2 的中值滤波器确保该轨迹对结果没有影响或影响很小,前提是测量了足够数量的其他车辆。
变道车辆的轨迹的曲率其实也是会影响到自车的预测的,如果车辆很多的话就影响不大了,但是如果只有一个变道的车岂不是影响很大???怎么规避呢???
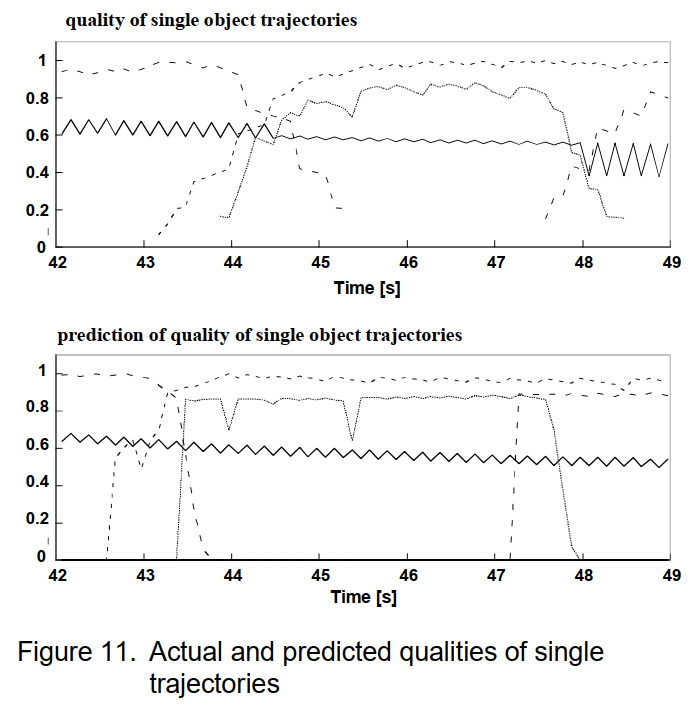
保持低内存消耗的一个重要特性是在对象列表已满的情况下选择相关对象。此选择基于对象应该提前一定时间的预测质量。图 11 显示了单个对象轨迹的实际质量和预测质量的比较。必须提到的是,单个轨迹的整体质量由两个因素组成:可预测部分和不可预测部分。对象的选择当然完全基于可预测部分。从图 11 中可以看出,仅显示可预测部分,预测质量与实际质量相比移到了更早的时间。这证明预测按预期工作。应该注意的是,与实际质量相比,上升和下降时间要短得多。这是因为预测无法预测车辆的首次检测。然后它立即跳转到未来真实轨迹将显示的值,导致急剧上升。
没太看懂下面这个图,没有图例
CONCLUSION
在本文中,我们介绍了两种基于测量和记录的其他车辆位置数据来预测主车轨迹的方法。预测的质量取决于跟踪车辆的数量、车道变换次数以及距离传感器信号的质量。主车的车道变换和车道曲率变化(例如进入或离开弯道时)不会影响预测。预览时间通常超过 1 秒,具体取决于前方车辆的状况。
第二种方法似乎很有前景。它分别分析每辆车的轨迹,提取相应的参数并分配质量。基于这些值的统计分析计算出代表性轨迹参数,以预测主车的运动。事实证明,在记录的车辆数量足够的情况下,这种方法对其他车辆变道等奇异事件和距离传感器的测量误差具有很强的鲁棒性。
距离传感器信号的准确性对于结果的质量至关重要。如果横向位置的质量太差,即使是第二种方法的拟合程序也无法补偿测量误差。传感器必须具有可靠的物体跟踪功能,以便记录对预测最有价值的长轨迹。此外,还应实施有效的物体聚类,即将一辆车(通常是卡车)的多个反射归类为一个物体。否则,分配给数据矩阵的内存将过早耗尽。
当然,这里介绍的预测方法不能取代其他方法,例如使用偏航率传感器。但是,它确实有效地支持仅使用本地确定主车辆轨迹的系统,方法是在有其他车辆的情况下提供真正的前瞻。
ACKNOWLEDGMENTS
作者要感谢罗伯特博世有限公司的 Hermann Winner 贡献了部分初步想法,并感谢罗伯特博世有限公司的 Harald Michi 在整个项目期间的密切合作。
REFERENCES



![小红书评论爬取使用教程[八猪采集器]](https://img-blog.csdnimg.cn/img_convert/8926593b2057d4b101fda5c042b94811.png)