前言
大模型在处理长文本上下文任务时主要存在以下两个问题:
- 输入长度减少:RAG的方法可以减少输入长度,但这可能导致所需信息的部分丢失,影响任务解决性能。
- 扩展LLMs的上下文长度:通过微调的方式来扩展LLMs的上下文窗口,以便处理整个输入。当窗口变长时,LLMs难以集中注意力在解决任务所需的信息上,导致上下文利用效率低下。
下面来看看两个有趣的另辟蹊径的方法,使用Agent协同来处理长上下文。
Chain-of-Agents(CoA)
method

阶段一:Worker Agent
Worker Agent的目的是分段理解和链式通信。在这一阶段,长文本被分割成多个小块(chunks),每个小块由一个工作智能体处理。每个工作智能体接收以下输入:
- 输入块(Chunk): c i c_i ci,源文本 x x x的一个子集,长度不超过智能体的上下文窗口限制 k k k。
- 查询(Query): q q q,与任务相关的查询或问题。
- 特定任务的指令: I W I_W IW,指导智能体执行特定任务的指令。
- 前一个智能体传递的消息(Message passed from the previous agent): C U i − 1 CU_{i-1} CUi−1,被称为“通信单元”(Communication Unit),包含了之前智能体处理的信息。
Worker的输出是一个更新的通信单元 C U i CU_i CUi,它将被传递给下一个Worker。这个过程可以用以下公式表示:
C U i = L L M W i ( I W , C U i − 1 , c i , q ) CU_i = LLM_{W_i}(I_W, CU_{i-1}, c_i, q) CUi=LLMWi(IW,CUi−1,ci,q)
这里的LLM_{W_i}表示工作智能体 W i W_i Wi使用的LLM模型。
图的左侧强调了Worker Agent之间协作通信的必要性,以有效解决复杂的长上下文推理任务。可以观察到以下几点:1) 尽管仅给定 c 1 c_1 c1时问题无法回答, W 1 W_1 W1生成了有助于回答问题的相关证据;2) 借助前一个工作者的部分答案, W 2 W_2 W2进一步推理当前来源,以完成跨代理的完整推理链,并生成解释性推理链;3) W 3 W_3 W3在第三段文本中未发现相关信息,它直接重写了 C U 2 CU_2 CU2,将正确答案作为 C U 3 CU_3 CU3的第一个标记,而没有添加任何无关信息。这表明,如果Worker是独立的(例如树状结构通信),那么当第一个跳转的答案被另一个工作者持有时,回答第二个跳转是不可能的。
worker-agent-chain:在Chain-of-Agents(CoA)框架中,一系列工作智能体(worker agents)顺序连接并协同工作的过程。在CoA框架中,每个工作智能体负责处理长文本中的一个部分,并生成一个通信单元(Communication Unit, CU),然后将这个CU传递给链中的下一个工作智能体。这个过程形成了一个“链”,每个智能体都是这个链上的一个环节。
阶段二:Manager Agent
在第二阶段,Manager Agent负责信息整合和响应生成。在所有Manager Agent完成信息提取和理解后,Manager Agent将使用累积的知识生成最终答案。具体来说,Manager Agent体会接收最后一个Worker Agent传递的通信单元 C U l CU_l CUl,然后结合在所有Manager的指令 I M I_M IM和查询 q q q来生成最终答案 R e s p o n s e Response Response:
R e s p o n s e = L L M M ( I M , C U l , q ) Response = LLM_M(I_M, CU_l, q) Response=LLMM(IM,CUl,q)
这里的
L
L
M
M
LLM_M
LLMM表示管理者智能体
M
M
M使用的LLM模型。
使用单独的LLM作为manager worker的优点是能够将分解长上下文块和产生最终答案的职责分开。
时间复杂度分析
在解码器仅设置下,假设LLM生成的响应平均包含r个标记,输入包含n个标记,LLM的上下文限制为k。时间复杂度如下表所示:

这表明CoA在编码时间上比Full-Context方法更高效,因为k通常远小于n。两者的解码时间复杂度相同。
实验



小结:CoA利用多智能体协作处理长上下文任务。它由多个工作智能体组成,这些智能体顺序地进行通信以处理文本的不同分段部分,随后由一个Manager Agent将这些贡献综合成一个连贯的最终输出。
Qwen-Agent
能够原生处理数百万字输入的大型语言模型(LLMs)成为了一种趋势。大部分工作集中在模型架构调整,如位置编码扩展或线性注意力机制等。然而,准备足够长度的微调数据作为讨论较少但同样重要的议题,却鲜少被提及。下面主要讨论利用一个较弱的8k上下文聊天模型构建一个相对强大的智能体,能够处理1M的上下文。
构建智能体
我们构建的智能体包含三个复杂度级别,每一层都建立在前一层的基础上。
级别一:检索
处理100万字上下文的一种朴素方法是简单采用增强检索生成(RAG)。 RAG将上下文分割成较短的块,每块不超过512个字,然后仅保留最相关的块在8k字的上下文中。 挑战在于如何精准定位最相关的块。经过多次尝试,我们提出了一种基于关键词的解决方案:
- 步骤1:指导聊天模型将用户查询中的指令信息与非指令信息分开。例如,将用户查询"回答时请用2000字详尽阐述,我的问题是,自行车是什么时候发明的?请用英文回复。"转化为{“信息”: [“自行车是什么时候发明的”], “指令”: [“回答时用2000字”, “尽量详尽”, “用英文回复”]}。
- 步骤2:要求聊天模型从查询的信息部分推导出多语言关键词。例如,短语"自行车是什么时候发明的"会转换为{“关键词_英文”: [“bicycles”, “invented”, “when”], “关键词_中文”: [“自行车”, “发明”, “时间”]}。
- 步骤3:运用BM25这一传统的基于关键词的检索方法,找出与提取关键词最相关的块。

其也尝试了基于向量的检索,但在大多数情况下,它带来的改进并不显著,不足以抵消部署单独向量模型所带来的额外复杂性。
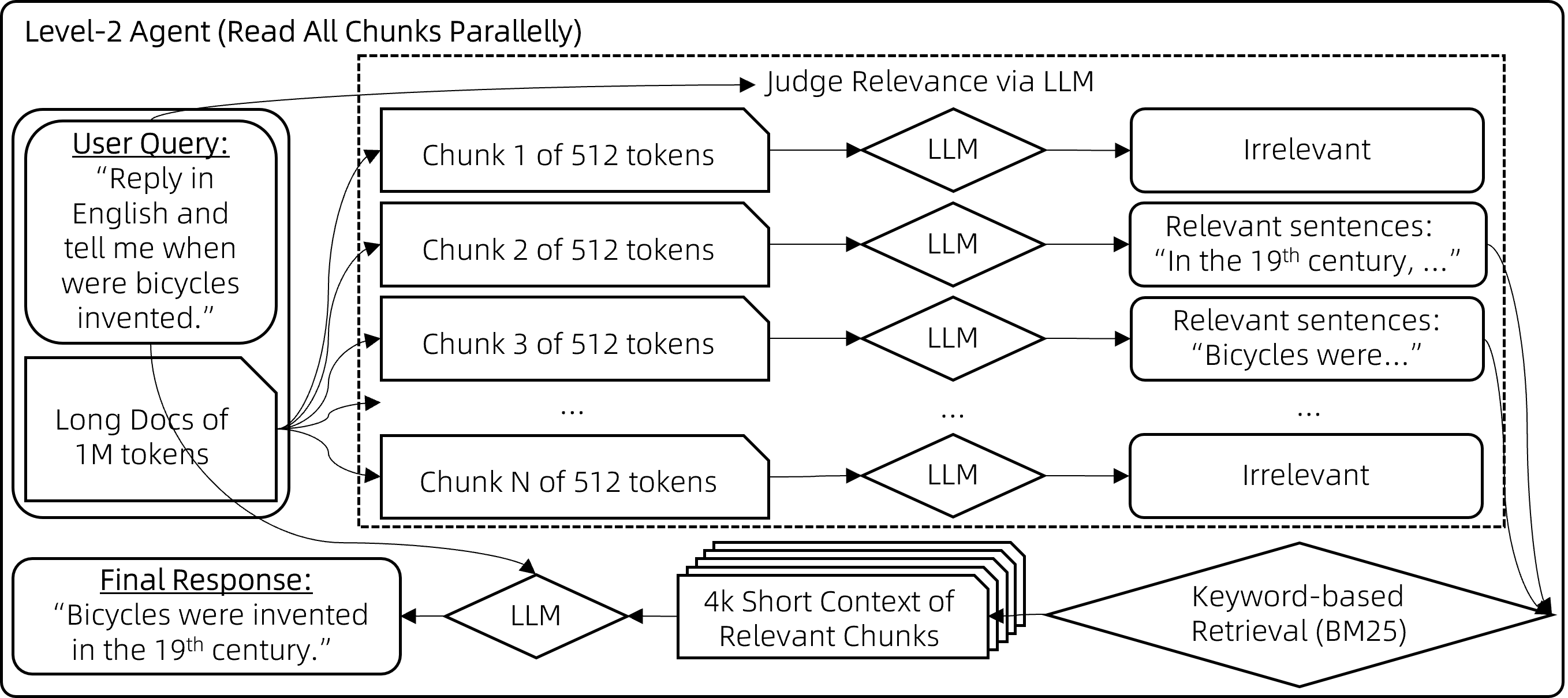
级别二:分块阅读
上述RAG方法很快速,但常在相关块与用户查询关键词重叠程度不足时失效,导致这些相关的块未被检索到、没有提供给模型。尽管理论上向量检索可以缓解这一问题,但实际上效果有限。 为了解决这个局限,我们采用了一种暴力策略来减少错过相关上下文的几率:
- 步骤1:对于每个512字块,让聊天模型评估其与用户查询的相关性,如果认为不相关则输出"无", 如果相关则输出相关句子。这些块会被并行处理以避免长时间等待。
- 步骤2:然后,取那些非"无"的输出(即相关句子),用它们作为搜索查询词,通过BM25检索出最相关的块(总的检索结果长度控制在8k上下文限制内)。
- 步骤3:最后,基于检索到的上下文生成最终答案,这一步骤的实现方式与通常的RAG相同。
级别三:逐步推理
在基于文档的问题回答中,一个典型的挑战是多跳推理。例如,考虑回答问题:“与第五交响曲创作于同一世纪的交通工具是什么?”模型首先需要确定子问题的答案,“第五交响曲是在哪个世纪创作的?”即19世纪。然后,它才可以意识到包含“自行车于19世纪发明”的信息块实际上与原始问题相关的。
工具调用(也称为函数调用)智能体或ReAct智能体是经典的解决方案,它们内置了问题分解和逐步推理的能力。因此,我们将前述级别二的智能体(Lv2-智能体)封装为一个工具,由工具调用智能体(Lv3-智能体)调用。工具调用智能体进行多跳推理的流程如下:
向Lv3-智能体提出一个问题。
while (Lv3-智能体无法根据其记忆回答问题) {
Lv3-智能体提出一个新的子问题待解答。
Lv3-智能体向Lv2-智能体提问这个子问题。
将Lv2-智能体的回应添加到Lv3-智能体的记忆中。
}
Lv3-智能体提供原始问题的最终答案。

例如,Lv3-智能体最初向Lv2-智能体提出子问题:“贝多芬的第五交响曲是在哪个世纪创作的?”收到“19世纪”的回复后,Lv3-智能体提出新的子问题:“19世纪期间发明了什么交通工具?”通过整合Lv2-智能体的所有反馈,Lv3-智能体便能够回答原始问题:“与第五交响曲创作于同一世纪的交通工具是什么?”
实验
在两个针对256k上下文设计的基准测试上进行了实验:
- NeedleBench,一个测试模型是否能在充满大量无关句子的语境中找到最相关句子的基准,类似于“大海捞针”。回答一个问题可能需要同时找到多根“针”,并进行多跳逐步推理。
- LV-Eval是一个要求同时理解众多证据片段的基准测试。我们对LV-Eval原始版本中的评估指标进行了调整,因为其匹配规则过于严苛,导致了许多假阴性结果。
比较了以下方法:
- 32k-模型:这是一个7B对话模型,主要在8k上下文样本上进行微调,并辅以少量32k上下文样本。为了扩展到256k上下文,我们采用了无需额外训练的方法,如基于RoPE的外推。
- 4k-RAG:使用与32k-模型相同的模型,但采取了Lv1-智能体的RAG策略。它仅检索并处理最相关的4k上下文。
- 4k-智能体:同样使用32k-模型的模型,但采用前文描述的更复杂的智能体策略。该智能体策略会并行处理多个片段,但每次请求模型时至多只使用模型的4k上下文。

实验结果说明了以下几点:
- 在短上下文场景中,4k-RAG的表现可能不如32k-模型。这可能是由于RAG方案难以检索到正确的信息或理解多个片段造成的。
- 相反,随着文档长度的增加,4k-RAG越发表现出超越32k-模型的趋势。这一趋势表明32k-模型在处理长上下文方面并没有训练到最优的状态。
- 值得注意的是,4k-智能体始终表现优于32k-模型和4k-RAG。它分块阅读所有上下文的方式使它能够避免原生模型在长上下文上训练不足而带来的限制。
总的来说,如果得到恰当的训练,32k-模型理应优于所有其他方案。然而,实际上由于训练不足,32k-模型的表现不及4k-智能体。
对该智能体进行了100万个字词的压力测试(在100万个字词的大海中寻找一根针),并发现它能够正常运行。然而,我们仍然缺乏一个更贴近真实使用场景的可靠基准来系统量化它在100万字词任务上的表现。
总结
本文介绍了两种处理长文本上下文任务的方法:Chain-of-Agents(CoA)和Qwen-Agent,CoA和Qwen-Agent都展示了在处理长文本上下文任务时的有效性。CoA通过多智能体协作和无需训练的特点提供了一个灵活且高效的解决方案,而Qwen-Agent通过逐步推理和分块阅读策略,使得较弱的模型也能处理超长文本。这两种方法都为大型语言模型在长文本处理方面提供了有价值的参考和启示。
参考文献
- Chain of Agents: Large Language Models Collaborating on Long-Context Tasks,https://arxiv.org/pdf/2406.02818
- https://qwenlm.github.io/zh/blog/qwen-agent-2405/