💛前情提要💛
本文是传知代码平台中的相关前沿知识与技术的分享~
接下来我们即将进入一个全新的空间,对技术有一个全新的视角~
本文所涉及所有资源均在传知代码平台可获取
以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!!
以下内容干货满满,跟上步伐吧~
📌导航小助手📌
- 💡本章重点
- 🍞一. 概述
- 🍞二. Flan-T5介绍
- 🍞三. 部署流程
- 🫓总结
💡本章重点
- Flan-T5 使用指南
🍞一. 概述
本篇《Flan-T5 使用指南》在 Scaling Instruction-Finetuned Language Models 这篇论文的基础上,将展示如何加载和运行 Flan-T5 模型
并提供不同任务的运行示例和结果展示,帮助学习者更好地理解和应用 Flan-T5 模型。
🍞二. Flan-T5介绍
Flan-T5 是一种基于 T5 架构的预训练语言模型。T5(Text-To-Text Transfer Transformer)是由 Google 提出的统一文本到文本的传输模型架构,通过大量的文本数据进行预训练,并且在多个下游任务中表现出色。
Flan-T5 进一步在 T5 的基础上,通过指令调优(instruction tuning)和其他改进,增强了模型在各种任务上的性能。
相关论文
在论文中,Flan-T5 在多个方面推进了指令微调:
- 扩展性研究:研究表明,指令微调在任务数量和模型大小上的扩展性良好。这表明未来的研究应进一步扩大任务数量和模型大小。
- 推理能力的增强:通过在微调过程中加入链式思维(Chain-of-Thought, CoT)数据,显著改善了模型的推理能力。在微调混合中仅加入九个CoT数据集,就能在所有评估中提高性能。
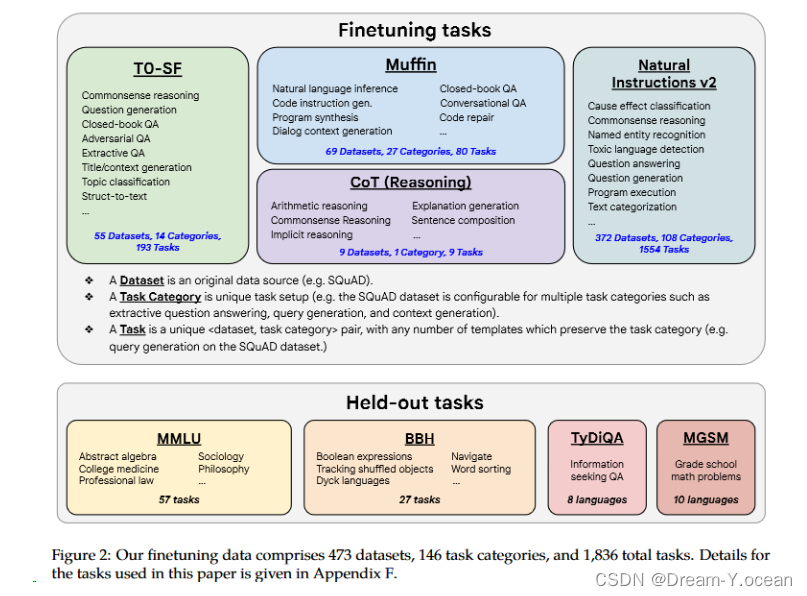
- 大型模型训练:基于上述发现,训练了一个具有540亿参数的Flan-PaLM模型,将微调任务数量增加到1800个,并包括CoT数据。Flan-PaLM 在多个基准测试中表现出色,如在大规模多任务语言理解(MMLU)上取得了75.2%的得分,比PaLM有显著提升。
- 多语言能力的提高:Flan-PaLM 相较于PaLM,在多语言任务上的表现也有显著提升,例如在单一示例的TyDiQA上有14.9%的绝对提升,以及在低资源语言的算术推理上有8.1%的提升。
- 人类评估中的表现:在开放式生成问题的评估中,Flan-PaLM 显著优于PaLM,表明其可用性大大提高。此外,指令微调还提升了模型在多个负责任的AI评估基准上的表现。
Flan-T5的性能
除了Flan-PaLM,本文还对Flan-T5模型(从80M到11B参数)进行了指令微调。结果显示,这些Flan-T5模型在零样本、少样本和链式思维任务上表现强劲,超越了先前的公开模型检查点,如T5。例如,Flan-T5 11B比T5 11B在一些具有挑战性的BIG-Bench任务上有双位数的改进,甚至在某些任务上超过了PaLM 62B。
总体而言,论文的结果强调了指令微调在提高模型在各种设置和评估任务上的性能方面的潜力。
Flan-T5的应用
Flan-T5 可以用于多种自然语言处理任务,包括但不限于:
- 文本摘要
- 文本摘要任务的目标是从长文本中提取出简洁的摘要。Flan-T5 可以有效地理解和处理长文本,生成简明扼要的摘要,保留文本中的关键信息。这在新闻摘要、学术论文摘要和其他需要简化信息的场景中非常有用。
- 机器翻译
- Flan-T5 在多语言数据上进行了训练,能够在不同语言之间进行高质量的文本翻译。它不仅可以处理常见的语言对,还可以处理一些低资源语言的翻译任务。这在跨国企业、国际交流和多语言内容生成中具有重要意义。
- 问答系统
- Flan-T5 能够根据提供的上下文回答问题,适用于构建智能问答系统。例如,在客户服务中,Flan-T5 可以根据用户的询问,从知识库中提取相关信息并生成准确的回答,从而提升用户体验和服务效率。
- 文本生成
- 基于给定的提示,Flan-T5 可以生成创意文本,如故事、诗歌等。这在内容创作、写作辅助和教育等领域具有广泛的应用前景。模型能够理解和扩展提示,生成连贯且富有创意的文本。
- 文本纠错
-
Flan-T5 可以对输入文本进行语法和拼写纠错,提高文本的准确性和可读性。这对于需要高质量文本输出的场景,如文档编辑、内容审核和语言学习等,非常有帮助。
-
本篇Flan-T5指南,在调用论文提出的Flan-T5基础上,将演示如何在五个主要的自然语言处理任务中应用 Flan-T5
-
🍞三. 部署流程
安装 Python 及必要库
pip install transformers torch
项目结构
flan_t5_tasks/
├── README.md
├── requirements.txt
├── main.py
└── tasks/
├── __init__.py
├── summarize.py
├── translate.py
├── question_answer.py
├── generate.py
└── correct.py
运行
python tasks/summarize.py

所有任务
python main.py

结果
执行各个脚本后,会在控制台输出相应任务的结果。例如,执行 summarize.py 后,控制台会输出生成的文本摘要。

核心代码
from transformers import T5Tokenizer, T5ForConditionalGeneration
# 加载模型和分词器
model_name = "google/flan-t5-small"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
def summarize_text(text):
input_text = f"Summarize: {text}"
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs, max_length=50, early_stopping=True)
summary = tokenizer.decode(outputs[0], skip_special_tokens=True)
return summary
if __name__ == "__main__":
text = "Transformers are a type of model architecture that has achieved state-of-the-art results in many NLP tasks..."
summary = summarize_text(text)
print(f"Summary: {summary}")
🫓总结
综上,我们基本了解了“一项全新的技术啦” 🍭 ~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
【传知科技 – 了解更多新知识】