欢迎收藏Star我的Machine Learning Blog:https://github.com/purepisces/Wenqing-Machine_Learning_Blog。如果收藏star, 有问题可以随时与我交流, 谢谢大家!
Airbnb租赁搜索排名
1. 问题陈述
Airbnb用户在特定地点搜索可用房源。系统应在搜索结果中对多个房源进行排序,使预订频率最高的房源排在最前面。

一种简单的方法是设计一个自定义评分排序函数,例如基于查询的文本相似度评分。然而,这种方法效果不好,因为相似性并不能保证预订。
更好的方法是根据预订的可能性对结果进行排序。我们可以建立一个监督学习模型来预测预订的可能性。这是一个二分类模型,即分类预订和未预订。
2. 指标设计和要求
指标
离线指标
-
折扣累积增益 (DCG):
D C G p = ∑ i = 1 p r e l i log 2 ( i + 1 ) DCG_p = \sum_{i=1}^{p} \frac{rel_i}{\log_2(i + 1)} DCGp=i=1∑plog2(i+1)reli
- p p p 是排名列表中的位置。
- r e l i rel_i reli 表示位置 i i i处结果的相关性。
-
理想折扣累积增益 (IDCG):
I D C G p = ∑ i = 1 ∣ R E L p ∣ 2 r e l i − 1 log 2 ( i + 1 ) IDCG_p = \sum_{i=1}^{|REL_p|} \frac{2^{rel_i} - 1}{\log_2(i + 1)} IDCGp=i=1∑∣RELp∣log2(i+1)2reli−1
- ∣ R E L p ∣ |REL_p| ∣RELp∣ 表示理想排序列表中考虑的前 p p p个位置的相关性分数数量。实质上,它是理想排序列表中前 p p p个位置的相关性分数的计数。
-
归一化折扣累积增益 (nDCG):
n D C G p = D C G p I D C G p nDCG_p = \frac{DCG_p}{IDCG_p} nDCGp=IDCGpDCGp
DCG是根据结果的预测排名计算的。DCG计算中使用的相关性分数是对应预测位置的真实相关性分数。
IDCG是根据结果的理想排名计算的,这意味着按真实相关性分数降序排列结果。IDCG计算中使用的相关性分数也是实际的真实相关性分数。
nDCG是DCG与IDCG的比率,提供了比较不同排名系统的归一化分数。nDCG的值范围在0到1之间,1表示完美排名。
在线指标
-
转化率和收入提升: 这衡量了用户会话中每次搜索结果的预订数量。
c o n v e r s i o n r a t e = n u m b e r o f b o o k i n g s n u m b e r o f s e a r c h r e s u l t s conversionrate = \frac{numberofbookings}{numberofsearchresults} conversionrate=numberofsearchresultsnumberofbookings
要求
训练
- 不平衡数据和明确的会话: 普通用户在决定预订之前可能会进行大量研究。因此,未预订标签的数量远远超过预订标签的数量。
- 训练/验证数据分割: 通过时间分割数据以模拟生产流量。例如,选择一个特定日期来分割训练和验证数据。使用该日期之前几周的数据作为训练数据,并使用该日期之后几天的数据作为验证数据。
明确的会话通常由一段连续的用户活动周期定义,没有显著的中断。会话的结束可以由用户一段时间内的不活动、注销或应用定义的其他标准标记。
模拟生产流量: 在分割训练和验证数据时,重要的是尽可能模拟真实世界的情况。在Airbnb的搜索排名系统的背景下,我们希望确保模型在过去的数据上进行训练,并在未来的数据上进行验证,以模拟其在生产环境中的表现。通过按时间分割数据,我们确保模型在未见过的数据上进行测试,类似于它在实时环境中遇到新的用户交互。
推理
- 服务: 搜索排名的低延迟(50ms - 100ms)。
- 对新房源的低估: 全新房源可能没有足够的数据让模型估算可能性,这可能导致对新房源的低估。
摘要
| 类型 | 预期目标 |
|---|---|
| 指标 | 实现高归一化折扣累积增益指标 |
| 训练 | 能够处理不平衡数据 |
| 按时间分割训练数据和验证数据 | |
| 推理 | 延迟从50ms到100ms |
| 能够避免对新房源的低估 |
3. 模型
特征工程
- 房源的地理位置(纬度/经度): 使用原始的纬度和经度特征进行建模非常困难,因为特征分布不平滑。解决这个问题的一种方法是分别对纬度和经度距离地图中心的距离取对数。
- 最喜欢的地方: 将用户最喜欢的社区地点存储在一个二维网格中。例如,用户将39号码头添加为最喜欢的地方,我们将此地点编码到一个特定的单元格中,然后在训练/服务之前使用嵌入。
| 特征 | 特征工程 | 描述 |
|---|---|---|
| 房源ID | 房源ID嵌入 | |
| 房源特征 | 卧室数量,设施列表,房源所在城市 | |
| 位置 | 从用户地图中心测量纬度/经度,然后归一化 | |
| 历史搜索查询 | 文本嵌入 | |
| 用户相关特征: 年龄,性别 | 归一化或标准化 | |
| 之前的预订数量 | 归一化或标准化 | |
| 之前的住宿时长 | 归一化或标准化 | |
| 时间相关特征 | 月份,年份中的周数,假期,星期几,小时 |
特征及其工程
房源ID
特征工程: 房源ID嵌入
描述: 每个房源都有一个唯一的标识符。使用嵌入可以让模型学习房源的密集表示,捕捉预订行为中的相似性和模式。
示例: 房源ID 12345可能表示为嵌入向量[0.1, -0.2, 0.5]。
房源特征
特征工程: 卧室数量,设施列表,房源所在城市
描述: 这些特征描述了房源本身,包括卧室数量、设施(如游泳池、Wi-Fi)以及房源所在的城市。
示例: 某房源可能有3间卧室,设施包括游泳池和Wi-Fi,位于旧金山。
位置
特征工程: 从用户地图中心测量纬度/经度,然后归一化
描述: 不使用原始的纬度和经度,而是测量到一个中心点(例如城市中心)的距离,并对这些值进行归一化,使它们更适合建模。
示例: 如果地图的中心是(37.7749, -122.4194),而房源位于(37.8044, -122.2711),计算距离然后进行归一化。
历史搜索查询
特征工程: 文本嵌入
描述: 使用文本嵌入将基于文本的搜索查询转换为数值向量,这些嵌入捕捉了词语之间的语义意义和关系。
示例: 搜索查询“靠近市中心的两居室公寓”可能嵌入为向量[0.25, 0.75, -0.1, …]。
用户相关特征: 年龄,性别
特征工程: 归一化或标准化
描述: 归一化或标准化用户的年龄、性别等人口特征,确保它们与其他特征在一个可比较的尺度上。
示例: 如果年龄范围是0-100,年龄30可能被归一化为0.3。
之前的预订数量
特征工程: 归一化或标准化
描述: 归一化或标准化用户之前的预订数量,确保不同用户之间的一致性。
示例: 如果用户之前有5次预订,且最大预订数量为100,则可能归一化为0.05。
之前的住宿时长
特征工程: 归一化或标准化
描述: 归一化或标准化之前的住宿时长,使其在不同用户之间具有可比性。
示例: 如果之前的住宿时长是7天,且最大住宿时长为100天,则可能标准化为0.07。
时间相关特征
特征工程: 月份,年份中的周数,假期,星期几,小时
描述: 编码预订时间或计划住宿时间的时间信息。这些特征有助于捕捉季节性趋势,工作日与周末模式,以及一天中的时间效应。
示例: 在12月的假期周五下午3点进行的预订,将用这些时间相关特征进行编码。
训练数据
- 来源: 用户搜索历史、查看历史和预订记录。
- 选择: 我们可以从选择一个时间段的数据开始:上个月、过去6个月等,以找到训练时间和模型准确性之间的平衡。
- 实验: 实践中,我们通过运行多个实验来决定训练数据的长度。每个实验将选择某个时间段的训练数据。然后我们比较不同实验中的模型准确性和训练时间。
模型架构
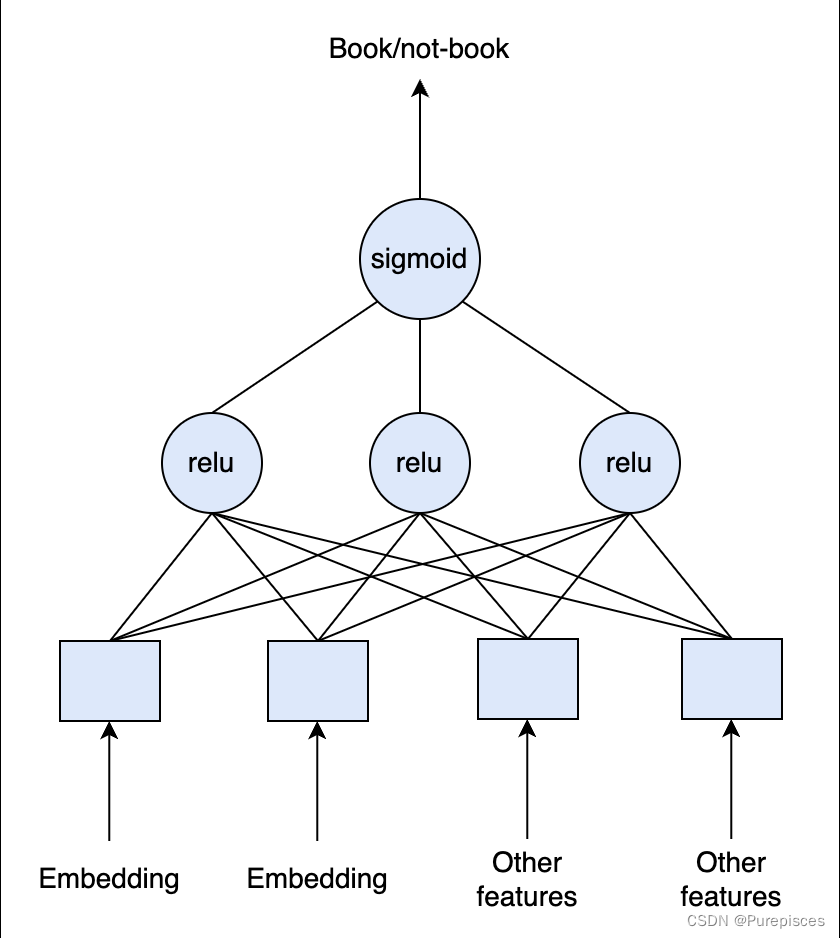
- 输入: 用户数据、搜索查询和房源数据。
- 输出: 这是一个二分类模型,即用户是否预订房源。
- 基线: 我们可以从使用全连接层的深度学习模型作为基线开始。模型输出在[0, 1]之间的一个数字,表示预订的可能性。
- 改进: 为了进一步改进模型,我们还可以使用其他更现代的网络架构,即变分自编码器或去噪自编码器。了解更多关于变分自编码器的信息。
用户数据: 这包括用户特定的特征,如年龄、性别、之前的预订数量、最喜欢的地方和其他相关属性。
搜索查询: 这包括用户的搜索偏好,可以使用文本嵌入进行编码。这些嵌入捕捉了用户搜索词语的语义意义。
房源数据: 这包括房源的属性,如房源ID、卧室数量、设施列表、位置(纬度和经度)以及其他相关特征。
变分自编码器 (VAE): VAE可用于生成与训练数据相似的新数据样本。它们特别有助于捕捉数据的底层分布。这对处理数据有限的新房源非常有用。
去噪自编码器 (DAE): DAE旨在从其损坏的版本中重建原始输入。这有助于模型学习对数据中的噪声不敏感的鲁棒特征。
4. 计算与估算
假设
- 1亿月活跃用户。
- 平均每个用户每年预订5次租赁房源。用户在预订前会从搜索结果中看到大约30个房源。
- 每年有 5 × 30 × 1 0 8 5 \times 30 \times 10^8 5×30×108 或 150亿个观测样本,每月约有12.5亿个样本。
数据大小
- 假设每个样本有数百个特征。为了简化,每行存储需要500字节。
- 总数据大小: 500 × 1.25 × 1 0 9 500 \times 1.25 \times 10^9 500×1.25×109 字节 = 625 GB。为了节省成本,我们可以在数据湖中保留最近6个月或1年的数据,将旧数据存档在冷存储中。
规模
- 支持1.5亿用户。
5. 高级设计

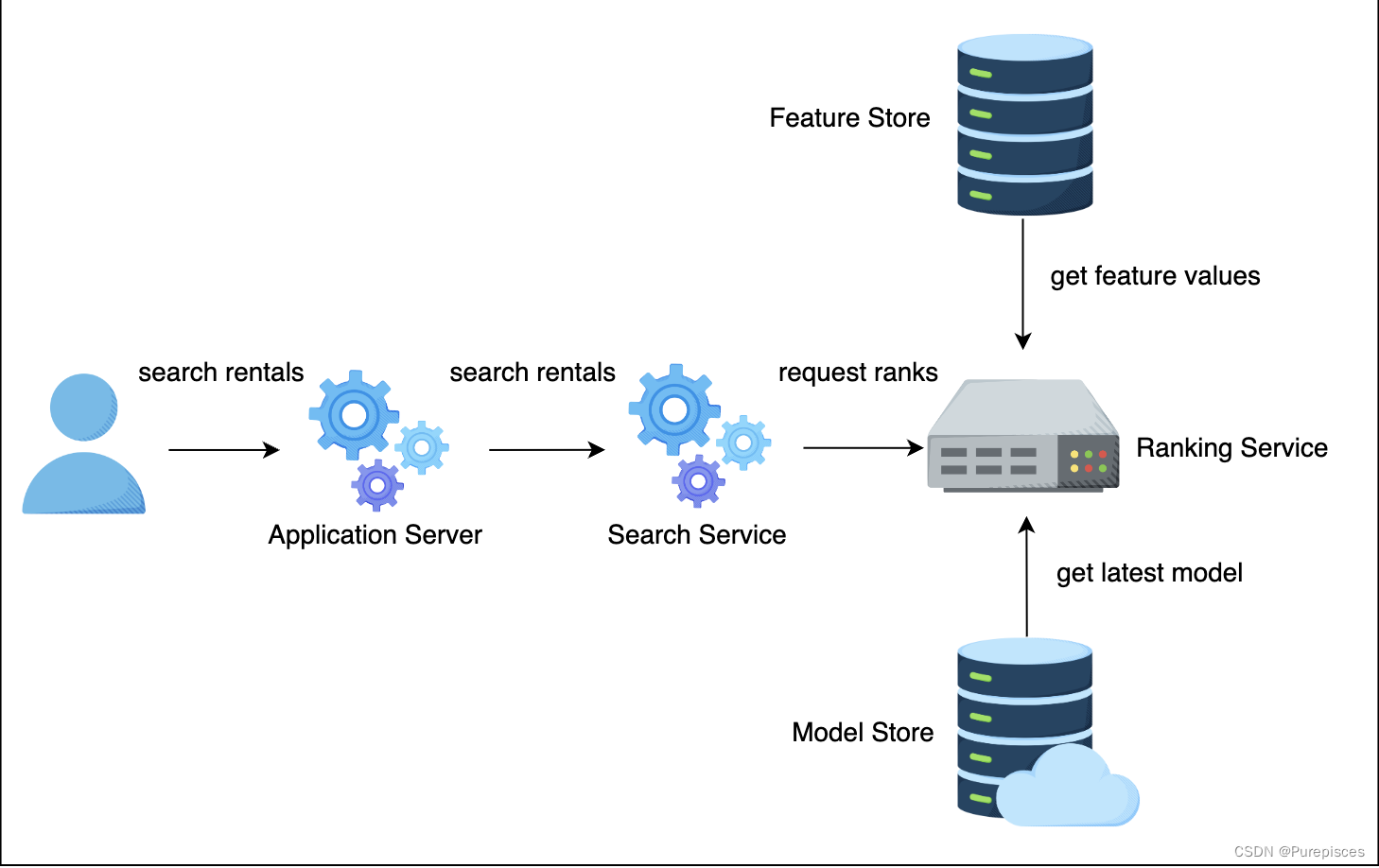
特征管道: 处理在线特征并将特征存储在键值存储中,以实现低延迟的下游处理。
特征存储: 特征值存储。在推理期间,我们需要低于10ms的低延迟来访问特征,以便进行评分。特征存储的例子包括MySQL Cluster、Redis和DynamoDB。
模型存储: 分布式存储,如S3,用于存储模型。
特征存储是一种专门的存储系统,旨在以低延迟存储和提供特征值。这在机器学习模型的推理阶段至关重要,在这一阶段,快速访问预计算特征对于确保实时预测是必要的。
让我们检查系统的流程:
-
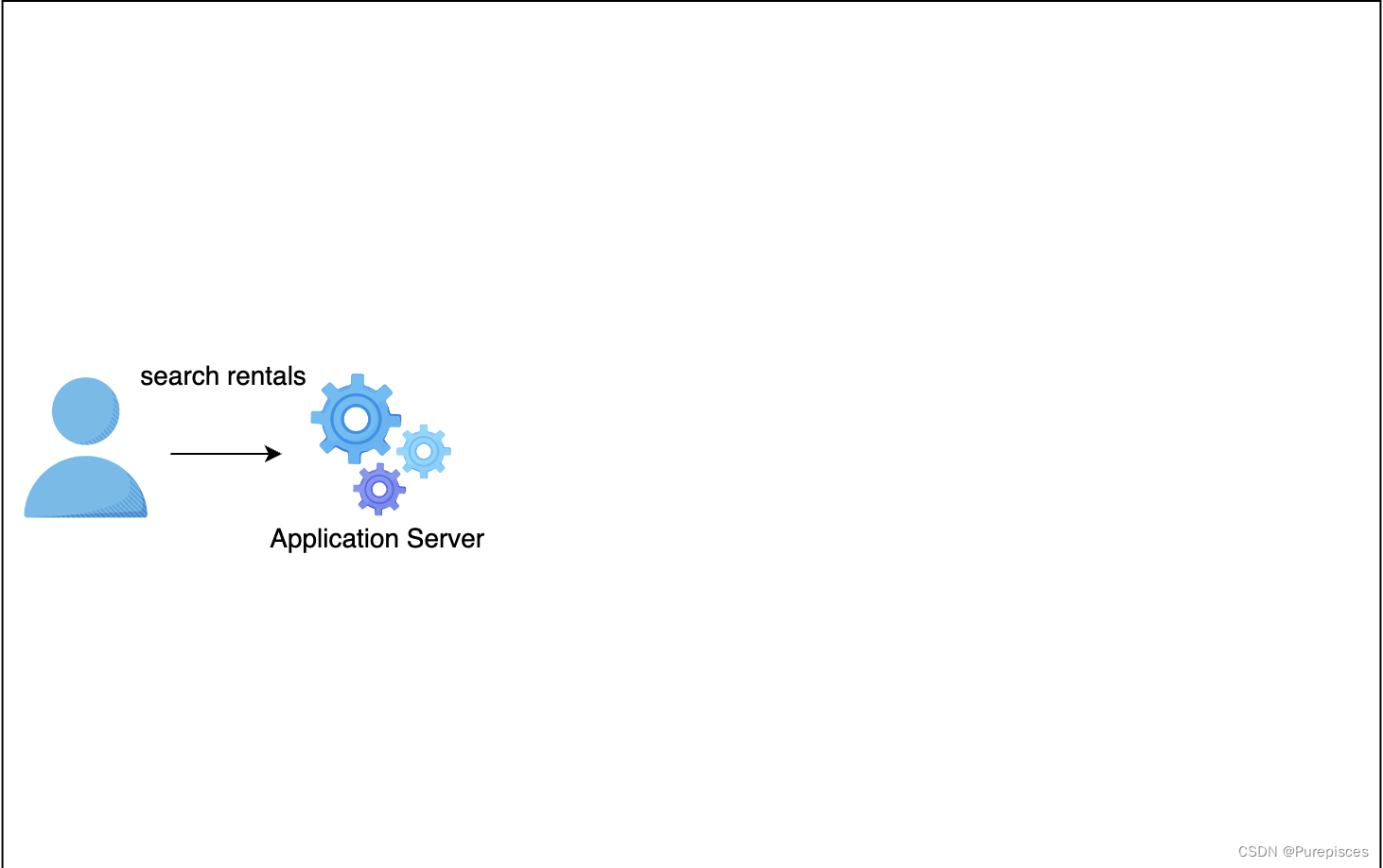
用户搜索房源并向应用服务器请求结果
-
应用服务器向搜索服务发送搜索请求

-
搜索服务从数据库获取房源,并向排名服务发送房源排名请求

-
排名服务对每个房源结果进行评分,并将评分返回给搜索服务
-
搜索服务将房源返回给应用服务器,应用服务器将房源返回给用户
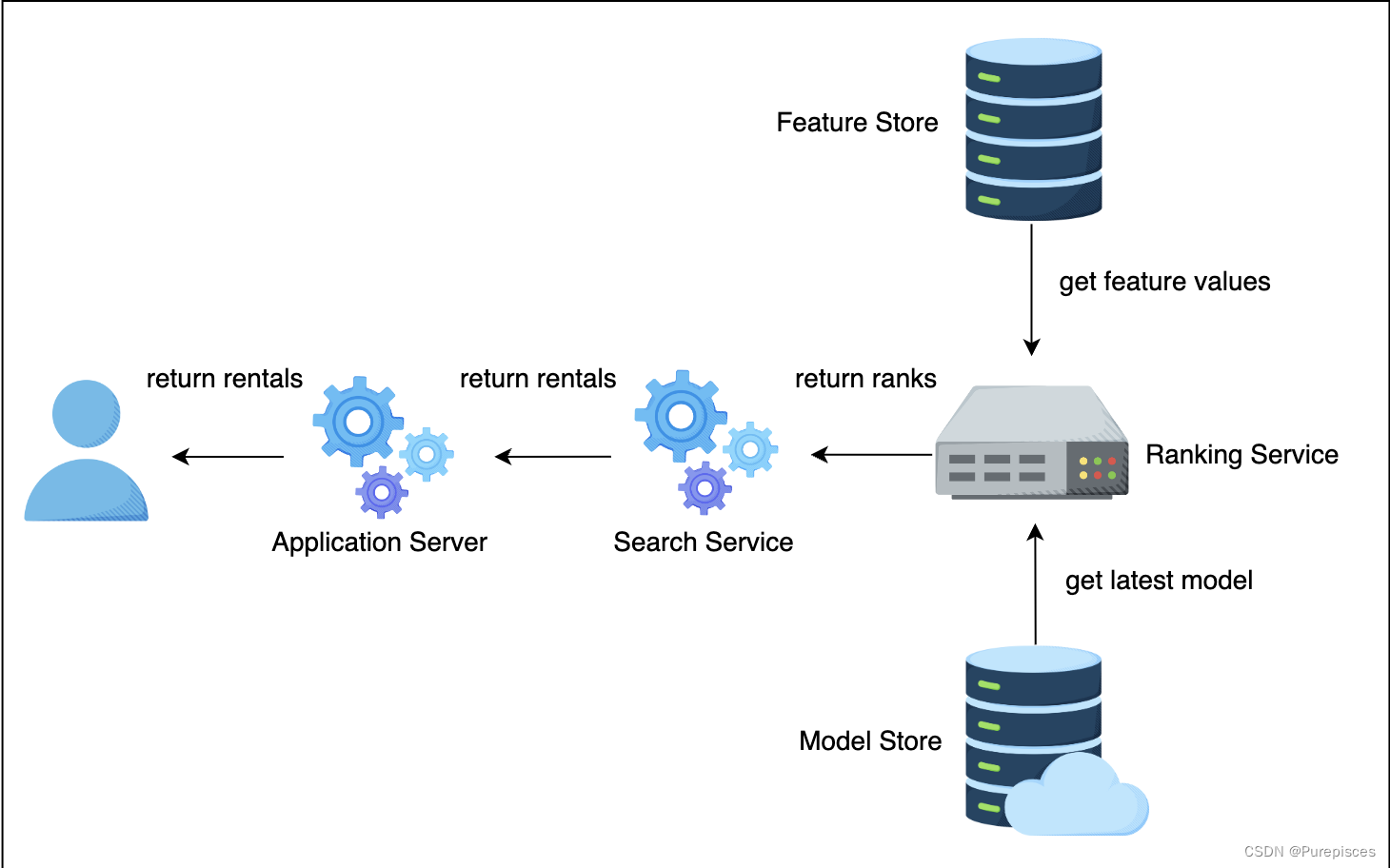
系统流程
- 用户搜索: 用户使用给定的查询(如城市和时间)搜索房源。应用服务器接收查询并向搜索服务发送请求。
- 搜索服务: 在索引数据库中查找并检索房源候选列表。然后将这些候选列表发送给排名服务。
- 排名服务: 使用机器学习模型对每个候选项进行评分。评分表示用户预订特定房源的可能性。排名服务返回带有评分的候选列表。
- 搜索服务: 接收带有预订概率的候选列表,并使用这些概率对候选项进行排序。然后将候选列表返回给应用服务器,应用服务器再返回给用户。
如您所见,我们从一个简单的设计开始,但这种设计无法很好地满足我们的需求,即1.5亿用户和每月12.5亿次搜索。在下一节中,我们将看到如何扩展设计。
索引数据库: 索引是在数据的一个或多个属性上创建的。例如,在租赁房源数据库中,索引可能在城市、价格、卧室数量和可用日期等属性上创建。
6. 设计扩展

为了扩展并处理每秒数百万次请求,我们可以从扩展应用服务器开始,并使用负载均衡器相应地分配负载。
我们还可以扩展搜索服务和排名服务,以处理来自应用服务器的数百万请求。
最后,我们需要记录所有推荐的候选项作为训练数据,因此搜索服务需要将日志发送到云存储或发送消息到Kafka集群。
Apache Kafka 是一个分布式流媒体平台和消息系统,设计用于实时数据摄取、处理和分发。它不是像Amazon S3那样的存储系统,而是用于处理大规模实时数据流的系统。
S3: 一种云存储服务,用于随时存储和检索任意数量的数据。它用于长期存储,可以处理各种类型的数据,包括日志、文件、备份等。
实时数据流 是指从各种来源持续且实时地传输数据到一个处理系统,该系统可以立即或以最小延迟处理、分析和对数据采取行动。此过程对于需要即时见解和响应变化数据的应用程序至关重要。
分布式消息系统 是一种软件基础设施,允许应用程序通过交换消息进行异步通信。这些系统设计用于跨多个服务器或节点工作,提供可扩展性、容错性和可靠性。它们对于构建可扩展和弹性的分布式应用程序至关重要。
消息 是从生产者(发送者)发送到消费者(接收者)的数据单元。消息可以包含各种类型的数据,例如文本、JSON、二进制数据等。
生产者: 创建并发送消息到消息系统的应用程序或服务。
消费者: 从消息系统接收并处理消息的应用程序或服务。
7. 后续问题
| 问题 | 答案 |
|---|---|
| 使用ListingID嵌入作为特征的缺点是什么? | ListingID仅限于几百万个唯一ID,而且每个房源每年的预订次数有限,这可能不足以训练嵌入。 |
| 假设用户在房源页面上的停留时间与预订的可能性有很强的相关性,你会如何重新设计网络架构? | 为两个输出训练多个输出网络:view_time和预订。 |
| 我们需要多长时间重新训练模型一次? | 这取决于需要,我们需要有基础设施来监控在线指标。当在线指标下降时,我们可能需要触发重新训练模型。 |
虽然有数百万个唯一的ListingID,但每个房源每年可能只有少数几次预订。这导致每个ListingID的数据稀疏,使得嵌入难以捕捉到有意义的模式。稀疏的交互意味着模型学习每个ListingID预订行为细微差别的例子有限。
如果我们直接使用查看时间作为输入特征,我们假设已经知道用户将在房源页面上停留的时间,而在实时预测场景中情况并非如此。
通过共享学习理解相关性:当两个任务(查看时间预测和预订可能性预测)共享相同的基础网络时,模型学习输入数据的共享表示。这种共享表示捕捉了与两个任务相关的底层模式和特征。即使最终输出是分开的,共享的基础网络也允许模型理解和利用两个任务之间的关系。
8. 总结
- 我们学习了如何通过使用预订可能性作为目标将搜索排名表述为一个机器学习问题。
- 我们学习了如何使用折扣累积增益作为训练模型的一个指标。
- 我们还学习了如何扩展我们的系统以处理每秒数百万次请求。
附录
示例:离线指标
步骤1:定义相关性分数
假设我们有一个包含以下相关性分数的5个搜索结果列表(分数越高越好):
| 位置 (i) | 房源ID | 相关性分数 (rel_i) |
|---|---|---|
| 1 | A | 3 |
| 2 | B | 2 |
| 3 | C | 3 |
| 4 | D | 0 |
| 5 | E | 1 |
步骤2:计算DCG
使用DCG公式:
D
C
G
p
=
∑
i
=
1
p
r
e
l
i
log
2
(
i
+
1
)
DCG_p = \sum_{i=1}^{p} \frac{rel_i}{\log_2(i + 1)}
DCGp=i=1∑plog2(i+1)reli
对于我们的5个结果:
D
C
G
5
=
3
log
2
(
1
+
1
)
+
2
log
2
(
2
+
1
)
+
3
log
2
(
3
+
1
)
+
0
log
2
(
4
+
1
)
+
1
log
2
(
5
+
1
)
DCG_5 = \frac{3}{\log_2(1 + 1)} + \frac{2}{\log_2(2 + 1)} + \frac{3}{\log_2(3 + 1)} + \frac{0}{\log_2(4 + 1)} + \frac{1}{\log_2(5 + 1)}
DCG5=log2(1+1)3+log2(2+1)2+log2(3+1)3+log2(4+1)0+log2(5+1)1
计算每一项:
3
log
2
(
2
)
=
3
\frac{3}{\log_2(2)} = 3
log2(2)3=3
2
log
2
(
3
)
≈
1.26186
\frac{2}{\log_2(3)} \approx 1.26186
log2(3)2≈1.26186
3
log
2
(
4
)
=
1.5
\frac{3}{\log_2(4)} = 1.5
log2(4)3=1.5
0
log
2
(
5
)
=
0
\frac{0}{\log_2(5)} = 0
log2(5)0=0
1
log
2
(
6
)
≈
0.38685
\frac{1}{\log_2(6)} \approx 0.38685
log2(6)1≈0.38685
将这些值相加:
D
C
G
5
=
3
+
1.26186
+
1.5
+
0
+
0.38685
≈
6.14871
DCG_5 = 3 + 1.26186 + 1.5 + 0 + 0.38685 \approx 6.14871
DCG5=3+1.26186+1.5+0+0.38685≈6.14871
步骤3:计算IDCG
使用IDCG公式:
I
D
C
G
p
=
∑
i
=
1
p
2
r
e
l
i
−
1
log
2
(
i
+
1
)
IDCG_p = \sum_{i=1}^{p} \frac{2^{rel_i} - 1}{\log_2(i + 1)}
IDCGp=i=1∑plog2(i+1)2reli−1
首先,将相关性分数按降序排序:[3, 3, 2, 1, 0]
使用排序后的相关性分数,计算IDCG:
I
D
C
G
5
=
2
3
−
1
log
2
(
1
+
1
)
+
2
3
−
1
log
2
(
2
+
1
)
+
2
2
−
1
log
2
(
3
+
1
)
+
2
1
−
1
log
2
(
4
+
1
)
+
2
0
−
1
log
2
(
5
+
1
)
IDCG_5 = \frac{2^3 - 1}{\log_2(1 + 1)} + \frac{2^3 - 1}{\log_2(2 + 1)} + \frac{2^2 - 1}{\log_2(3 + 1)} + \frac{2^1 - 1}{\log_2(4 + 1)} + \frac{2^0 - 1}{\log_2(5 + 1)}
IDCG5=log2(1+1)23−1+log2(2+1)23−1+log2(3+1)22−1+log2(4+1)21−1+log2(5+1)20−1
计算每一项:
2
3
−
1
log
2
(
2
)
=
7
1
=
7
\frac{2^3 - 1}{\log_2(2)} = \frac{7}{1} = 7
log2(2)23−1=17=7
2
3
−
1
log
2
(
3
)
≈
7
1.58496
≈
4.41651
\frac{2^3 - 1}{\log_2(3)} \approx \frac{7}{1.58496} \approx 4.41651
log2(3)23−1≈1.584967≈4.41651
2
2
−
1
log
2
(
4
)
=
3
2
=
1.5
\frac{2^2 - 1}{\log_2(4)} = \frac{3}{2} = 1.5
log2(4)22−1=23=1.5
2
1
−
1
log
2
(
5
)
≈
1
2.32193
≈
0.43068
\frac{2^1 - 1}{\log_2(5)} \approx \frac{1}{2.32193} \approx 0.43068
log2(5)21−1≈2.321931≈0.43068
2
0
−
1
log
2
(
6
)
=
0
2.58496
=
0
\frac{2^0 - 1}{\log_2(6)} = \frac{0}{2.58496} = 0
log2(6)20−1=2.584960=0
将这些值相加:
I
D
C
G
5
=
7
+
4.41651
+
1.5
+
0.43068
+
0
≈
13.34719
IDCG_5 = 7 + 4.41651 + 1.5 + 0.43068 + 0 \approx 13.34719
IDCG5=7+4.41651+1.5+0.43068+0≈13.34719
步骤4:计算nDCG
最后,nDCG是DCG与IDCG的比率:
n
D
C
G
p
=
D
C
G
p
I
D
C
G
p
nDCG_p = \frac{DCG_p}{IDCG_p}
nDCGp=IDCGpDCGp
对于我们的示例:
n
D
C
G
5
=
6.14871
13.34719
≈
0.4605
nDCG_5 = \frac{6.14871}{13.34719} \approx 0.4605
nDCG5=13.347196.14871≈0.4605
总结
- DCG: 6.14871
- IDCG: 13.34719
- nDCG: 0.4605
示例:使用在线指标:转化率和收入提升
让我们以一个实际示例来实施新的搜索排名算法,并使用转化率和收入提升来衡量其影响。
变更前后的数据收集
| 指标 | 变更前 | 变更后 |
|---|---|---|
| 搜索结果数量 | 10,000 | 10,000 |
| 预订数量 | 1,000 | 1,200 |
| 每次预订的平均收入 | $200 | $220 |
转化率计算
变更前:
conversion rate before = 1 , 000 10 , 000 = 10 % \text{conversion rate}_{\text{before}} = \frac{1,000}{10,000} = 10\% conversion ratebefore=10,0001,000=10%
变更后:
conversion rate after = 1 , 200 10 , 000 = 12 % \text{conversion rate}_{\text{after}} = \frac{1,200}{10,000} = 12\% conversion rateafter=10,0001,200=12%
收入提升计算
变更前的总收入:
total revenue before = 1 , 000 × $ 200 = $ 200 , 000 \text{total revenue}_{\text{before}} = 1,000 \times \$200 = \$200,000 total revenuebefore=1,000×$200=$200,000
变更后的总收入:
total revenue after = 1 , 200 × $ 220 = $ 264 , 000 \text{total revenue}_{\text{after}} = 1,200 \times \$220 = \$264,000 total revenueafter=1,200×$220=$264,000
收入提升:
revenue lift = $ 264 , 000 − $ 200 , 000 $ 200 , 000 × 100 % = 32 % \text{revenue lift} = \frac{\$264,000 - \$200,000}{\$200,000} \times 100\% = 32\% revenue lift=$200,000$264,000−$200,000×100%=32%
总结
- 转化率 从10%增加到12%,表明更多的用户在预订房源。
- 收入提升 增加了32%,表明新算法不仅带来了更多的预订,还显著增加了总收入。
参考资料:
- 来自educative的机器学习系统设计