欢迎关注微信公众号:互联网全栈架构
分布式缓存可能是Redis最常见的应用场景了。缓存里的热点数据一般来自于关系型数据库,这样的话,就会存在缓存与数据库的数据一致性问题。
当然,这种数据不一致性主要是针对写操作来说的,如果仅仅是读取操作,因为数据在两边都没有变化,不存在不一致的情况。
一
读取缓存
读取Redis中的数据时,它的操作步骤如下:
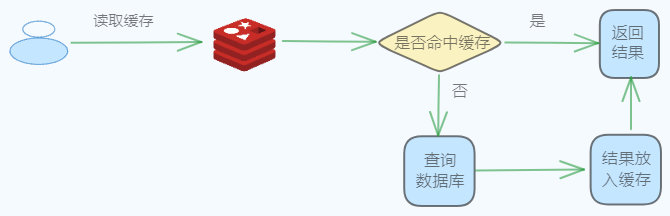
数据读取的流程比较简单,客户端请求首先访问缓存,如果缓存中有对应的key,则直接返回结果,如果没有,则需要查询数据库,并且把查询结果放入缓存,然后返回查询结果即可。
二
更新的步骤
数据一致性问题主要是指数据更新的场景,因为数据有改变,那么缓存和数据库中的数据就有可能存在不一致的情况。
数据更新的操作可以分为两类:是更新缓存还是删除缓存?先操作数据库还是先操作缓存?这两类操作组合起来可以细分为如下四种情况:
先更新缓存,再更新数据库;
先更新数据库,再更新缓存;
先删除缓存,再更新数据库;
先更新数据库,再删除缓存。
与删除缓存相比,更新缓存的操作更为复杂,成本也更高,很多时候,缓存里面的数据可能来自于多张表,比如商品的价格,可能关联了商品表、价格表等,并且经过了一系列的计算操作,所以一般情况下都是删除缓存而不是更新缓存,下次访问数据库的时候,把最新的数据计算好放入缓存即可。
三
先删缓存,再更新数据库
这样的话,前面两种情况暂时不考虑,我们来看看第三种情况,也就是先删除缓存,再更新数据库:
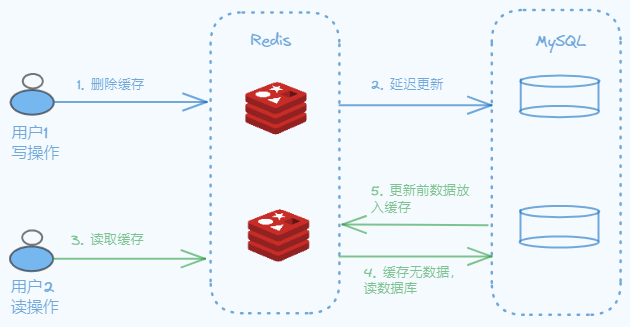
如上图所示,如果存在读写并发的情况,如果先删除缓存后更新数据库,也会存在数据不一致的情况,我们来看看具体的操作步骤:
第一步:用户1先删除缓存,并操作成功;
第二步:用户1接下来更新数据库,但由于网络延迟或者系统故障,导致数据库更新没有及时完成;
第三步:用户2开始读取缓存中的内容;
第四步:由于用户1已经删除缓存,所以读取数据库的内容;
第五步:由于第二步的延迟更新,导致读取的数据库内容为更新前的数据,而当用户1的操作最终更新了数据库,这就使得数据库和缓存的内容不一致了。
可以看出,这样的方式还是会导致数据的不一致性。针对这样的问题,可以考虑通过延迟双删的方式来解决,就是先删除缓存,再更新数据库,然后再次删除缓存,从而避免第五步带来的数据不一致性。试想一下,如果不再次进行删除的话,缓存里面的数据就永远是旧的(除非到了过期时间)。伪代码:
redis.del(key);
mysql.update(data);
Thread.sleep(500); # 具体的延迟时间视业务场景而定
redis.del(key);当然,在第二次删除缓存之前,如果有访问缓存的操作,这时候读到的数据依然还是旧的。
四
先更新数据库,再删缓存
接下来我们看看先更新数据库,再删除缓存的情况:

同样,如果存在读写并发的情况,先更新数据库再删除缓存,也会存在数据不一致的情况:
第一步:用户1更新数据库,操作成功;
第二步:用户1接下来删除缓存,但由于网络或者系统原因,操作存在延迟;
第三步:用户2读取缓存中的内容,由于缓存还没有删除成功,里面保存的依然是旧的数据,所以导致数据的不一致性。
五
总结
引入Redis作为分布式缓存,就会存在数据的不一致性问题,也就是Redis中的热点数据与关系型数据库的数据不一致。这种不一致性主要是针对写操作来说的,对于读操作是不存在的。
而解决这种不一致问题,主要的分歧在于先更新数据库还是先删除缓存,不论是哪种方式,在极端情况下都会存在不一致性的问题,而且删除缓存的操作也可能会失败,这时候可以引入消息队列的方式,异步进行重试删除的操作。
另外,对于这种不一致性问题,也可以考虑采用Canal中间件来解决,它监听MySQL中的数据变化,并把这种变化更新到缓存中,通过这样的方式也可以解决不一致问题,关于Canal的介绍,请参见之前的文章:数据同步的利器:Canal
创作不易,烦请点个在看、点个赞。
有任何问题,也欢迎留言讨论。
推荐阅读:
吃透Redis系列:对过期数据挥刀问斩
吃透Redis系列:总体介绍