一、背景和研究意义
计算机已成为现代社会不可或缺的工具,广泛应用于个人生活、学术研究和商业领域。随着科学技术的飞速发展,计算机不仅在性能上不断突破,在种类和品牌上也呈现出多样化和差异化。无论是办公、娱乐、学习还是创作,人们都离不开电脑的帮助。然而,随着电脑市场的不断扩大和竞争的加剧,消费者在面对琳琅满目的产品时,往往需要综合考虑性能、品牌和价格等因素才能做出购买决策。价格作为购买决策中最关键的因素之一,对消费者来说尤为重要。
二、数据选择
该数据集包含数千台笔记本电脑的信息,涵盖各种品牌、型号和配置。其中包括入门级和高端笔记本电脑,满足了不同用户的需求和偏好。数据集中的每个笔记本电脑条目都提供了大量属性,如处理器详细信息、内存容量、存储空间大小、显示屏特性、图形处理能力、电池寿命、操作系统等。利用该数据集,用户可以进行探索性数据分析,发现不同笔记本电脑规格之间的有趣趋势、模式和相关性。
数据集和代码
代码和完整报告
三、数据描述
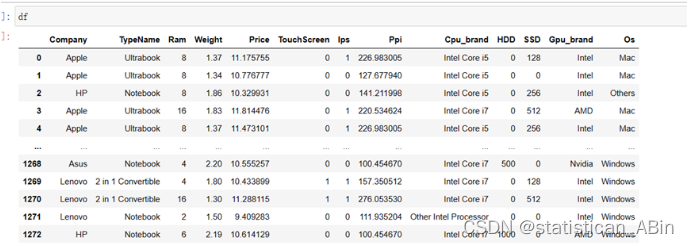
接下来查看缺失数据
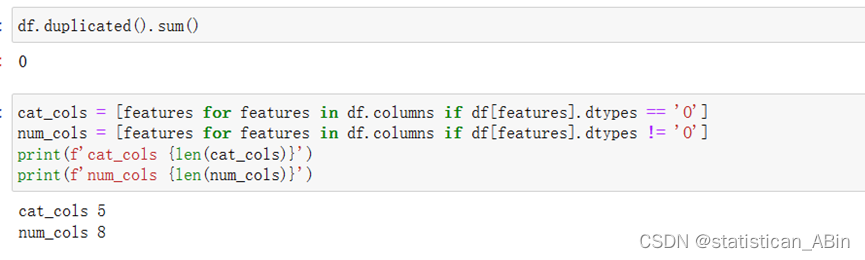
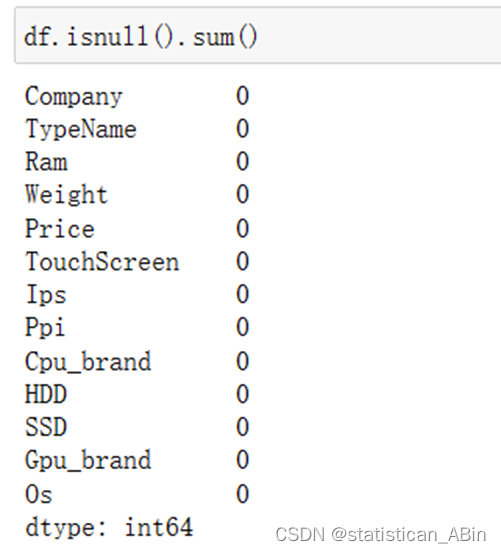
从上述结果可以看出,数据相对完整,没有缺失值。接下来,对数据的数字类型特征进行描述性统计分析:
df[num_cols].describe().T
每台笔记本电脑具有以下特征:
内存:平均内存大小约为 8.45 GB,标准差约为 5.10 GB,最小为 2 GB,最大为 64 GB。平均重量约为 2.04 kg,标准差约为 0.67 kg,最小为 0.69 kg,最大为 4.7 kg。价格平均约为 10.83,标准差约为 0.62,最小约为 9.13,最大约为 12.69。触摸屏:约 14.7%的笔记本电脑具有触摸屏功能。就触摸屏功能而言,约 14.7% 的笔记本电脑具有触摸屏功能。。。。
四、数据预处理
接下来查看数据集类型:
df[cat_cols].info()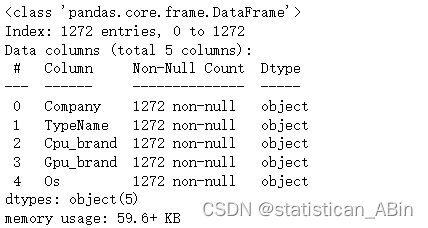
可以看到,数据类型主要包括数字类型和字符串。
接下来移除数据集中的特征单位:
五、数据分析和结果讨论
plt.subplots(nrows=2,ncols=2,figsize = (25,12))
plt.subplot(2,2,1)
ax = sns.histplot(data=df[num_cols]['Price'],kde=True,color='g')
for i in ax.containers:
ax.bar_label(i)
plt.title('Price Distribution')
plt.subplot(2,2,2)
ax = sns.histplot(data=df[num_cols]['Ppi'],kde=True,color='y')
for i in ax.containers:
ax.bar_label(i)
plt.subplot(2,2,3)
sns.histplot(data=df[num_cols]['Ram'],kde=True)
plt.subplot(2,2,4)
ax = sns.histplot(data=df[num_cols]['Weight'],kde=True,color='b')
for i in ax.containers:
ax.bar_label(i)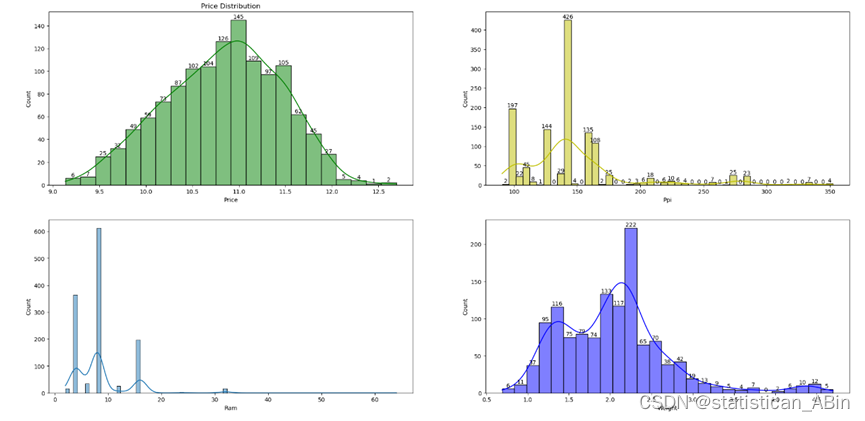
从图中可以看出,在价格分布方面,整体呈现正态分布,其中价格最高的为 11,从ppi 的分布也可以看出,分布较为分散,其中频率最高的为 145
plt.subplots(nrows=1,ncols=2,figsize = (20,7))
plt.subplot(1,2,1)
ax = sns.histplot(data=df,x=df['Price'],color='g',hue='Company',kde=True)
plt.title('campanies')
plt.xticks(rotation = 'vertical')
plt.subplot(1,2,2)
sns.histplot(data=df,x=df['Price'],kde=True,hue=df['TypeName'])
plt.title('TypeName',)
plt.xticks(rotation = 'vertical')
print(f'{df["Company"].value_counts().head(1)}')
print('')
print(f'{df["TypeName"].value_counts().head(1)}')
print('')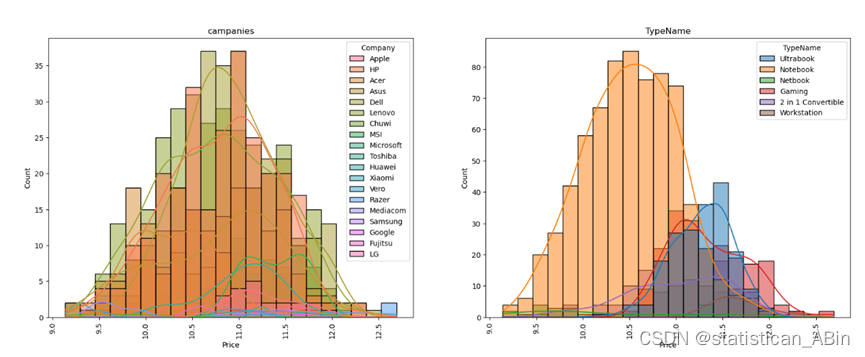
从图中我们可以清晰地看到,左边展示的是电脑公司品牌的分布情况。通过柱状图的呈现,我们可以明显地观察到宏碁和联想这两个品牌的分布较为广泛。这意味着在市场中,宏碁和联想的产品较为常见,受到了较多消费者的青睐。。。。
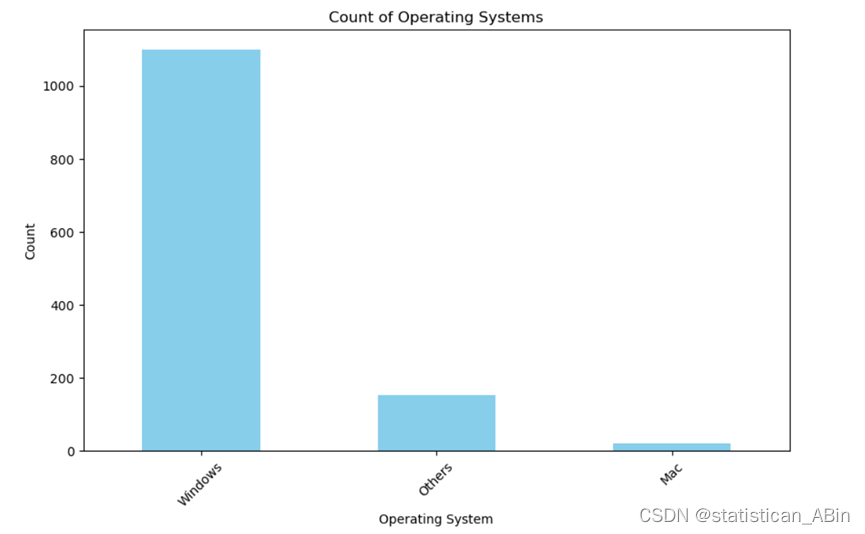 该图清晰地呈现了系统在各类电脑上的分布状况。通过仔细观察,可以发现 Windows 系统的分布最为广泛,其总数超过了 1000 个。这表明 Windows 系统在电脑市场中占据着主导地位,被广泛应用于各种类型的电脑设备中。紧随其后的是其他系统,它们在电脑上的分布也较为可观。
该图清晰地呈现了系统在各类电脑上的分布状况。通过仔细观察,可以发现 Windows 系统的分布最为广泛,其总数超过了 1000 个。这表明 Windows 系统在电脑市场中占据着主导地位,被广泛应用于各种类型的电脑设备中。紧随其后的是其他系统,它们在电脑上的分布也较为可观。
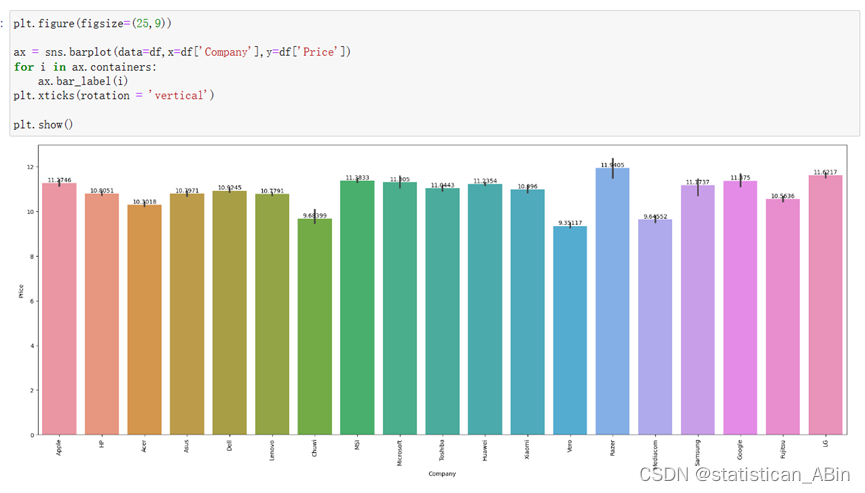
通过对图中不同公司价格分布的仔细观察和分析,我们可以发现这些公司之间的价格差距实际上并不是特别明显。其中,Razer 公司的价格分布呈现出相对较高的水平,达到了 11.94。这表明 Razer 公司的产品在市场上可能被定位为高端或具有特定竞争优势的品牌。。。。
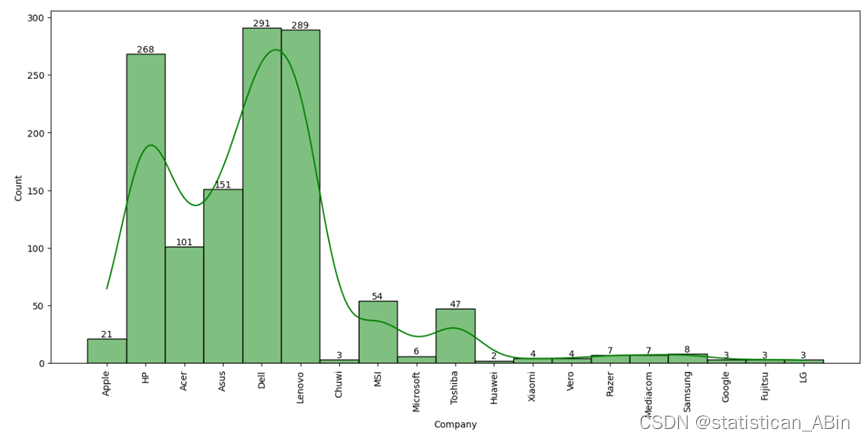
从图表中可以清晰地看出,戴尔、联想和惠普这三家公司的分布范围最为广泛。它们在市场上的占有率相对较高,产品覆盖面较广
接下来,让我们一起看看数值数据的相关系数热图。
plt.figure(figsize=(15,6))
sns.heatmap(data=df[num_cols].corr(),annot=True)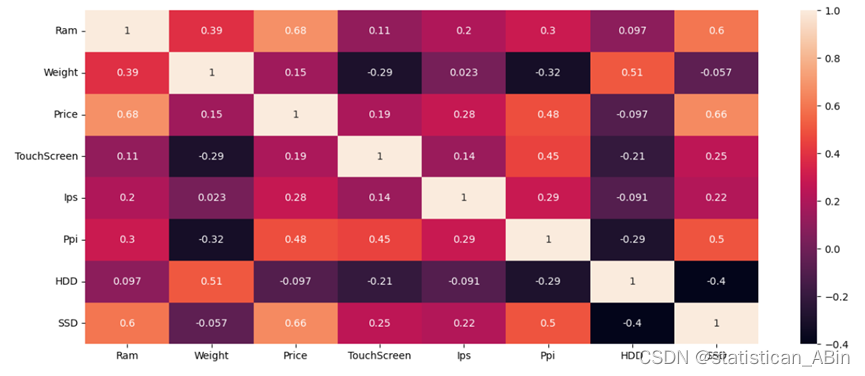 从热图中我们可以清晰地看到,拉姆与 Ppi 以及怀特的相关系数均达到了 0.3。这意味着它们之间存在着一定程度的正相关关系。同时,价格预测 Ppi 的相关系数为 0.48,这表明 Ppi 对价格预测具有一定的影响力。。。
从热图中我们可以清晰地看到,拉姆与 Ppi 以及怀特的相关系数均达到了 0.3。这意味着它们之间存在着一定程度的正相关关系。同时,价格预测 Ppi 的相关系数为 0.48,这表明 Ppi 对价格预测具有一定的影响力。。。
接下来是机器学习
对非数字数据进行唯一热编码,然后按 8:2 的比例分成训练集和测试集
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 划分特征和目标变量
X = df_encoded
y = df['Price']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
print("均方误差 (MSE):", mse)
# 训练随机森林回归模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# 预测
y_pred_rf = rf_model.predict(X_test)
# 评估模型
mse_rf = mean_squared_error(y_test, y_pred_rf)
print("随机森林模型均方误差 (MSE):", mse_rf)# 模型名称
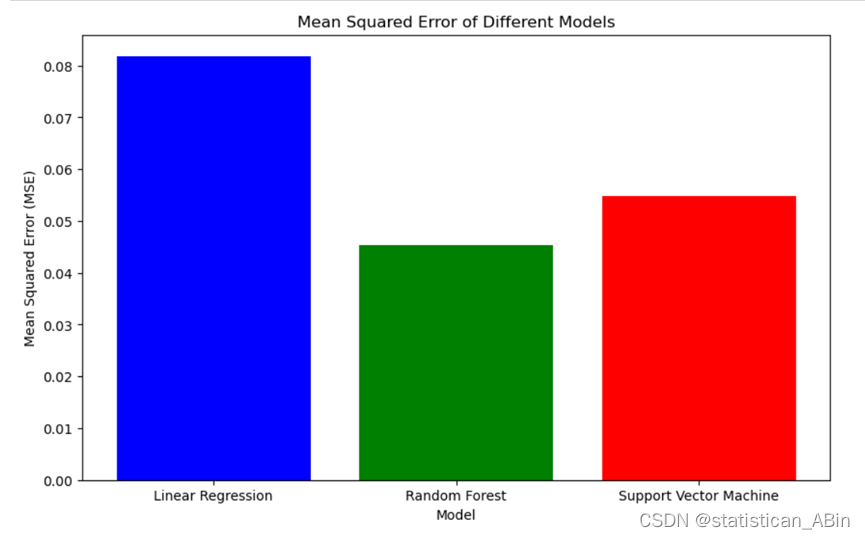
models = ['Linear Regression', 'Random Forest', 'Support Vector Machine']
# 模型均方误差值
mse_values = [0.0818452452933915, 0.04533960518967475, 0.05473241603725401]
# 绘制直方图
plt.figure(figsize=(10, 6))
plt.bar(models, mse_values, color=['blue', 'green', 'red'])
plt.xlabel('Model')
plt.ylabel('Mean Squared Error (MSE)')
plt.title('Mean Squared Error of Different Models')
plt.show()
六、结论
本研究通过对笔记本电脑数据集的分析,旨在探讨笔记本电脑的内存和价格之间的关系,并利用机器学习算法进行价格预测。研究结果表明,内存和价格之间存在一定的相关性,并且通过机器学习算法可以较为准确地预测笔记本电脑的价格。。。。
参考文献
[1] Gu Xiaojun. Research on price prediction model based on improved KNN algorithm[J]. Computer Knowledge and Technology,2010,6(33):9463-9465.
[2] Feng Kepeng.Research and improvement of KNN price prediction model[J]. Software Guide,2010,9(10):84-86.
创作不易,希望大家多点赞关注评论!!!