在 4.1.2 节中,我们介绍了 Spring Boot 的四大核心组成部分,第 4 章主要介绍了其中的起步依赖与自动配置,本章将重点介绍 Spring Boot Actuator,包括如何通过 Actuator 提供的各种端点(endpoint)了解系统的运行情况,使用 Micrometer 为各种监控系统提供度量指标数据,最后还要了解如何打包部署 Spring Boot 应用程序。
5.1 Spring Boot Actuator 概述
Spring Boot Actuator 是 Spring Boot 的重要功能模块,能为系统提供一系列在生产环境中运行所必需的功能,比如监控、度量、配置管理等。只需引入 org.springframework.boot:spring-boot-starter-actuator 起步依赖后,我们就可以通过 HTTP 来访问这些功能(也可以使用 JMX 来访问)。Spring Boot 还为我们预留了很多配置,可以根据自己的需求对 Spring Boot Actuator 的功能进行定制。
5.1.1 端点概览
不知道大家有没有尝试解决过类似下面的问题:
- Spring 上下文中到底存在哪些 Bean
- Spring Boot 中的哪些自动配置最终生效了
- 应用究竟获取到了哪些配置项
- 系统中存在哪些 URL,它们又映射到了哪里
在没有 Spring Boot Actuator 的时候,获取这些信息还是需要费一番功夫的;但现在就不一样了,Spring Boot Actuator 内置了大量的端点,这些端点可以帮助大家了解系统内部的运行情况,并针对一些功能做出调整。
根据功能的不同,我们可以将这些端点划分成四类:信息类端点、监控类端点、操作类端点、集成类端点,其中部分端点需要引入特定的依赖,或者配置特定的 Bean。接下来我们会依次介绍这四类端点,首先是用于获取系统运行信息的端点,如表 5-1 所示。
表 5-1 Spring Boot Actuator 中的信息类端点列表
| 端点 ID | 默认开启 HTTP | 默认开启 JMX | 端点说明 |
|---|---|---|---|
auditevents | 否 | 是 | 提供系统的审计信息 |
beans | 否 | 是 | 提供系统中的 Bean 列表 |
caches | 否 | 是 | 提供系统中的缓存信息 |
conditions | 否 | 是 | 提供配置类的匹配情况及条件运算结果 |
configprops | 否 | 是 | 提供 @ConfigurationProperties 的列表 |
env | 否 | 是 | 提供 ConfigurableEnvironment 中的属性信息 |
flyway | 否 | 是 | 提供已执行的 Flyway 数据库迁移信息 |
httptrace | 否 | 是 | 提供 HTTP 跟踪信息,默认最近 100 条 |
info | 是 | 是 | 显示事先设置好的系统信息 |
integrationgraph | 否 | 是 | 提供 Spring Integration 图信息 |
liquibase | 否 | 是 | 提供已执行的 Liquibase 数据库迁移信息 |
logfile | 否 | 无此功能 | 如果设置了 logging.file.name 或 logging.file.path 属性,则显示日志文件内容 |
mappings | 否 | 是 | 提供 @RequestMapping 的映射列表 |
scheduledtasks | 否 | 是 | 提供系统中的调度任务列表 |
第二类端点是监控与度量相关的端点,具体如表 5-2 所示。
表 5-2 Spring Boot Actuator 中的监控类端点列表
| 端点 ID | 默认开启 HTTP | 默认开启 JMX | 端点说明 |
|---|---|---|---|
health | 是 | 是 | 提供系统运行的健康状态 |
metrics | 否 | 是 | 提供系统的度量信息 |
prometheus | 否 | 无此功能 | 提供 Prometheus 系统可解析的度量信息 |
我们对第 1 章的 helloworld 示例稍作调整,在其 pom.xml 的 <dependencies/> 中增加如下内容即可引入 Spring Boot Actuator 的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
从上述两张表中我们可以发现,默认只有 info 和 health 两个端点是开启了 HTTP 访问的,因此在运行程序后,通过浏览器或者其他方式访问 http://localhost:8080/actuator/health 就能访问到 health 端点的信息。如果在 macOS 或 Linux 上,我们可以使用 curl 命令,具体运行结果如下:
▸ curl -v http://localhost:8080/actuator/health
* Trying ::1...
* TCP_NODELAY set
* Connected to localhost (::1) port 8080 (#0)
> GET /actuator/health HTTP/1.1
> Host: localhost:8080
> User-Agent: curl/7.64.1
> Accept: */*
>
< HTTP/1.1 200
< Content-Type: application/vnd.spring-boot.actuator.v3+json
< Transfer-Encoding: chunked
< Date: Fri, 10 Jul 2020 15:38:54 GMT
<
* Connection #0 to host localhost left intact
{"status":"UP"}* Closing connection 0
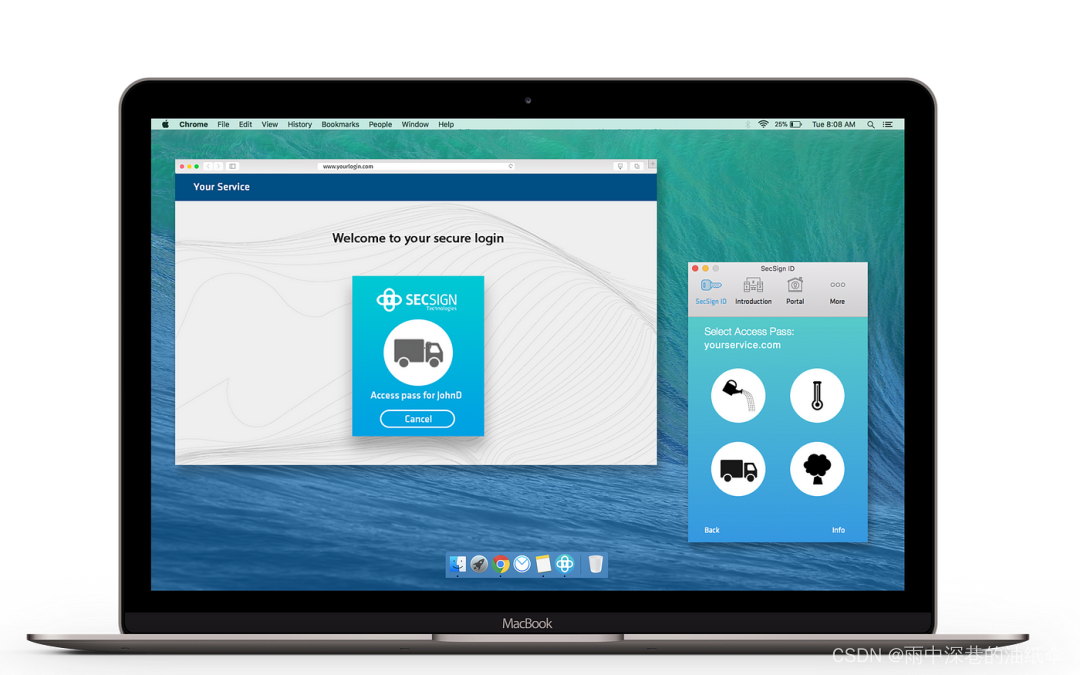
如果使用浏览器,访问的效果如图 5-1 所示。

图 5-1 通过 Chrome 浏览器查看 health 端点
第三类端点可以执行一些实际的操作,例如调整日志级别,具体如表 5-3 所示。
表 5-3 Spring Boot Actuator 中的操作类端点列表
| 端点 ID | 默认开启 HTTP | 默认开启 JMX | 端点说明 |
|---|---|---|---|
heapdump | 否 | 无此功能 | 执行 Heap Dump 操作 |
loggers | 否 | 是 | 查看并修改日志信息 |
sessions | 否 | 是 | 针对使用了 Spring Session 的系统,可获取或删除用户的 Session |
shutdown | 否 | 否 | 优雅地关闭系统 |
threaddump | 否 | 是 | 执行 Thread Dump 操作 |
最后一类端点比较特殊,它的功能与集成有关,就只有一个 jolokia,见表 5-4。
表 5-4 Spring Boot Actuator 中的集成类端点列表
| 端点 ID | 默认开启 HTTP | 默认开启 JMX | 端点说明 |
|---|---|---|---|
jolokia | 否 | 无此功能 | 通过 HTTP 来发布 JMX Bean |
5.1.2 端点配置
在了解了 Spring Boot 提供的端点后,我们就要将它们投入具体的生产使用当中了。Spring Boot Actuator 非常灵活,它提供了大量的开关配置,还有两种不同的访问方式可供我们选择。接下来大家就来一起了解一下这些配置。
-
开启或禁用端点
默认情况下,除了
shutdown以外,所有的端点都是处于开启状态的,只是访问方式不同,或者保护状态不同。如果要开启或者禁用某个端点,可以调整management.endpoint.<id>.enabled属性。例如,想要开启shutdown端点,就可以这样配置:management.endpoint.shutdown.enabled=true也可以调整默认值,禁用所有端点,随后开启指定端点。例如,只开启
health端点:management.endpoints.enabled-by-default=false management.endpoint.health.enabled=true -
通过 HTTP 访问端点
默认仅有
health和info端点是可以通过 HTTP 方式来访问的,在 5.1.1 节中,我们已经看到了如何通过curl命令和浏览器来访问health端口。那如何才能开启其他端点的 HTTP 访问功能呢?可以使用management.endpoints.web.exposure.include和management.endpoints.web.exposure.exclude这两个属性来控制哪些端点可以通过 HTTP 方式发布,哪些端点不行。前者的默认值为health,info,后者的默认值为空。例如,我们希望在原有基础上再增加
beans和env端点,就可以这样来设置:management.endpoints.web.exposure.include=beans,env,health,info如果希望放开所有的端点,让它们都能通过 HTTP 方式来访问,我们就可以将上述属性设置为
*:management.endpoints.web.exposure.include=*要是一个端点同时出现在
management.endpoints.web.exposure.include和management.endpoints.web.exposure.exclude这两个属性里,那么后者的优先级会高于前者,也就是说该端点会被排除。如果我们希望了解 HTTP 方式可以访问哪些端点,可以直接访问
/actuator地址,会得到类似下面的 JSON 信息:{ "_links": { "health": { "href": "http://localhost:8080/actuator/health", "templated": false }, "health-path": { "href": "http://localhost:8080/actuator/health/{*path}", "templated": true }, "info": { "href": "http://localhost:8080/actuator/info", "templated": false }, "self": { "href": "http://localhost:8080/actuator", "templated": false } } }其中
templated为true的 URL 可以用具体的值去代替{}里的内容,比如,http://localhost:8080/actuator/metrics/的 `` 就可以用http://localhost:8080/actuator/metrics里所罗列的名称代替。需要特别说明一点,要发布 HTTP 端点,必须要有 Web 支持,因此项目需要引入
spring-boot-starter-web起步依赖。 -
通过 JMX 访问端点
与 HTTP 方式类似,JMX 也有两个属性,即
management.endpoints.jmx.exposure.include和management.endpoints.jmx.exposure.exclude。前者的默认值为*,后者的默认值为空。有不少工具可以用来访问 JMX 端点,比如 JVisualVM 和 JConsole,它们都是 JDK 自带的工具。以 JConsole 为例,启动 JConsole 后会弹出新建连接界面,从中可以选择想要连接的本地 Java 进程,也可以通过指定信息连接远程的进程,具体如图 5-2 所示。
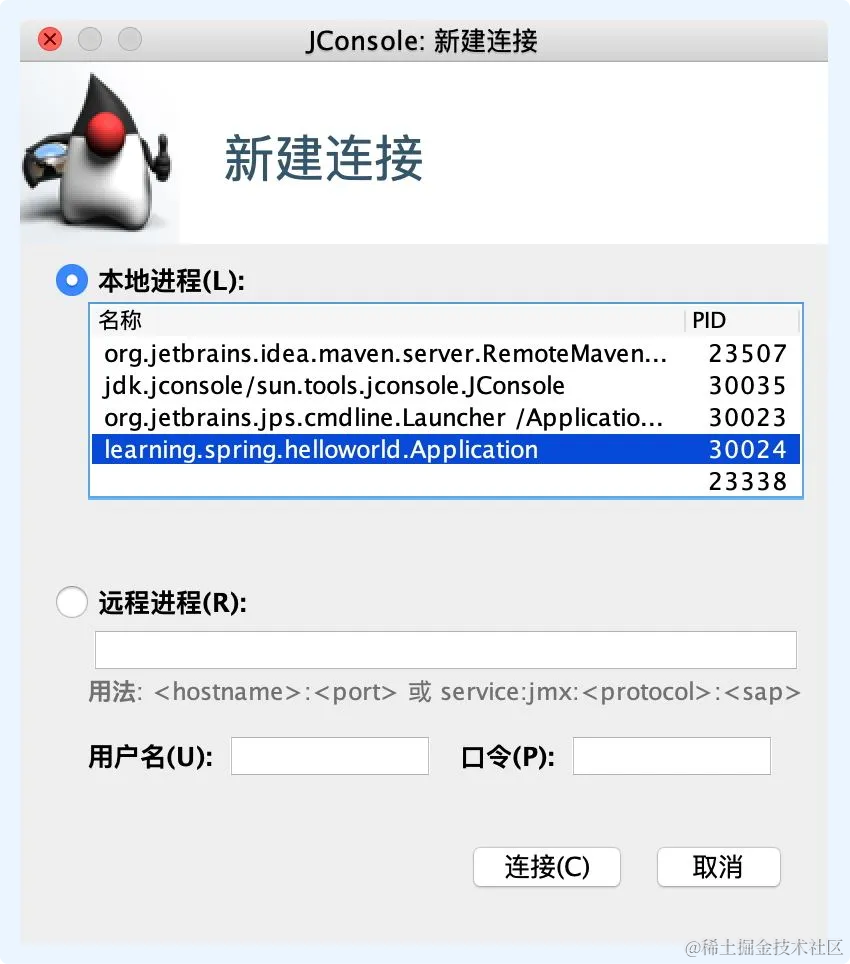
图 5-2 JConsole 的新建连接界面选中目标进程后,点击连接按钮,稍过一段时间后,就能连上目标进程了。随后选中 MBean 标签页,在
org.springframework.boot目录下找到Endpoint,其中列出的就是可以访问的 JMX 端点。图 5-3 就是选择了Health后界面的样子,点击health按钮即可获得健康检查的 JSON 结果。
图 5-3 通过 JMX 方式访问
health端点 -
保护端点
如果在工程中引入了 Spring Security,那么 Spring Boot Actuator 会自动对各种端点进行保护,例如,默认通过浏览器访问时,浏览器会显示一个页面,要求输入用户名和密码。如果我们没有配置过相关信息,那么在系统启动时,可以在日志中查找类似下面的日志:
Using generated security password: 4fbc8059-fdb8-46f9-a54e-21d5cb2e9eb2默认的用户名是
user,密码就是上面这段随机生成的内容。关于 Spring Security 的更多细节,我们会在第 10 章中详细展开。此处,给出两个示例,它们都需要在 pom.xml 中增加spring-boot-starter-actuator和spring-boot-starter-security起步依赖。这里先来演示如何不用登录页,而是使用 HTTP Basic 的方式进行验证(但health端点除外),具体的配置如代码示例 5-1 所示,注意其中的EndpointRequest用的是org.springframework.boot.actuate.autoconfigure.security.servlet.EndpointRequest。代码示例 5-1 需要认证才可访问端点的配置代码片段
@Configuration public class ActuatorSecurityConfigurer extends WebSecurityConfigurerAdapter { @Override protected void configure(HttpSecurity http) throws Exception { http.requestMatcher(EndpointRequest.toAnyEndpoint().excluding("health")). authorizeRequests((requests) -> requests.anyRequest().authenticated()); http.httpBasic(); } }第二个演示针对所有端点,可以提供匿名访问,具体如代码示例 5-2 所示。
代码示例 5-2 可匿名访问端点的配置代码片段
@Configuration public class ActuatorSecurityConfigurer extends WebSecurityConfigurerAdapter { @Override protected void configure(HttpSecurity http) throws Exception { http.requestMatcher(EndpointRequest.toAnyEndpoint()).authorizeRequests((requests) -> requests. anyRequest().anonymous()); http.httpBasic(); } }茶歇时间:针对 Web 和 Actuator 使用不同端口的好处
试想一下,我们的系统在对外提供 HTTP 服务,一般会在集群前增加一个负载均衡设备(比如 Nginx),将外部对
80端口的请求转发至系统的8080端口。如果 Spring Boot Actuator 的端口也在8080,而我们又没对端点做足够的保护,黑客很轻松地就能获取系统的信息。就算做了保护,黑客也能通过端点信息推断出这个系统是通过 Spring Boot 实现的、可能存在哪些漏洞。一般我们都会在系统启动后,通过
health端点来判断系统的健康情况,如果对这个端点做了过多保护,反而不便于获取健康检查结果。一种做法是在防火墙或者负载均衡层面,禁止外部访问 Spring Boot Actuator 的 URL,例如,直接禁止访问
/actuator及其子路径。另一种做法,就是索性让 Actuator 的端点暴露在与业务代码不同的 HTTP 端口上,比如,不再共用8080端口,而是单独提供一个8081端口,而防火墙和负载均衡设备只知道8080端口的存在,也只会转发请求到8080端口,就不用担心外部能访问到8081端口的问题了。通过
management.server.port=8081能实现设置 Actuator 专属端口的功能。更进一步,我们还可以使用management.server.base-path属性(以前是management.server.servlet.context-path)为 Spring Boot Actuator 设置 Servlet 上下文,默认为空;使用management.endpoints.web.base-path属性来调整/actuator这个默认的基础路径。如果像下面这样来做设置,就能将health端点访问的 URL 调整为http://localhost:8081/management/my-actuator/health了:management.server.port=8081 management.server.base-path=/management management.endpoints.web.base-path=/my-actuator
5.1.3 定制端点信息
Spring Boot Actuator 中的每个端点或多或少会有一些属于自己的配置属性,大家可以在 org.springframework.boot:spring-boot-actuator-autoconfigure 包中查看各种以 Properties 结尾的属性类,也可以直接通过 configprops 端点来查看属性类。
例如, EnvironmentEndpointProperties 就对应了 management.endpoint.env 中的属性,其中的 keysToSanitize 就是环境中要过滤的自定义敏感信息键名清单,根据代码注释,其中可以设置匹配的结尾字符串,也可以使用正则表达式。在设置了 management.endpoint.env.keys-to-sanitize=java.*,sun.* 后, env 端点返回的属性中,所有 java 和 sun 打头的属性值都会以 * 显示。
Spring Boot Actuator 默认为 info 和 health 端点开启了 HTTP 访问支持,那么就让我们来详细了解一下这两个端点有哪些可以定制的地方吧。
-
定制 info 端点信息
根据
InfoEndpointAutoConfiguration可以得知,InfoEndpoint中会注入 Spring 上下文中的所有InfoContributorBean 实例。InfoContributorAutoConfiguration自动注册了env、git和build这三个InfoContributor,Spring Boot Actuator 提供的InfoContributor列表如表 5-5 所示。表 5-5 内置
InfoContributor列表
| 类名 | 默认开启 | 说明 |
|---|---|---|
BuildInfoContributor | 是 | 提供 BuildProperties 的信息,通过 spring.info.build 来设置,默认读取 META-INF/build-info.properties |
EnvironmentInfoContributor | 是 | 将配置中以 info 打头的属性通过端点暴露 |
GitInfoContributor | 是 | 提供 GitProperties 的信息,通过 spring.info.git 来设置,默认读取git.properties |
InfoPropertiesInfoContributor | 否 | 抽象类,一般作为其他 InfoContributor 的父类 |
MapInfoContributor | 否 | 将内置 Map 作为信息输出SimpleInfoContributor否仅包含一对键值对的信息 |
假设在配置文件中设置了如下内容:
info.app=HelloWorld
info.welcome=Welcome to the world of Spring.
再提供如下的 Bean:
@Bean
public SimpleInfoContributor simpleInfoContributor() {
return new SimpleInfoContributor("simple", "HelloWorld!");
}
那 info 端点输出的内容大致如下所示:
{
"app": "HelloWorld",
"simple": "HelloWorld!",
"welcome": "Welcome to the world of Spring."
}
-
定制 health 端点信息
健康检查是一个很常用的功能,可以帮助我们了解系统的健康状况,例如,系统在启动后是否准备好对外提供服务了,所依赖的组件是否已就绪等。
健康检查主要是依赖
HealthIndicator的各种实现来完成的。Spring Boot Actuator 内置了近 20 种不同的实现,表 5-6 列举了一些常用的HealthIndicator实现,基本可以满足日常使用的需求。表 5-6 常用的
HealthIndicator实现
| 实现类 | 作用 |
|---|---|
DataSourceHealthIndicator | 检查 Spring 上下文中能取到的所有 DataSource 是否健康 |
DiskSpaceHealthIndicator | 检查磁盘空间 |
LivenessStateHealthIndicator | 检查系统的存活(Liveness)情况,一般用于 Kubernetes 中 |
ReadinessStateHealthIndicator | 检查系统是否处于就绪(Readiness)状态,一般用于 Kubernetes 中 |
RedisHealthIndicator | 检查所依赖的 Redis 健康情况 |
每个 HealthIndicator 检查后都会有自己的状态信息,Spring Boot Actuator 最后会根据所有结果的状态信息综合得出系统的最终状态。 org.springframework.boot.actuate.health.Status 定义了几种默认状态,按照优先级降序排列分别为 DOWN、 OUT_OF_SERVICE、 UP 和 UNKNOWN,所有结果状态中优先级最高的状态会成为 health 端点的最终状态。如果有需要,我们也可以通过 management.endpoint.health.status.order 来更改状态的优先级。
Spring Boot Actuator 默认开启了所有的 HealthIndicator,它们会根据情况自行判断是否生效,也可以通过 management.health.defaults.enabled=false 开关(默认关闭),随后使用 management.health.<name>.enabled 选择性地开启 HealthIndicator。例如, DataSourceHealthContributorAutoConfiguration 是这样定义的:
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ JdbcTemplate.class, AbstractRoutingDataSource.class })
@ConditionalOnBean(DataSource.class)
@ConditionalOnEnabledHealthIndicator("db")
@AutoConfigureAfter(DataSourceAutoConfiguration.class)
public class DataSourceHealthContributorAutoConfiguration extends
CompositeHealthContributorConfiguration
<AbstractHealthIndicator, DataSource>
implements InitializingBean {}
那么它的生效条件是这样的:
- CLASSPATH 中存在
JdbcTemplate和AbstractRoutingDataSource类; - Spring 上下文中存在
DataSource类型的 Bean; - 默认开关打开,或者
management.health.db.enabled=true,此处@ConditionalOnEnabledHealthIndicator中的db就是name。
知道了 health 中的各个 HealthIndicator 后,怎么才能看到结果呢?我们可以通过配置 management.endpoint.health.show-details 和 management.endpoint.health.show-components 的属性值来查看结果,默认是 never,将其调整为 always 后就会始终显示具体内容了。如果依赖中存在 Spring Security,也可以仅对授权后的用户开放,将属性值配置为 when-authorized,这时我们可以通过 management.endpoint.health.roles 来设置可以访问的用户的角色。一般情况下,可以考虑将其调整为 always。
如今越来越多的系统运行在 Kubernetes 环境中,而 Kubernetes 需要检查系统是否存活,是否就绪,对此, health 端点也提供了对应的 LivenessStateHealthIndicator 和 ReadinessStateHealthIndicator,默认 URL 分别为 /actuator/health/liveness 和 /actuator/health/readiness。
5.1.4 开发自己的组件与端点
在上一节中,我们看到的基本都是对现有端点与组件的配置,Spring Boot Actuator 提供了让我们自己扩展端点或者实现新端点的功能。例如,在进行健康检查时,我们可以加入自己的检查逻辑,只需实现 HealthIndicator 即可。
-
开发自己的 HealthIndicator
为了增加自己的健康检查逻辑,我们可以定制一个 HealthIndicator 实现,通常会选择扩展
AbstractHealthIndicator类,实现其中的doHealthCheck()方法。根据
HealthEndpointConfiguration类的代码,我们可以知道healthContributorRegistry会从 Spring 上下文获取所有HealthContributor类型(HealthIndicator继承了这个接口)的 Bean,并进行注册,所以我们也只需要把写好的HealthIndicator配置为 Bean 即可。@Configuration(proxyBeanMethods = false) class HealthEndpointConfiguration { @Bean @ConditionalOnMissingBean HealthContributorRegistry healthContributorRegistry(ApplicationContext applicationContext, HealthEndpointGroups groups) { Map<String, HealthContributor> healthContributors = new LinkedHashMap<>(applicationContext .getBeansOfType(HealthContributor.class)); if (ClassUtils.isPresent("reactor.core.publisher.Flux", applicationContext.getClassLoader())) { healthContributors.putAll(new AdaptedReactiveHealthContributors(applicationContext).get()); } return new AutoConfiguredHealthContributorRegistry(healthContributors, groups.getNames()); } // 省略其他代码 }
接下来,我们以第 4 章的 BinaryTea 项目作为基础,在其中添加自己的 HealthIndicator。在 ShopReadyHealthIndicator 上添加 @Component 注解,以便在扫描到它后就能将其注册为 Bean。通过构造方法注入 BinaryTeaProperties,检查时如果没有 binaryTeaProperties 或者属性中的 ready 为 false,检查即为失败,除此之外都算成功。具体如代码示例 5-3 所示。
代码示例 5-3 ShopReadyHealthIndicator 健康检查器
@Component
public class ShopReadyHealthIndicator extends AbstractHealthIndicator{
private BinaryTeaProperties binaryTeaProperties;
public ShopReadyHealthIndicator(ObjectProvider<BinaryTeaProperties> binaryTeaProperties) {
this.binaryTeaProperties = binaryTeaProperties.getIfAvailable();
}
@Override
protected void doHealthCheck(Health.Builder builder) throws Exception {
if (binaryTeaProperties == null || !binaryTeaProperties.isReady()) {
builder.down();
} else {
builder.up();
}
}
}
运行代码前还需要在 pom.xml 中加入 Spring Web 和 Spring Boot Actuator 的依赖,具体如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
同时在 application.properties 中增加 management.endpoint.health.show-details=always,以便可以看到 ShopReadyHealthIndicator 的效果。运行 BinaryTeaApplication 后,在浏览器中访问 http://localhost:8080/actuator/health,就能看到类似下面的 JSON 输出:
{
"components": {
// 省略部分内容
"ping": {
"status": "UP"
},
"shopReady": {
"status": "UP"
}
},
"status": "UP"
}
为了能够进行自动测试,我们还可以在 ShopConfigurationEnableTest 和 ShopConfigurationDisableTest 中分别加入对应的测试用例,再写个测试检查是否注册了对应的信息,如代码示例 5-4 所示。
代码示例 5-4 针对 ShopReadyHealthIndicator 的各种单元测试用例
// ShopConfigurationEnableTest中的测试用例
@Test
void testIndicatorUp() {
ShopReadyHealthIndicator indicator = applicationContext.getBean(ShopReadyHealthIndicator.class);
assertEquals(Status.UP, indicator.getHealth(false).getStatus());
}
// ShopConfigurationDisableTest中的测试用例
@Test
void testIndicatorDown() {
ShopReadyHealthIndicator indicator = applicationContext.getBean(ShopReadyHealthIndicator.class);
assertEquals(Status.DOWN, indicator.getHealth(false).getStatus());
}
// 独立的ShopReadyHealthIndicatorTest,测试是否注册了shopReady
@SpringBootTest
public class ShopReadyHealthIndicatorTest {
@Autowired
private HealthContributorRegistry registry;
@Test
void testRegistryContainsShopReady() {
assertNotNull(registry.getContributor("shopReady"));
}
}
如果一切顺利,执行 mvn test 后我们应该就能看到测试通过的信息了:
[INFO] Results:
[INFO]
[INFO] Tests run: 7, Failures: 0, Errors: 0, Skipped: 0
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
茶歇时间:为什么要优先通过
ObjectProvider获取 Bean当我们需要从 Spring 上下文中获取其他 Bean 时,最直接的方法是使用
@Autowired注解,但系统运行时的不确定性太多了,比如不确定是否存在需要的依赖,这时就需要加上required=false;也有可能目标类型的 Bean 不止一个,而我们只需要一个;构造方法有多个参数……这时就该
ObjectProvider<T>上场了,它大多用于构造方法注入的场景,让我们有能力处理那些尴尬的场面,其中的getIfAvailable()方法在存在对应 Bean 时返回对象,不存在时则返回null;getIfUnique()方法在有且仅有一个对应 Bean 时返回对象,Bean 不存在或不唯一,且不唯一时没有标注Primary的情况下返回null。再加上一些检查和遍历的方法,通过明确的编码,我们就可以确保自己的代码获取到必要的依赖,或判断出缺少的东西,并加以处理。
-
开发自己的端点
如果内置的端点无法满足我们的需求,那最后一招就是写一个自己的端点。好在 Spring Boot Actuator 支持到位,只需简单几步就能帮助我们实现一个端点。
首先,在 Bean 上添加
@Endpoint注解,其中带有@ReadOperation、@WriteOperation和@DeleteOperation的方法能被发布出来,而且能通过 JMX 或者 HTTP 的方式访问到这些方法接下来,如果我们希望限制只用其中的一种方式来发布,则可以将
@Endpoint替换为@JmxEndpoint或@WebEndpoint。如果是通过 HTTP 方式访问的,默认的 URL 是
/actuator/<id>,其中的id就是@Endpoint注解中指定的id,而@ReadOperation、@WriteOperation和@DeleteOperation的方法分别对应了 HTTP 的GET、POST和DELETE方法。HTTP 的响应码则取决于方法的返回值,如果存在返回内容,则响应码是200 OK,否则@ReadOperation方法会返回404 Not Found,而另两个则返回204 No Content;对于需要参数但又获取不到的情况,方法会返回400 Bad Request。我们为 BinaryTea 编写了一个返回商店状态的端点,具体如代码示例 5-5 所示,大部分逻辑与
ShopReadyHealthIndicator是类似的,这里就不再赘述了。代码示例 5-5
ShopEndpoint代码片段@Component @Endpoint(id = "shop") public class ShopEndpoint { private BinaryTeaProperties binaryTeaProperties; public ShopEndpoint(ObjectProvider<BinaryTeaProperties> binaryTeaProperties) { this.binaryTeaProperties = binaryTeaProperties.getIfAvailable(); } @ReadOperation public String state() { if (binaryTeaProperties == null || !binaryTeaProperties.isReady()) { return "We're not ready."; } else { return "We open " + binaryTeaProperties.getOpenHours() + "."; } } }为了能访问到我们的端点,需要在
application.properties中允许它以 Web 形式发布:management.endpoints.web.exposure.include=health,info,shop启动系统后,通过
http://localhost:8080/actuator/shop即可访问ShopEndpoint的输出。
5.2 基于 Micrometer 的系统度量
系统在生产环境中运行时,我们需要通过各种方式了解系统的运作是否正常。之前提到的 health 端点只能判断最基本的情况,至于更多细节,还需要获取详细的度量指标, metrics 端点就是用来提供系统度量信息的。
5.2.1 Micrometer 概述
从 2.0 版本开始,Spring Boot 就把 Micrometer 作为默认的系统度量指标获取途径了,因此本节也先从 Micrometer 讲起。
Java 开发者应该都很熟悉 SLF4J(Simple Logging Facade for Java),它提供了一套日志框架的抽象,屏蔽了底层不同日志框架(比如 Commons Logging、Log4j 和 Logback)实现上的差异,让开发者能以统一的方式在代码中打印日志。如果说 Micrometer 的目标就是成为度量界的 SLF4J,相信大家就能理解 Micrometer 是干什么的了。
Micrometer 为很多主流的监控系统提供了一套简单且强大的客户端门面,先是定义了一套 SPI(Service Provider Interface),再为不同的监控系统提供实现。接入 Micrometer 后,开发者通过 Micrometer 进行埋点时就不会被绑定在某个特定的监控系统上。它支持的监控系统,以及这些系统的特性,如表 5-7 所示。
表 5-7 Micrometer 支持的监控系统清单
| 监控系统 | 是否支持多维度 | 数据聚合方式 | 数据获取方式 |
|---|---|---|---|
| AppOptics | 是 | 客户端聚合 | 客户端推 |
| Atlas | 是 | 客户端聚合 | 客户端推 |
| Azure Monitor | 是 | 客户端聚合 | 客户端推 |
| Cloudwatch | 是 | 客户端聚合 | 客户端推 |
| Datadog | 是 | 客户端聚合 | 客户端推 |
| Datadog StatsD | 是 | 客户端聚合 | 服务端拉 |
| Dynatrace | 是 | 客户端聚合 | 客户端推 |
| Elastic | 是 | 客户端聚合 | 客户端推 |
| Etsy StatsD | 否 | 客户端聚合 | 服务端拉 |
| Ganglia | 否 | 客户端聚合 | 客户端推 |
| Graphite | 否 | 客户端聚合 | 客户端推 |
| Humio | 是 | 客户端聚合 | 客户端推 |
| Influx | 是 | 客户端聚合 | 客户端推 |
| JMX | 否 | 客户端聚合 | 客户端推 |
| KairosDB | 是 | 客户端聚合 | 客户端推 |
| New Relic | 是 | 客户端聚合 | 客户端推 |
| Prometheus | 是 | 服务端聚合 | 服务端拉 |
| SignalFx | 是 | 客户端聚合 | 客户端推 |
| Sysdig StatsD | 是 | 客户端聚合 | 服务端拉 |
| Telegraf StatsD | 是 | 客户端聚合 | 服务端拉 |
| Wavefront | 是 | 服务端聚合 | 客户端推 |
Micrometer 通过 Meter 接口来收集系统的度量数据,由 MeterRegistry 来创建并管理 Meter,Micrometer 支持的各种监控系统都有自己的 MeterRegistry 实现。内置的 Meter 实现分为几种,具体如表 5-8 所示。
表 5-8 几种主要的 Meter 实现
Meter 类型 | 说明 |
|---|---|
Timer | 计时器,用来记录一个事件的耗时 |
Counter | 计数器,用来表示一个单调递增的值 |
Gauge | 计量仪,用来表示一个变化的值,通常能用 Counter 就不用 Gauge |
DistributionSummary | 分布统计,用来记录事件的分布情况,可以设置一个范围,获取范围内的直方图和百分位数 |
LongTaskTimer | 长任务计时器,记录一个长时间任务的耗时,可以记录已经耗费的时间 |
FunctionCounter | 函数计数器,追踪某个单调递增函数的计数器 |
FunctionTimer | 函数计时器,追踪两个单调递增函数,一个计数,另一个计时 |
要创建 Meter,既可以通过 MeterRegistry 上的方法,例如 registry.timer("foo"),也可以通过 Fluent 风格的构建方法,例如 Timer.builder("foo").tags("bar").register(registry)。 Meter 的命名采用以 . 分隔的全小写单词组合,不同的监控系统功能有不同的命名方式,Micrometer 会负责将 Meter 的名称转为合适的方式,在官方文档中就给出了这样一个例子:
registry.timer("http.server.requests");
在使用 Prometheus 时,这个 Timer 的名字就会被转为 http_server_requests_duration_seconds。
标签也遵循一样的命名方式,Micrometer 同样也会负责帮我们将 Timer 的标签转换成不同监控系统所推荐的名称。下面的标签名为 uri,值为 /api/orders:
registry.timer("http.server.requests", "uri", "/api/orders");
针对通用的标签,Micrometer 还贴心地提供了公共标签的功能,在 MeterRegistry 上设置标签:
registry.config().commonTags("prod", "region", "cn-shanghai-1");
5.2.2 常用度量指标
Spring Boot Actuator 中提供了 metrics 端点,通过 /actuator/metrics 我们可以获取系统的度量值。而且 Spring Boot 还内置了很多实用的指标,可以直接拿来使用。
首先介绍的是 Micrometer 本身支持的 JVM 相关指标,具体见表 5-9。
表 5-9 Micrometer 支持的 JVM 度量指标
| 度量指标 | 说明 |
|---|---|
ClassLoaderMetrics | 收集加载和卸载的类信息 |
JvmMemoryMetrics | 收集 JVM 内存利用情况 |
JvmGcMetrics | 收集 JVM 的 GC 情况 |
ProcessorMetrics | 收集 CPU 负载情况 |
JvmThreadMetrics | 收集 JVM 中的线程情况 |
用下面的语句就能绑定一个 ClassLoaderMetrics:
new ClassLoaderMetrics().bindTo(registry);
但在 Spring Boot Actuator 的帮助下,我们无须自己来绑定这些度量指标,Spring Boot 中 JvmMetricsAutoConfiguration 之类的自动配置类已经替我们做好了绑定的工作。此外,它还在此基础上提供了 Spring MVC、Spring WebFlux、HTTP 客户端和数据源等其他度量指标。
仍然以 5.1.4 节的 binarytea-endpoint 为例,我们在 application.properties 中做些修改,将 metrics 端点加入 Web 可访问的端点中:
management.endpoints.web.exposure.include=health,info,shop,metrics
启动程序后,通过 http://localhost:8080/actuator/metrics 可以看到类似下面这样的一个清单,其中列举的 names 就是具体的度量指标名称:
{
"names": [
"http.server.requests",
"jvm.buffer.count",
"jvm.buffer.memory.used",
"jvm.buffer.total.capacity",
"jvm.classes.loaded",
"jvm.classes.unloaded",
"jvm.gc.live.data.size",
"jvm.gc.max.data.size",
"jvm.gc.memory.allocated",
"jvm.gc.pause",
"jvm.memory.max",
"jvm.memory.used",
"jvm.threads.live",
"jvm.threads.peak",
"logback.events",
"process.cpu.usage",
"process.files.max",
"process.start.time",
"process.uptime",
"system.cpu.usage",
"system.load.average.1m",
"tomcat.sessions.active.current",
"tomcat.sessions.active.max",
"tomcat.sessions.rejected"
// 列表中省略了一些内容
]
}
在 URI 后增加具体的名称,例如, http://localhost:8080/actuator/metrics/jvm.classes.loaded,就能查看具体的度量信息:
{
"availableTags": [
],
"baseUnit": "classes",
"description": "The number of classes that are currently loaded in the Java virtual machine",
"measurements": [
{
"statistic": "VALUE",
"value": 7232.0
}
],
"name": "jvm.classes.loaded"
}
-
Spring MVC
默认所有基于 Spring MVC 的 Web 请求都会被记录下来,通过
/actuator/metrics/http.server.requests我们可以查看类似下面这样的输出,其中包含了大量的信息,比如用过的 HTTP 方法、访问过的地址、返回的 HTTP 响应码、请求的总次数和总耗时,以及最大单次耗时等:{ "availableTags": [ { "tag": "exception", "values": ["None"] }, { "tag": "method", "values": ["GET"] }, { "tag": "uri", "values": [ "/actuator/metrics/", "/actuator/metrics" ] }, { "tag": "outcome", "values": ["SUCCESS"] }, { "tag": "status", "values": ["200"] } ], "baseUnit": "seconds", "description": null, "measurements": [ { "statistic": "COUNT", "value": 5.0 }, { "statistic": "TOTAL_TIME", "value": 0.085699938 }, { "statistic": "MAX", "value": 0.042694752 } ], "name": "http.server.requests" }management.metrics.web.server.request.autotime.enabled默认为true,它能自动统计所有的 Web 请求,如果我们将它设置为false,则需要自己在类上或者方法上添加@Timed来标记要统计的Controller方法,@Timed注解可以做些更精细的设置,例如,添加额外的标签,计算百分位数,等等:@Controller public class SampleController { @RequestMapping("/") @Timed(extraTags = { "region", "cn-shanghai-1" }, percentiles = 0.99) public String foo() {} } -
HTTP 客户端
当使用
RestTemplate和WebClient访问 HTTP 服务时,Spring Boot Actuator 提供了针对 HTTP 客户端的度量指标,但这并不是自动的,还需要做一些配置它们才能生效。这里建议通过如下方式来创建RestTemplate:@Bean public RestTemplate restTemplate(RestTemplateBuilder builder) { return builder.build(); }使用
RestTemplateBuilder来构建RestTemplate时,会对其应用所有配置在 Spring 上下文里的RestTemplateCustomizer,而其中就有与度量相关的MetricsRestTemplateCustomizer。针对WebClient也是一样的,可以用WebClient.Builder。如果大家有通过
RestTemplate访问过 HTTP 服务,访问/actuator/metrics/http.client.requests后就能看到类似下面这样的输出:{ "availableTags": [ { "tag": "method", "values": [ "GET" ] }, { "tag": "clientName", "values": [ "localhost" ] }, { "tag": "uri", "values": [ "/actuator/metrics" ] }, { "tag": "outcome", "values": [ "SUCCESS" ] }, { "tag": "status", "values": [ "200" ] } ], "baseUnit": "seconds", "description": "Timer of RestTemplate operation", "measurements": [ { "statistic": "COUNT", "value": 1.0 }, { "statistic": "TOTAL_TIME", "value": 0.115555898 }, { "statistic": "MAX", "value": 0.115555898 } ], "name": "http.client.requests" } -
数据源
对于那些使用了数据库的系统,了解数据源的具体情况是非常有必要的,例如,当前的连接池配置的大小是什么样的,有多少个连接处于活跃状态等。如果连接池经常被占满,导致业务代码无法获取连接,那么无论是让业务线程等待连接,还是等待超时后报错都可能影响业务。
只要在 Spring 上下文中存在
DataSourceBean,Spring Boot Actuator 就会自动配置对应的度量指标,如果我们使用的是 HikariCP,还会有额外的信息。访问/actuator/metrics后能看到下面这些显示:{ "names": [ "hikaricp.connections", "hikaricp.connections.acquire", "hikaricp.connections.active", "hikaricp.connections.creation", "hikaricp.connections.idle", "hikaricp.connections.max", "hikaricp.connections.min", "hikaricp.connections.pending", "hikaricp.connections.timeout", "hikaricp.connections.usage", "jdbc.connections.max", "jdbc.connections.min" // 省略其他无关的内容 ] }而具体到
/actuator/metrics/hikaricp.connections则是这样的:{ "availableTags": [ { "tag": "pool", "values": [ "HikariPool-1" ] } ], "baseUnit": null, "description": "Total connections", "measurements": [ { "statistic": "VALUE", "value": 10.0 } ], "name": "hikaricp.connections" }通过这些度量指标,我们可以轻松地掌握系统中数据源的大概情况,在遇到问题时更好地进行决策。
5.2.3 自定义度量指标
Spring Boot Actuator 内置的度量指标可以帮助我们掌握系统的情况,但光了解系统是远远不够的,系统运行正常,但业务指标却一路下滑的情况并不少见,因此还需要针对各种业务做对应的数据埋点,通过业务指标我们也可以反过来进一步了解系统的情况。
有两种绑定 Meter 的方法,一般可以考虑使用后者:
- 注入 Spring 上下文中的
MeterRegistry,通过它来绑定Meter; - 让 Bean 实现
MeterBinder,在其bindTo()方法中绑定Meter。
下面,让我们通过二进制奶茶店项目中的一个例子来了解一下如何自定义度量指标。
需求描述 门店开始营业后,我们要频繁关注经营情况,像订单总笔数、总金额、客单价等都是常见的经营指标,最好能有个地方可以让经营者方便地看到这些信息。
以 5.1.4 节的 binarytea-endpoint 作为基础,增加如表 5-10 所示的三个经营指标,用来记录自开始营业起的经营情况,相信是个经营者都关心自己的店是不是赚钱吧?大家可以在本书配套示例的 ch5/binarytea-metrics 目录中找到这个例子。
表 5-10 三个经营指标
| 指标名称 | 类型 | 含义 |
|---|---|---|
order.count | Counter | 总订单数 |
order.amount.sum | Counter | 总订单金额 |
order.amount.average | Gauge | 客单价 |
除此之外,为了演示 DistributionSummary 的用法,我们还额外增加了一个 order.summary 的指标,可以输出 95 分位的订单情况。对应的 Meter 配置与绑定代码如代码示例 5-6 所示,其中绑定了四个 Meter(为了方便演示,客单价使用了一个整数),还提供了一个新的下订单方法,用来改变各 Meter 的值。
代码示例 5-6 SalesMetrics 的代码片段
@Component
public class SalesMetrics implements MeterBinder {
private Counter orderCount;
private Counter totalAmount;
private DistributionSummary orderSummary;
private AtomicInteger averageAmount = new AtomicInteger();
@Override
public void bindTo(MeterRegistry registry) {
this.orderCount = registry.counter("order.count", "direction", "income");
this.totalAmount = registry.counter("order.amount.sum", "direction", "income");
this.orderSummary = registry.summary("order.summary", "direction", "income");
registry.gauge("order.amount.average", averageAmount);
}
public void makeNewOrder(int amount) {
orderCount.increment();
totalAmount.increment(amount);
orderSummary.record(amount);
averageAmount.set((int) orderSummary.mean());
}
}
由于现阶段还没有开发下单的客户端,我们可以在 BinaryTeaApplication 这个主程序中通过 2.4.2 节中介绍的定时任务来定时下单,如代码示例 5-7 所示,其中金额为 0 至 100 元内的随机整数,每隔 5 秒会下一单并打印日志。
代码示例 5-7 可以定时下单的主程序代码片段
@SpringBootApplication
@EnableScheduling
public class BinaryTeaApplication {
private static Logger logger = LoggerFactory.getLogger(BinaryTeaApplication.class);
private Random random = new Random();
@Autowired
private SalesMetrics salesMetrics;
public static void main(String[] args) {
SpringApplication.run(BinaryTeaApplication.class, args);
}
@Scheduled(fixedRate = 5000, initialDelay = 1000)
public void periodicallyMakeAnOrder() {
int amount = random.nextInt(100);
salesMetrics.makeNewOrder(amount);
logger.info("Make an order of RMB {} yuan.", amount);
}
}
此时,通过 /actuator/metrics 我们会看到多出了如下几个指标:
{
"names": [
"order.amount.average",
"order.amount.sum",
"order.count",
"order.summary",
// 省略其他内容
]
}
具体访问 /actuator/metrics/order.summary 则能看到类似下面这样的输出:
{
"availableTags": [
{ "tag": "direction", "values": [ "income" ] }
],
"baseUnit": null,
"description": null,
"measurements": [
{ "statistic": "COUNT", "value": 168.0 },
{ "statistic": "TOTAL", "value": 7890.0 },
{ "statistic": "MAX", "value": 95.0 }
],
"name": "order.summary"
}
Spring Boot Actuator 中可以对 Micrometer 的度量指标做很多定制,我们既可以按照 Micrometer 的官方做法用 MeterFilter 精确地进行调整,也可以简单地使用配置来做些常规的改动。
例如,可以像下面这样来设置公共标签,将 region 标签的值设置为 cn-shanghai-1:
management.metrics.tags.region=cn-shanghai-1
针对每个 Meter 也有一些对应的属性,如表 5-11 所示,表中给出的是前缀,在其后面带上具体的度量指标名称后,即可有针对性地进行设置了,例如 management.metrics.enable.order.amount.average=false。
表 5-11 部分针对单个 Meter 的属性前缀
| 属性前缀 | 说明 | 适用范围 |
|---|---|---|
management.metrics.enable | 是否开启 | 全部 |
management.metrics.distribution.minimum-expected-value | 分布统计时范围的最小值 | Timer 与 DistributionSummary |
management.metrics.distribution.maximum-expected-value | 分布统计时范围的最大值 | Timer 与 DistributionSummary |
management.metrics.distribution.percentiles | 分布统计时希望计算的百分位值 | Timer 与 DistributionSummary |
如果希望输出 95 分位的订单情况,可以像代码示例 5-8 那样修改 application.properties 文件。
代码示例 5-8 修改后的 application.properties
binarytea.ready=true
binarytea.open-hours=8:30-22:00
management.endpoint.health.show-details=always
management.endpoints.web.exposure.include=health,info,shop,metrics
management.metrics.distribution.percentiles.order.summary=0.95
配置后会多出一个 order.summary.percentile 的度量指标,具体的内容大致如下所示:
{
"availableTags": [
{ "tag": "phi", "values": [ "0.95" ] },
{ "tag": "direction", "values": [ "income" ] }
],
"baseUnit": null,
"description": null,
"measurements": [
{ "statistic": "VALUE", "value": 87 }
],
"name": "order.summary.percentile"
}
茶歇时间:性能分析时的 95 线与 99 线是什么含义
说到衡量一个接口的耗时怎么样,大家的第一反应大多是使用平均响应时间。的确,平均耗时能代表大部分情况下接口的表现。假设一个接口的最小耗时为 4 毫秒,平均耗时为 8 毫秒—看起来性能挺好的,但如果经常会有那么几个请求的时间超过 1000 毫秒,那我们是否应该继续去优化它呢?
答案是肯定的,对于这类长尾的请求,我们还需要去做进一步的分析,这其中必然隐藏着一些问题。在性能测试中,我们往往会更多地关注 TP95 或者 TP99(TP 是 Top Percentile 的缩写),也就是通常所说的 95 线和 99 线指标。在 100 个请求中,按耗时从小到大排序,第 95 个就是耗时的 95 线,95%的请求都能在这个时间内完成。
还有更苛刻的条件是要去分析 TP9999,也就是 99.99%的情况,这样才能确保绝大部分请求的耗时都达到要求。
5.2.4 度量值的输出
通过 /actuator/metrics 虽然可以看到每个度量值的情况,但我们无法一直盯着这个 URI 看输出。在实际生产环境中,我们需要一个更成熟的度量值输出和收集的方案。好在 Micrometer 和 Spring Boot 早已经考虑到了这些,为我们准备好了。
-
输出到日志
Micrometer 提供了几个基本的
MeterRegistry,其中之一就是LoggingMeterRegistry,它可以定时将系统中的各个度量指标输出到日志中。有了结构化的日志信息,就能通过 ELK(Elasticsearch、Logstash 和 Kibana)等方式将它们收集起来,并加以分析。即使不做后续处理,把这些日志放着,作为日后回溯的材料也是可以的。前一节的例子中,在
BinaryTeaApplication里加上代码示例 5-9 的代码,用来定义一个组合的MeterRegistry,其中添加了基础的SimpleMeterRegistry和输出日志的LoggingMeterRegistry。代码示例 5-9 组合多个
MeterRegistry的定义@Bean public MeterRegistry customMeterRegistry() { CompositeMeterRegistry meterRegistry = new CompositeMeterRegistry(); meterRegistry.add(new SimpleMeterRegistry()); meterRegistry.add(new LoggingMeterRegistry()); return meterRegistry; }运行后,过一段时间就能在控制台输出的日志中看到类似下面的内容:
2022-02-06 22:44:00.029 INFO 50342 --- [trics-publisher] i.m.c.i.logging.LoggingMeterRegistry : jvm.gc. pause throughput=0.033333/s mean=0.012s max=0.012s 2022-02-06 22:44:00.030 INFO 50342 --- [trics-publisher] i.m.c.i.logging.LoggingMeterRegistry : order. summary throughput=0.133333/s mean=40.125 max=84在生产环境中使用时,我们可以调整日志的配置文件,将
LoggingMeterRegistry输出的日志打印到单独的日志中,方便管理。 -
输出到 Prometheus
在介绍 Mircometer 时,我们提到过它支持多种不同的监控系统,将度量信息直接输出到监控系统也是一种常见做法。下面以 Prometheus 为例,介绍一下它在 Spring Boot 系统中该如何操作。
首先,需要在项目的 pom.xml 中添加 Micrometer 为 Prometheus 编写的
MeterRegistry依赖,有了这个依赖,后面的事交给 Spring Boot 的自动配置即可:<dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-registry-prometheus</artifactId> </dependency>随后,在
application.properties中放开对对应端点的控制,让prometheus端点可以通过 Web 访问:management.endpoints.web.exposure.include=health,info,shop,metrics,prometheus再次运行我们的程序,在浏览器中访问
/actuator/prometheus就能看到一个文本输出,Prometheus 在经过适当配置后会读取其中的内容,可以看到其中的名称已经从 Micrometer 的以点分隔,变为了 Prometheus 的下划线分隔,这也是 Micrometer 实现的:# 省略了很多内容,以下仅为片段 jvm_memory_max_bytes 2.44105216E8 # HELP order_count_total # TYPE order_count_total counter order_count_total 7.0 # HELP order_summary_max # TYPE order_summary_max gauge order_summary_max 76.0 # HELP order_summary # TYPE order_summary summary order_summary 79.5 order_summary_count 7.0 order_summary_sum 347.0 # HELP tomcat_sessions_active_current_sessions # TYPE tomcat_sessions_active_current_sessions gauge tomcat_sessions_active_current_sessions 0.0
5.3 部署 Spring Boot 应用程序
在 Spring Boot Actuator 的帮助下,我们早早地就准备好了一些手段来掌握系统在运行时的各种指标,现在就差临门一脚,让系统在服务器上跑起来了,而这也是一门学问,在这一节里就让我们一同来了解一下其中的秘诀。
5.3.1 可执行 Jar 及其原理
放到以前,要运行 Java EE 的应用程序需要一个应用容器,比如 JBoss 或者 Tomcat。但随着技术的发展,外置容器已经不再是必选项了,Spring Boot 可以内嵌 Tomcat、Jetty 等容器,一句简单的 java -jar 命令就能让我们的工程像个普通进程一样运行起来。
-
通过 Maven 打包整个工程
在用 Maven 命令打包前,先来回顾一下 pom.xml 中配置的插件:
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
spring-boot-maven-plugin 会在 Maven 的打包过程中自动介入,除了生成普通的 Jar 包外,还会生成一个包含所有依赖的 Fat Jar。以上一节用到的 ch5/binarytea-export 为例,打开一个终端(macOS 中的终端,对应 Windows 中的 CMD 或者 PowerShell),在工程目录中(即 pom.xml 的目录)键入如下命令:
▸ mvn clean package -Dmaven.test.skip
随后,查看 target 目录的内容,大致会是下面这样的:
total 38712
-rw-r--r-- 1 digitalsonic staff 19M 2 7 22:43 binarytea-0.0.1-SNAPSHOT.jar
-rw-r--r-- 1 digitalsonic staff 8.3K 2 7 22:43 binarytea-0.0.1-SNAPSHOT.jar.original
drwxr-xr-x 5 digitalsonic staff 160B 2 7 22:43 classes
drwxr-xr-x 3 digitalsonic staff 96B 2 7 22:43 generated-sources
drwxr-xr-x 3 digitalsonic staff 96B 2 7 22:43 maven-archiver
drwxr-xr-x 3 digitalsonic staff 96B 2 7 22:43 maven-status
其中的 binarytea-0.0.1-SNAPSHOT.jar.original 是原始的 Jar 包,仅包含工程代码编译后的内容,大小只有 8.3KB;而 binarytea-0.0.1-SNAPSHOT.jar 则有 19MB,这就是生成的可执行 Jar 包。只需简单的一条命令就能将工程运行起来:
▸ java -jar target/binarytea-0.0.1-SNAPSHOT.jar
-
可执行 Jar 背后的原理
binarytea-0.0.1-SNAPSHOT.jar相比binarytea-0.0.1-SNAPSHOT.jar.original而言,简直就是一个庞然大物,通过unzip命令查看 Jar 包内容,我们可以看到它基本由以下几部分组成:
META-INF,工程的元数据,例如 Maven 的描述文件与spring.factories文件;org/springframework/boot/loader,Spring Boot 用来引导工程启动的 Loader 相关类;BOOT-INF/classes,工程自身的类与资源文件;BOOT-INF/lib,工程所依赖的各种其他 Jar 文件。
大概就像下面这样:
▸ unzip -l binarytea-0.0.1-SNAPSHOT.jar
Archive: binarytea-0.0.1-SNAPSHOT.jar
Length Date Time Name
--------- ---------- ----- ----
0 02-07-2022 22:43 META-INF/
472 02-07-2022 22:43 META-INF/MANIFEST.MF
103 02-07-2022 22:43 META-INF/spring.factories
# 省略大量META-INF/下的文件
0 02-01-1980 00:00 org/
0 02-01-1980 00:00 org/springframework/
0 02-01-1980 00:00 org/springframework/boot/
0 02-01-1980 00:00 org/springframework/boot/loader/
5871 02-01-1980 00:00 org/springframework/boot/loader/ClassPathIndexFile.class
# 省略大量org/下的文件
0 02-07-2022 22:43 BOOT-INF/
0 02-07-2022 22:43 BOOT-INF/classes/
242 02-07-2022 22:43 BOOT-INF/classes/application.properties
0 02-07-2022 22:43 BOOT-INF/classes/learning/
0 02-07-2022 22:43 BOOT-INF/classes/learning/spring/
# 省略大量BOOT-INF/classes/下的文件
0 02-07-2022 22:43 BOOT-INF/lib/
1423985 01-20-2022 14:03 BOOT-INF/lib/spring-boot-2.6.3.jar
1627754 01-20-2022 14:02 BOOT-INF/lib/spring-boot-autoconfigure-2.6.3.jar
# 省略大量BOOT-INF/lib/下的文件
--------- -------
19930105 141 files
运行这个 Jar 所需要的信息都记录在了 META-INF/MANIFEST.MF 中,具体内容如下所示:
Manifest-Version: 1.0
Created-By: Maven JAR Plugin 3.2.2
Build-Jdk-Spec: 11
Implementation-Title: BinaryTea
Implementation-Version: 0.0.1-SNAPSHOT
Main-Class: org.springframework.boot.loader.JarLauncher
Start-Class: learning.spring.binarytea.BinaryTeaApplication
Spring-Boot-Version: 2.6.3
Spring-Boot-Classes: BOOT-INF/classes/
Spring-Boot-Lib: BOOT-INF/lib/
Spring-Boot-Classpath-Index: BOOT-INF/classpath.idx
Spring-Boot-Layers-Index: BOOT-INF/layers.idx
java 命令会找到 Main-Class 作为启动类,Spring Boot 提供了三种不同的 Launcher,可以从内嵌文件中加载启动所需的资源:
JarLauncher,从 Jar 包的固定位置加载内嵌资源,即BOOT-INF/lib/;WarLauncher,从 War 包的固定位置加载内嵌资源,分别为WEB-INF/lib/和WEB-INF/lib-provided/;PropertiesLauncher,默认从BOOT-INF/lib/加载资源,但可以通过环境变量来指定额外的位置。
默认生成的工程会使用 JarLauncher 生成可执行 Jar 包,而启动后执行的具体代码则由 StartClass 指定,我们可以看到这个类就是添加了 @SpringBootApplication 注解的类。
用这种方式打包有两个 局限。
- Jar 文件其实就是一个 ZIP 文件,ZIP 文件可以设置压缩力度,从仅存储(不压缩)到最大化压缩,在内嵌 Jar 的情况下,我们只能使用
ZipEntry.STORED,即仅存储,不压缩的方式。 - 要获取
ClassLoader时必须使用Thread.getContextClassLoader(),而不能使用ClassLoader.getSystemClassLoader()。
Spring Boot 中还有一种更激进的方式,生成可以直接在 Linux 中运行的 Jar 文件,不再需要 java -jar 命令(当然,这个文件中不包含 JRE),具体修改 spring-boot-maven-plugin 配置的方式如下:
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<executable>true</executable>
</configuration>
</plugin>
</plugins>
</build>
这样通过 mvn package 打出的 Jar 包会更特殊一些,用文本编辑器或者 less 命令查看这个文件,我们会发现这个文件的头部其实是个 Shell 脚本,后面才是压缩的 Jar 包内容。这背后的“魔法”正是 利用了 Shell 脚本是从前往后解析,而 Jar 文件则是从后往前解析的特性。
现在要运行这个文件只需简单的 ./target/binarytea-0.0.1-SNAPSHOT.jar 就可以了。对应的一些类似 JVM 参数和运行的参数,可以放在同名的 .conf 配置文件中,一些基本的执行配置项见表 5-12。
表 5-12 一些基本的执行配置项
| 配置项 | 说明 |
|---|---|
CONF_FOLDER | .conf 文件的目录位置,因为要靠它加载配置文件,所以这个参数必须放在环境变量里 |
JAVA_OPTS | 启动 Java 程序使用的 JVM 参数,比如 JVM 内存和 GC 相关的参数 |
RUN_ARGS | 运行程序所需提供的运行时参数 |
这样一来就可以把这个 Jar 文件放在 init.d 或 systemd 里运行了,但不得不说,相比 java -jar,这种用法还是很少见的。此外,更新的技术出现了,不仅能代替这种方式,而且还带来了更好的体验,这就是 GraalVM。GraalVM 能把 Java 程序编译为 Linux 二进制,系统启动速度更快,所占内存更小。
5.3.2 构建启动代码
在之前的例子中我们已经多次看到过带有 @SpringBootApplication 注解的主类,其中用 SpringApplication.run() 方法来运行我们的代码。Spring Boot 为我们预留了很多自定义工程启动的扩展点,比如可以设置启动的各种参数,能针对失败进行各种处理、还能定制自己的 Banner 栏等。
-
自定义 SpringApplication
通过 Spring Initializr 生成的工程,其中的
main()方法应该是下面这样的,它可以满足绝大部分的需求:
public static void main(String[] args) {
SpringApplication.run(BinaryTeaApplication.class, args);
}
我们也完全可以自己新建一个 SpringApplication 对象,设置各种属性,例如 bannerMode 和 lazyInitialization 等,随后再调用它的 run() 方法。
当然,这样的操作略显繁琐,Spring Boot 贴心地提供了一个 SpringApplicationBuilder 构造器,通过它我们可以流畅地编写类似代码示例 5-10 这样的代码。
代码示例 5-10 通过 SpringApplicationBuilder 启动应用程序
public static void main(String[] args) {
new SpringApplicationBuilder()
.sources(BinaryTeaApplication.class)
.main(BinaryTeaApplication.class)
.bannerMode(Banner.Mode.OFF)
.web(WebApplicationType.SERVLET)
.run(args);
}
上面的一些设置代码,也可以改用配置文件的方式,在 application.properties 或 application.yml 里进行设置,例如在 application.properties 里可以像下面这样来关闭 Web 容器和 Banner 栏:
spring.main.web-application-type=none
spring.main.banner-mode=off
-
通过 FailureAnalyzer 提供失败原因分析
程序启动时,如果遇到异常就会退出,这时需要查看日志,分析原因,那有没有可能让系统自己分析原因,然后告诉我们为什么失败了呢?答案是肯定的,因为 Spring Boot 可以通过
FailureAnalyzer来分析失败,并打印分析出的原因。表 5-13 罗列了一些内置的FailureAnalyzer实现类,Spring Boot 内置了近 20 种不同的分析器,表 5-13 里展示的只是其中的一小部分。表 5-13 Spring Boot 的部分内置
FailureAnalyzer实现类
FailureAnalyzer 实现类 | 功能 |
|---|---|
BindFailureAnalyzer | 提示属性绑定相关异常 |
DataSourceBeanCreationFailureAnalyzer | 提示数据源创建相关异常 |
InvalidConfigurationPropertyNameFailureAnalyzer | 提示配置属性名不正确 |
NoSuchBeanDefinitionFailureAnalyzer | 提示 Spring 上下文中找不到需要的 Bean 定义 |
NoUniqueBeanDefinitionFailureAnalyzer | 提示要注入一个 Bean,但实际却找到了不止一个 |
我们也可以根据实际情况,提供自己的 FailureAnalyzer 实现类。方便起见,Spring Boot 提供了一个 AbstractFailureAnalyzer<T extends Throwable> 抽象类,其中的泛型 T 就是要分析的异常,实现这个抽象类会更简单,框架内置的大部分实现都是基于这个抽象类来开发的。我们以 Spring Boot 的 PortInUseFailureAnalyzer 为例,看到传入待分析的异常是 PortInUseException 就能知道端口已经被占用了,从而直观地提示 Web 服务器端口已被占用:
class PortInUseFailureAnalyzer extends AbstractFailureAnalyzer<PortInUseException> {
@Override
protected FailureAnalysis analyze(Throwable rootFailure, PortInUseException cause) {
return new FailureAnalysis("Web server failed to start. Port " + cause.getPort() + " was already in use.",
"Identify and stop the process that's listening on port " + cause.getPort() + " or configure this "
+ "application to listen on another port.", cause);
}
}
-
自定义 Banner 栏
启动程序时,默认会打出 Spring 的字样,这是由 ASCII 字符组成的图案,看起来非常的酷炫。我们可以通过
spring.main.banner-mode属性来控制 Banner 的输出方式:
Banner.Mode.OFF(属性值为off),关闭输出;Banner.Mode.CONSOLE(属性值为console),输出到控制台,即标准输出 STDOUT;Banner.Mode.LOG(属性值为log),输出到日志。
如果要自定义输出的内容,可以在 CLASSPATH 中放置一个 banner.txt,也可以通过 spring.banner.location 指定文件位置,文件中除了 ASCII 图案,还可以写一些占位符,例如,可以从 MANIFEST.MF 文件中获取一些信息:
$,对应Implementation-Title;$,对应Implementation-Version;$,同样对应Implementation-Version,但会添加v前缀,再将版本放在括号内。
当然,如果还希望做得更彻底,我们可以直接写一个自己的 org.springframework.boot.Banner 接口实现,在其中的 printBanner() 方法里打印 Banner。
茶歇时间:如何优雅地关闭系统
系统有启动,自然就会有关闭的时候。如果说异常宕机时损失一个实例对整个集群的服务造成部分影响还情有可原,那常规的系统升级发布就不应该对整体服务有任何影响。
在我们打算关闭系统时,可能会遇到如下的情况(不仅限于此):
- 系统仍在接收同步请求,例如,在处理 HTTP 请求;
- 系统仍在消费消息,例如,在消费 Kafka 消息;
- 系统有定时任务在运行,可能是分布式调度,也可能是单机的调度任务。
当系统处于处理中的状态时,直接关闭系统可能会影响当前的处理。
为此,我们要针对性地做一些处理,例如,将当前节点从负载均衡中剔除,如果使用 Nginx 进行负载均衡,就调整
upstream的配置;如果是动态发现的,就让健康检查失败(可以使用 5.1 节中提到的health端点),让服务注册中心将节点下线。(在第 13 章中我们还会聊到服务的注册中心。)消息的消费要力争做到可重复消费,因为消费本身就要考虑到消息的乱序和重发等情况。如果一条消息消费到一半,进程被杀掉了,那么消息中间件会认为该消息未被正常处理,会再重新发送。当然,我们也可以做些优化,在停止进程前,不再接收新消息,针对拉(PULL)模式的客户端,不再从服务端拉取新消息,推(PUSH)模式的则不再处理新消息,等待或拒绝也不失为一个好办法。
对调度任务也是一样的,任务需要能够支持“重跑”,高频任务不必多说,低频任务万一被中断,需要有补偿机制,能够快速恢复。例如,分布式调度(诸如 ElasticJob 之类的调度)可以设置故障转移。
Spring Boot 提供了优雅关闭的能力,通过
server.shutdown=graceful这个配置可以开启 Web 服务器优雅关闭的支持,让系统在收到关闭信号时等待一段时间(通过spring.lifecycle.timeout-per-shutdown-phase设置),以便等待当前正在处理的请求处理结束。但通过前面的描述,我们不难发现,仅提供这些能力并不足以在生产环境中做到无损的节点下线,还有大量的工作需要我们自己来实现。
5.3.3 启动后的一次性执行逻辑
在系统启动时,可能会有些初始化后需要立即执行的逻辑,也有可能这就是一个命令行程序,执行完特定逻辑后程序就该退出了。这时我们该怎么办?写一个 Bean,在它的 @PostConstruct 方法中执行逻辑么?其实,在 Spring Boot 中有更好的选择。
Spring Boot 为我们提供了两个接口,分别是 ApplicationRunner 与 CommandLineRunner,它们的功能基本是相同的,只是方法的参数不同,具体如下所示:
public interface ApplicationRunner {
void run(ApplicationArguments args) throws Exception;
}
public interface CommandLineRunner {
void run(String... args) throws Exception;
}
CommandLineRunner 的 run(String... args) 传入的参数与 main(String... args) 方法一样,就是命令行的所有参数。而通过 ApplicationArguments,我们可以更方便灵活地控制命令行中的参数。如果 Spring 上下文中存在多个 ApplicationRunner 或 CommandLineRunner Bean,可以通过 @Order 注解或 Ordered 接口来指定运行的顺序。接下来,让我们看个例子。
需求描述 有奶茶店,自然就会有顾客,每次都让顾客跑到门店找服务员点单多少有些不方便,我们需要一个程序让顾客可以自己下单。所以,为顾客开发一个程序吧。
为了方便演示,建立一个新的 Customer 工程,代表二进制奶茶店的顾客,放在 ch5/customer 项目中,其详细信息如表 5-14 所示。
表 5-14 Customer 工程的详细信息
| 条目 | 内容 |
|---|---|
| 项目 | Maven Project |
| 语言 | Java |
| Spring Boot 版本 | 2.6.3 |
| Group | learning.spring |
| Artifact | customer |
| 名称 | Customer |
| Java 包名 | learning.spring.customer |
| 打包方式 | Jar |
| Java 版本 | 11 |
| 依赖 | Lombok |
这个项目会模拟顾客的操作,目前我们的奶茶店还没开门营业,可以让顾客选择等待奶茶店开门,还是直接离开。
代码示例 5-11 是一个 CommandLineRunner 的实现,它的作用是打印所有的命令行参数,其中的日志输出通过 Lombok 的 @Slf4j 指定了使用 SLF4J 日志框架,无须我们自己定义 log 成员变量。
代码示例 5-11 ArgsPrinterRunner 代码片段
@Component
@Slf4j
@Order(1)
public class ArgsPrinterRunner implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
log.info("共传入了{}个参数。分别是:{}", args.length, StringUtils.arrayToCommaDelimitedString(args));
}
}
代码示例 5-12 是一个 ApplicationRunner 的实现,它会根据命令行上传入的参数来决定是否等待,如果我们通过 wait 选项设置了等待时间,则等待时间即为程序里 sleep 对应的秒数,没有 wait 就直接结束。其中演示了几个方法:
containsOption(),是否包含指定选项(所谓选项,其形式是--选项名=值);getOptionValues(),获取指定选项的值,返回的是一个List,因为可以多次设值,例如--wait=5--wait=6;getNonOptionArgs(),获取非选项类型的其他参数。
代码示例 5-12 WaitForOpenRunner 代码片段
@Component
@Slf4j
@Order(2)
public class WaitForOpenRunner implements ApplicationRunner {
@Override
public void run(ApplicationArguments args) throws Exception {
boolean needWait = args.containsOption("wait");
if (!needWait) {
log.info("如果没开门,就不用等了。");
return;
}
List<String> waitSeconds = args.getOptionValues("wait");
if (!waitSeconds.isEmpty()) {
int seconds = NumberUtils.parseNumber(waitSeconds.get(0), Integer.class);
log.info("还没开门,先等{}秒。", seconds);
Thread.sleep(seconds * 1000);
}
log.info("其他参数:{}",StringUtils.collectionToCommaDelimitedString(args.getNonOptionArgs()));
}
}
使用 mvn clean package -Dmaven.test.skip 命令打包后,通过如下命令启动程序:
▸ java -jar target/customer-0.0.1-SNAPSHOT.jar --wait=3 Hello
运行的结果应该与下面的输出类似:
INFO 85578 --- [main] l.spring.customer.CustomerApplication : Started CustomerApplication in 1.059
seconds (JVM running for 1.482)
INFO 85578 --- [main] l.spring.customer.ArgsPrinterRunner : 共传入了2个参数。分别是:--wait=3,Hello
INFO 85578 --- [main] l.spring.customer.WaitForOpenRunner : 准备等待3秒。
INFO 85578 --- [main] l.spring.customer.WaitForOpenRunner : 其他参数:Hello
程序退出时可以指定一个退出码,在 Linux 或 macOS 操作系统中,可以用 echo $? 命令看到上一条命令的退出码。通常,退出码 0 表示 正常结束,其他的退出码都表示 非正常结束。在 Shell 脚本中往往都会根据某条命令的退出码决定后续的动作。
在 Java 里,可以调用 System.exit() 退出程序,这个方法能够传入需要返回的退出码。Spring Boot 为我们提供了 ExitCodeGenerator 接口,通过实现该接口我们可以加入自己的逻辑来控制退出码,如果存在多个 Bean,可以和前文一样用 @Order 注解或 Ordered 接口来控制顺序。调用 SpringApplication.exit() 方法即可获得最终计算出的退出码,把它传入 System.exit() 就可以了。
作为经营者,我们当然是希望顾客来自己店里,而且如果顾客愿意等我们开门最好了,为此,我们编写一个自己的 ExitCodeGenerator 实现,命令行里提供了 wait 选项则视为正常,否则不正常,具体代码如代码示例 5-13 所示。
代码示例 5-13 直接在 @Bean 方法中实现 ExitCodeGenerator
@SpringBootApplication
public class CustomerApplication {
public static void main(String[] args) {
SpringApplication.run(CustomerApplication.class, args);
}
/**
* 如果命令行里给了wait选项,返回0,否则返回1
*/
@Bean
public ExitCodeGenerator waitExitCodeGenerator(ApplicationArguments args) {
return () -> (args.containsOption("wait") ? 0 : 1);
}
}
框架会自动把上下文中的 ApplicationArguments 作为参数传入 waitExitCodeGenerator(),这里取到的值和我们在 ApplicationRunner 里取到的值是一样的。
随后,简单调整一下 WaitForOpenRunner,在执行完日志输出后调用退出逻辑,如代码示例 5-14 所示。 SpringApplication.exit() 需要传入 ApplicationContext,因此我们让 WaitForOpenRunner 实现 ApplicationContextAware,这里的 Setter 方法直接通过 Lombok 的 @Setter 来实现。
代码示例 5-14 调整后的 WaitForOpenRunner 代码片段
@Component
@Slf4j
@Order(2)
public class WaitForOpenRunner implements ApplicationRunner, ApplicationContextAware {
@Setter
private ApplicationContext applicationContext;
@Override
public void run(ApplicationArguments args) throws Exception {
boolean needWait = args.containsOption("wait");
if (!needWait) {
log.info("如果没开门,就不用等了。");
} else {
List<String> waitSeconds = args.getOptionValues("wait");
if (!waitSeconds.isEmpty()) {
int seconds = NumberUtils.parseNumber(waitSeconds.get(0), Integer.class);
log.info("还没开门,先等{}秒。", seconds);
Thread.sleep(seconds * 1000);
}
log.info("其他参数:{}", StringUtils.collectionToCommaDelimitedString(args.getNonOptionArgs()));
}
System.exit(SpringApplication.exit(applicationContext));
}
}
现在重新打包运行我们的程序,如果命令行里没有 --wait,退出码就是 1。
茶歇时间:通过 Lombok 简化代码
相信只要是写过 Java 的人都会写过
Getter和Setter方法,虽然绝大多数人会选择让 IDE 来自动生成,但本着“懒惰是程序员的第一大美德”的理念,能不要这些代码,我们还是希望就不出现这些代码。与之类似的还有简单的用于成员变量赋值的构造方法、Logger对象的定义语句等。Lombok 就是这样一个解放生产力的利器,它通过一系列注解消灭了上述冗长繁琐的语句。常用的一些注解如表 5-15 所示。
表 5-15 常用的 Lombok 注解
| 注解 | 作用 |
|---|---|
@Getter / @Setter | 自动生成成员属性的 Getter 和 Setter 方法 |
@ToString | 自动生成 toString() 方法,默认拼接所有的成员属性,也可以排除指定的属性 |
@NoArgsConstructor / @RequiredArgsConstructor / @AllArgsConstructor | 自动生成无参数的构造方法,必要参数的构造方法以及包含全部参数的构造方法 |
@EqualsAndHashCode | 自动生成 equals() 与 hashCode() 方法 |
@Data | 相当于添加了 @ToString、 @EqualsAndHashCode、 @Getter、 @Setter 和 @RequiredArgsConstructor 注解 |
@Builder | 提供了一个灵活的构造器,能够设置各个成员变量,再据此创建对象实例 |
@Slf4j / @CommonsLog / @Log4j2 | 自动生成对应日志框架的日志类,例如定义了一个 Logger 类型的 log,方便输出日志 |
需要注意的是,虽然编译时没有什么特殊设置,但在 IDE 中,为了开启对 Lombok 的支持,我们需要安装对应 IDE 的 Lombok 插件,例如,IDEA 中要安装 IntelliJ Lombok plugin。
5.4 小结
本章我们学习了 Spring Boot 提供的面向生产环境的诸多功能,例如,Spring Boot Actuator 的各种端点,如何自己定制健康检查信息。还学习了生产环境中所必不可少的度量方法,通过 Micrometer 输出各种内容,帮助我们了解系统的运行情况。最后,把开发好的代码打包成了实际可以部署的 Jar 包,Spring Boot 的 Jar 包可以直接执行,我们对这背后的原理也做了说明。除此之外,还聊了聊怎么编写用来启动整个工程的 SpringAppliation 代码,控制整个启动和运行的逻辑。
在代码示例中,我们第一次引入了 Lombok,它可以在很大程度上简化我们的代码,在日常工作中也强烈建议大家使用。
专栏的第一部分到此就告一段落了,我们学习了 Spring Framework 与 Spring Boot 的一些基础知识和用法,从下一章开始,我们将进入新的环节,编写与数据库交互的系统。
二进制奶茶店项目开发进度
本章我们为二进制奶茶店的程序增加了一些面向生产环境的功能:
- 添加了可在运行时了解营业情况的健康检查项和端点;
- 添加了可获得累计营收情况的监控项。
此外,我们还初始化了代表顾客的 Customer 工程,它目前可以接受一些命令行参数,判断是否等待店铺开门。