阿丹:
之前有同学反应分享的东西有点概念化,表示不看着代码无法更深刻能理解。那么今天直接上代码!!!
有两种方式使用自己训练好的nlu
1、rasa与nul分开启动,就是在rasa中的配置中配置好目标对应的nlu的服务器,然后使用rasa和nlu分开启动。(下文为启动方式1)
2、使用已经训练好的rasa组件,从别人那里获取来直接一整个整体启动(下文为启动方式2)
rasa官网中推荐的博客文章-启动方式1
用Rasa NLU构建自己的中文NLU系统
训练中文模型-启动方式1
语料获取以及预先预处理
使用的解决方案是MITIE模型,我们需要一个规模比较大的中文语料。
下面的这个网址是一个解决方案的git项目:
GitHub - crownpku/Awesome-Chinese-NLP: A curated list of resources for Chinese NLP 中文自然语言处理相关资料
这个项目中包含了很多例子等,可以保证在需要的时候快速的构建起来库。
下载jieba分词器-启动方式1:
获取一些初级的语料作为训练基础,让模型开始初步理解中文。
下载安装jieba:
pip install jieba下载基础中文语料-启动方式1:
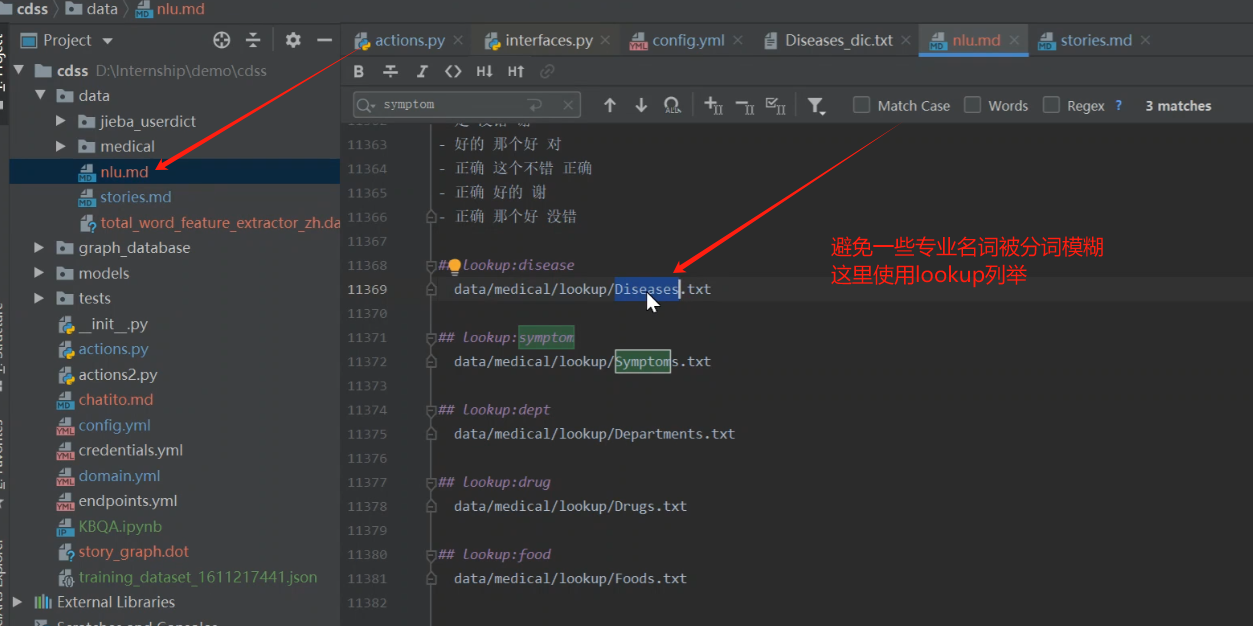
需要自己从社区获取,以及一些专业的名词来完成这个举动。
将一个语料文件分词,以空格为分隔符:
python -m jieba -d " " ./test > ./test_cut语句解释(根据自己的实际情况修改文件名字):
这个命令行语句是在使用Python的jieba分词库对一个名为test的文件进行中文分词处理,并将处理结果输出到另一个名为test_cut的文件中。具体来说,各部分含义如下:
-
python -m jieba: 这部分是通过Python的-m选项来调用jieba模块(一个常用的中文分词库)作为脚本运行。 -
-d " ": 这是一个参数,传递给jieba分词器,指定分隔符为一个空格。这意味着在分词结果中,每个词语之间将由一个空格隔开。 -
./test: 这是指定的输入文件路径,即jieba将会读取这个文件中的文本内容进行分词处理。 -
> ./test_cut: 这是Unix/Linux shell中的重定向操作符,它表示将前面命令的输出结果不是打印到屏幕上,而是写入到./test_cut这个文件中。换句话说,jieba处理test文件产生的分词结果会被保存到test_cut文件里。
综上所述,该命令的功能是读取test文件中的文本,使用jieba进行分词处理(词语间以空格分隔),并将分词后的结果保存到test_cut文件中。
MITIE模型训练-启动方式1
我们把所有分好词的语料文件放在同一个文件路径下。接下来我们要训练MITIE模型。
首先将MITIE clone下来:
git clone https://github.com/mit-nlp/MITIE.git我们要使用的只是MITIE其中wordrep这一个工具。我们先build它。
cd MITIE/tools/wordrepmkdir buildcd build
cmake ..cmake --build . --config Release然后训练模型,得到total_word_feature_extractor.dat。注意这一步训练会耗费几十GB的内存,大概需要两到三天的时间
./wordrep -e /path/to/your/folder_of_cutted_text_files因为需要很长时间,这里我就直接使用别人使用中文wikipedia和百度百科语料生成 的文件
大家需要的话直接自取就可以了。
链接:https://pan.baidu.com/s/1teZYgkkTPB-WNb6gy9ghZw?pwd=0iza
提取码:0izatotal_word_feature_extractor.dat
构建rasa_nlu语料和模型-启动方式1
将rasa_nlu_chi clone下来并安装:
git clone https://github.com/crownpku/rasa_nlu_chi.gitcd rasa_nlu_chipython setup.py install构建尽可能多的示例数据来做意图识别和实体识别的训练数据:
data/examples/rasa/demo-rasa_zh.json
格式是json,例子如下。’start’和’end’是实体对应在’text’中的起止index。
{
"text": "找个吃拉面的店",
"intent": "restaurant_search",
"entities": [
{
"start": 3,
"end": 5,
"value": "拉面",
"entity": "food"
}
]
},
{
"text": "这附近哪里有吃麻辣烫的地方",
"intent": "restaurant_search",
"entities": [
{
"start": 7,
"end": 10,
"value": "麻辣烫",
"entity": "food"
}
]
},
{
"text": "附近有什么好吃的地方吗",
"intent": "restaurant_search",
"entities": []
},
{
"text": "肚子饿了,推荐一家吃放的地儿呗",
"intent": "restaurant_search",
"entities": []
}
使用MitieNLP作为预训练的中文模型 -方式2

完整config.yml的配置文件-方式2
# 指定模型架构的方案,这里使用默认版本v1
recipe: default.v1
# 助手唯一标识符,需要替换为实际部署中唯一的助手名称
assistant_id: placeholder_default
# 配置Rasa NLU部分,指定使用的自然语言
language: zh
# Rasa NLU管道组件配置
pipeline:
- name: "MitieNLP" # 使用MITIE进行自然语言处理,需要预先训练好的模型文件
model: "data/total_word_feature_extractor_zh.dat" # MITIE模型路径
- name: "JiebaTokenizer" # 使用jieba进行中文分词
# dictionary_path: "data/jieba_userdict" # 可选,自定义词典路径,用于增强jieba的分词理解,默认不启用
- name: "MitieEntityExtractor" # 使用MITIE进行实体提取
epochs: 100 # 实体提取器训练轮数
- name: "EntitySynonymMapper" # 映射实体别名
epochs: 50 # 同样
- name: "RegexFeaturizer" # 使用正则表达式特征化器增强特征
- name: "MittieFeaturizer" # 注意拼写错误,应为"MitieFeaturizer",使用MITIE生成特征
- name: "DIETClassifier" # 使用DIET分类器进行意图识别和实体抽取
epochs: 10 # 训练轮数
# Configuration for Rasa Core.
# https://rasa.com/docs/rasa/core/policies/
#对话管理
- # Rasa Core(对话管理)策略配置
policies:
- name: "TEDPolicy" # TED (Transformer Embedding Dialogue) Policy,利用Transformer网络提高对话管理性能
max_history: 5 # 对话历史的最大轮数,用于构建对话上下文的序列
epochs: 10 # 训练轮数
batch_size: 64 # 批量大小
embedding_dimension: 256 # 词嵌入维度
# 其他可选参数如dropout rates, learning rate等可以根据需求调整
- name: "MemoizationPolicy" # 记忆策略,用于直接记住并重用之前成功的对话路径
max_history: 10 # 决定了记忆的对话深度
- name: "RulePolicy" # 规则策略,允许直接编写规则来指导对话流程
# rule_persistence: "policies/rules.yml" # 规则文件位置,如果需要从外部文件加载规则
- name: "FallbackPolicy" # 回退策略,当系统不确定如何响应时触发特定动作
nlu_threshold: 0.4 # NLU部分的置信度阈值
core_threshold: 0.3 # 核心对话管理部分的置信度阈值
fallback_action_name: 'action_default_fallback' # 回退时执行的动作名称
- name: "MappingPolicy" # 映射策略,直接将特定的用户输入映射到动作
#KerasPolicy已经有更先进的配置组件来完成这个需求
# - name: "KerasPolicy"
# epochs: 120
# featurizer:
# - name: MaxHistoryTrackerFeaturizer
# max_history: 5
# state_featurizer:
# - name: BinarySingleStateFeaturizer
# - name: "rasa.core.policies.memoization.MemoizationPolicy"
# max_history: 10
# - name: "rasa.core.policies.mapping_policy.MappingPolicy"
# - name: "rasa.core.policies.fallback.FallbackPolicy"
# nlu_threshold: 0.4
# core_threshold: 0.3
# fallback_action_name: 'action_donknow'
定义配置文件中的 action_default_fallback
在Rasa中,action_default_fallback是一个预设的回退动作,当所有其他策略都无法确定一个合适的回复时,系统会调用此动作。这个动作通常用于处理未能理解用户意图或实体的情况,你可以自定义它的行为,比如提示用户重新表述问题、提供帮助信息,或者转接到人工客服。
要在Rasa项目中实现action_default_fallback,你需要做两件事:、
定义Action
首先,在actions文件夹下创建或编辑一个Python文件,比如actions.py,然后定义一个名为action_default_fallback的函数。这个函数应该接受一个参数dispatcher(用于发送消息给用户),以及可选的tracker(跟踪对话状态)和domain(定义了所有可能的行动和实体)。下面是一个简单的示例:
from typing import Any, Text, Dict, List
from rasa_sdk import Action, Tracker
from rasa_sdk.executor import CollectingDispatcher
class ActionDefaultFallback(Action):
def name(self) -> Text:
return "action_default_fallback"
def run(self, dispatcher: CollectingDispatcher,
tracker: Tracker,
domain: Dict[Text, Any]) -> List[Dict[Text, Any]]:
# 定义当触发回退时要发送给用户的回复消息
message = "对不起,我没有理解你的意思。请尝试用另一种方式告诉我你的问题或需求。"
# 使用dispatcher发送消息给用户
dispatcher.utter_message(text=message)
return []注册Action
确保你的自定义Action在Rasa配置文件(通常是endpoints.yml)中被注册。如果你使用的是Rasa SDK开发动作,且你的Action位于默认的actions模块中,通常不需要额外配置,因为Rasa默认会寻找这个文件。但是,如果你的动作位于不同的路径或模块中,你可能需要在endpoints.yml中指定actions端点:
actions:
- endpoint:
url: "http://localhost:5055/webhook"
# 如果你的actions.py在默认位置,这一段通常不需要整个配置文件中我都写好了对应的解释注释,注意在使用的时候需要安装对应的组件,
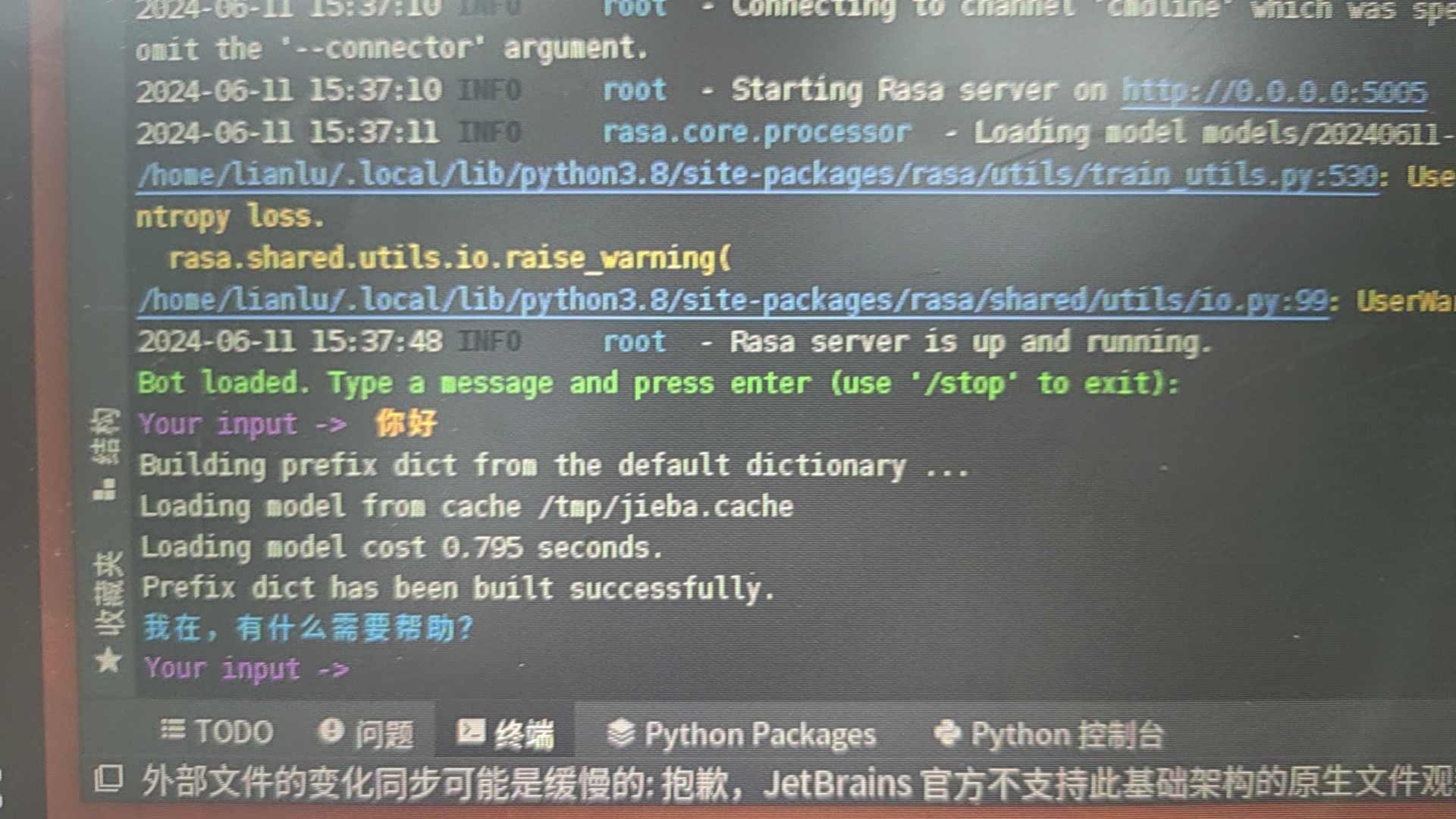
然后我们在domain中尝试使用一些中文并归类意图。
要注意在rasa 3.0以上的时候兜底的
FallbackPolicy已经被舍弃了。只需要使用最基础的兜底action来完成就OK了。
接下来使用rasa train来训练,训练之后运行就OK了。