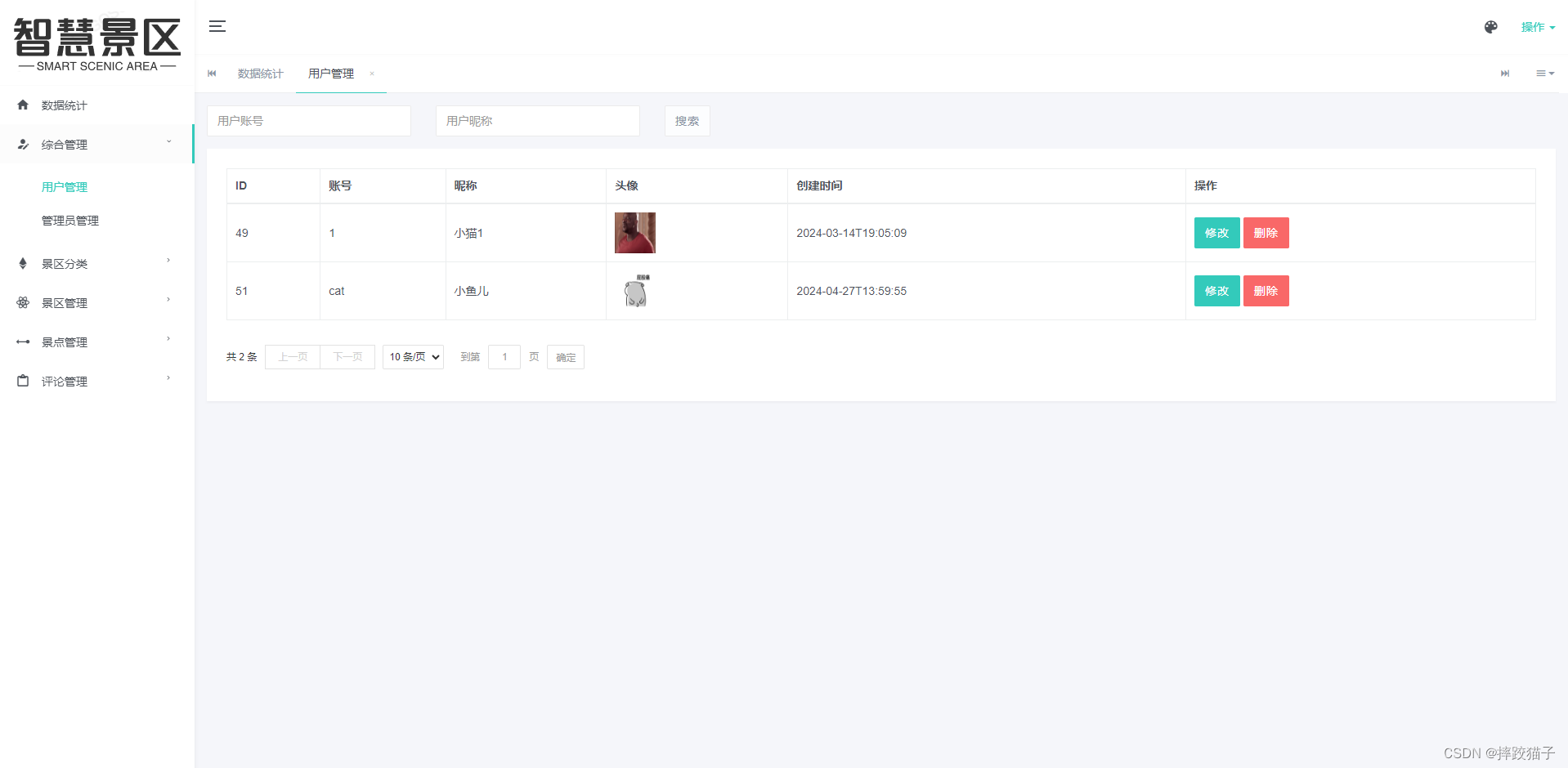
作者:来自 Elastic Navarone Feekery

多年来,Elastic 已经经历了几次 Crawler 迭代。最初是 Swiftype 的 Site Search,后来发展成为 App Search Crawler,最近又发展成为 Elastic Crawler。这些 Crawler 功能丰富,允许以稳健而细致的方式将网站数据导入 Elasticsearch。但是,如果用户想在自己的基础设施上运行这些 Crawler,他们也需要运行整个企业搜索。企业搜索代码库非常庞大,包含许多不同的工具,因此用户无法选择只运行 Crawler。由于企业搜索是私有代码,因此用户也不完全清楚他们正在运行什么。
这一切都改变了,因为我们发布了最新版本的 Crawler:Open Crawler!
Open Crawler 允许用户从他们喜欢的任何位置抓取 Web 内容并将其索引到 Elasticsearch 中。使用 Elastic Cloud 没有任何要求,也不需要运行 Kibana 或企业搜索实例。只需要一个 Elasticsearch 实例即可将抓取结果导入其中。
这次的存储库也是开放代码。用户现在可以检查代码库、提交问题和 PR 请求,或者分支存储库进行更改并运行他们自己的爬虫变体。
有什么变化?
Open Crawler 比之前的 SaaS 爬虫轻量得多。该产品本质上是现有 Elastic Crawler 的核心爬虫代码,与企业搜索服务分离。分离 Open Crawler 意味着暂时放弃一些功能。如果你想阅读我们实现功能对等的路线图,本博客末尾有一个完整的功能比较表。我们打算重新引入这些功能,并在该产品成为正式发布时达到近乎功能对等。
这个过程还使我们能够对核心产品进行改进。例如:
- 我们能够消除索引命名的限制
- 现在可以在抓取和提取内容之前对索引使用自定义映射
- 抓取结果现在也被批量索引到 Elasticsearch 中,而不是一次索引一个网页
- 这提供了显着的性能提升,我们将在下面介绍
它与 Elastic Crawler 相比如何?
如前所述,此爬虫程序可以从你喜欢的任何地方运行;你的计算机、你的个人服务器或云托管服务器。它可以将文档索引到本地、云甚至无服务器的 Elasticsearch 中。你也不再需要使用企业搜索将你的网站内容导入 Elasticsearch。
但最令人兴奋的是,Open Crawler 也比 Elastic Crawler 更快。
我们进行了性能测试,以比较 Open Crawler 和我们的下一个最新爬虫程序 Elastic Crawler 的速度。这两个爬虫程序都爬取了网站 elastic.co,没有更改默认配置。Open Crawler 设置为在两个 AWS EC2 实例上运行;m1.small 和 m1.large,而 Elastic Crawler 则从 Elastic Cloud 本地运行。所有这些都设置在北弗吉尼亚州地区。内容被索引到具有相同设置的 Elasticsearch Cloud 实例中(默认 360 GB 存储 | 8 GB RAM | 最多 2.5 个 vCPU)。
结果如下:
| Crawler Type | Server RAM | Server CPU | Crawl Duration (mins) | Docs Ingested (n) |
|---|---|---|---|---|
| Elastic Crawler | 2GB | up to 8 vCPU | 305 | 43957 |
Open Crawler (m1.small) | 1.7 GB | 1 vCPU | 160 | 56221 |
Open Crawler (m1.large) | 3.75 GB per vCPU | 2 vCPU | 100 | 56221 |
对于 m1.small,Open Crawler 的速度几乎是后者的两倍,而对于 m1.large,速度则是后者的三倍多!
尽管运行在 vCPU 配置较少的服务器上,Open Crawler 的速度也同样快。Open Crawler 提取了大约 13000 多个文档,但这是因为 Elastic Crawler 将具有相同主体的网站页面合并为一个文档。此功能称为重复内容处理(duplicate content handling),详细描述位于本博客末尾的功能比较矩阵中。这里的要点是,即使提取的文档数量不同,这两个爬虫在各自的抓取过程中遇到的网页数量相同。
以下是一些图表,比较了这对 Elasticsearch 的影响。这些图表比较了 Elastic Crawler 和在 m1.large 实例上运行的 Open Crawler。
CPU
当然,Open Crawler 导致 Elastic Cloud 上的 CPU 使用率显著降低,但这是因为我们删除了整个企业搜索服务器。仍然值得快速查看一下此 CPU 使用率分布在哪里。
Elastic Crawler CPU 负载(Elastic Cloud)
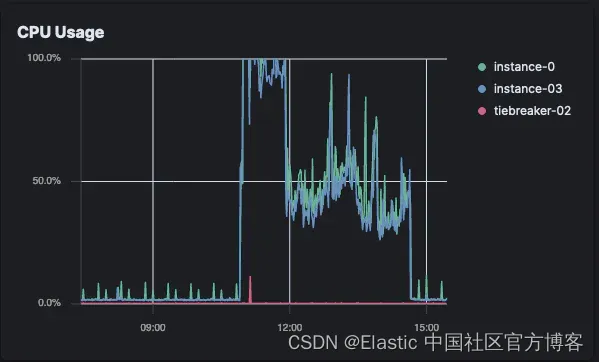
打开爬虫 CPU 负载(Elastic Cloud)
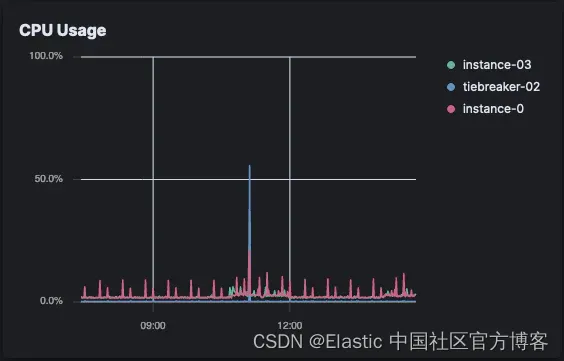
Elastic Crawler 立即达到 CPU 阈值并持续使用了一个小时。然后它下降并出现周期性峰值,直到爬取完成。
对于 Open Crawler,Elastic Cloud 上几乎没有明显的 CPI 使用情况,但 CPU 仍在某处被消耗,在我们的例子中,这是在 EC2 实例上。
EC2 CPU 负载 (m1.large)
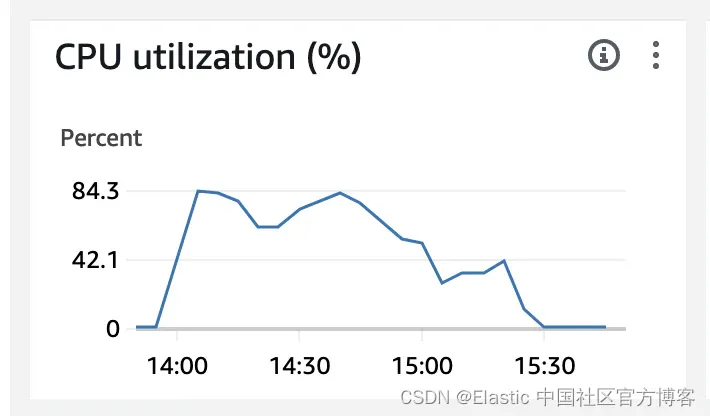
我们在这里可以看到,Open Crawler 没有达到 100% 的限制阈值。它使用的最高 CPU 为 84.3%。这意味着这里还有更多的优化空间。根据用户设置(以及我们可以添加到代码库的优化),Open Crawler 可能会更快。
请求数 (n)
通过比较抓取期间发出的请求数,我们可以看到 Elasticsearch 服务器负载的真正变化。
Elastic Crawler 请求数
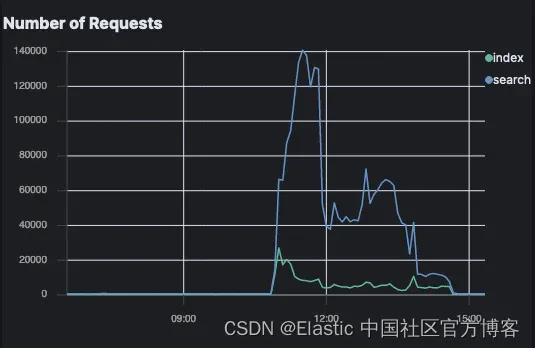
Open Crawler 请求:
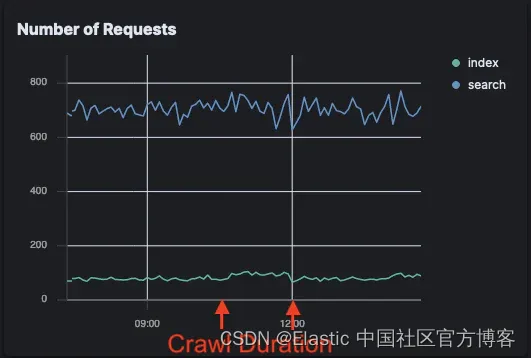
Open Crawler 对索引请求的影响非常小,与背景噪音相比,在这张图上甚至无法察觉。索引请求略有增加,搜索请求没有变化。
与此同时,Elastic Crawler 的请求激增;特别是搜索请求。
这意味着对于想要减少对其 Elasticsearch 实例的请求的用户来说,Open Crawler 是一个很好的解决方案。
那么为什么它的速度会快这么多呢?
1) Open Crawler 发出的索引请求明显更少。
Elastic Crawler 每次只对一个爬取结果进行索引。这样做是为了实现重复内容管理等功能。这意味着 Elastic Crawler 在爬取过程中执行了 43,957 个文档索引请求。它还会在遇到重复内容时更新文档,因此它还执行了超过 13,000 个单独的更新请求。
Open Crawler 反而会汇集爬取结果并批量对其进行索引。在此测试中,它仅在 604 个大小各异的批量请求中就索引了相同数量的爬取结果。这不到所发出索引请求的 1.5%,这大大降低了 Elasticsearch 的管理负载。
2)Elastic Crawler 还执行许多搜索请求,进一步降低了性能
Elastic Crawler 的配置和元数据在 Elasticsearch 伪系统(pseudo-system)索引中进行管理。在爬取时,它会定期检查此配置并更新其中一些索引的元数据,这是通过进一步的 Elasticsearch 请求完成的。
Open Crawler 的配置完全在 yaml 文件中管理。它也不会跟踪 Elasticsearch 索引上的元数据。它对 Elasticsearch 发出的唯一请求是在抓取网站时从抓取结果中索引文档。
3)Open Crawler 对抓取结果的处理较少
在 Open Crawler 的技术预览阶段,有许多功能尚未提供。在 Elastic Crawler 中,这些功能均通过 Elasticsearch 中的伪系统索引进行管理。当我们将这些功能添加到 Open Crawler 时,我们可以确保它们以不涉及多次向 Elasticsearch 发出请求以检查配置的方式完成。这意味着即使在达到与 Elastic Crawler 几乎相同的功能后,Open Crawler 仍应保持这种速度优势。
我如何使用它?
你现在可以克隆存储库并按照此处的文档开始使用。如果你不更改源代码,我建议使用 Docker 来运行 Open Crawler,以使过程更顺畅。
如果你想将抓取结果索引到 Elasticsearch 中,你还可以试用 Elasticsearch on Cloud 的免费试用版或自行从网站下载并运行 Elasticsearch。
这是抓取网站 parksaustralia.gov.au 的快速演示。此操作的要求是 Docker、Open Crawler 存储库的克隆/分叉以及正在运行的 Elasticsearch 实例。
1. 构建 Docker 映像并运行它
这可以在一行中完成,使用 docker build -t crawler-image . && docker run -i -d --name crawler crawler-image。
docker build -t crawler-image . && docker run -i -d --name crawler crawler-image。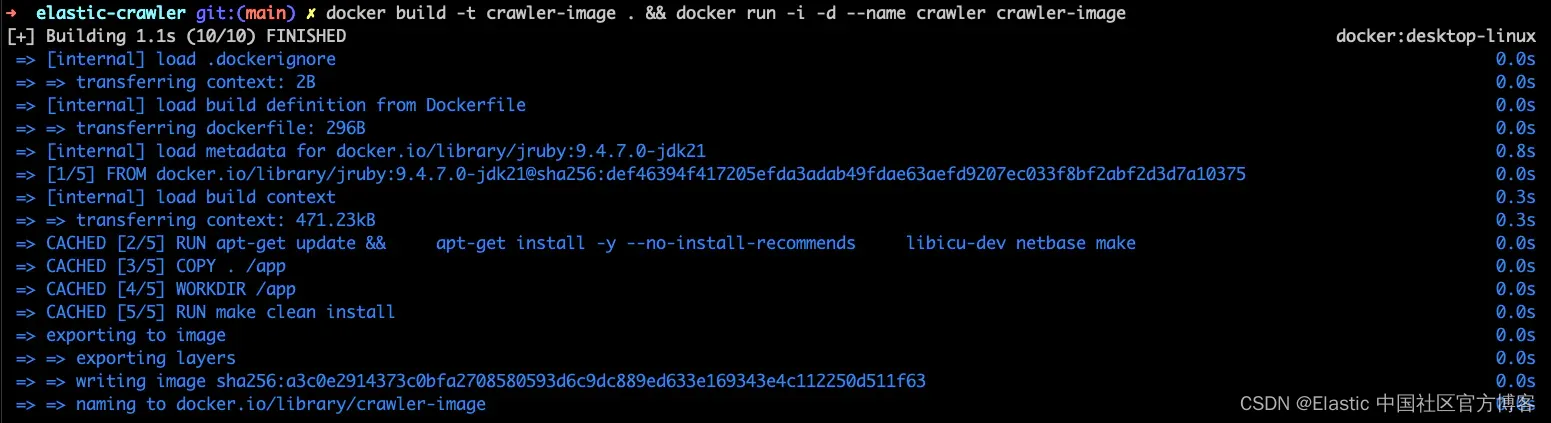
然后,你可以使用 CLI 命令检查版本,确认它正在运行:
docker exec -it crawler bin/crawler version
2. 配置爬虫
使用存储库中的示例,你可以创建一个配置文件。在这个例子中,我正在爬取网站 parksaustralia.org.au 并将其索引到基于云的 Elasticsearch 实例中。
这是我的配置示例,我创造性地将其命名为 example.yml。
example.yml
domain_allowlist:
- https://parksaustralia.gov.au
seed_urls:
- https://parksaustralia.gov.au
output_sink: elasticsearch
output_index: elastic-crawler-test-2
max_crawl_depth: 2
elasticsearch:
host: "https://myinstance.eu-north1.gcp.elastic-cloud.com"
port: "443"
username: "elastic"
password: "realpassword"
可以使用以下方式将其复制到 docker 容器中:
ocker cp config/example.yml crawler:/app/config/example.yml
4. 爬取!
使用 docker exec -it crawler bin/crawler crawl config/example.yml 开始爬取。
docker exec -it crawler bin/crawler crawl config/example.yml
如果站点很大,则需要一段时间才能完成,但你会根据 shell 输出知道它已完成。

5. 检查内容
然后我们可以针对索引执行 _search 查询。如果你有一个正在运行的实例,也可以在 Kibana Dev Tools 中执行此操作。
curl -X GET "https://myinstance.eu-north1.gcp.elastic-cloud.com:443/elastic-crawler-test-2/_search" \
-H 'Content-Type: application/json' \
-u elastic:realpassword \
-d'
{
"_source": ["url", "title", "body_content"],
"size": 1,
"query": {
"match": {
"title": "Uluru"
}
}
}
' | jq '.hits.hits[]._source'
还有结果!
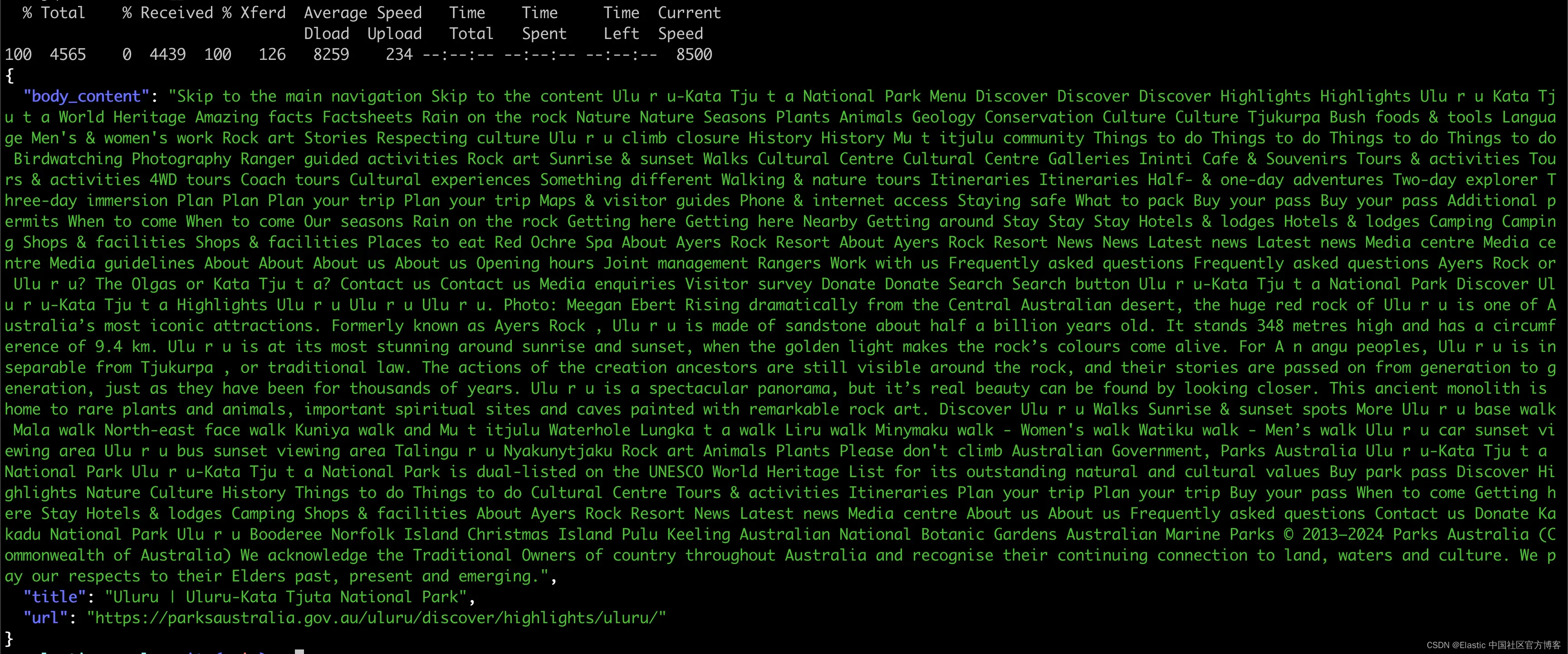
你甚至可以将这些结果与语义搜索联系起来,并进行一些很酷的真实语言查询,例如澳大利亚中心的公园是什么?你只需将你创建的管道的名称添加到 Crawler 配置 yaml 文件的 elasticsearch.pipeline 字段下。
功能比较细分
以下是截至 v8.13 的 Elastic Crawler 功能的完整列表,以及我们打算将它们添加到 Open Crawler 的时间。技术预览中提供的功能已经可用。
这些与任何特定的堆栈版本无关,但我们为每个版本设定了一个大致的时间。
- 技术预览:今天(2024 年 6 月)
- 测试版:2024 年秋季
- GA:2025 年夏季
| Feature | Open Crawler | Elastic Crawler |
|---|---|---|
| Index content into Elasticsearch | tech-preview | ✔ |
| No index name restrictions | tech-preview | ✖ |
| Run anywhere, without Enterprise Search or Kibana | tech-preview | ✖ |
| Bulk index results | tech-preview | ✖ |
| Ingest pipelines | tech-preview | ✔ |
| Seed URLs | tech-preview | ✔ |
robots.txt and sitemap.xml adherence | tech-preview | ✔ |
| Crawl through proxy | tech-preview | ✔ |
| Crawl sites with authorization | tech-preview | ✔ |
| Data attributes for inclusion/exclusion | tech-preview | ✔ |
| Limit crawl depth | tech-preview | ✔ |
| Robots meta tags | tech-preview | ✔ |
| Canonical URL link tags | tech-preview | ✔ |
| No-follow links | tech-preview | ✔ |
| CSS selectors | beta | ✔ |
| XPath selectors | beta | ✔ |
| Custom data attributes | beta | ✔ |
| Binary content extraction | beta | ✔ |
| URL pattern extraction (extraction directly from URLs using regex) | beta | ✔ |
| URL filters (extraction rules for specific endpoints) | beta | ✔ |
| Purge crawls | beta | ✔ |
| Crawler results history and metadata | GA | ✔ |
| Duplicate content handling | TBD | ✔ |
| Schedule crawls | TBD | ✔ |
| Manage crawler through Kibana UI | TBD | ✔ |
由于我们正在评估 Open Crawler 的未来,因此 TBD 功能仍未确定。其中一些功能(如计划抓取)已经可以使用 cron 作业或类似的自动化功能完成。根据用户反馈以及 Open Crawler 项目的发展情况,我们可能会决定在以后的版本中正确实现这些功能。如果你需要其中之一,请联系我们!你可以在论坛和社区 Slack 中找到我们,也可以直接在存储库中创建问题。
下一步是什么?
我们希望在 v9.0 中及时将其发布为正式版。Open Crawler 的设计考虑到了 Elastic Cloud Serverless,我们打算让它成为该版本的主要 Web 内容提取方法。
我们还计划支持 Elastic 数据提取服务,因此可以使用 Open Crawler 提取更大的二进制内容文件。
与此同时,我们需要引入许多功能,以获得与 Elastic Crawler 目前相同的功能丰富的体验。
你可以使用来自任何来源的数据构建搜索。查看此网络研讨会,了解 Elasticsearch 支持的不同连接器和来源。
准备好自己尝试一下了吗?开始免费试用。
原文:Open Crawler released for tech-preview — Elastic Search Labs