encoding 编码
“encoding” 是一个在计算机科学和人工智能领域广泛使用的术语,它可以指代多种不同的过程和方法。核心就是编码:用某些数字来表示特定的信息。当然你或许会说字符集(Unicode)更理解这种概念,编码更强调这种动态的过程。而字符集是静态的。以下是一些具体的例子和用法,帮助你更全面地理解这个概念:
字符编码(Character Encoding)
UTF-8 Encoding:将Unicode字符转换为字节序列。
text = "你好,世界"
encoded_text = text.encode('utf-8')
print(encoded_text) # 输出: b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8c\xe4\xb8\x96\xe7\x95\x8c'
Base64 Encoding:将二进制数据编码为ASCII字符串,常用于在URL、电子邮件等中传输二进制数据。
一般我们调用云服务进行什么QQ截图识别,截图的这个图像就是通过base64字符串进行传播的。
import base64
data = b"hello world"
encoded_data = base64.b64encode(data)
print(encoded_data) # 输出: b'aGVsbG8gd29ybGQ='
序列编码(Sequence Encoding)
例如独热编码(One-Hot Encoding):将分类数据转换为二进制向量,每个向量中只有一个高位(1),其余为低位(0)。
from sklearn.preprocessing import OneHotEncoder
import numpy as np
categories = np.array(['apple', 'banana', 'cherry']).reshape(-1, 1)
encoder = OneHotEncoder(sparse=False)
one_hot_encoded = encoder.fit_transform(categories)
print(one_hot_encoded)
# 输出: [[1. 0. 0.]
# [0. 1. 0.]
# [0. 0. 1.]]
词嵌入(Word Embeddings)
是的,Embedding其实也是一种encoding,更广义的,一篇文章切分成块以后,也可以把文本块转成成特定的向量。这里的word Embeddings特指把英文单词表示为向量。(杠精问中文单词怎么办,中文需要在进入embeddings前加一道分词的工序)
例如 Word2Vec:将单词表示为向量,使得语义相似的单词在向量空间中距离较近。
from gensim.models import Word2Vec
sentences = [["hello", "world"], ["machine", "learning"], ["word", "embeddings"]]
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
vector = model.wv['hello']
print(vector) # 输出: [0.1, -0.2, ..., 0.05] # 维度为100的向量
位置编码(Positional Encoding)
正弦和余弦位置编码(Sinusoidal Positional Encoding):在Transformer模型中用于注入位置信息。
import torch
import math
def positional_encoding(max_len, d_model):
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
return pe
max_len = 50
d_model = 512
pos_enc = positional_encoding(max_len, d_model)
print(pos_enc.shape) # 输出: torch.Size([50, 512])
图像编码(Image Encoding)
JPEG Encoding:将图像数据压缩并编码为JPEG格式。
from PIL import Image
import io
image = Image.open("example.jpg")
buffer = io.BytesIO()
image.save(buffer, format="JPEG")
jpeg_encoded_image = buffer.getvalue()
print(jpeg_encoded_image[:10]) # 输出图像文件的前10个字节
PNG Encoding:将图像数据编码为PNG格式。
from PIL import Image
import io
image = Image.open("example.png")
buffer = io.BytesIO()
image.save(buffer, format="PNG")
png_encoded_image = buffer.getvalue()
print(png_encoded_image[:10]) # 输出图像文件的前10个字节
Token
计算机领域
Token这一次不是最近才出现的,在计算机领域是早已有之。在计算机科学的早期,人们主要使用低级语言,如机器语言和汇编语言,直接与计算机硬件进行交互。这些语言的指令通常直接对应于计算机的基本操作,不需要像高级语言那样经过复杂的编译或解释过程。
随着高级编程语言的出现,如FORTRAN(1957)、COBOL(1959)、ALGOL(1960)等,编译器和解释器开始扮演重要的角色。这些语言引入了更抽象、更接近人类语言的语法和结构,需要通过编译或解释的过程转换为计算机可以直接执行的低级指令。
在这个过程中,词法分析(Lexical Analysis)作为编译器或解释器的第一步,负责将源代码划分为一系列的token。token的概念在这个时期开始在计算机领域广泛使用,用于表示源代码中的基本单元,如关键字、标识符、字面量等。
下面是一些编程语言中token的例子:
In C++:
- Keywords: if, else, for, while, int, float, etc.
- 关键字: if, else, for, while, int, float 等。
- Identifiers: variable names, function names, etc.
- 标识符: 变量名,函数名等。
- Operators: +, -, *, /, =, ==, !=, etc.
- 运算符: +, -,*, /, =, ==, != 等。
- Literals: 42, 3.14, “Hello, world!”, etc.
- 字面量: 42, 3.14, “Hello, world!” 等。(注意,在编译器的语言环境里,字面量这么一个字符串,就是一个token,和后面人工智能领域token的概念有差别.)
In Python:
- Keywords: if, elif, else, for, while, def, class, etc.
- 关键字: if, elif, else, for, while, def, class 等。
- Identifiers: variable names, function names, class names, etc.
- 标识符: 变量名,函数名,类名等。
- Operators: +, -, *, /, =, ==, !=, in, not, etc.
- 运算符: +, -, *, /, =, ==, !=, in, not 等。
- Literals: 42, 3.14, “Hello, world!”, [1, 2, 3], {“key”: “value”}, etc.
- 字面量: 42, 3.14, “Hello, world!”, [1, 2, 3], {“key”: “value”} 等。
自然语言处理
在自然语言处理(NLP)领域,token是一个基本而重要的概念。它源自编程语言的词法分析过程,表示源代码中的最小有意义单元,如关键字、标识符、字面量等。随着NLP技术的发展,token这一概念被引入到了人类语言的处理中,成为了文本分析和理解的基础。
早期的NLP研究受到了形式语言理论和生成语法的影响,致力于发现人类语言的结构化规则和范式。研究人员尝试将语法分析的方法应用于自然语言,将句子划分为更小的单元(即token)进行处理。在这个过程中,token可以表示单词、标点符号、停顿等语言元素。通过对token的分析和组合,研究人员希望揭示语言的底层结构,实现对人类语言的自动理解和生成。
然而,随着语言的不断发展和变化,传统的基于规则的方法面临着挑战。人类语言的表达方式灵活多变,新词、新语和隐喻不断涌现。例如,

"好样的!精神点!别丢分!"这样的口语表达,其中蕴含了丰富的情感和语境信息,而这些信息难以用简单的词法和语法规则来捕捉。再比如,"坤坤"这样的网络流行语,其指代对象可能与字面意思完全不同。传统的NLP方法难以应对这种语言的动态性和创造性。
随着深度学习和神经网络的兴起,NLP领域出现了新的突破。基于transformer架构的语言模型,如BERT、GPT等,展现了强大的语言理解和生成能力。这些模型不再依赖于预定义的语法规则,而是通过从海量文本数据中学习语言的统计规律和上下文信息,自动捕捉语言的复杂特征。在这个过程中,token的概念得到了延续和发展。现代的NLP模型通过tokenization(分词)将文本转换为token序列,再通过神经网络对token序列进行编码和解码,生成丰富的语言表示。在英语等语言中,单词之间通常用空格或标点符号分隔,因此tokenization的任务相对简单,通常可以通过识别空格和标点符号来实现。例如,给定一个英文句子"I love natural language processing!“,tokenization的结果将是:

然而,在中文等没有明显单词边界的语言中,tokenization(分词)的任务就更加复杂。中文句子中的字与字之间没有明显的分隔符,因此需要使用更复杂的方法来识别单词的边界。例如,给定一个中文句子"我爱自然语言处理!”,分词的结果可能是:

不像英文可以用空格无缝分词,中文的分词又是另一门学问了,句读的说法是古已有之。
总之,在当前的NLP实践中,tokenization是文本处理管道中不可或缺的一步。对于英语等语言,tokenization通常基于空格和标点符号进行分割。而对于中文等没有明显单词边界的语言,则需要使用更复杂的分词算法,如基于字典、统计、规则或机器学习的方法。分词的目标是将连续的文本切分成有意义的最小单元,为后续的语言理解和生成任务奠定基础。
扩展token的含义,可以详细看看这篇文章-Token在不同领域内的中文译名浅析

Embedding:
Embedding是将token或其他离散单元映射到连续向量空间的过程。
在自然语言处理中,embedding通常用于将词语映射到高维向量空间,捕捉词语之间的语义关系。例如,词嵌入(word embedding)可以将词语映射到一个密集的实数向量。
Embedding的目的是将离散的token转换为连续的向量表示,以便在神经网络和其他机器学习模型中进行处理和计算。
常见的词嵌入方法包括Word2Vec、GloVe和FastText等。这些方法通过在大规模文本语料库上训练,学习词语之间的语义关系,并生成词向量。
Token和Embedding的关系大概是这样:
Token是embedding的输入。在进行embedding之前,首先需要将文本划分为一系列的token。
Embedding是在token级别上进行的。每个token都会被映射到一个对应的向量表示。
Embedding的结果是一个向量表示,而不是token本身。Embedding将token转换为连续的向量空间中的点。
举个例子,对于前面这个句子"I love natural language processing!",分词后得到的token序列为[“I”, “love”, “natural”, “language”, “processing”, “!”]。通过embedding,每个token都会被映射到一个对应的向量表示,例如:
from gensim.models import KeyedVectors
# 加载预训练的word2vec模型(这里使用Google News语料库训练的300d词向量)
model = KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
# 输入一个句子
sentence = "I love natural language processing!"
# 将句子转换为词语列表
words = sentence.lower().split()
# 打印每个词的embedding向量
for word in words:
if word in model.vocab:
print(f"{word}: {model[word]}")
else:
print(f"{word}: 不在词汇表中")
结果可以看到像这样,每个token都被相同维度的向量来表示。
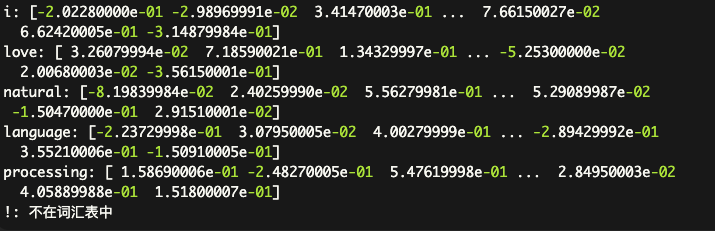
这些向量表示捕捉了token之间的语义关系,并可以用于下游的自然语言处理任务,如文本分类等等等等等