1.Collection接口
collection接口是Java最基本的集合接口,它定义了一组允许重复的对象。它虽然不能直接创建实例,但是它派生了两个字接口List和Set,可以使用子接口的实现类创建实例。Collection 接口是抽取List接口和Set接口共同的存储特点和操作方法进行的重构设计。Collection接口提供了操作集合以及集合中元素的方法。Collection接口的常用方法如下表:
| 方法声明 | 功能描述 |
| boolean add(Object obj) | 向集合中添加一个元素 |
| boolean addAll(Collection c) | 将指定集合中所有元素添加到当前集合中 |
| void clear() | 清空集合中的所有元素 |
| boolean contains(Object obj) | 判断集合中是否包括某个元素 |
| boolean containsAll(Collection c) | 判断集合中是否包含指定集合中的所有元素 |
| Iterator iterator() | 返回在Collection的元素上进行迭代的迭代器 |
| boolean remove(Object o) | 删除集合中的指定元素 |
| boolean removeAll(Object o) | 删除指定集合中所有元素 |
| boolean retainAll(Collection c) | 仅保留当前Collection中那些也包含在指定Collection的元素 |
| Object[] toArray() | 返回包含Collection中所有元素的数组 |
| boolean isEmpty() | 如果集合为空,则返回true |
| int size() | 返回集合中元素个数 |
图示方法是集合的共性方法,这些方法即可以操作List集合,又可以操作Set集合。
2.List接口
List接口是单列集合的一个重要分支,一般将实现了List接口的对象称为List集合。List集合中的元素是有序且可重复的,相当于数学里面的数列,有序、可重复。List集合的List接口记录元素的先后添加顺序,使用此接口能够精确地控制每个元素插入的位置,用户也可以通过索引来访问集合中的指定元素。
List接口作为Collection接口的子接口,不但继承了Collection的所有方法,而且增加了一些操作List集合的特有方法,如下表:
| 方法声明 | 功能描述 |
| void add(int index,Object element) | 在index位置插入element元素 |
| Object get(int index) | 得到index出的元素 |
| Object set(int index ,Object element) | 用element替换index位置的元素 |
| Object remove(int index) | 移除index位置的元素,并返回元素 |
| int indexOf(Object o) | 返回集合中第一次出现o的索引,若集合中不包含该元素,则返回-1 |
| int lastIndex(Object o) | 返回集合中最后一次出现o的索引,若集合中不包含该元素,返回-1 |
上表列出了List接口的常用方法,所有List实现类都可以通过调用这些方法对集合元素进行操作。
创建一个List对象的语法格式如下:
List 变量 =new 实现类();3.1ArrayList类
ArrayList类是动态数组,用MSDN中的说法,就是数组的复杂版本,它提供了动态增加和减少元素的方法,继承AbstractList类,实现了List接口,提供了相关的添加、删除、修改、遍历等功能,具有灵活地设置数组大小的优点。ArrayList实现了长度可变的数组,在内存中分配连续的空间,允许不同类型的元素共存。ArrayList类能够根据索引位置快速地访问集合中的元素,因此,ArrayList集合遍历元素和随机访问元素的效率比较高。
ArrayList类中大部分方法都是从List接口继承过来的。
ArrayList的底层使用数组来保存元素的,用自动扩容机制实现动态增加容量。因为它的底层是用数组实现的,所以插入和删除操作的效率不佳,不建议用ArrayList做大量的增删操作。但是由于它有索引,所以查询效率很高,适合用来做大量查询操作。
3.2LinkedList类
为克服ArrayList集合查询速度快,增删速度慢的问题,可以使用LinkedList实现类。
LinkedList底层的数据结构是基于双向链表的,它的底层实际上是由若干个相连的Node节点组成的,每个Node节点都包含该节点的数据、前一个结点、后一个节点。LinkedList集合添加元素如图①,LinkedList集合添加元素如图②。
①
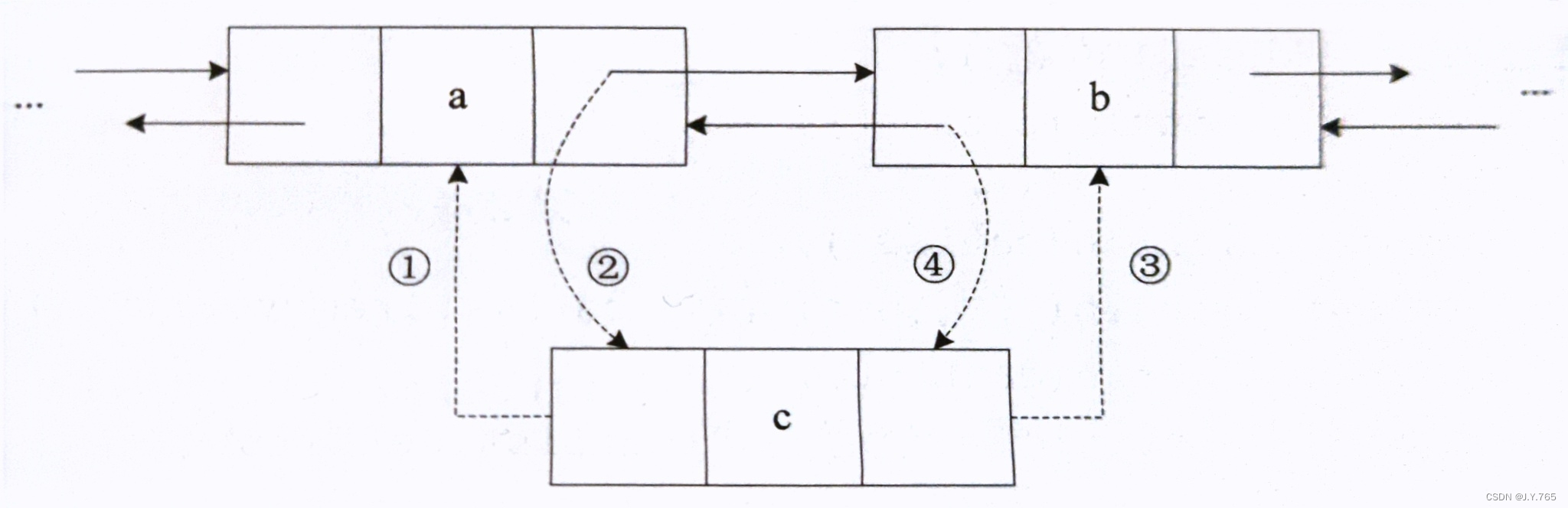
②

和ArrayList使用数据结构不同的是,链表结构的优势在于大量数据的添加和删除,但并不擅长依赖索引 的查询,因此,LinkedList在执行像插入或者删除这样的操作时,效率是很高的,但是随机访问方面就弱了很多。
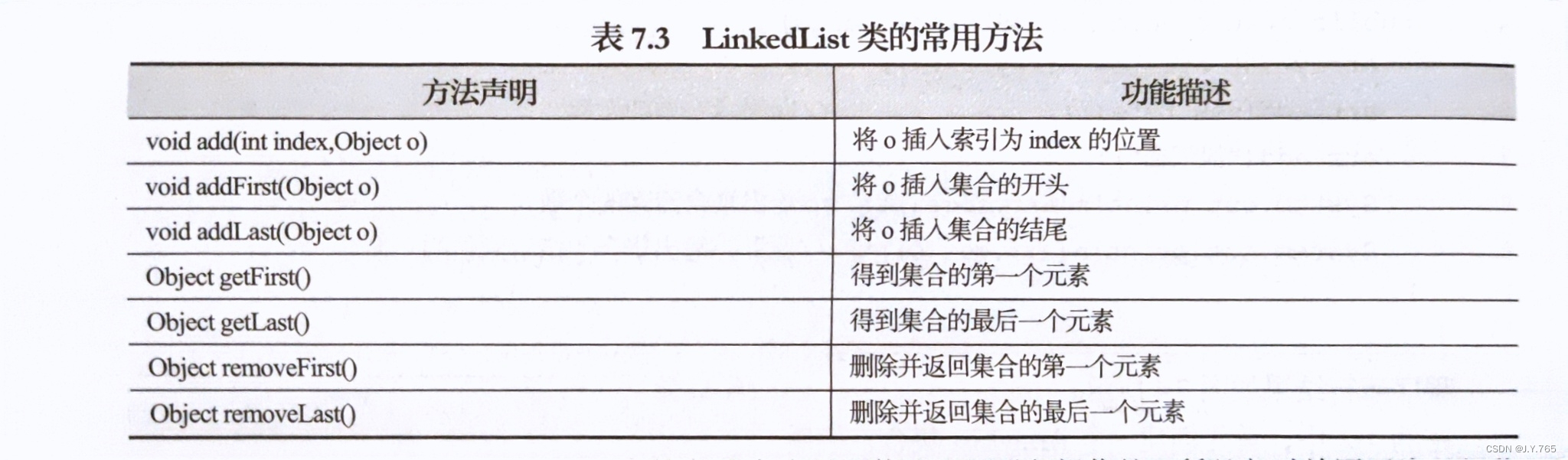
如图示,LinkedList类的方法大多是围绕头尾进行操作的,所以他对首尾元素的操作效率高。
4.集合的迭代操作
4.1Iterator接口
Java提供了一个专门用于遍历集合的接口--Iterator,它是用来迭代访问Colllection中元素的,因此也称为迭代器。通过Collection接口中的iterator()方法可以得到集合的迭代器对象,只要拿到这个对象,使用迭代器就可以遍历集合。
TestIterator.java
public class TestIterator{
public static void main(String[] args){
List catList=new ArrayList(); //创建流浪猫集合
Cat catl=new Cat("小哺",'母',"橘猫","收留");
Cat cat2=new Cat("小米",'公',"三花","收留");
Cat cat3=new Cat("小",'母”,"奶牛,"领养");
catList.add(cat1);
catList.add(cat2);
catList.add(cat3);
Iterator iterator=catList.iterator(); //获取Iterator 对象
while(iterator.hasNext()){ //判断集合中是否存在下一个元素
Cat ele=(Cat)iterator.next(); //输出集合中的元素
System.out.println(ele);
}
}
}调用ArrayList的iterator()方法获得迭代器的对象,然后使用hasNext()方法判断集合中是否存在下一个元素,若存在,则通过next()方法取出。这里要注意,通过next()方法获取去元素时,必须调用hasNext()方法检测是否存在下一个元素,若元素不存在,会抛出NoSuchElementException异常。Iterator仅用于遍历集合,如果需要创建对象,则必须有一个被迭代的集合。
在Iterator使用next()方法之前,迭代器游标在第一个元素之前,不知想任何元素,在第一次调用next()方法后,迭代器游标会后移一位,指向第一个元素并返回,依此类推,当hasNext()方法返回false时,则说明达到集合末尾,停止遍历。
4.2foreach遍历集合
Java还提供了一种很简洁的遍历方法,即使用foreach循环遍历集合,它既能遍历普通数组,也能遍历集合。其语法格式如下:
for(容器中元素类型 临时变量:容器变量){
代码块
}从上述语法格式可以看出,与普通的for循环不同的是,foreach循环不需要获取容器的长度,不需要用索引去访问容器中元素,但是它能自动遍历容器中所有元素。
5.Set接口
Set接口是单列集合的一个重要分支,一般将实现了Set接口的对象称为Set集合。Set集合中元素是无序的、不可重复的。严格地说,是没有按照元素的插入顺序排列。
Set集合判断两个元素是否相等用equals()方法,而不是使用“=”运算符。如果两个对象比较就,equals()返回true,则Set集合是不会接受这两个对象的。Set集合可以储存null,但是只能储存一个,即使添加多个也只能储存一个。
Set接口也继承了Collection接口,但是它没有对Collectionjk的方法进行扩充。Set接口的主要实现类是HashSet和TreeSet。其中,HashSet根据对象的哈希值来确定元素在集合中的存储位置,能高效的查询,可以用来做少量数据的插入操作;TreeSet底层是 用二叉树来实现存储元素的,它可以对集合中的元素进行排序。
5.1HashSet类
HashSet按照Hash算法来确对象在集合中的储存位置。因此,具有很好的存取和查找性能。Set集合和List集合存取元素的方式是一样的。
 5.2TreeSet类
5.2TreeSet类
TreeSet集合和HashSet集合都可以保证容器内元素的唯一性,但是它们底层实现方式不同,TreeSet底层是用自平衡的排序二叉树实现的,所以它既能保证元素的唯一性,又可以对元素进行排序。TreeSet类还提供一些特有的方法,如下表示:
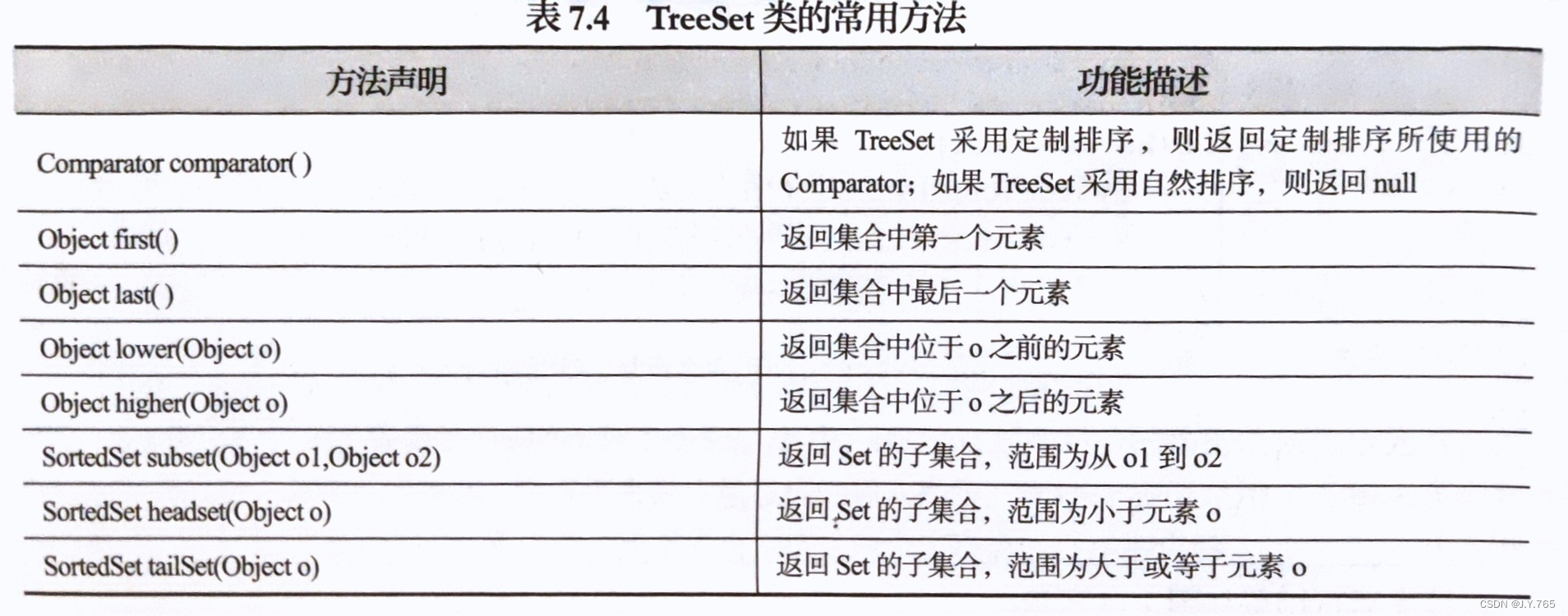
TreeSet有两种排序方法:自然排序和定制排序。默认情况下,TreeSet采用自然排序。
1.自然排序
TreeSet类会调用集合元素的comparable(Object obj)方法来比较元素的大小,然后将集合内的元素按升序排序,这是自然排序。
Java提供了Comparable接口,它里面定义了一个comparableTo(Object obj),实现Comparable接口必须实现该方法,在方法中实现对象大小比较。当该方法被调用时,如obj1.compare To(obj2),若该方法返回0,则说明obj1和obj2相等;若该方法返回一个正数,则说明obj1大于obj2;若该方法返回一个负数,则说明obj1小于obj2.
如果把一个对象添加到TreeSet集合,则该对象必须实现Comparable接口,否则程序会抛出ClassCastException异常。
另外,向TreeSet集合中添加的应该是同一个类的对象,否则运行结果也会报ClassCastException异常。
2.定制排序
TreeSet的自然排序根据集合元素大小,按升序排序,如果需要按特殊规则排序或者元素本身不具备比较性,比如按降序排列,这时候就需要用到定制排序。Comparator接口包含一个int compare(T t1,T t2)方法,该方法可以比较t1和t2大小,返回正整数,则说明t1大于t2;若返回0,则说明t1等于t2;若返回负整数,则说明t1小于t2.
要实现TreeSet的定制排序,只需在创建TreeSet对象时,提供Comparator对象与该集合关联,并在Comparator中编写排序逻辑。
import java.util.*;
public class TestTreeSetSort{
public static void main(string[] args){
//创建TreeSet集合对象时,提供一个Comparator对象
TreeSet tree=new TreeSet(new MyComparator ());
tree.add(new Student(140));
tree.add(new Student(15));
tree.add(new Student(11));
system.out.println(tree);
}
}
Class Student{
//定义Student类
private Integer age;
public Student (Integer age){
this.age=age;
}
public Integer getAge(){
return age;
}
public void setAge (Integer age){
this.age=age;
}
public String toString(){
return age+"";
}
}
class MyComparator implements Comparator{ //实现Comparator接口
//实现一个campare方法, 判断对象是否是特定类的一个实例
public int compare (Object o1,0bject o2){
if(o1 instanceof Student&o2 instanceof Student){
Student s1=(Student)o1; //强制转换为Student类型
Students2=(Student) o2;
if(s1.getAge()>s2.getAge()){
return -1;
}elseif(s1.getAge()<s2.getAge()){
return 1;
}
}
return 0;
}
}
6.Map接口
6.1Map简介
Map接口不继承Collection接口,它与Collection接口是并列存在的,用于存储键值对形式的元素,描述了由于不重复的键到值的映射。
Map中key和value都可以是任何引用类型的的数据。Map中key用Set来存放,不允许重复,及同一个Map对象所对应的类,必须重写hashCode()方法和equals()方法。通常用String类作为Map的key,key和value之间存在一对一的关系,即通过指定的key总能遭到唯一的、确定的value。Map接口的方法如下图示:
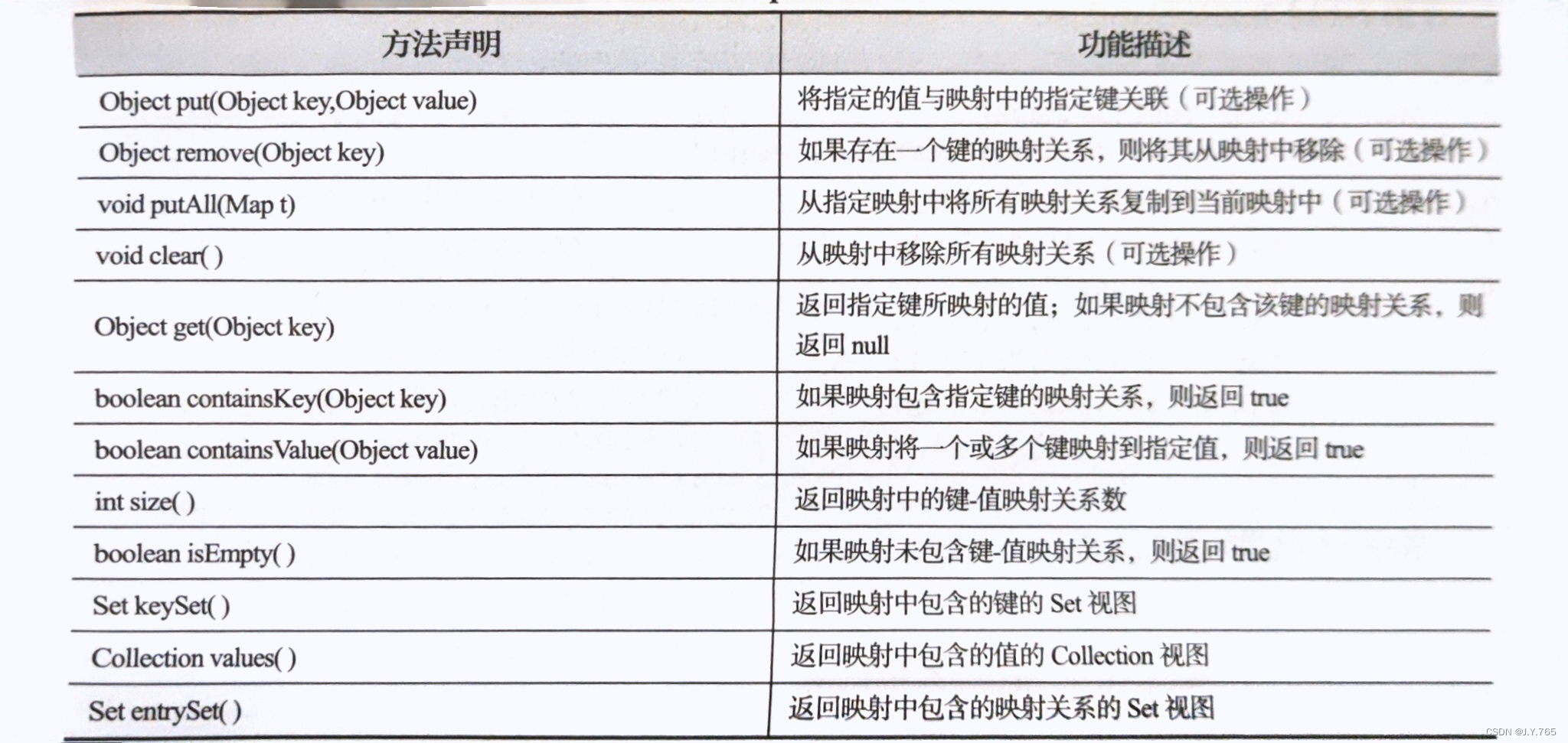
6.2HashMap类
HashMap类是Map接口中使用频率最高的实现类,允许使用null键和null值,与HashSet集合一样,不保证映射的顺序。HashMap集合判断两个key相等的标准:两个key通过equals()方法返回true,hashCode值也相等。HashMap集合判断两个value相等的标准:两个value通过equals()方法返回true。由于HashMap集合中的键是用Set来储存的,所以不可以重复。
当键重复时,后添加元素的值,覆盖了先添加的元素的值,简单来说就是键相同,值覆盖。
遍历Map的方式有两种,第一种是先遍历所有的键,再根据键获得对应的值。第二种遍历方式是先获得集合所有的映射关系,然后再根据映射关系获取键和值。
6.3LinkedHashMap类
LinkedHashMap类是HashMap的子类,LinkedHashMap类可以维护Map的迭代顺序,迭代顺序与键值插入顺序一致。如果需要输出顺序与输入时顺序相同,那么就用LinkedHashMap集合。
6.4Properties类
Map接口中有一个古老的、线程安全的实现类--Hashtable,与HashMap集合相同的是,他也不能保证其中键值对的顺序,他判断两个键、两个值相等的标准与HashMap集合一样,与HashMap集合不同的是,他不允许使用null作为键和值。
Hashtable类存取元素速度较慢,目前基本被HashMap类代替,但是他有一个子类Properties在实际开发中 很常用,该子类对象处理文件,由于属性文件里的键和值都是字符串类型的,所以Properties类的键和值都是字符串类型的。
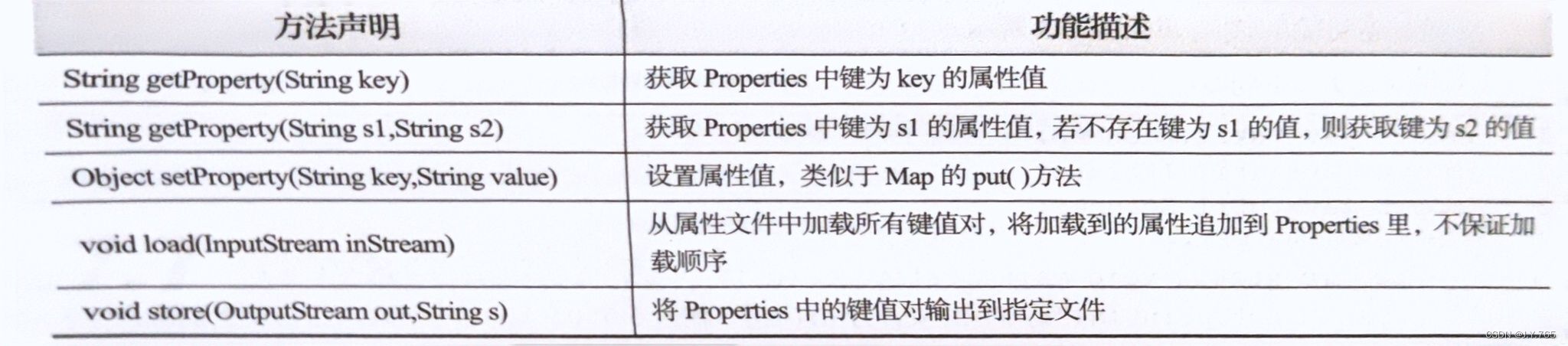
7.1为什么要使用泛型
为了解决数据类型的安全性问题,其主要原理是在类声明时通过一个标识,表示类中某个属性的类型或者是某个方法的返回值及参数类型。这样在类声明或者实例化时只要指定好需要的具体类型即可。
Java泛型可以保证程序在编译时如果没有发出警告,运行时就不会报ClassCastException异常,同时,代码更加简洁、健壮。
7.2泛型的定义
在定义泛型时,使用“<参数化类型>”的方式指定集合中方法操作的数据类型,具体示例如下。
ArrayList <参数化类型> list =new ArrayList<参数化类型>();在创建集合的时候,如果指定了泛型为String类型,该集合只能添加String类型的元素,编译文件时,不再出现类型安全警告,如果向集合中添加非String类型的元素,则会报编译时异常。
7.3通配符
这里要引入一个通配符的概念,类型通配符用符号“ ?”表示,比如List<?>,它是List<String>、List<Object>等各种泛型的父类。
import java.util.*;
public class TestGeneric2{
public static void main(String[] args){
//声明泛型类型为“?”
List<?> list=null;
list=new ArrayList<String>();
list=new ArrayList<Integer>(); //编译时报错
//list.add(3);
list.add(null); //添加元素null
System.out.println(list);
List<Integer> 11=new ArrayList<Integer>();
List<String>l2=new ArrayList<String>();
l1.add(1000);
12.add("phone");
read(ll);
read(l2);
}
static void read(List<?> list){
for(0bjecto:list){
System.out.println(0);
}
}
}先声明List的泛型类型为“ ?”,然后在创建对象实例时,泛型类型设为String或者Integer都不会报错,这体现了泛型的可扩展性,此时向集合中添加元素会报错,因为List的元素类型无法确定,唯一的例外是null,它是所有类型的成员。
另外,在方法read()的参数声明中,List参数也应用了泛型类型“?”,所以使用此静态方法能接收多种类型。
7.4自定义泛型
假设要实现一个简单的容器,用于保存某个值,这个容器应该定义两个方法--get()方法和set(),前者用于取值,后者用于存值,如法格式如下:
void set(参数类型 参数){...}
返回值 参数类型 get(){...}