目录
一、理解缓存区的好处
(一)直观性的理解
(二)缓存区的好处
二、经典案例分析体会
(一)文件读写流(File I/O Buffering)
BufferedOutputStream 和 BufferedWriter 可以加快写入的速度
BufferedInputStream 和 BufferedReader 可以加快读取字符的速度
(二)日志缓冲(Logging Buffering)
三、案例回顾和优化方向分析
四、Kafka缓存区优化思考
(一)Kafka 的生产者,有可能会丢数据吗?
(二)Kafka 生产者会影响业务的高可用吗?
参考文章
在计算机科学的广袤世界里,有一项看似简单却又深奥无比的技术,那就是缓冲。缓冲,像是隐藏在代码背后的魔法,它默默地改变着数据的流动,使得看似杂乱无章的操作变得井然有序。然而,它的本质并非只是简单的数据暂存,而是一种艺术,一门科学。
一、理解缓存区的好处
(一)直观性的理解
在Java虚拟机(JVM)中,堆内存扮演了一个重要的角色,用于存储动态分配的对象。当代码执行时,不断地在堆空间中创建新的对象,这些对象会暂时存放在堆中,直到不再需要时才被垃圾回收器回收。这个过程就像是在一个巨大的缓存中存储着各种数据。
垃圾回收器进程则负责在后台默默地进行垃圾回收,清理不再被引用的对象,释放内存空间。这就像是在缓存中进行定期的清理和整理,以保持缓存的有效性和性能。
所以,JVM的堆空间可以被视为一个巨大的缓存,它存储着临时的对象数据,并且由垃圾回收器进程来管理和维护。这个例子很好地展示了缓存的概念,即通过暂存数据来提高系统的效率和性能,同时保持数据的一致性和可用性。
生活化一些的,想象每年过大年你和大家庭的亲人们正在一起包饺子,每个人都有不同的任务。有的人负责擀面皮,有的人负责包馅料,还有的人负责煮饺子。但是,大家的速度并不总是一致的,有时候有人擀好了面皮,但包馅的还没准备好,有时候包馅的准备好了,但煮饺子的还在忙其他的事情。
这时,你们决定在中间放一个大盆子,就像是一个缓冲区一样。每当有人完成了自己的任务,就把成果放进盆子里,而需要下一个任务的人则从盆子里取出材料进行下一步操作。这样一来,即使大家的速度不一致,也不会影响整个过程的进行,每个人都可以按照自己的节奏进行操作,保持了整个包饺子过程的顺畅进行。
(二)缓存区的好处
无论是在生活中还是在程序设计中,缓冲区都扮演着类似的角色,平衡了不同速度之间的数据流动,保证了整个过程的顺畅进行。总结下缓冲区的好处:
| 好处 | 描述 |
|---|---|
| 平衡数据流速度差异 | 缓冲区可以暂时存储数据,平衡生产者和消费者之间的速度差异,防止数据丢失或处理延迟。 |
| 降低系统开销 | 通过批量处理数据,减少频繁的数据交互和I/O操作,降低系统的开销,提高系统效率。 |
| 提高系统性能 | 缓冲区优化数据处理方式,减少等待时间,提高系统的响应速度,从而提高系统性能。 |
| 保护数据一致性 | 缓冲区暂存数据,直到数据传输或处理完成,保护数据的一致性,避免数据丢失或损坏。 |
| 优化用户体验 | 在音视频播放或网络通信等应用场景中,提前缓冲数据可以实现流畅的用户体验,提高用户满意度。 |
二、经典案例分析体会
我们将介绍几个经典的缓冲区应用案例,并分析它们的优势和适用场景:
| 案例 | 前提描述 | 描述 |
|---|---|---|
| 文件读写流(File I/O Buffering) | 当需要进行大量文件读写操作时,可以使用缓冲区来提高性能。 | 在文件读写操作中使用缓冲区来提高性能。将文件内容暂存到内存缓冲区中,减少对磁盘的频繁访问。写入数据时,也可以暂存到缓冲区,减少磁盘I/O操作次数。 |
| 网络数据传输缓冲(Network Data Transfer Buffering) | 在进行网络数据传输时,为了提高效率和稳定性,可以使用缓冲区来缓存发送和接收的数据。 | 在网络通信中使用缓冲区来缓存发送和接收的数据,提高网络数据传输的效率和稳定性。发送端和接收端都可以利用缓冲区来优化数据传输。 |
| 日志缓冲(Logging Buffering) | 当系统需要进行日志记录,并且对系统性能有一定要求时,可以使用日志缓冲区来优化日志写入操作。 | 在软件系统中使用日志缓冲区来减少对系统性能的影响。将待写入的日志信息暂存到缓冲区中,定期批量写入日志文件,减少磁盘I/O操作,提高系统性能。 |
| 内存缓存(Memory Caching) | 当系统需要频繁访问某些数据,并且对数据访问速度有较高要求时,可以使用内存缓存来提高数据访问速度。 | 使用内存缓存来暂存频繁访问的数据,提高数据访问速度和效率。比如,Web服务器可以将经常访问的网页内容暂存到内存中,减少磁盘访问,提高网页访问速度。 |
选取其中的两个可以展开进行分析体会。
(一)文件读写流(File I/O Buffering)
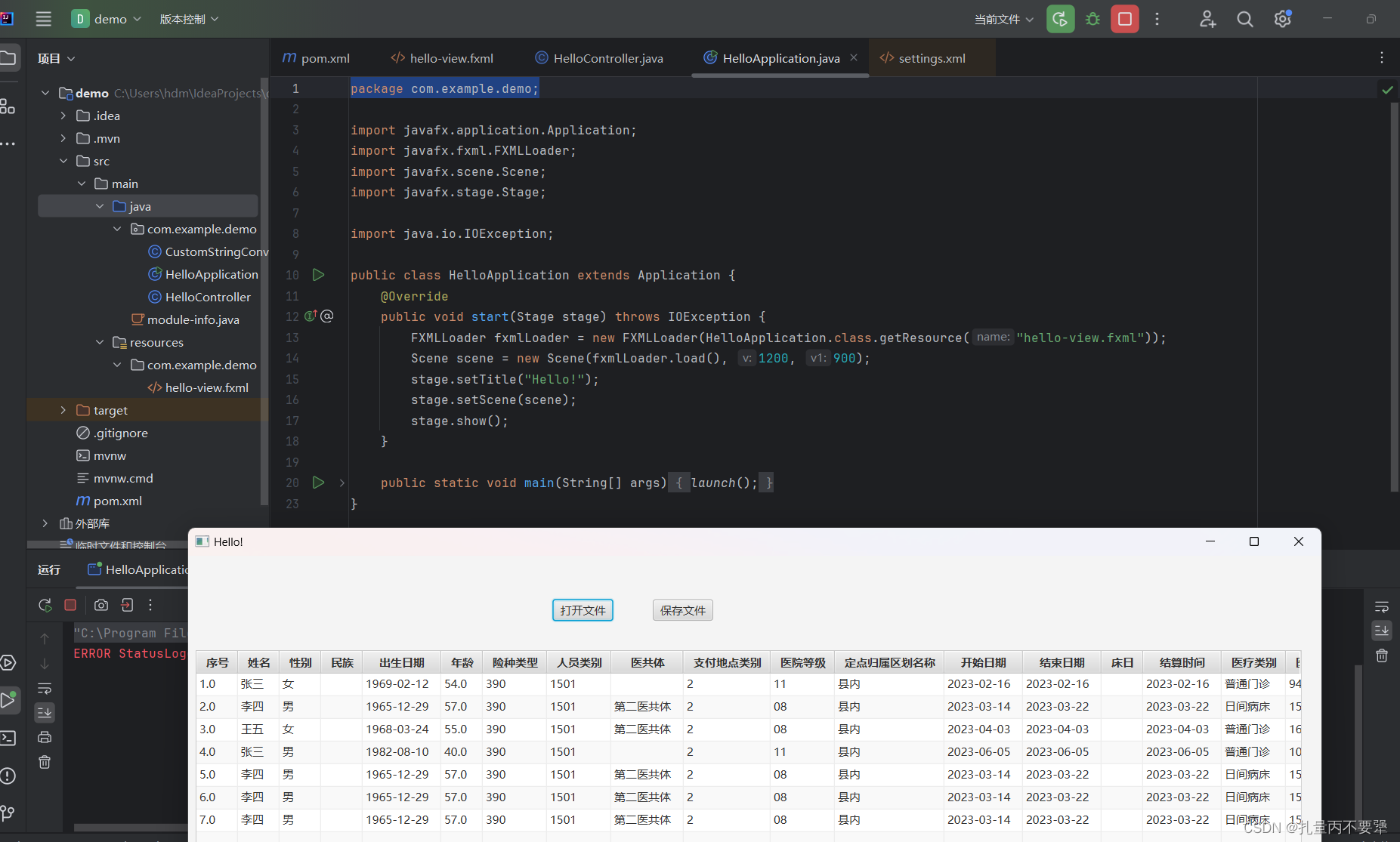
缓冲在 Java 语言中被广泛应用,在 IDEA 中搜索*buffer,可以看到长长的类列表,其中最典型的就是文件读取和写入字符流。
Java 的 I/O 流设计,采用的是装饰器模式,当需要给类添加新的功能时,就可以将被装饰者通过参数传递到装饰者,封装成新的功能方法。

Java的I/O库中提供了许多装饰器类,如BufferedInputStream和BufferedOutputStream,它们通过装饰器模式来给输入流和输出流添加额外的功能,比如缓冲功能。
一般情况下,在读取和写入流的 API 中,BufferedInputStream 和 BufferedReader 可以加快读取字符的速度,BufferedOutputStream 和 BufferedWriter 可以加快写入的速度。
BufferedOutputStream 和 BufferedWriter 可以加快写入的速度
以BufferedWriter为例分析,当需要写入字符时,使用BufferedWriter相对于直接使用FileWriter可以提供更高的写入速度,因为BufferedWriter内部使用了缓冲区,能够一次写入多个字符,减少了频繁的系统调用和磁盘访问次数。我们可以通过对比使用BufferedWriter和直接使用FileWriter的写入速度:
package org.zyf.javabasic.io;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
/**
* @program: zyfboot-javabasic
* @description: 使用BufferedWriter相对于直接使用FileWriter可以提供更高的写入速度
* @author: zhangyanfeng
* @create: 2024-05-26 17:28
**/
public class BufferedWriterIOExample {
private static final String FILE_PATH = "example.txt";
private static final String CONTENT = "This is a test content. ";
public static void main(String[] args) {
long startTime, endTime;
// 测试直接使用FileWriter写入字符
startTime = System.currentTimeMillis();
try (FileWriter fileWriter = new FileWriter(FILE_PATH)) {
for (int i = 0; i < 100000; i++) {
fileWriter.write(CONTENT);
}
} catch (IOException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("直接使用FileWriter写入字符耗时:" + (endTime - startTime) + " 毫秒");
// 测试使用BufferedWriter写入字符
startTime = System.currentTimeMillis();
try (BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(FILE_PATH))) {
for (int i = 0; i < 1000000; i++) {
bufferedWriter.write(CONTENT);
}
} catch (IOException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("使用BufferedWriter写入字符耗时:" + (endTime - startTime) + " 毫秒");
}
}
通过运行测试
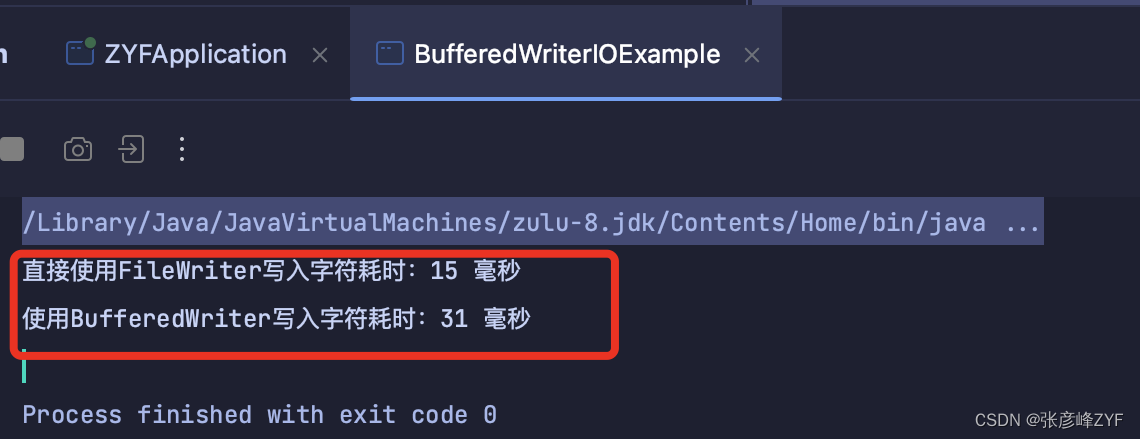
可以观察到使用BufferedWriter的写入速度明显要快,在BufferedWriter的源码中,可以看到它内部维护了一个字符数组作为缓冲区,数据会先被写入到这个缓冲区中,然后再一次性地将缓冲区中的数据写入到底层的Writer中。简化版本BufferedWriter:
import java.io.*;
public class BufferedWriter extends Writer {
// 缓冲区大小,默认为 8192
private static final int DEFAULT_BUFFER_SIZE = 8192;
// 缓冲区字符数组
private char[] buffer;
// 缓冲区中的数据索引
private int index;
// 底层的 Writer 对象
private Writer out;
// 构造方法
public BufferedWriter(Writer out) {
this(out, DEFAULT_BUFFER_SIZE);
}
// 带缓冲区大小的构造方法
public BufferedWriter(Writer out, int bufferSize) {
this.out = out;
buffer = new char[bufferSize];
index = 0;
}
// 写入一个字符到缓冲区
@Override
public void write(int c) throws IOException {
if (index >= buffer.length) {
flushBuffer(); // 如果缓冲区已满,先将缓冲区中的数据写入到底层 Writer 中
}
buffer[index++] = (char) c;
}
// 写入字符数组到缓冲区
@Override
public void write(char[] cbuf, int off, int len) throws IOException {
for (int i = off; i < off + len; i++) {
write(cbuf[i]); // 循环调用写入一个字符到缓冲区的方法
}
}
// 刷新缓冲区,将缓冲区中的数据写入到底层 Writer 中
@Override
public void flush() throws IOException {
flushBuffer();
out.flush();
}
// 关闭 BufferedWriter,先刷新缓冲区,再关闭底层的 Writer
@Override
public void close() throws IOException {
flush();
out.close();
}
// 刷新缓冲区
private void flushBuffer() throws IOException {
if (index > 0) {
out.write(buffer, 0, index); // 将缓冲区中的数据写入到底层 Writer 中
index = 0; // 重置索引
}
}
}
通过这段代码,我们可以直接看到BufferedWriter内部使用了缓冲区,数据会先暂时存储在缓冲区中,等到需要刷新缓冲区或关闭BufferedWriter时,才会将缓冲区中的数据一次性写入到底层的Writer中。
BufferedInputStream 和 BufferedReader 可以加快读取字符的速度
同样以BufferedReader为例,当需要读取字符时,使用BufferedReader相对于直接使用FileReader可以提供更高的读取速度,因为BufferedReader内部使用了缓冲区,能够一次读取多个字符,减少了频繁的系统调用和磁盘访问次数。我们通过对比使用BufferedReader和直接使用FileReader的读取速度:
package org.zyf.javabasic.io;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
/**
* @program: zyfboot-javabasic
* @description: 使用BufferedReader相对于直接使用FileReader可以提供更高的读取速度
* @author: zhangyanfeng
* @create: 2024-05-26 17:40
**/
public class BufferedReaderIOExample {
private static final String FILE_PATH = "example.txt";
public static void main(String[] args) {
long startTime, endTime;
// 测试直接使用FileReader读取字符
startTime = System.currentTimeMillis();
try (FileReader fileReader = new FileReader(FILE_PATH)) {
int data;
while ((data = fileReader.read()) != -1) {
// 模拟处理读取的字符
// System.out.print((char) data);
}
} catch (IOException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("直接使用FileReader读取字符耗时:" + (endTime - startTime) + " 毫秒");
// 测试使用BufferedReader读取字符
startTime = System.currentTimeMillis();
try (BufferedReader bufferedReader = new BufferedReader(new FileReader(FILE_PATH))) {
String line;
while ((line = bufferedReader.readLine()) != null) {
// 模拟处理读取的字符
// System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("使用BufferedReader读取字符耗时:" + (endTime - startTime) + " 毫秒");
}
}
通过运行测试
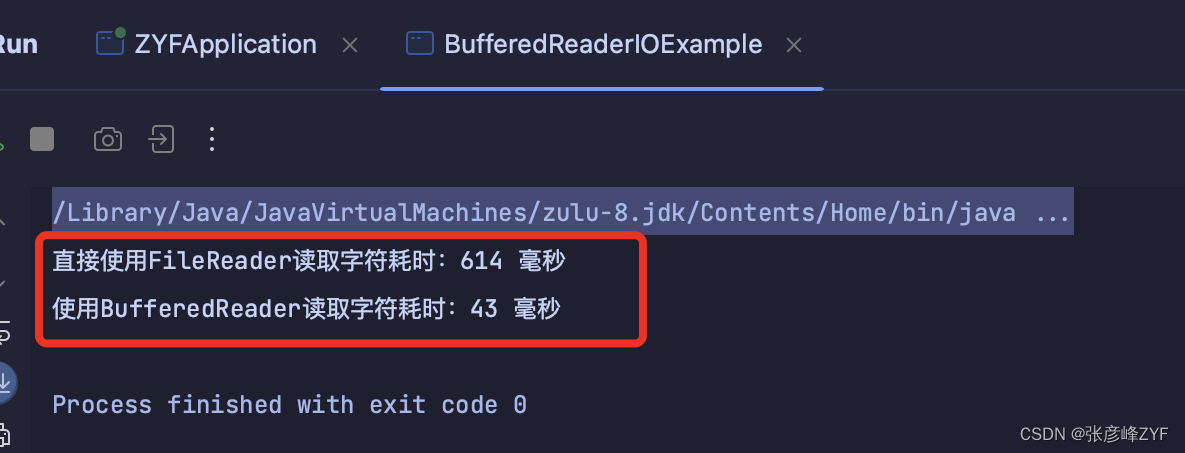
可以观察到使用BufferedReader的读取速度会明显快于直接使用FileReader,这是因为BufferedReader内部使用了缓冲区,能够一次读取多个字符,减少了频繁的系统调用和磁盘访问次数,从而提高了读取的效率,其源码上的处理这里就不在展示了。
(二)日志缓冲(Logging Buffering)
在Java开发中,日志记录是一个至关重要的方面。 无论是开发过程中的调试和追踪问题,还是生产环境中的监控和排错,日志都是程序员们必不可少的工具之一。然而,在高并发和大规模的应用中,日志记录往往会带来一些挑战。 随着应用程序的规模和用户量的增长,日志消息的数量也会急剧增加,可能会导致大量的磁盘 I/O 操作和系统开销,从而影响应用程序的性能和稳定性。
为了解决这些挑战,我们需要一种高效且可靠的日志记录框架。 这就是Logback发挥作用的地方。作为SLF4J的一种实现,Logback不仅提供了简洁易用的API,还具有出色的性能和可靠性。
其中一个Logback的特点就是异步日志记录。 异步日志记录机制使得Logback可以将日志消息先放入缓冲队列中,而不是立即写入到日志文件中,从而减少了对磁盘的频繁访问,提高了日志记录的效率。以下图实现为了:
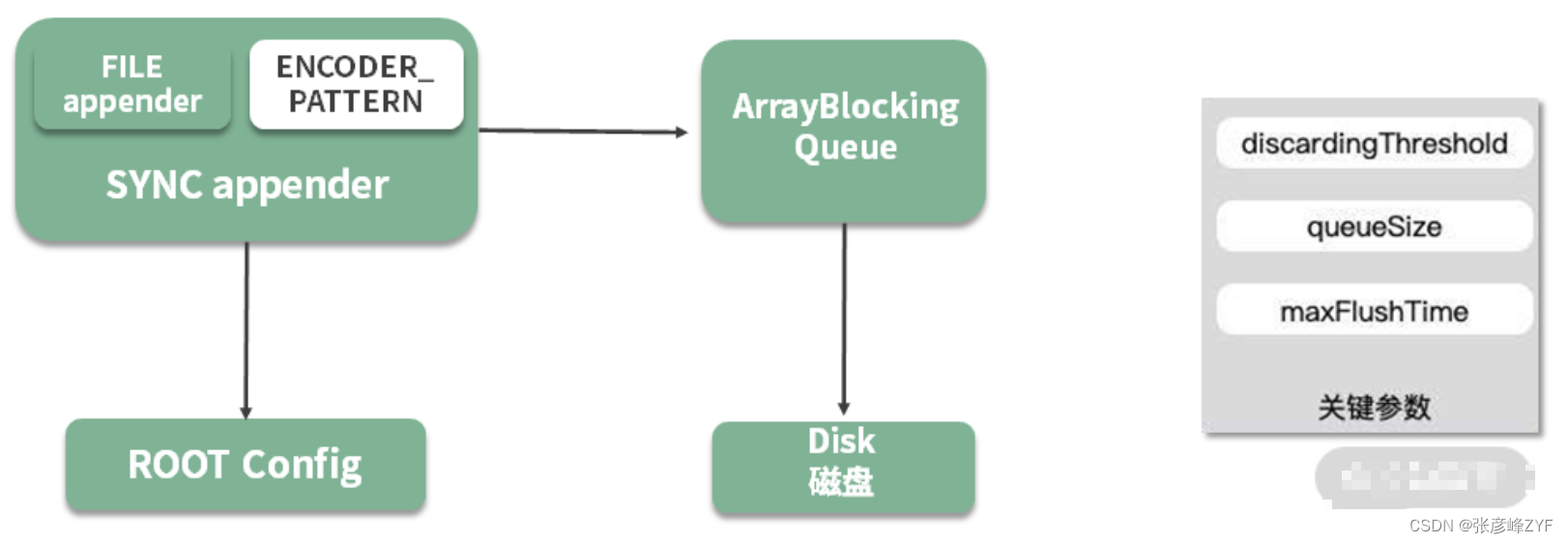
Logback的异步日志输出流程中应用程序生成日志消息,并调用Logback的日志记录接口进行记录。Logback将生成的日志消息放入一个ArrayBlockingQueue队列中,这是一个线程安全的有界队列。这个队列充当了生产者-消费者模式中的缓冲区,用于临时存储待写入的日志消息。
也就是说,Logback启动一个后台Worker线程,该线程负责从队列中获取日志消息,并将其写入到磁盘中。后台Worker线程不断地从队列中取出日志消息,然后将这些消息写入到指定的日志文件中。在写入磁盘时,Logback可以通过一些优化手段,比如批量写入和异步IO,来提高写入性能。
一旦后台Worker线程将队列中的日志消息全部写入磁盘后,整个日志记录流程就完成了。总的来说,异步日志输出之后,日志信息将暂存在 ArrayBlockingQueue 列表中,后台会有一个 Worker 线程不断地获取缓冲区内容,然后写入磁盘中。
上图中提及的三个关键参数说明如下:
-
queueSize(队列大小):这个参数定义了异步日志队列的最大容量,即可以存放的日志消息数量上限。默认值为256。如果队列大小设置得太小,在高并发情况下,日志消息产生速度超过了写入速度,可能会导致队列溢出,从而丢失一部分日志消息。因此,应根据系统的实际情况和性能需求合理设置队列大小。但要注意,如果将队列大小设置得太大,在突发断电等异常情况下,会导致大量的日志消息被丢失。
-
maxFlushTime(最大刷新时间):这个参数定义了在关闭日志上下文后,继续执行写任务的时间。Logback会在关闭日志上下文时调用Thread的join方法,等待后台Worker线程执行完剩余的写任务。默认情况下,maxFlushTime未设置,即等待所有写任务执行完毕才关闭日志上下文。如果系统中有一些耗时较长的写任务,可能会导致日志上下文无法及时关闭,影响系统的正常关闭和资源释放。因此,可以通过设置maxFlushTime来限制等待的最大时间,保证日志上下文能够及时关闭。
-
discardingThreshold(丢弃阈值):这个参数定义了当队列快要达到最大容量时,是否丢弃一些级别较低的日志消息。默认值为队列长度的80%。在高负载情况下,如果不及时处理日志消息,队列可能会溢出,从而导致丢失重要的日志信息。通过设置discardingThreshold,可以在队列快要达到上限时,丢弃一些级别较低的日志消息,保证队列不会溢出。如果你担心可能会丢失业务关键的日志,可以将这个值设置为0,表示不丢弃任何日志消息,所有日志都会被记录。
这些关键参数在配置异步日志记录时非常重要。
三、案例回顾和优化方向分析
针对文件读写流和Logback的两个例子,我们可以看到:
- 文件读写流:当使用文件写入流(如BufferedOutputStream)时,写入的数据首先被放入缓冲区中,而不是直接写入到文件中。这意味着在写入操作完成之前,数据实际上并没有真正地写入到文件中,而是先存储在缓冲区中。为了确保数据被及时写入文件,我们需要手动调用flush()方法来刷新缓冲区,将数据立即写入文件中。这样可以避免因为程序崩溃而导致的数据丢失问题。
- Logback:Logback的异步日志记录机制使用了缓冲区,将日志消息暂存于缓冲队列中,然后由后台Worker线程负责将日志消息写入磁盘中。通过配置参数来控制缓冲队列的大小、最大刷新时间等,以及是否在队列快满时丢弃日志消息。通过合理配置这些参数,可以平衡性能和可靠性之间的关系,确保日志记录的效率和稳定性。
在处理缓冲区设计的常规操作时,需要注意及时刷新缓冲区,以确保数据被正确地写入到目标资源中,同时要考虑到异步操作可能引入的时序问题,保证程序的正确性和稳定性。
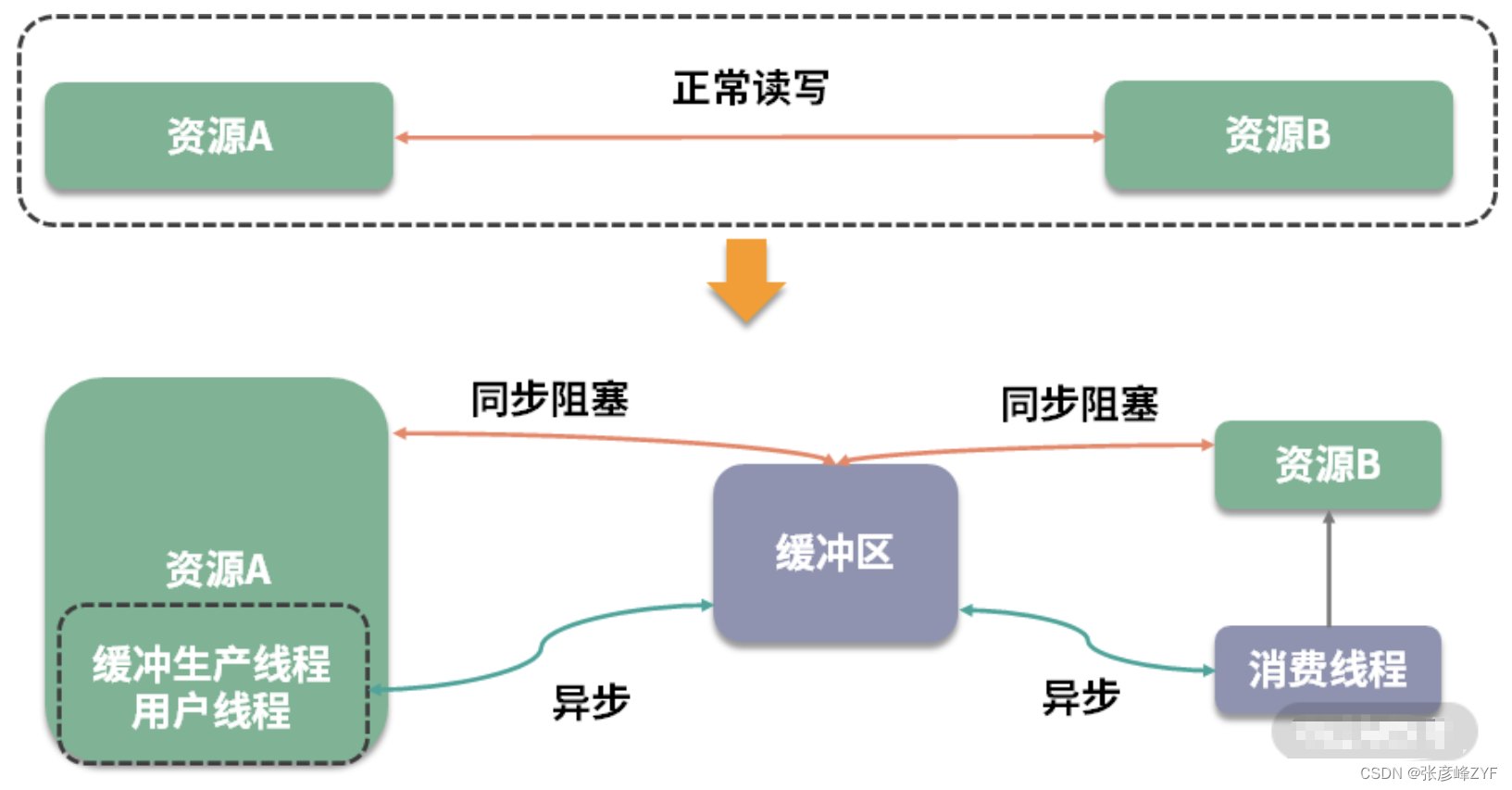
根据不同的资源和应用场景,选择适当的缓存优化设计是非常常见的做法。
-
同步操作:适用于对数据完整性要求较高,可以容忍一定程度的性能损失的场景。同步操作会阻塞当前线程,直到操作完成,确保数据的及时写入或处理。这种方式通常适用于对数据一致性要求较高、对性能要求相对较低的场景。
-
异步操作:适用于对性能要求较高,可以容忍一定程度的数据丢失或时序不一致的场景。异步操作将数据暂存于缓冲区中,并由后台线程异步处理,从而提高了系统的响应性能和并发能力。这种方式通常适用于高并发、大规模的应用场景,可以显著提升系统的吞吐量和性能。
有时候,甚至可以结合同步和异步操作,针对不同的场景采用不同的缓存优化方案,以达到最佳的性能和可靠性。日常的开发中我们需要不断的思考引入缓存来解决我们的一些业务诉求,同时需要思考对应的优化手段。
四、Kafka缓存区优化思考
在 Kafka 中,消息是通过分区存储的,并且每个分区都有一个存储日志文件(log file)来持久化消息。这些日志文件是以分段(segment)的方式组织的,每个分段包含一定数量的消息。而消息的写入和读取都是通过分段来进行的。

Kafka 同样利用了缓存区的思想来优化消息的写入和读取过程,具体我们通过分析两个基本问题来说明。
(一)Kafka 的生产者,有可能会丢数据吗?
Kafka 生产者会将发送到同一个分区的多条消息封装在一个缓冲区(batch)中。这个缓冲区有两种触发条件:一是缓冲区满了,即达到了指定的大小(batch.size);二是消息在缓冲区中等待的时间超过了指定的超时时间(linger.ms)。一旦满足了其中一个条件,缓冲区中的消息就会被发送到 Kafka Broker 上。
在默认情况下,Kafka 的缓冲区大小为 16KB。如果生产者的业务突然断电或发生故障,尚未发送到 Broker 的 16KB 数据将会丢失,因为它们没有机会被发送出去。这种情况下,消息丢失是有可能发生的。
为了避免这种情况的发生,我们有两种解决办法都是可行的:
-
缓冲区大小设置较小:将缓冲区大小设置得非常小,以确保在生产者发生故障时,待发送的数据量较小,从而减少了可能丢失的数据量。但是,将缓冲区大小设置得太小可能会导致性能下降,因为每条消息都需要单独发送,增加了网络开销和系统负载。
-
消息发送日志记录:在消息发送前记录一条日志,标记消息发送的开始,然后在消息成功发送后通过回调再记录一条日志,标记消息发送的结束。通过扫描生成的日志,可以判断哪些消息丢失了。这种方法可以有效地追踪和识别丢失的消息,但需要额外的日志记录和扫描操作,可能会增加系统的复杂性和开销。
对于如何处理生产者发生故障时可能丢失的数据,需要根据具体的业务需求和性能要求来选择合适的解决方案。在权衡性能和可靠性的基础上,可以选择合适的缓冲区大小,并结合消息发送日志记录等技术手段来确保消息的可靠传输和处理。
(二)Kafka 生产者会影响业务的高可用吗?
Kafka 生产者的设计确实可能会影响业务的高可用性,特别是与生产者的缓冲区大小和超时参数相关的配置。
-
缓冲区大小限制:生产者的缓冲区是有限的,如果消息产生得过快或者生产者与 Broker 节点之间存在网络问题,缓冲区可能会一直处于满载状态。在这种情况下,有新的消息到达时,可能会导致阻塞。
-
超时参数设置:通过配置生产者的超时参数和重试次数,可以控制生产者在缓冲区满载时的行为。一般来说,将超时参数设置得较小可以让新的消息不会一直阻塞在业务方。然而,有些情况下,如果将超时参数设置得过大,可能会导致生产者线程被阻塞,无法继续处理新的请求,从而影响了业务的高可用性。
为了确保 Kafka 生产者与业务的高可用性,需要合理配置生产者的缓冲区大小、超时参数以及重试策略,以及针对可能的异常情况进行监控和调优。同时,也需要在系统设计时考虑消息传输的可靠性和容错性,以应对可能发生的各种问题,从而保障业务的稳定运行。
参考文章
《Java 性能优化与面试 21 讲》,李国
https://www.cnblogs.com/zhzhlong/p/11420084.html
【深入浅出C#】章节 7: 文件和输入输出操作:文件读写和流操作-腾讯云开发者社区-腾讯云
Azure HPC 缓存使用情况模型 | Microsoft Learn
专为流式数据设计的另一种缓存:流式缓存技术解读_语言 & 开发_Andrei Paduroiu_InfoQ精选文章
https://zhuanlan.zhihu.com/p/641984395
https://zhuanlan.zhihu.com/p/475320277
IO流中的设计模式_io流用到的设计模式-CSDN博客
https://www.cnblogs.com/LoveShare/p/17029000.html
概念,原理,到例子,全解析logback ,学会日志系统-腾讯云开发者社区-腾讯云
logback配置详解 & 原理介绍_logback 配置原理-CSDN博客
logback之 AsyncAppender 的原理、源码及避坑建议-阿里云开发者社区
快速了解常用日志技术(JCL、Slf4j、JUL、Log4j、Logback、Log4j2)-阿里云开发者社区