⭐️我叫忆_恒心,一名喜欢书写博客的研究生👨🎓。
如果觉得本文能帮到您,麻烦点个赞👍呗!
近期会不断在专栏里进行更新讲解博客~~~
有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三连支持一下呗。👍⭐️❤️
📂Qt5.9专栏定期更新Qt的一些项目Demo
📂项目与比赛专栏定期更新比赛的一些心得,面试项目常被问到的知识点。
欢迎评论 💬点赞👍🏻 收藏 ⭐️加关注+
解锁ChatGPT:从原理探索到GPT-2的中文实践及性能优化
引言
在当今的人工智能领域,ChatGPT已成为一个炙手可热的话题。作为OpenAI的一项革命性成果,ChatGPT不仅在理论研究上取得了突破,也在实际应用中展示了巨大潜力。本文将深入剖析ChatGPT的核心机制,探讨基于GPT-2模型的实际操作经验,以及如何通过技术手段优化模型以适应中文处理的挑战。我们将通过技术细节揭示这一前沿技术如何改变与AI的交互方式,带来更加智能化的应用体验。
- Open Ai ChatgGPT2.0源码
- GPT2 for Chinese chitchat/用于中文闲聊的GPT2模型(实现了DialoGPT的MMI思想)
一、ChatGPT架构概览
随着人工智能技术的快速发展,自然语言处理(NLP)领域的进步尤为显著。OpenAI推出的ChatGPT作为一款基于GPT(Generative Pre-training Transformer)架构的对话型AI,不仅改变了公众与AI互动的方式,也引发了学术界和工业界对其技术内核的广泛探讨。本文将深入剖析ChatGPT的基本原理,从模型结构、训练方法到实际应用等多个维度进行解读。
GPT模型概述
GPT是基于Transformer架构的预训练语言模型。它首先在大规模文本数据上进行预训练,掌握丰富的语言知识,然后在特定任务上进行微调。预训练部分主要是无监督学习,通过预测输入文本中被遮蔽的部分来学习语言规律。这种设计使得GPT模型能够生成连贯且相关性强的文本。
无论是现在的chatgpt4 还是ChatGPT4o 原理都是在基于open AI 团队的《Improving Language Understanding by Generative Pre-Training》论文。
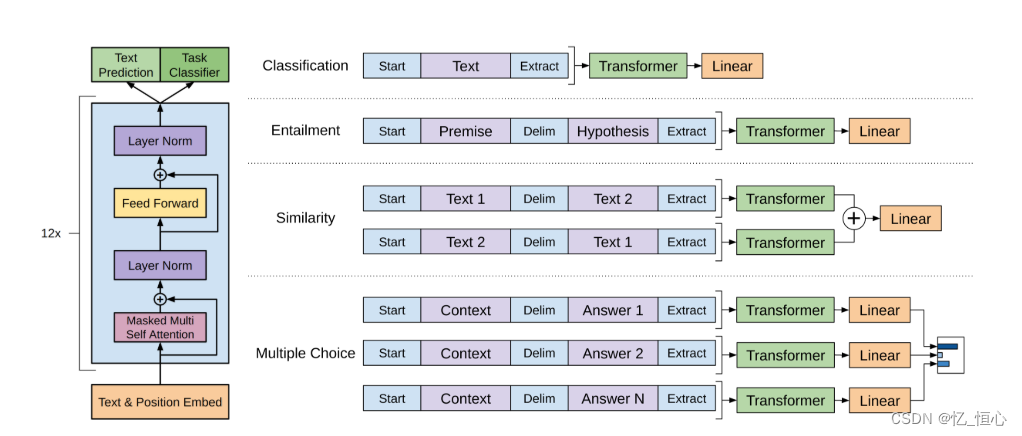
简单地来说,堆叠多个Transformer模型,不断微调,因此在早几年的,自然语言处理时,GPT论文的复现难度比较大,且成本非常高。
说到这就不得不提一下Transformer架构。
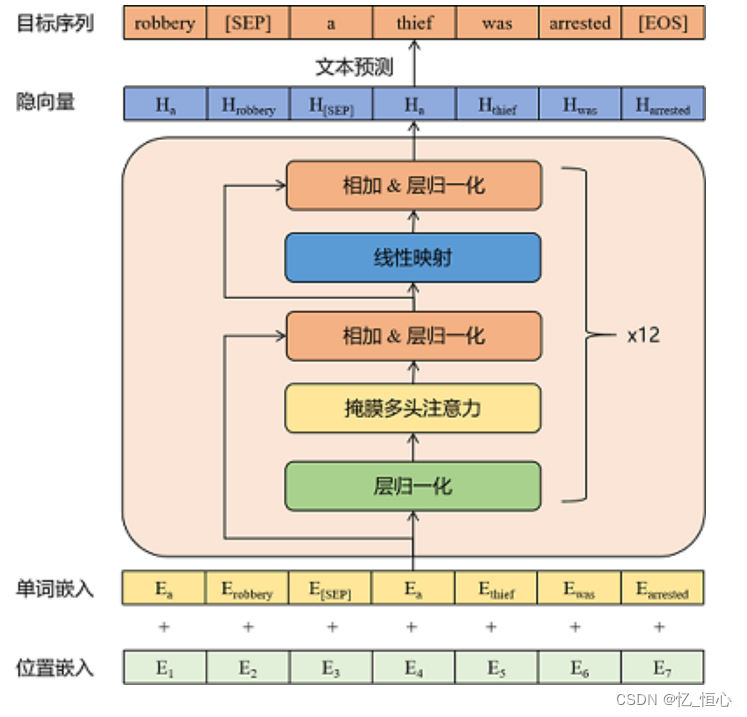
Transformer架构
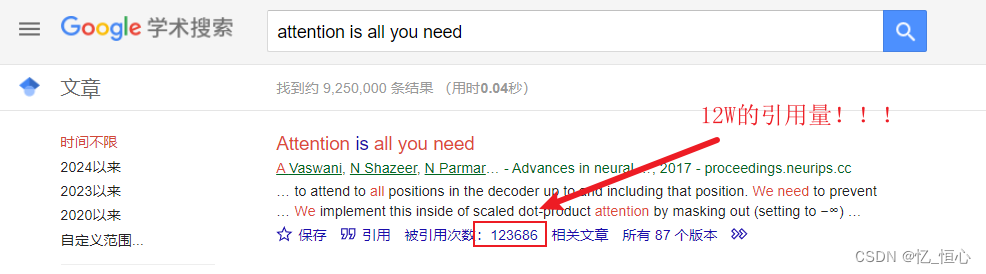
这个思路来源于《attention is all you need》,这论文现在的饮用量已经高达了12W了,非常推荐大家去读一下原文。
Transformer模型是由多个编码器(Encoder)和解码器(Decoder)层堆叠而成,是目前自然语言处理技术的核心。其核心技术是自注意力机制(Self-Attention Mechanism),允许模型在处理输入的每个单词时,考虑到句子中的其他单词,从而更好地理解语境。

简单来说,这篇论文主要介绍下面的内容:
“Attention Is All You Need”,作者是 Ashish Vaswani 等人。该论文提出了一种新的简单网络架构——Transformer,它完全基于注意力机制,摒弃了递归和卷积。在两个机器翻译任务上的实验表明,这些模型在质量上更优越,同时更具并行性,训练所需的时间也显著减少。
- 引言:
- 介绍了序列转导模型的背景和现状,以及递归神经网络和注意力机制的应用。
- 提出了 Transformer 模型,它是一种基于注意力机制的新型序列转导模型,摒弃了递归和卷积。
- 背景:
- 介绍了减少序列计算的目标,以及 Extended Neural GPU、ByteNet 和 ConvS2S 等模型的基础。
- 讨论了自我注意机制的应用,包括阅读理解、抽象摘要、文本蕴涵和学习与任务无关的句子表示等。
- 介绍了端到端记忆网络的基于循环注意力机制,而不是序列对齐的递归。
- 模型架构:
- 描述了 Transformer 模型的总体架构,包括编码器和解码器堆栈,以及它们的组成部分。
- 详细介绍了编码器和解码器中的每个层,包括多头自注意力机制、位置前馈网络、嵌入层和 softmax 层。
- 解释了如何使用位置编码来注入序列的顺序信息,以及如何使用多头注意力来并行处理不同位置的信息。
- 为什么使用自我注意:
- 比较了自我注意层与递归和卷积层在计算复杂性、并行性和长程依赖学习方面的差异。
- 解释了为什么自我注意可以更好地处理长序列数据,以及如何通过限制自我注意的范围来提高计算效率。
- 讨论了自我注意可能产生更可解释模型的原因,并通过示例展示了注意力分布的可视化。
- 训练:
- 描述了训练 Transformer 模型的数据集和批处理方法,以及硬件和时间表。
- 介绍了使用的优化器和学习率调度,以及正则化方法,包括残差 dropout 和标签平滑。
- 结果:
- 报告了 Transformer 模型在英语到德语和英语到法语翻译任务上的性能,与以前的最先进模型进行了比较。
- 分析了不同模型变体的性能,包括多头数量、注意力键和值维度、模型大小和 dropout 率等。
- 讨论了结果的意义和潜在的应用,以及未来的研究方向。
- 结论:
- 总结了 Transformer 模型的主要贡献,包括基于注意力机制的新型序列转导模型、在机器翻译任务上的优越性能、更具并行性和可扩展性、以及可能产生更可解释模型的潜力。
- 讨论了未来的研究方向,包括将 Transformer 扩展到其他任务和模态、研究局部和受限注意力机制、以及提高生成的非顺序性。
总的来说,该论文提出了一种基于注意力机制的新型序列转导模型——Transformer,它在机器翻译任务上取得了优越的性能,同时具有更具并行性和可扩展性的优点。未来的研究方向包括将
Transformer 扩展到其他任务和模态,以及研究更高效的注意力机制和训练方法。
二、模型训练与微调
ChatGPT目前并没有进行开源,但是如果从深度解析原来来看,我们完全可以通过GPT2.0 来完成学习。
GPT-2的预训练阶段,模型使用一个非常大的数据集进行训练,这些数据集包括从网上收集的8百万个网页的文本。预训练的目标是让模型学会语言的统计规律,通过预测给定文本片段中的下一个单词来进行。
预训练过程:
- 数据收集: 搜集各类文本数据如书籍、网页、新闻。
- 训练目标: 预测文本中的下一个词汇。
微调过程:
- 特定数据: 使用对话型数据集进行优化,提升模型的对话能力。
- 调整目标: 提高生成对话的连贯性和相关性。
代码示例(伪代码):
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel, AdamW
# 加载预训练模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
optimizer = AdamW(model.parameters(), lr=5e-5)
# 示例文本输入
input_ids = tokenizer.encode("Sample text input:", return_tensors='pt')
# 微调模型
for _ in range(100):
outputs = model(input_ids, labels=input_ids)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
三、实际应用与性能优化
在实际应用中,ChatGPT可服务于多种业务场景,如自动客服、内容推荐、自动编程辅助等。针对具体任务,可能需要通过模型剪枝来降低模型大小,或使用量化技术减少计算资源的消耗,从而提高响应速度和处理效率。这些技术帮助部署在资源受限的环境中,同时保持良好的性能。
可以用于中文模型进行训练,
GPT2 for Chinese chitchat/用于中文闲聊的GPT2模型(实现了DialoGPT的MMI思想)
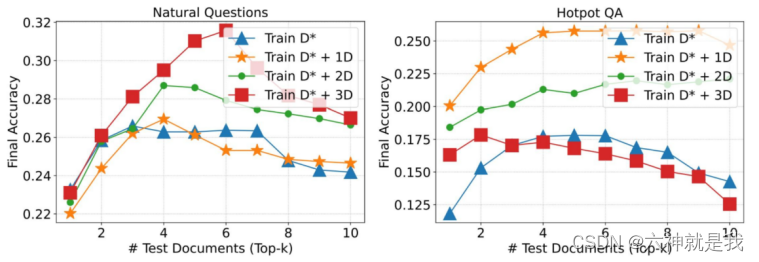
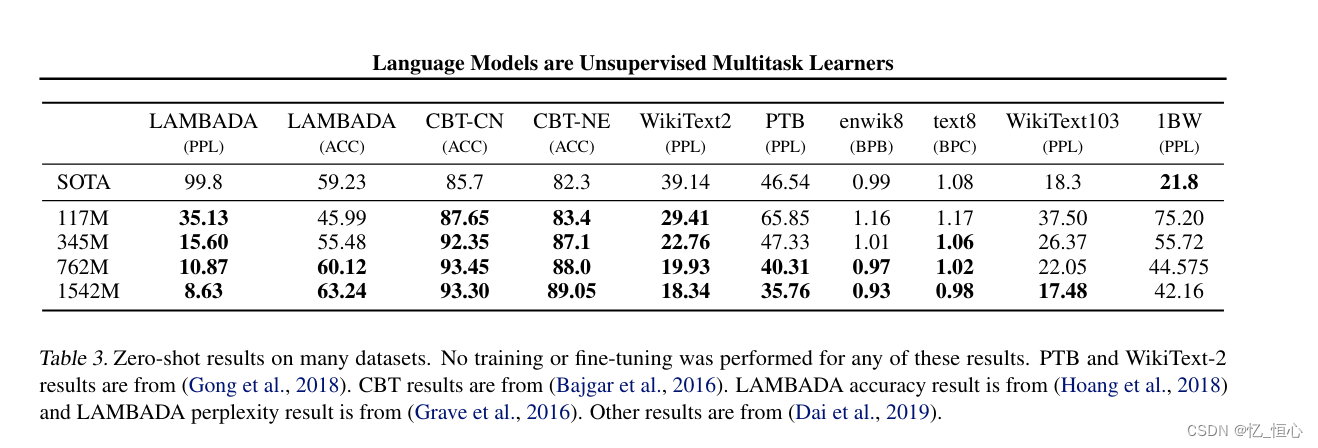
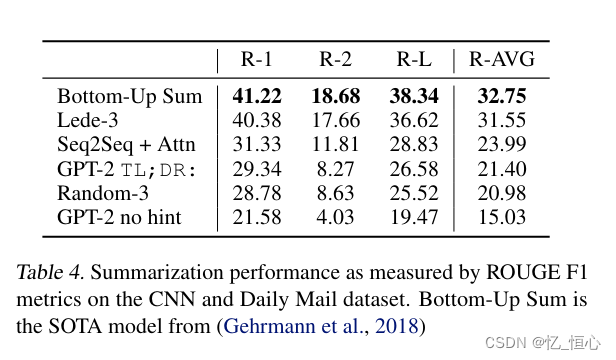
实验效果图:
可以选择其中几个感兴趣的任务来跑即可。
在使用ChatGPT时,确保内容的安全性和合规性至关重要,例如限制生成有害内容和保护用户隐私。
总结
通过深入探索ChatGPT的架构、训练过程和应用场景,我们可以更好地理解并利用这项技术。希望本文能为读者提供有价值的见解和帮助。
往期优秀文章推荐:
- 研究生入门工具——让你事半功倍的SCI、EI论文写作神器
- 磕磕绊绊的双非硕秋招之路小结
- 研一学习笔记-小白NLP入门学习笔记
- C++ LinuxWebServer 2万7千字的面经长文(上)
- C++Qt5.9学习笔记-事件1.5W字总结
资料、源码获取以及更多粉丝福利,可以关注下