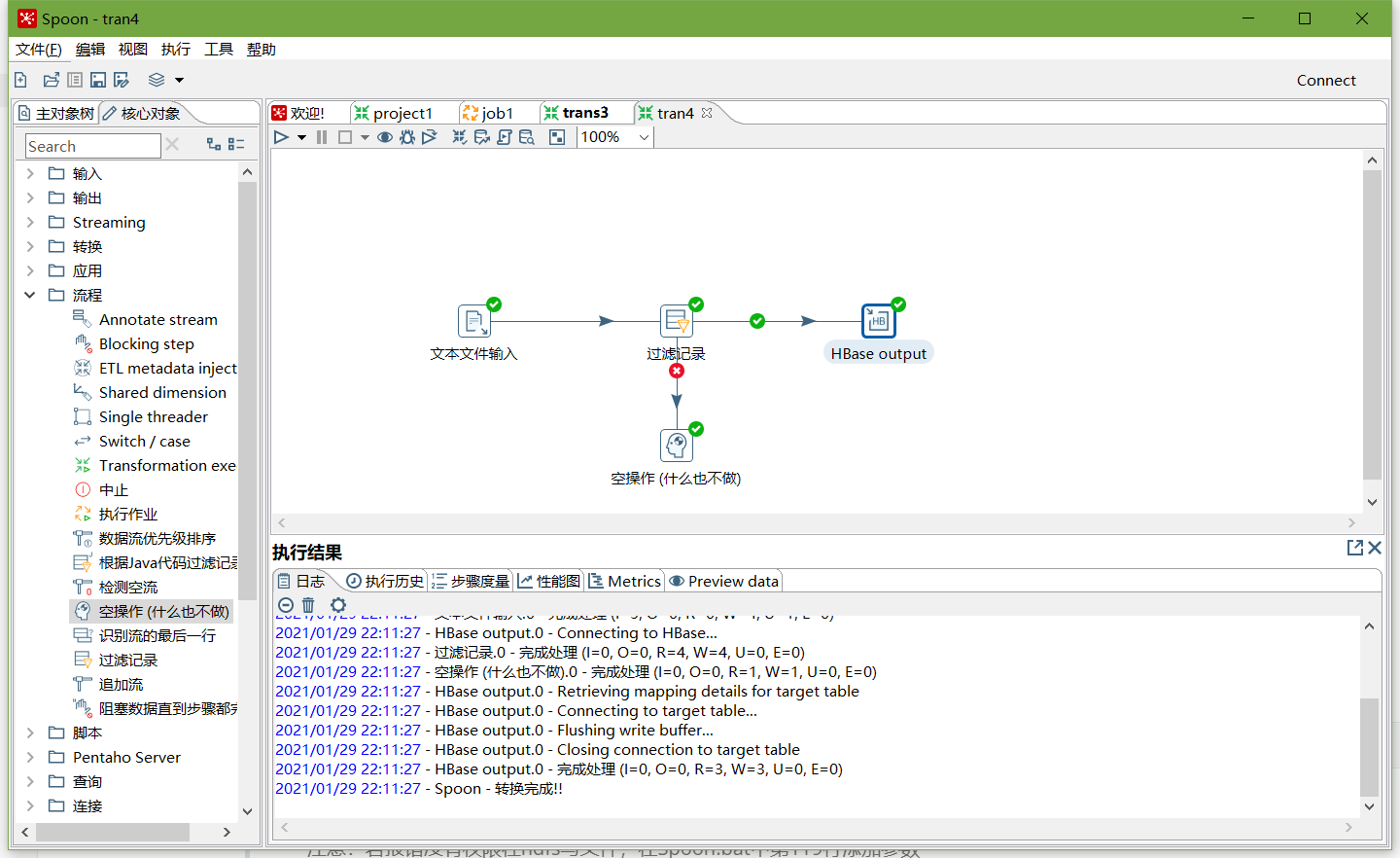
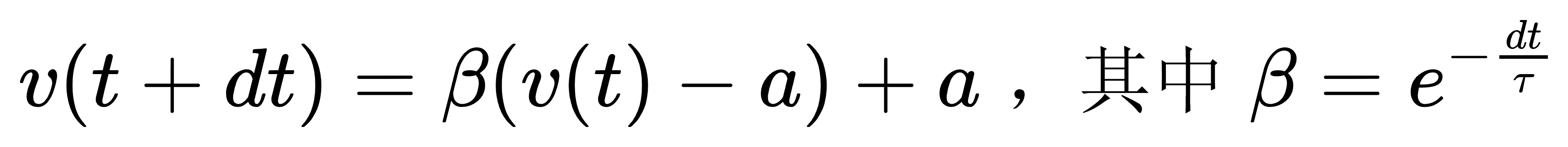最近看了一篇苏神的文章,对多模态LLM的设计思考很有启发,总结如下,原文可参考“闭门造车”之多模态模型方案浅谈 - 科学空间|Scientific Spaces
多模态模型要解决什么问题
视频生成、文生图这些内容,图文混合的双模态输入输出,能够使得模型更加理解人类的认知,解决多模态场景下的任务。
多模态背后的数学基础
本质上建模的理论基础是条件概率,最初的n-gram语言模型,还是后来的Seq2Seq、GPT,都是这个条件概率的近似。
文本和图像生成区别
- 1、文本方向明确。人们对“实现文本生成需要往哪个方向走”是很明确的,只是背后所用的模型有所不同,如LSTM、CNN、Attention乃至最近复兴的线性RNN等。图像则不然,如VAE、GAN、Flow、Diffusion,还有小众的EMB、PixelRNN/PixelCNN等,这些方法的区分,并不是因为它们用了RNN、CNN或者Attention导致效果上的不同,而是建模理论就有根本差别。
- 2、图像生成手段多样化的根本原因,是对连续变量进行概率建模的困难性。文本生成可以看做分类任务,求当前条件下各个类别最大概率,而图像由于是连续型变量,即所求概率变换为概率密度函数,需要满足以下条件:
神经网络是函数的万能拟合器,但不是概率密度的万能拟合器,这就是连续型变量做生成建模的本质困难,而图像生成的各种方案,本质上都是“各显神通”来绕过对概率密度的直接建模(除了Flow)。虽然正态分布满足条件,但并不足以拟合任意复杂的分布。
- 3、离散型变量不存在这个困难,因为离散型概率的约束是求和为1,通过Softmax可以实现。因此目前主流思路即将图像离散化,然后套用文本生成模型,实现多模态生成。
工程化难点
1、由于序列太长,生成时效性问题,无法在像素空间上直接生成。因此,需要进行先压缩后生成。
2、压缩需要考虑进行无损压缩,存在压缩损失问题。在一个真正通用的多模态模型中,图像部分必然要比文本部分要困难得多,因为图像的信息量远大于文字。但其实人类自己创造的图像(比如画画)也不会比文字(比如写作)复杂多少,真正复杂的图像,是直接采集自大自然的照片。所以归根结底,文字只是人类的产物,而图像是大自然的产物,人不如自然聪明,所以文字也不如图像难,而真正通用的人工智能,本就是要往全面碾压人类的方向走的。
3、由于压缩后的编码空间时二维信息,需要人工设计生成方向。比如先左右后上下、先上下后左右、从中心逆时针到四周、按照到左上角的距离排序等等。不同的生成方向可能会明显影响生成效果,这就引入了额外的超参。当然针对这个问题,可以用Cross Attention的方式对二维特征进行组合,输出只有单一方向的编码结果。
总结
关于多模态模型设计的构思——直接以原始图像的Patch作为图像输入,文本部分还是常规预测下一个Token,图像部分则用输入加噪图像来重构原图,这种组合理论上能以最保真的方式实现多模态生成。初步来看,直接以原始图像的Patch作为输入的Transformer,是有可能训练出成功的图像扩散模型的,那么这种扩散与文本混合的模型设计,也就有成功的可能了。