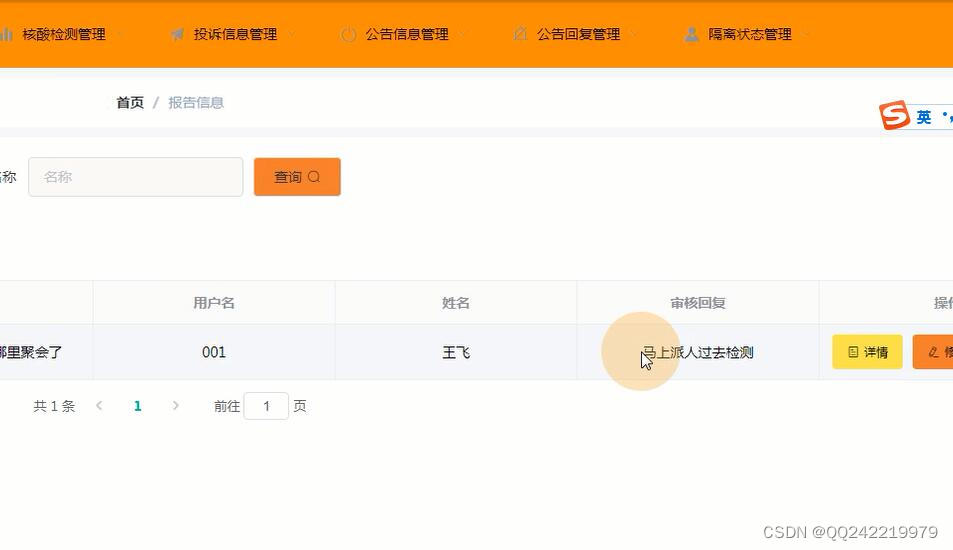
研究问题
将基于记忆的方法与预训练语言模型相结合,以完成知识图谱补全任务
背景动机
- 传统模型无法处理未见实体
- 记忆增强神经网络的相关进展,即在传统的计算模块之外添加单独的记忆存储模块
模型方法
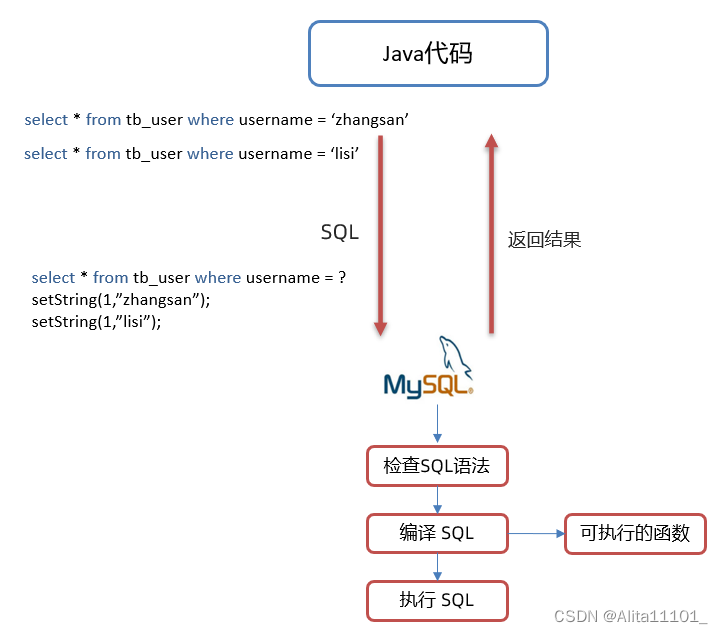
首先使用预训练语言模型构建实体的知识库,并根据嵌入距离查找其最近邻居,将记忆搜索与语言模型预测的结果插值结合
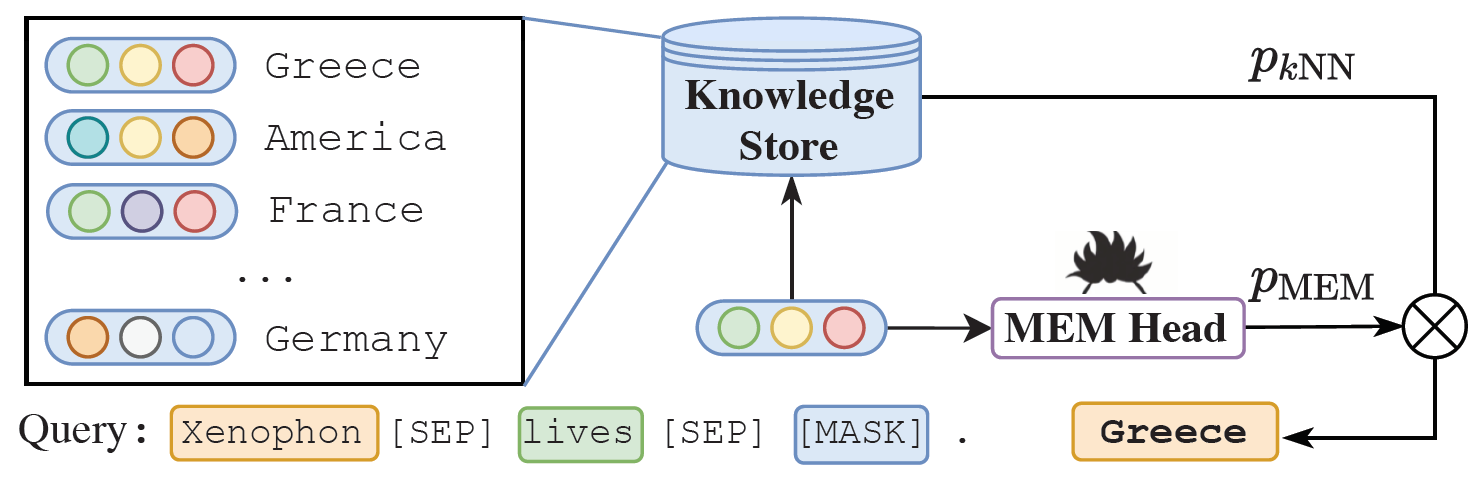
Masked Entity Modeling

对于每个三元组查询 ( e i , r j , ? ) \left(e_i, r_j, ?\right) (ei,rj,?)及实体 e i e_i ei的描述 d d d,获得如下的查询语句:
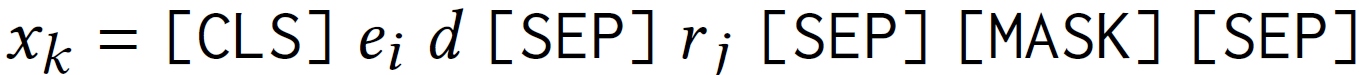
接下来计算mask位置对应不同实体的词的概率:
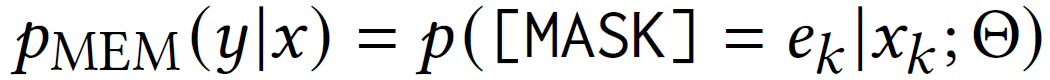
最终的损失函数即为分类器损失函数:
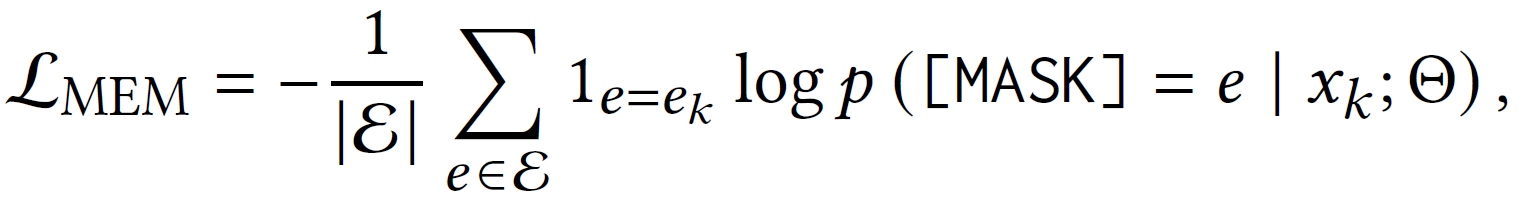
Entity Vocabulary Expansion
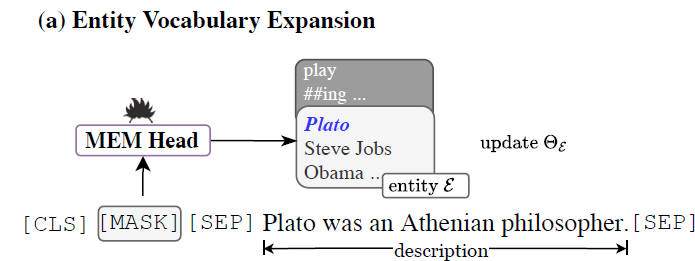
这一步其实是对上一步的预处理,因为预训练语言模型在编码阶段会将一个词拆解为若干sub token,因此无法将其输出的token概率与实体完全对齐。为了能让每个实体拥有一个唯一对应的概率,就需要对语料库进行扩展。扩展的方式是加入所谓的special tokens,为了让special tokens有明确的语义,还需要加入以下的预训练任务。
对于每个实体及其描述,获得以下查询语句:
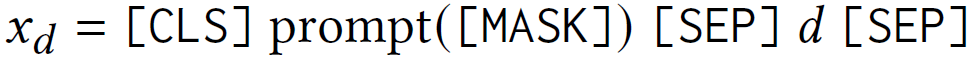
预训练目标损失:
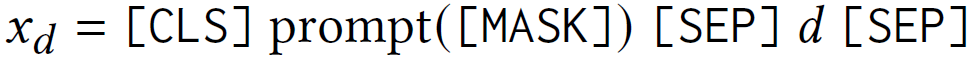
词表扩展相关代码
def get_entities(self, data_dir):
"""Gets all entities in the knowledge graph."""
with open(self.entity_path, 'r') as f:
lines = f.readlines()
entities = []
for line in lines:
entities.append(line.strip().split("\t")[0])
ent2token = {ent : f"[ENTITY_{i}]" for i, ent in enumerate(entities)}
return list(ent2token.values())
entity_list = self.processor.get_entities(args.data_dir)
num_added_tokens = self.tokenizer.add_special_tokens({'additional_special_tokens': entity_list})
Knowledge Store
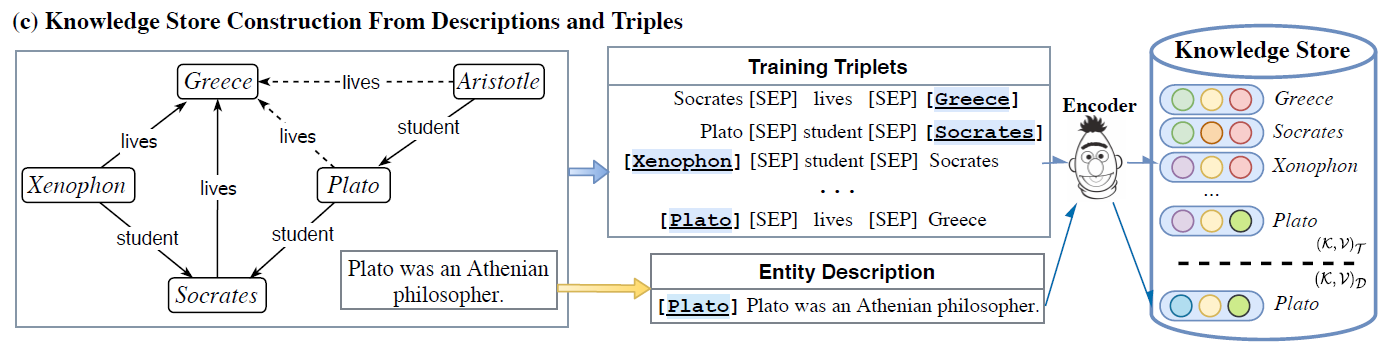
从包含语义信息的实体描述和包含结构信息的实体三元组两方面来构建知识库
实体描述部分取的就是Entity Vocabulary Expansion部分学习到的嵌入表示
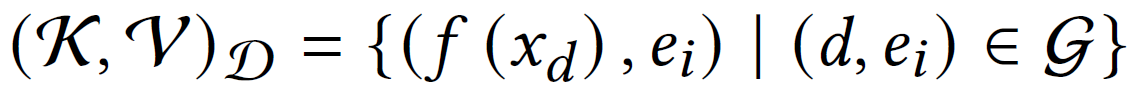
三元组部分就是把所有包含目标实体的三元组对应的嵌入加入库中
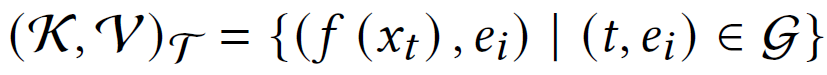
知识库中以(k,v)对的形式存储实体与嵌入的关系,其中k是基于描述或三元组的嵌入,v是对应实体的名称,论文使用开源的FAISS来执行高维空间的检索算法。
记忆推理
给定一个三元组查询,通过Masked Entity Modeling方法得到缺失实体的嵌入表示
h
[
m
a
s
k
]
h_{[mask]}
h[mask],嵌入间的距离定义如下:
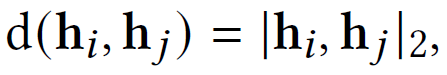
knn算法用嵌入距离来表征候选实体为目标实体的概率,注意到由于每个候选实体会有几个不同的嵌入表示,最终只取距离最近的那一个:
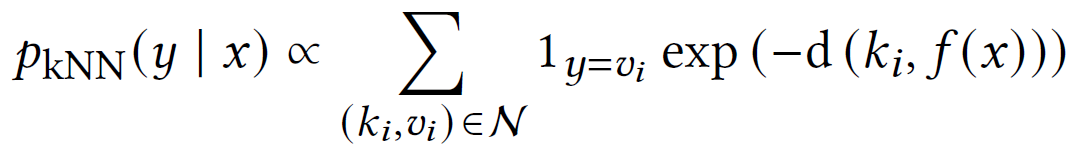
最终结果为二者的加权和
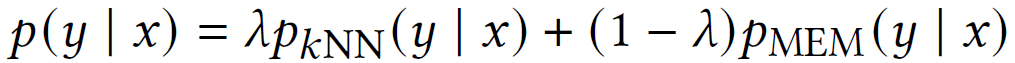
实验结果
链路预测
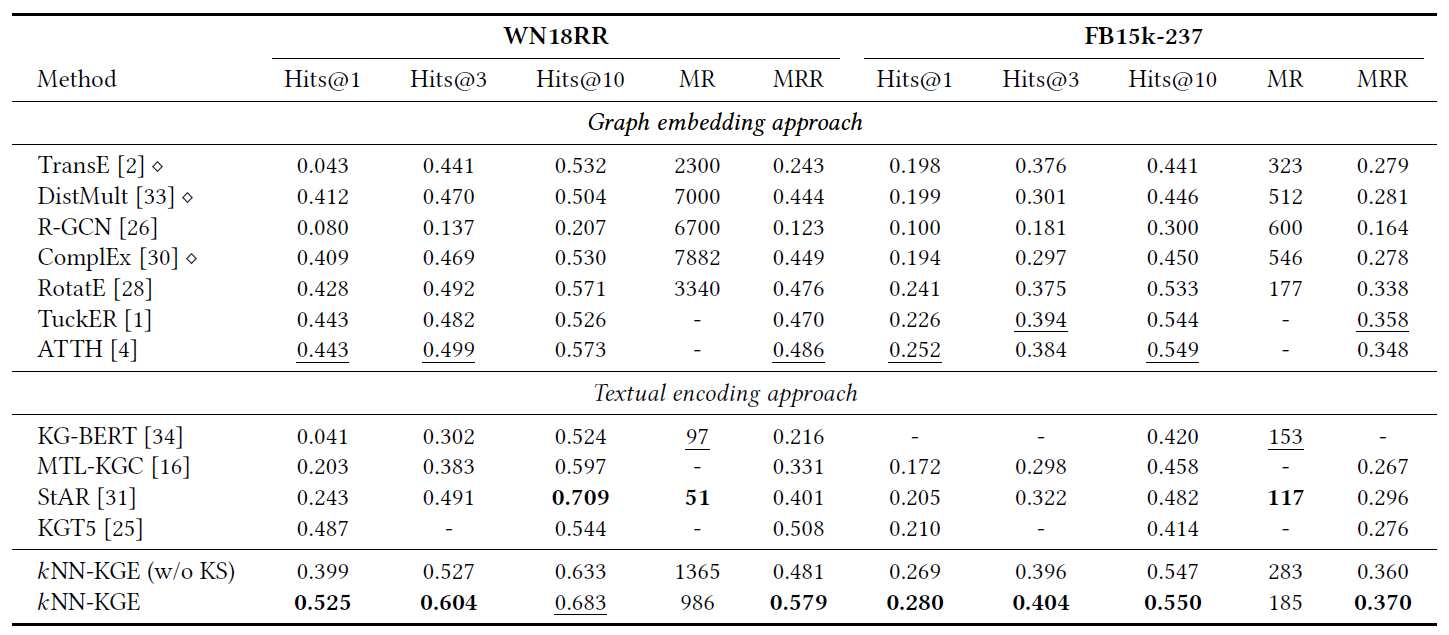
KS即KNN部分
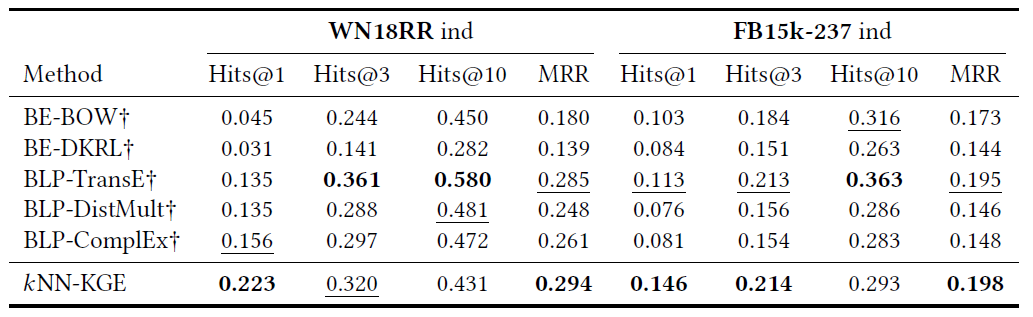
低资源场景
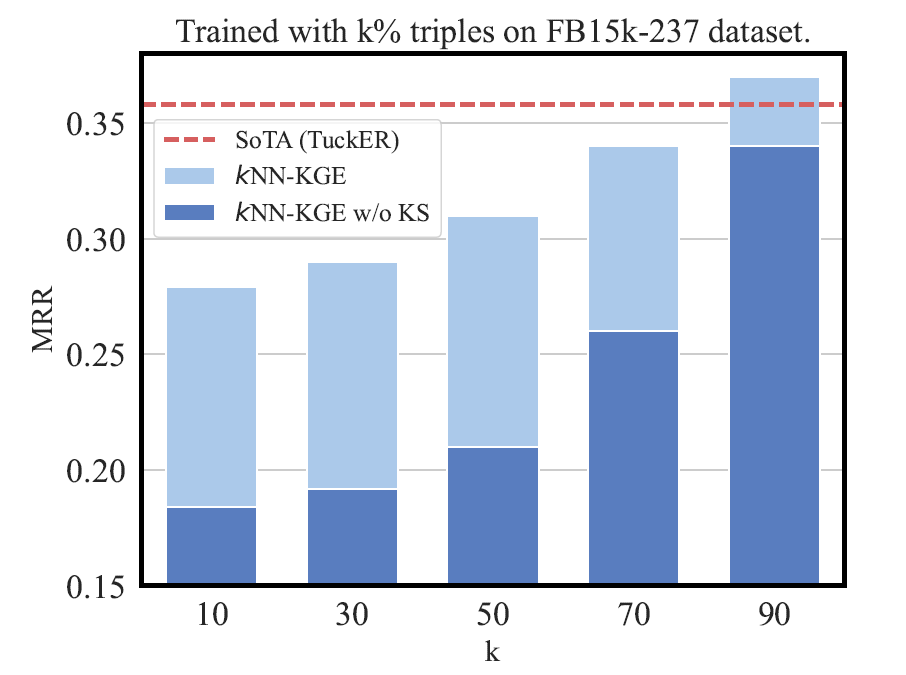
论文从低到高调整训练样本的比例,并比较加KS部分带来的效果提升,观察其何时能超过sota效果
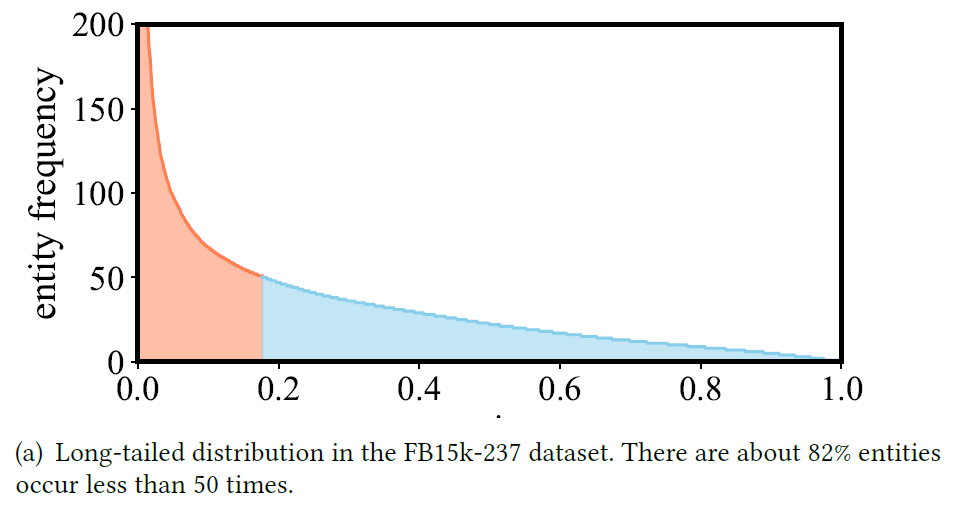
长尾实体上的效果比较
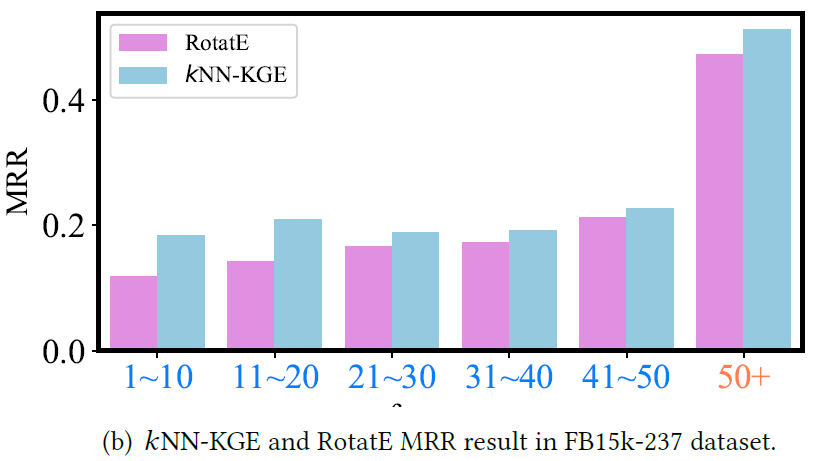
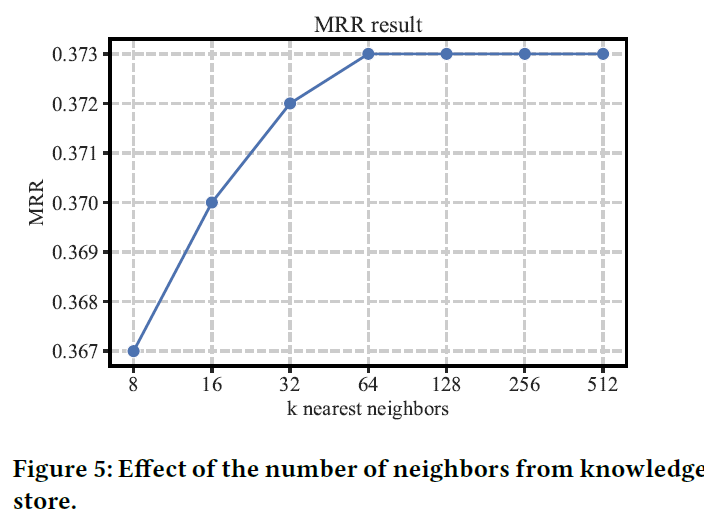
KNN中K的数目设置
看到这里我才理解整个KNN算法,给定一个最近邻居k,是在知识库中筛选出k个离给定嵌入表示最近的实体,然后用距离表示它们的概率,并与另一种方式计算出来的概率加权。这里有个假设,也就是目标实体就在这k个实体中,不过前面的公式没体现出来这个k。
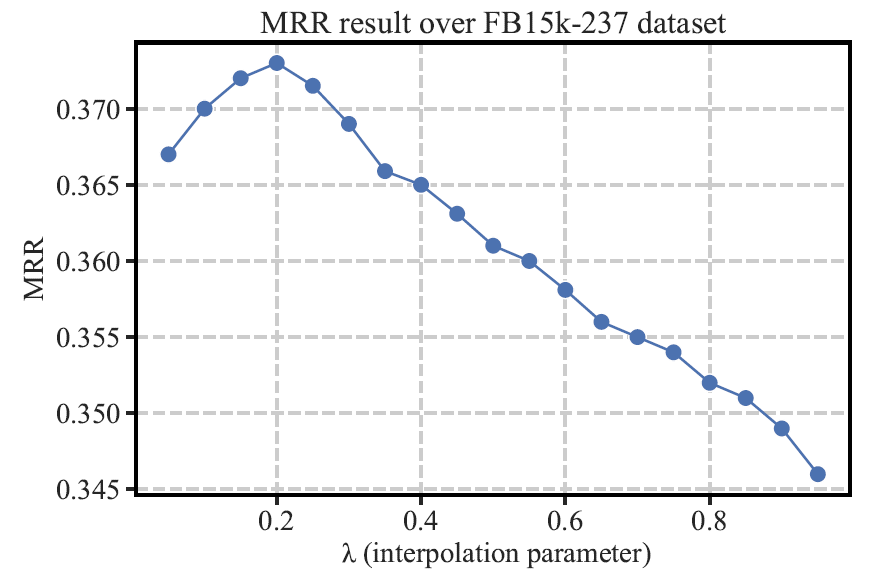
插值参数的取值
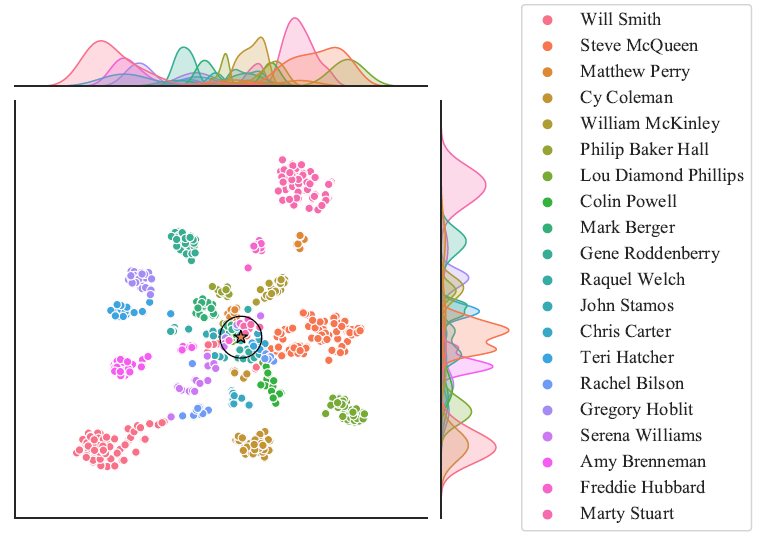
可视化
2D t-SNE对距离最近的k个邻居以及其他实体做了可视化,可见语义接近的实体在空间上也更为接近
模型比较
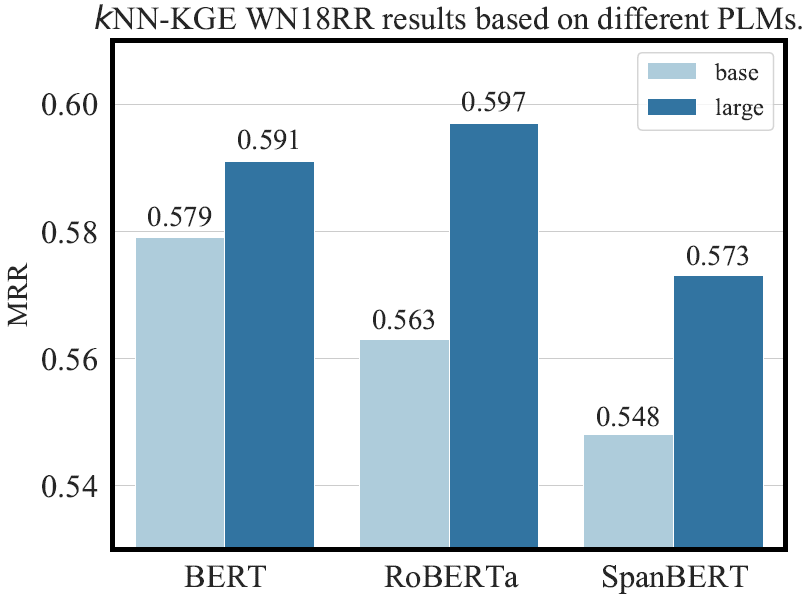
规模越大越好,RoBERTa上限最高
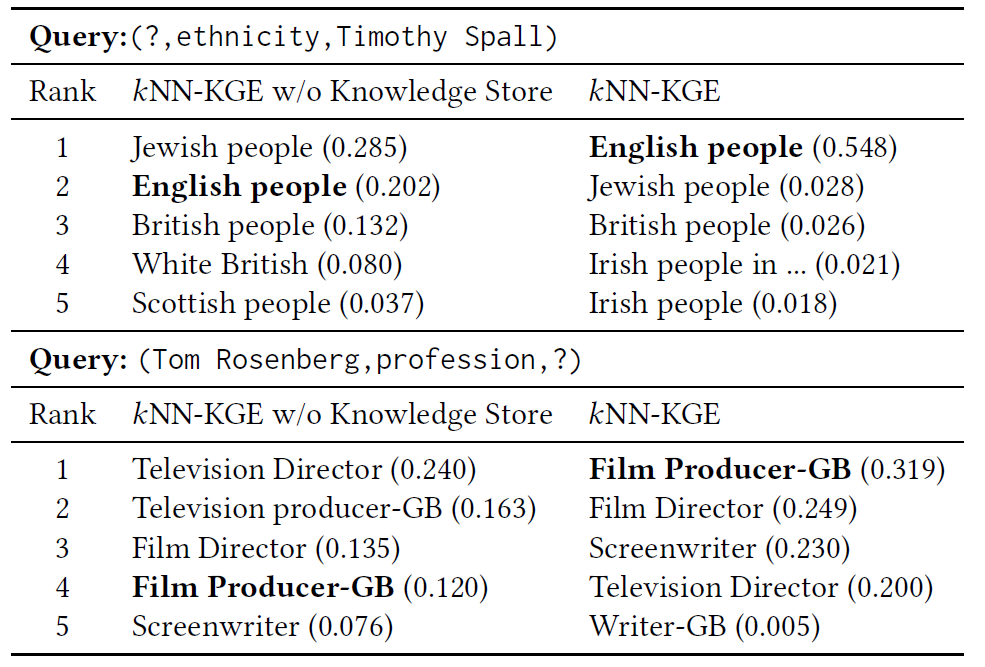
案例