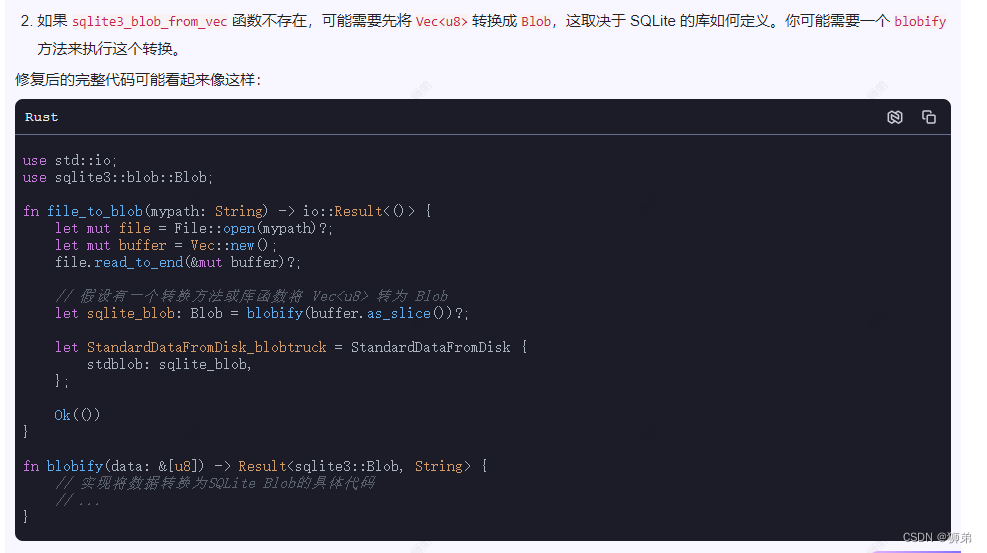
python-windows10普通笔记本跑bert mrpc数据样例0.1.000
-
- 背景
- 参考章节
- 获取数据
- 下载bert模型
- 下载bert代码
- windows10的cpu进行训练
- 进行预测
- 注意事项
- TODOLIST
背景
看了介绍说可以在gpu或者tpu上去微调,当前没环境,所以先在windows10上跑一跑,看是否能顺利进行,目标就是训练的过程中没有报错就行
参考章节
参考这个链接https://github.com/google-research/bert/tree/master?tab=readme-ov-file,其中的这个章节Sentence (and sentence-pair) classification tasks
获取数据
文章提高的使用 GLUE data by running this script(https://gist.github.com/W4ngatang/60c2bdb54d156a41194446737ce03e2e),但是我使用这个脚本下载不了,因为是内网,没有办法只能手动下载了,方法如下
- 下载download_glue_data.py这个脚本后
- 找到第39和40行,将里面的链接打开保存文件就可以获得msr_paraphrase_train.txt和sr_paraphrase_test.txt文件了
MRPC_TRAIN = 'https://dl.fbaipublicfiles.com/senteval/senteval_data/msr_paraphrase_train.txt'
MRPC_TEST = 'https://dl.fbaipublicfiles.com/senteval/senteval_data/msr_paraphrase_test.txt'
- 数据不大,我直接修改的文本格式为tsv,最后得到test.tsv和train.tsv文件
- 打开这个链接下载另外一个需要的数据dev_ids.tsv
https://raw.githubusercontent.com/MegEngine/Models/master/official/nlp/bert/glue_data/MRPC/dev_ids.tsv - 注释掉download_glue_data.py里面的下面的代码
# try:
# urllib.request.urlretrieve(TASK2PATH["MRPC"], os.path.join(mrpc_dir, "dev_ids.tsv"))
# except KeyError or urllib.error.HTTPError:
# print("\tError downloading standard development IDs for MRPC. You will need to manually split your data.")
# return
- 将dev_ids.tsv的文件放在–data_dir下面的MRPC里面
- 运行download_glue_data.py文件生成数据如下
python .\download_glue_data.py --tasks=MRPC --data_dir=D:\jpdir\bert\glue_data\MRPC\fin --path_to_mrpc=D:\jpdir\bert\glue_data\MRPC
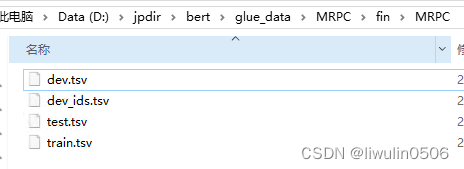
8. 将生成的dev.tsv文件放在python run_classifier.py脚本的data_dir目录下
下载bert模型
下载bert-base-uncased模型,如下图
下载bert代码
将这个链接https://github.com/google-research/bert/tree/master?tab=readme-ov-file的代码clone下来到本地,进入到这个文件夹里,执行如下命令即可:
python run_classifier.py --task_name=MRPC --do_train=true --do_eval=true --data_dir=D:\jpdir\bert\glue_data\MRPC --vocab_file=D:\jpdir\bert\bert-base-uncased\bert-base-uncased\bert-base-uncased\vocab.txt --bert_config_file