电池的故障预测和健康管理PHM是为了保障设备或系统的稳定运行,提供参考的电池健康管理信息,从而提醒决策者及时更换电源设备。不难发现,PHM的核心问题就是确定电池的健康状态,并预测电池剩余使用寿命。但是锂电池的退化过程影响因素众多,不仅受其本身工作模式的影响,外部环境的压力、温度等都会影响锂电池的退化。这些影响因素之间的相互耦合,导致锂电池的退化表现出很强的非线性及不确定性,这给SOH估计和RUL预测带来了很大的困难。
该项目代码较简单,主要包括Capacity predict,RUL predict,Trends predic,以Capacity predict为例,首先加载模块。
import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Ffrom torch.utils.data import DataLoader, TensorDataset
import pandas as pdimport numpy as npimport osimport matplotlib.pyplot as pltimport warningswarnings.filterwarnings("ignore")device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")Debug = False
模型定义
# 定义LSTM模型class LSTMModel(nn.Module):def __init__(self, conv_input, input_size, hidden_size, num_layers, output_size):super(LSTMModel, self).__init__()self.conv=nn.Conv1d(conv_input,conv_input,1)self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, bidirectional=True).to(device)#self.fc1 = nn.Linear(hidden_size*2, hidden_size*2)self.fc = nn.Linear(hidden_size, output_size)self.num_layers = num_layersself.hidden_dim = hidden_sizeself.dropout = nn.Dropout(p=0.3)def forward(self, x):x=self.conv(x)h0 = torch.randn((self.num_layers, x.shape[0], self.hidden_dim)).to(device) # 初始化隐藏状态c0 = torch.randn((self.num_layers, x.shape[0], self.hidden_dim)).to(device) # 初始化细胞状态output, _ = self.lstm(x,(h0,c0))output = self.dropout(output)output = self.fc(output[:, -1, :])return output
导入数据
# 创建一个空列表来存储读取的 DataFramesdataframes_Cap = []dataframes_EIS = []# 使用循环读取文件并分配名称for i in range(1, 9):# 构建文件名file_name_cap= f"Capacity_data/Data_Capacity_25C{i:02}.txt"file_name_EIS = f"EIS_data/EIS_state_V_25C{i:02}.txt" # 使用状态Vif not os.path.isfile(file_name_cap):print(f"Cap文件 {file_name_cap} 不存在,跳过...")continueelif not os.path.isfile(file_name_EIS):print(f"EIS文件 {file_name_EIS} 不存在,跳过...")continue# 读取文件并添加到列表df_cap = pd.read_csv(file_name_cap, sep="\t")df_EIS = pd.read_csv(file_name_EIS, sep="\t")#print(df_cap.columns)if i == 1 or i==5:cap_number = 3else:cap_number = 5#剔除表现不佳的电池if i == 4 or i == 8:continuecycle = []cap = []eis = []cycle_max = df_cap[df_cap.columns[1]].max()cycle_max2 = df_EIS[df_EIS.columns[1]].max()cycle_number = min(cycle_max,cycle_max2)max_scale = df_cap[df_cap[df_cap.columns[1]]==0][df_cap.columns[cap_number]][:].max()for i in range(1,int(cycle_number)+1):temp = df_cap[df_cap[df_cap.columns[1]]==i][df_cap.columns[cap_number]][-1:].max()temp_EIS_Re = np.array(df_EIS[df_EIS[df_EIS.columns[1]]==i][df_EIS.columns[3]][:])temp_EIS_Im = np.array(df_EIS[df_EIS[df_EIS.columns[1]]==i][df_EIS.columns[4]][:])cycle.append(i)cap.append(temp)eis.append(np.concatenate((temp_EIS_Re, temp_EIS_Im), axis=0))dataframes_Cap.append(cap)dataframes_EIS.append(eis)
#将35数据读入# 使用循环读取文件并分配名称for i in range(1, 3):# 构建文件名file_name_cap= f"Capacity_data/Data_Capacity_35C{i:02}.txt"file_name_EIS = f"EIS_data/EIS_state_V_35C{i:02}.txt" # 使用状态Vif not os.path.isfile(file_name_cap):print(f"Cap文件 {file_name_cap} 不存在,跳过...")continueelif not os.path.isfile(file_name_EIS):print(f"EIS文件 {file_name_EIS} 不存在,跳过...")continue# 读取文件并添加到列表df_cap = pd.read_csv(file_name_cap, sep="\t")df_EIS = pd.read_csv(file_name_EIS, sep="\t")cap_number = 3cycle = []cap = []eis = []cycle_max = df_cap[df_cap.columns[1]].max()cycle_max2 = df_EIS[df_EIS.columns[1]].max()cycle_number = min(cycle_max,cycle_max2)#max_scale = df_cap[df_cap[df_cap.columns[1]]==1][df_cap.columns[cap_number]][-1:].max()for i in range(1,int(cycle_number)+1):temp = df_cap[df_cap[df_cap.columns[1]]==i][df_cap.columns[cap_number]][-1:].max()temp_EIS_Re = np.array(df_EIS[df_EIS[df_EIS.columns[1]]==i][df_EIS.columns[3]][:])temp_EIS_Im = np.array(df_EIS[df_EIS[df_EIS.columns[1]]==i][df_EIS.columns[4]][:])#temp = temp/max_scalecycle.append(i)cap.append(temp)eis.append(np.concatenate((temp_EIS_Re, temp_EIS_Im), axis=0))dataframes_Cap.append(cap)dataframes_EIS.append(eis)
#将45数据读入for i in range(1, 3):# 构建文件名file_name_cap= f"Capacity_data/Data_Capacity_45C{i:02}.txt"file_name_EIS = f"EIS_data/EIS_state_V_45C{i:02}.txt" # 使用状态Vif not os.path.isfile(file_name_cap):print(f"Cap文件 {file_name_cap} 不存在,跳过...")continueelif not os.path.isfile(file_name_EIS):print(f"EIS文件 {file_name_EIS} 不存在,跳过...")continue# 读取文件并添加到列表df_cap = pd.read_csv(file_name_cap, sep="\t")df_EIS = pd.read_csv(file_name_EIS, sep="\t")#print(df_cap.columns)cap_number = 3cycle = []cap = []eis = []cycle_max = df_cap[df_cap.columns[1]].max()cycle_max2 = df_EIS[df_EIS.columns[1]].max()cycle_number = min(cycle_max,cycle_max2)#max_scale = df_cap[df_cap[df_cap.columns[1]]==1][df_cap.columns[cap_number]][-1:].max()for i in range(1,int(cycle_number)+1):temp = df_cap[df_cap[df_cap.columns[1]]==i][df_cap.columns[cap_number]][-1:].max()temp_EIS_Re = np.array(df_EIS[df_EIS[df_EIS.columns[1]]==i][df_EIS.columns[3]][:])temp_EIS_Im = np.array(df_EIS[df_EIS[df_EIS.columns[1]]==i][df_EIS.columns[4]][:])#temp = temp/max_scalecycle.append(i)cap.append(temp)eis.append(np.concatenate((temp_EIS_Re, temp_EIS_Im), axis=0))dataframes_Cap.append(cap)dataframes_EIS.append(eis)
X = []y = []for i in range(0,len(dataframes_Cap)):for j in range(len(dataframes_Cap[i])):X.append(dataframes_EIS[i][j])y.append(dataframes_Cap[i][j])X = np.array(X)y = np.array(y)print(X.shape,y.shape)
# 将EIS的每个实部和每个虚部分别各自归一化remax = []immax = []data={}from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()y = y.reshape(-1,1)# 对标签也进行归一化y = scaler.fit_transform(y)# 将每份电池单独制作,便于交叉训练和验证,start = 0for i in range(len(dataframes_Cap)):feature_name = f'EIS{i+1:02}'target_name = f'Cap{i+1:02}'n = len(dataframes_Cap[i])X_r = X[start:start+n,:60].copy()#将实部整体进行归一化X_r_flat = X_r.flatten()#取第一个EIS的最大最小值进行归一X_r_min = X_r_flat[:60].min()X_r_max = X_r_flat[:60].max()remax.append(X_r_flat[:].max()/X_r_max)normalized_Xr_flat = ((X_r_flat.reshape(-1, 1))-X_r_min)/(X_r_max-X_r_min)normalized_Xr_data = normalized_Xr_flat.reshape(X[start:start+n,:60].shape)#将虚部进行归一化X_i = X[start:start+n,60:]X_i_flat = X_i.flatten()X_i_min = X_i_flat[:60].min()X_i_max = X_i_flat[:60].max()immax.append(X_i_flat[:].max()/X_i_max)normalized_Xi_flat = ((X_i_flat.reshape(-1, 1))-X_i_min)/(X_i_max-X_i_min)normalized_Xi_data = normalized_Xi_flat.reshape(X[start:start+n,60:].shape)data[feature_name] = np.concatenate((normalized_Xr_data, normalized_Xi_data), axis=1)data[feature_name] = data[feature_name].reshape(-1,2, 60)#将数据形式转换为(batch,60,2),实部和虚部作为一个整体特征data[feature_name] = data[feature_name].transpose(0, 2, 1)data[target_name] = y[start:start+n].reshape(-1,1)start += n
if Debug:# 检查数据效果for i in range(15,20):x_plot = data["EIS01"][i][:60]y_plot = data["EIS01"][i][60:]plt.plot(x_plot, y_plot)plt.show()
if Debug:# 检查数据效果for i in range(15,20):x_plot = data["Cap02"][:]plt.plot(x_plot)plt.show()
start = 0for i in range(1,11):if i == 1:trainning_data = data[f"EIS{i:02}"][start:].copy()trainning_target = data[f"Cap{i:02}"][start:].copy()#剔除测试集elif i!=4 and i!= 8 and i!= 10:#else:trainning_data = np.vstack((trainning_data,data[f"EIS{i:02}"][start:]))trainning_target = np.vstack((trainning_target,data[f"Cap{i:02}"][start:]))
trainning_data = torch.tensor(trainning_data, dtype=torch.float32)trainning_target = torch.tensor(trainning_target, dtype=torch.float32)
开始训练
# 初始化模型、损失函数和优化器input_size = 2 # 特征数量hidden_size = 128num_layers = 5output_size = 1conv_input = 60batch_size = 128epochs = 1500n_splits = 5
from sklearn.model_selection import KFoldimport gcdef gc_collect():gc.collect()torch.cuda.empty_cache()gc_collect()
kf = KFold(n_splits=n_splits, shuffle=True)model_number = 0for train_idx, val_idx in kf.split(trainning_data):train_X, val_X = trainning_data[train_idx], trainning_data[val_idx]train_y, val_y = trainning_target[train_idx], trainning_target[val_idx]train_dataset = TensorDataset(train_X, train_y)val_dataset = TensorDataset(val_X, val_y)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)model = LSTMModel(conv_input, input_size, hidden_size, num_layers, output_size)model = model.to(device)criterion = nn.MSELoss()optimizer = optim.Adam(model.parameters(), lr=0.0001,betas=(0.5,0.999))for epoch in range(epochs):model.train()for i, (inputs, labels) in enumerate(train_loader):inputs = inputs.to(device)labels = labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()model.eval()with torch.no_grad():for inputs, labels in val_loader:inputs = inputs.to(device)labels = labels.to(device)outputs = model(inputs)val_loss = criterion(outputs, labels)if epoch%100 ==0:print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item()}, Validation Loss: {val_loss.item()}')torch.save(model.state_dict(), f"model_weights/CNNBiLSTM/test{model_number}.pth")model_number += 1
from sklearn.metrics import mean_squared_errorfrom sklearn.metrics import r2_scoreimport math
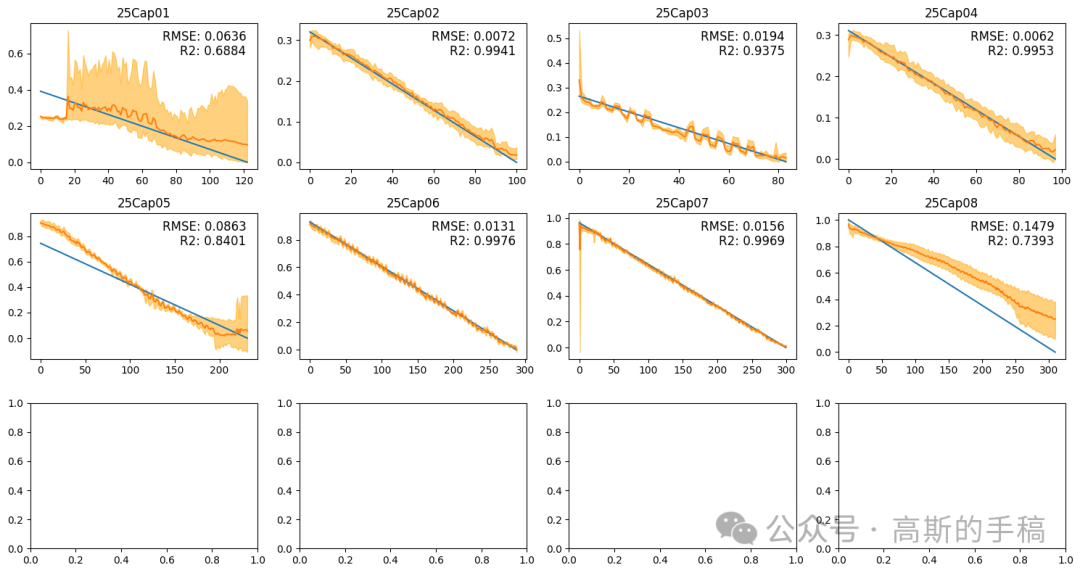
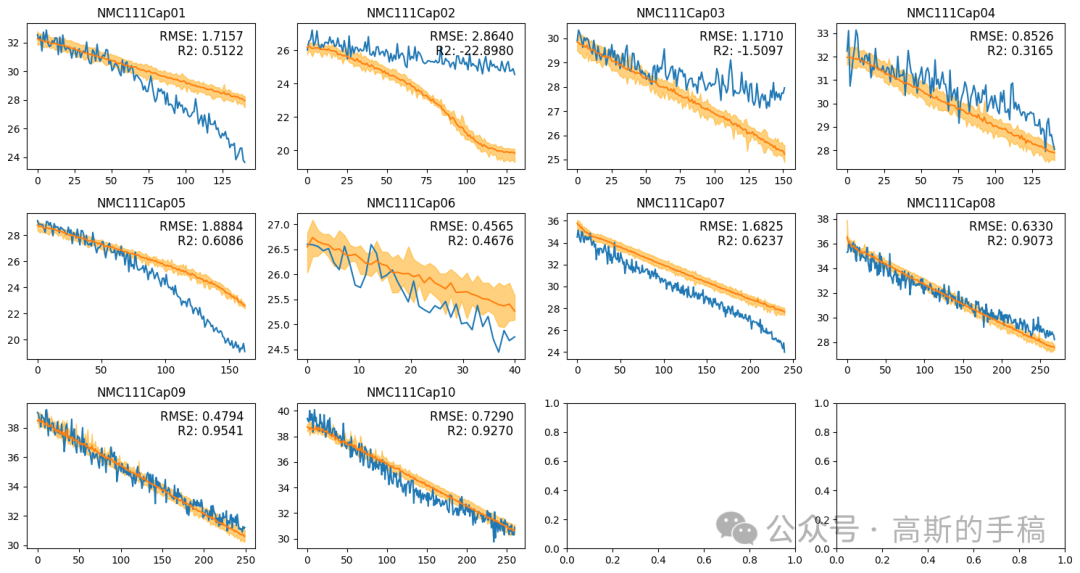
# 创建画布fig, axs = plt.subplots(nrows=3, ncols=4, figsize=(15, 8))ID = 1title_name = 1start = 0mean_RMSE_train = 0mean_RMSE_test = 0mean_R2_train = 0mean_R2_test = 0model = LSTMModel(conv_input, input_size, hidden_size, num_layers, output_size)model = model.to(device)# 在每个小区域中绘制图像for i in range(3):for j in range(4):result = []x = torch.tensor(data[f"EIS{ID:02}"], dtype=torch.float32)for k in range(n_splits):model.load_state_dict(torch.load(f"model_weights/CNNBiLSTM/test{k}.pth",map_location=torch.device(device)))out = model(x.to(device))out = out.cpu()out = out.detach().numpy()out = scaler.inverse_transform(out)result.append(out)result = np.array(result)out = np.mean(result, axis=0)out_upper = np.max(result, axis=0)out_upper = np.squeeze(out_upper)out_lower = np.min(result, axis=0)out_lower = np.squeeze(out_lower)true = data[f"Cap{ID:02}"]true = scaler.inverse_transform(true)MSE = mean_squared_error(out[start:], true[start:])R2_result = r2_score(true[start:], out[start:])RMSE_result = math.sqrt(MSE)mean_RMSE_train += RMSE_resultmean_R2_train += R2_resultRMSE_str = "{:.4f}".format(RMSE_result)R2_str = "{:.4f}".format(R2_result)x = np.linspace(0,x.shape[0],x.shape[0])axs[i, j].plot(x[start:], true[start:])axs[i, j].plot(x[start:], out[start:])axs[i, j].fill_between(x[start:], out_upper[start:], out_lower[start:], color='orange', alpha=0.5)axs[i, j].set_title(f"25Cap{title_name:02}")axs[i, j].text(0.95, 0.95, "RMSE: "+ RMSE_str, ha='right', va='top', fontsize=12, transform=axs[i, j].transAxes)axs[i, j].text(0.95, 0.85, "R2: "+ R2_str, ha='right', va='top', fontsize=12, transform=axs[i, j].transAxes)# 使用循环将数组中的每个元素写入文件with open(f"data/Nature_Cap_train{title_name:02}", 'w') as file:for item in range(out[start:].shape[0]):out_number = round(float(out[start:][item].flatten()), 4)#file.write(str(out_number) + '\t'+str(out_upper[start:][item])+ '\t'+str(out_lower[start:][item])+ '\n')file.write(str(out_number)+'\n')# 关闭文件file.close()ID += 1title_name += 1if ID == 11:break# 调整子图之间的距离plt.tight_layout()plt.savefig('figure_results/cap_alltempalldata_test_5_10_12.png')print("train RMSE: ", mean_RMSE_train/8)print("train R2: ", mean_R2_train/8)# 显示图像plt.show()

RUL预测结果:
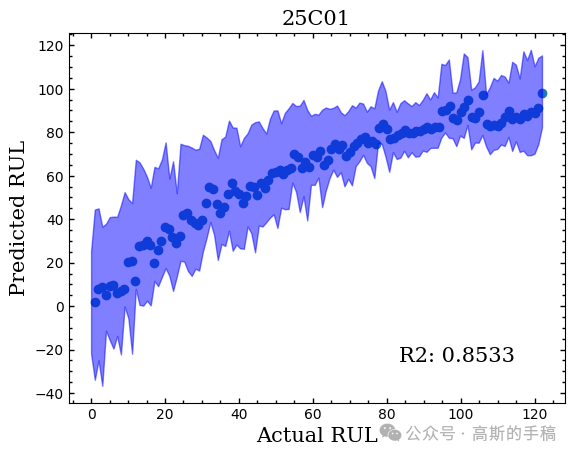
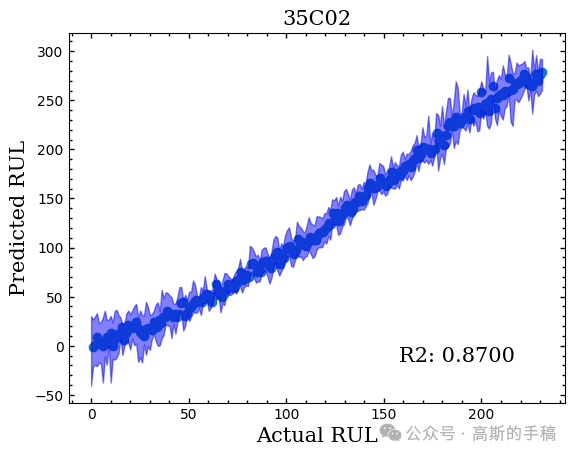
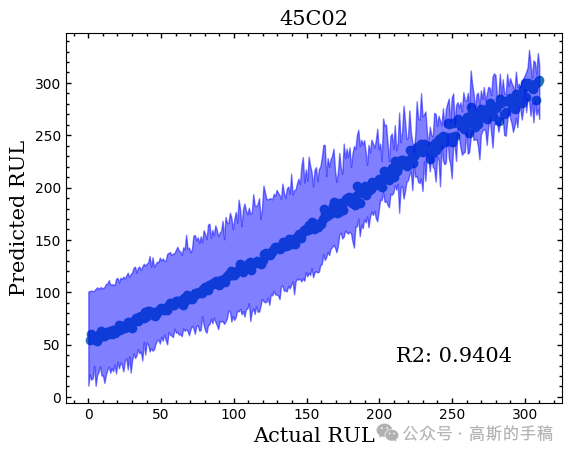
Trends预测结果
担任《Mechanical System and Signal Processing》《中国电机工程学报》《控制与决策》等期刊审稿专家,擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。