文章目录
- 生成式模型和判别式模型的具体分析
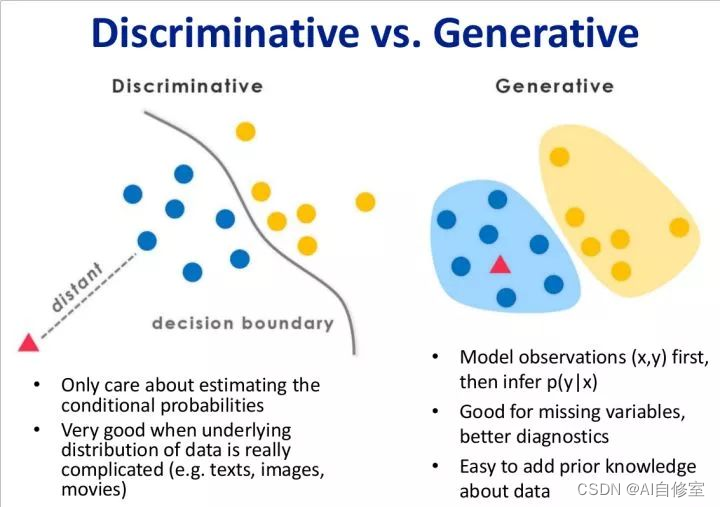
- ==生成式模型==
- 定义
- 工作原理
- 优点
- 缺点
- 常见模型
- ==判别式模型==
- ==总结==
- 生成式模型
- 判别式模型
生成式模型和判别式模型的具体分析
生成式模型和判别式模型在机器学习中有着不同的目标、应用场景和性能特点。以下将详细分析它们的定义、工作原理、优缺点和常见模型,并提供具体的示例。
生成式模型
定义
生成式模型是用于建模输入数据 (X) 和标签 (Y) 的联合概率分布 (P(X, Y))。通过学习联合分布,生成式模型可以推导出条件概率 (P(Y|X)) 进行分类,并且能够生成新的数据样本。
工作原理
生成式模型首先估计联合分布 (P(X, Y)),然后利用贝叶斯定理推导条件分布 (P(Y|X)):
P
(
Y
∣
X
)
=
P
(
X
∣
Y
)
P
(
Y
)
P
(
X
)
P(Y|X) = \frac{P(X|Y) P(Y)}{P(X)}
P(Y∣X)=P(X)P(X∣Y)P(Y)
其中:
- (P(X|Y)) 是给定类别 (Y) 下的特征分布。
- (P(Y)) 是类别的先验概率。
- (P(X)) 是特征的边际分布。
优点
- 生成新数据:能够从学到的分布中生成新样本。
- 处理缺失数据:在推断时可以处理部分缺失的数据。
- 全面建模:对数据分布有全面的理解。
缺点
- 计算复杂:估计联合分布的计算复杂度较高。
- 训练困难:需要大量数据来准确估计分布,训练过程复杂。
常见模型
-
朴素贝叶斯(Naive Bayes):假设特征之间条件独立,适用于文本分类、垃圾邮件过滤等。
P ( Y ∣ X ) ∝ P ( Y ) ∏ i = 1 n P ( X i ∣ Y ) P(Y|X) \propto P(Y) \prod_{i=1}^n P(X_i|Y) P(Y∣X)∝P(Y)∏i=1nP(Xi∣Y)
-
高斯混合模型(Gaussian Mixture Models, GMM): 假设数据由多个高斯分布组成,用于聚类和密度估计。
P ( X ) = ∑ k = 1 K π k N ( X ∣ μ k , Σ k ) P(X) = \sum_{k=1}^K \pi_k \mathcal{N}(X|\mu_k, \Sigma_k) P(X)=∑k=1KπkN(X∣μk,Σk) -
隐马尔可夫模型(Hidden Markov Models, HMM):用于时间序列数据,如语音识别、基因序列分析。
P ( X , Y ) = P ( Y 1 ) ∏ t = 2 T P ( Y t ∣ Y t − 1 ) P ( X t ∣ Y t ) P(X, Y) = P(Y_1) \prod_{t=2}^T P(Y_t|Y_{t-1}) P(X_t|Y_t) P(X,Y)=P(Y1)∏t=2TP(Yt∣Yt−1)P(Xt∣Yt)
-
生成对抗网络(Generative Adversarial Networks, GANs):用于图像生成,通过对抗训练生成逼真的图像。包括生成器 (G) 和判别器 (D),相互博弈提升生成效果。
-
变分自编码器(Variational Autoencoders, VAEs):
用于生成图像、文本,通过变分推断进行训练。
由编码器和解码器组成,学习数据的潜在表示。
示例:
- GANs生成图像:生成对抗网络可以生成逼真的人脸图像,广泛用于图像生成和增强。
- 朴素贝叶斯文本分类:通过计算词频分布,分类电子邮件为垃圾邮件或正常邮件。
判别式模型
定义:
判别式模型直接建模输入数据 (X) 和标签 (Y) 之间的条件概率分布 (P(Y|X)),或直接学习输入到输出的映射 (Y = f(X))。主要用于分类和回归任务。
工作原理:
判别式模型通过优化目标函数来直接学习从输入到输出的映射:
P ( Y ∣ X ) = 1 Z ( X ) exp ( f ( X , Y ) ) P(Y|X) = \frac{1}{Z(X)} \exp(f(X, Y)) P(Y∣X)=Z(X)1exp(f(X,Y))
其中 (Z(X)) 是归一化因子,确保概率分布的和为1。
优点:
- 计算效率高:直接建模条件概率,训练和预测速度快。
- 优化分类边界:关注输入特征和输出标签的直接关系。
- 高效处理大规模数据:适用于大数据量下的分类和回归任务。
缺点:
- 无法生成新数据:不能从模型中生成新样本。
- 对缺失数据不鲁棒:无法处理数据中的缺失值。
- 需要更多标签数据:通常需要大量标注数据来训练。
常见模型:
-
逻辑回归(Logistic Regression):
- 用于二分类问题,学习输入特征和标签的条件概率。
- P ( Y = 1 ∣ X ) = 1 1 + exp ( − ( β 0 + β 1 X 1 + ⋯ + β p X p ) ) P(Y=1|X) = \frac{1}{1 + \exp(-(\beta_0 + \beta_1 X_1 + \cdots + \beta_p X_p))} P(Y=1∣X)=1+exp(−(β0+β1X1+⋯+βpXp))1
-
支持向量机(Support Vector Machines, SVM):
- 通过最大化分类间隔的超平面进行分类。
- f ( X ) = w T X + b f(X) = w^T X + b f(X)=wTX+b
-
线性判别分析(Linear Discriminant Analysis, LDA):
- 通过学习线性组合的投影来最大化类间距离。
- δ k ( X ) = X T Σ − 1 μ k − 1 2 μ k T Σ − 1 μ k + log ( π k ) \delta_k(X) = X^T \Sigma^{-1} \mu_k - \frac{1}{2} \mu_k^T \Sigma^{-1} \mu_k + \log(\pi_k) δk(X)=XTΣ−1μk−21μkTΣ−1μk+log(πk)
-
决策树(Decision Trees):
- 通过树形结构递归分割数据,进行分类或回归。
- 根据信息增益或基尼系数选择最优分割点。
-
随机森林(Random Forest):
- 集成多棵决策树,通过多数投票或平均进行预测。
- 提升模型的鲁棒性和准确性。
-
梯度提升机(Gradient Boosting Machines, GBM):
- 逐步添加弱学习器(如决策树)来优化模型。
- 通过残差学习逐步提升预测精度。
-
神经网络(Neural Networks):
- 包括单层感知机、多层感知机(MLP)、卷积神经网络(CNN)、循环神经网络(RNN)等。
- 通过多个隐藏层和非线性激活函数,能够拟合复杂的非线性关系。
示例:
- 逻辑回归二分类:用于预测信用卡用户是否会违约,通过学习用户特征与违约行为的关系。
- SVM文本分类:用于情感分析,通过找到最优超平面分类正负情感文本。
总结

生成式模型
- 目标:建模联合概率分布 (P(X, Y))。
- 优点:可以生成新数据、处理缺失数据、全面建模。
- 缺点:计算复杂、训练困难。
- 常见模型:朴素贝叶斯、GMM、HMM、GANs、VAEs。
判别式模型
- 目标:建模条件概率分布 (P(Y|X)) 或直接学习输入到输出的映射。
- 优点:计算效率高、优化分类边界、处理大规模数据高效。
- 缺点:无法生成新数据、对缺失数据不鲁棒、需要大量标注数据。
- 常见模型:逻辑回归、SVM、LDA、决策树、随机森林、GBM、神经网络。
选择生成式模型还是判别式模型取决于具体的任务需求。如果需要生成新数据或处理不完全数据,生成式模型是更好的选择;如果主要目标是分类或回归,且数据规模较大,判别式模型通常更为高效。