目录
一、Fast R-CNN如何生成候选框特征矩阵
二、 关于正负样本的解释
三、训练样本的候选框
四、Fast R-CNN网络架构
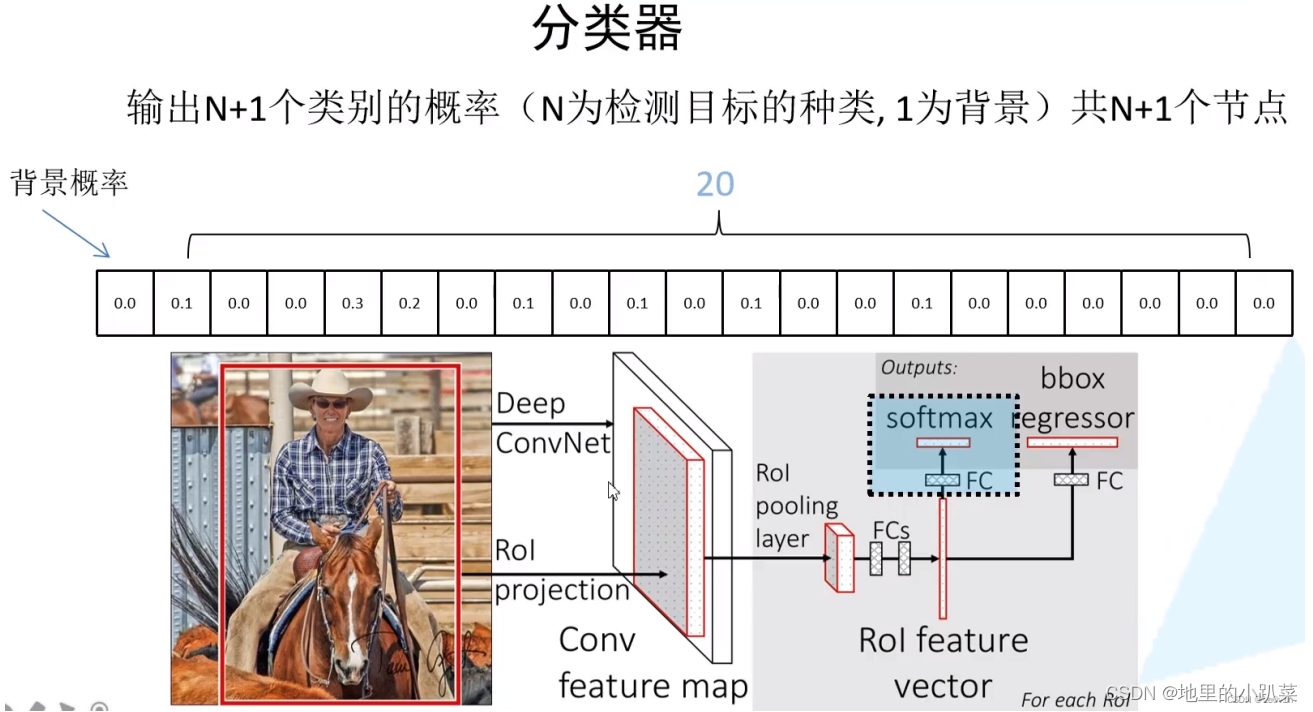
4.1 分类器
4.2 边界框回归器
一、Fast R-CNN如何生成候选框特征矩阵
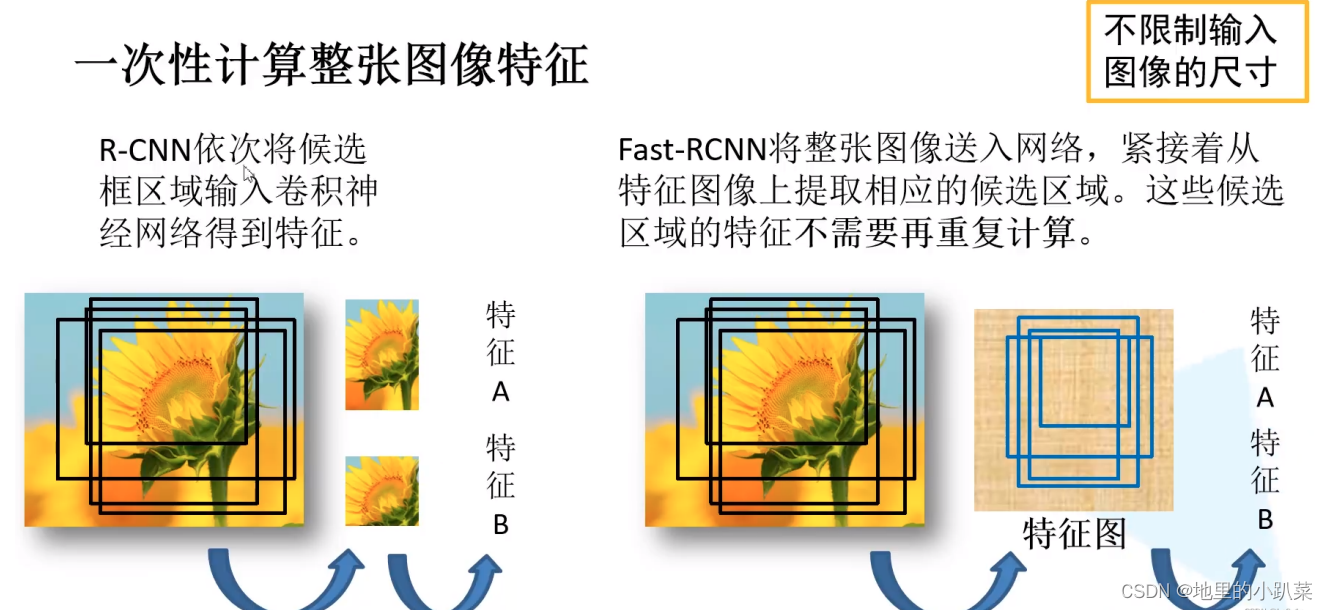
在R-CNN中,通过SS算法得到2000个候选框,则需要进行2000次正向传播 得到2000个特征 —— 很冗余 ——很多重叠部分计算计算一次就可以。
在Fast R-CNN中,直接将整张图片送入CNN得到这张图片的特征图,再根 据候选框与原图的关系映射到特征图上,就不需要重复运算了。——大幅度提 升Fast R-CNN的运算速度
二、 关于正负样本的解释
在Fast R-CNN网络训练过程中,并不会使用SS算法提供的所有候选框(SS 算法生成大约2000个候选框),只需使用一小部分的数据即可。对于采样数 据,它分为“正样本”和“负样本”。
正样本:候选框中确实存在所需检测目标(前景)的样本
负样本:候选框中没有所需检测目标(背景)的样本
为什么要将样本分为正样本和负样本呢?
假如我们要训练一个猫狗分类器,如果猫的样本数量远大于狗的样本数量 (数据不平衡),网络在预测时会更偏向于“猫”,很明显这样是不对的。如果数 据中全是“猫”的样本, 没有“狗”的样本,那么网络预测几乎一定会出现问题。
同理,在训练Fast R-CNN时,如果数据中全部都是正样本,那么网络就会 很大概率认为候选区域是所需要检测的目标(可能这个框明明框住的是背景, 但网络仍会认为这个被框住的背景是有用的,是一个前景),这时网络肯定会 出问题。所以数据要分为正样本和负样本。

在原论文中,对于每一张图片,从2000个候选框中采集64个候选框。这64 个候选框,一部分框的是正样本,一部分框的是负样本。那么正样本是如何定 义的呢?
只要候选框与真实框(GT)的IoU大于0.5,则认定为正样本,反之认定为 负样本。
三、训练样本的候选框
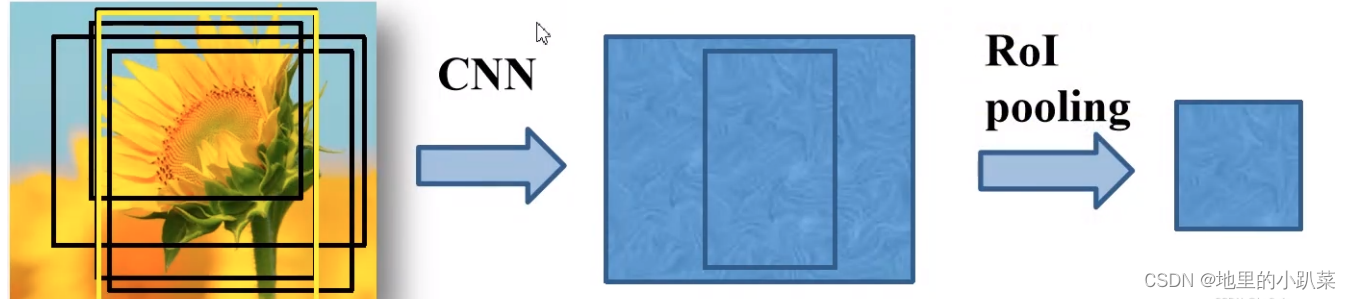
原理:
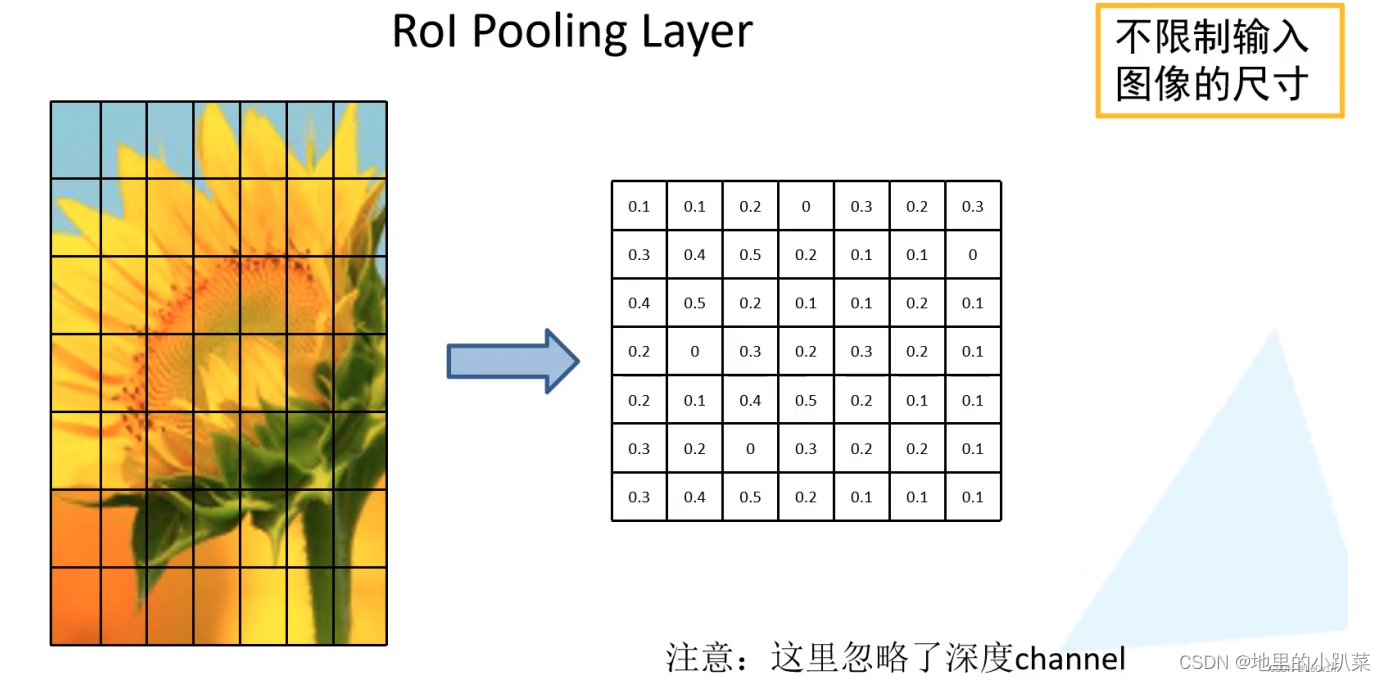
左边图其实是一个经过特征提取的特征图,本身可视化出来也是很抽象 的,这里只是为了方便理解,使用了RGB图像。
具体实现为:将特征图划分为 7×7 个小块,对其每一小块执行MaxPooling
这样处理对输入特征图的尺寸没有要求了,无论怎样都可以缩放到7×7 -> 在R-CNN中,输入图像被限定为227×227,而在Fast R-CNN中,输入图像尺寸 不再被限制。
这里忽略了Channel维度,和最大池化一样,有几个通道就做几次,最后 concat就可以了。
四、Fast R-CNN网络架构
4.1 分类器
4.2 边界框回归器
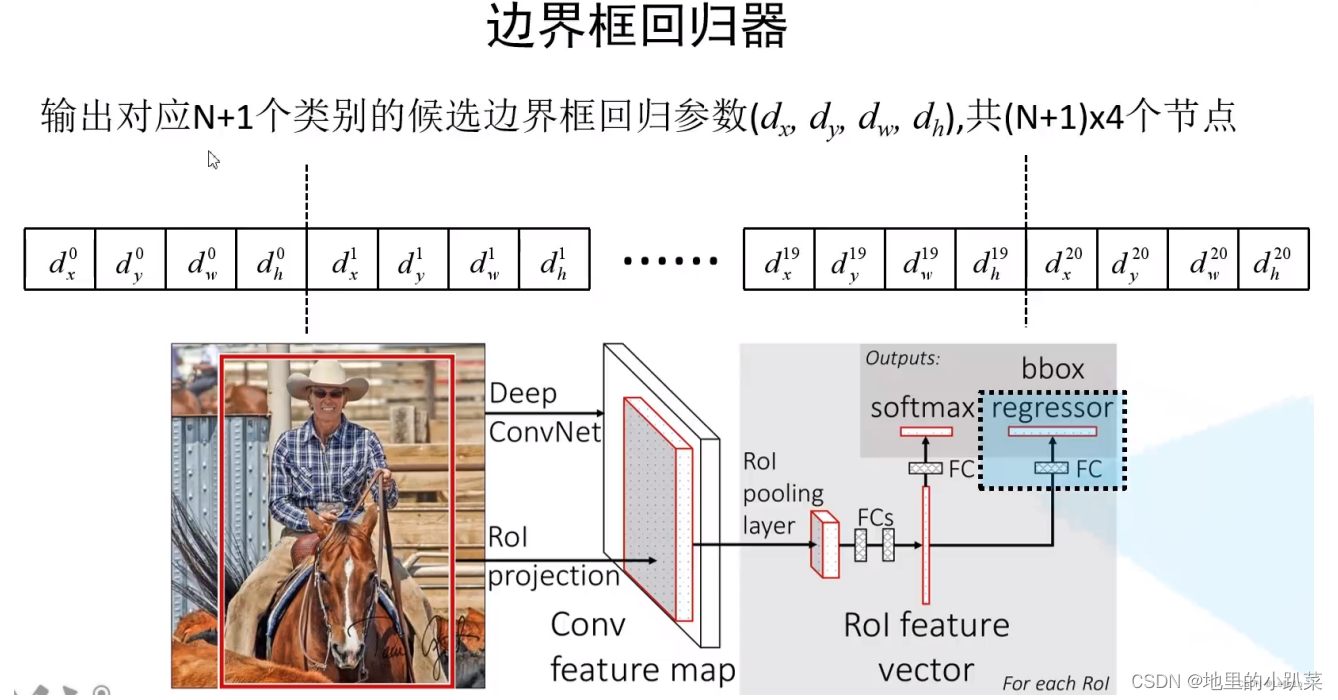

d x , d y :用 来 调 整 候 选 框 中 心 坐 标 的 回 归 参 数
d w , d h :用 来 调 整 候 选 框 宽 度 和 高 度 的 回 归 参 数