表的索引可以给数据检索提升效率,但是也给表的增删改操作带来代价。本文我们将关注,索引数量对INSERT操作的影响。
结论
索引数的新增会造成INSERT操作效率下降,约每增一个索引会降低10%效率。
实验数据
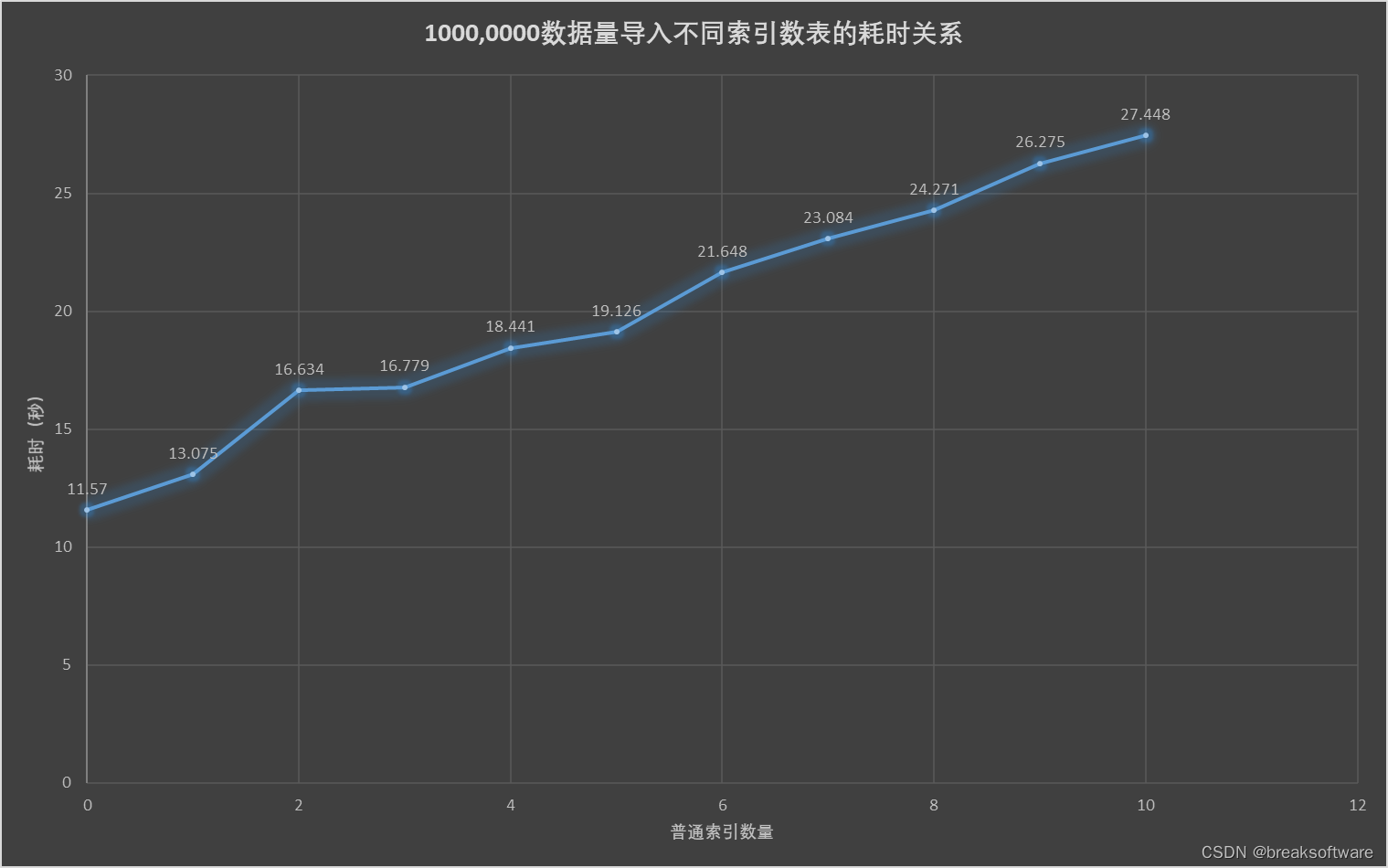
可以看到0个索引的效率是7个索引效率的一倍。
测试环境
见《Mysql使用中的性能优化——搭建Mysql的监测服务》
测试代码
DROP DATABASE IF EXISTS testdb;
CREATE DATABASE IF NOT EXISTS testdb;
USE testdb;
DROP TABLE IF EXISTS test_insert_src;
CREATE TABLE test_insert_src (
id SERIAL PRIMARY KEY,
name TEXT,
name1 TEXT,
name2 TEXT,
name3 TEXT,
name4 TEXT,
name5 TEXT,
name6 TEXT,
name7 TEXT,
name8 TEXT,
name9 TEXT
) engine=InnoDB;
DROP TABLE IF EXISTS test_insert_0_index;
CREATE TABLE test_insert_0_index (
id SERIAL PRIMARY KEY,
name TEXT,
name1 TEXT,
name2 TEXT,
name3 TEXT,
name4 TEXT,
name5 TEXT,
name6 TEXT,
name7 TEXT,
name8 TEXT,
name9 TEXT
) engine=InnoDB;
DROP TABLE IF EXISTS test_insert_1_index;
CREATE TABLE test_insert_1_index (
id SERIAL PRIMARY KEY,
name TEXT,
name1 TEXT,
name2 TEXT,
name3 TEXT,
name4 TEXT,
name5 TEXT,
name6 TEXT,
name7 TEXT,
name8 TEXT,
name9 TEXT,
INDEX name_index (name(32))
) engine=InnoDB;
DROP TABLE IF EXISTS test_insert_2_index;
CREATE TABLE test_insert_2_index (
id SERIAL PRIMARY KEY,
name TEXT,
name1 TEXT,
name2 TEXT,
name3 TEXT,
name4 TEXT,
name5 TEXT,
name6 TEXT,
name7 TEXT,
name8 TEXT,
name9 TEXT,
INDEX name_index (name(32)),
INDEX name1_index (name1(32))
) engine=InnoDB;
DROP TABLE IF EXISTS test_insert_3_index;
CREATE TABLE test_insert_3_index (
id SERIAL PRIMARY KEY,
name TEXT,
name1 TEXT,
name2 TEXT,
name3 TEXT,
name4 TEXT,
name5 TEXT,
name6 TEXT,
name7 TEXT,
name8 TEXT,
name9 TEXT,
INDEX name_index (name(32)),
INDEX name1_index (name1(32)),
INDEX name2_index (name2(32))
) engine=InnoDB;
DROP TABLE IF EXISTS test_insert_4_index;
CREATE TABLE test_insert_4_index (
id SERIAL PRIMARY KEY,
name TEXT,
name1 TEXT,
name2 TEXT,
name3 TEXT,
name4 TEXT,
name5 TEXT,
name6 TEXT,
name7 TEXT,
name8 TEXT,
name9 TEXT,
INDEX name_index (name(32)),
INDEX name1_index (name1(32)),
INDEX name2_index (name2(32)),
INDEX name3_index (name3(32))
) engine=InnoDB;
DROP TABLE IF EXISTS test_insert_5_index;
CREATE TABLE test_insert_5_index (
id SERIAL PRIMARY KEY,
name TEXT,
name1 TEXT,
name2 TEXT,
name3 TEXT,
name4 TEXT,
name5 TEXT,
name6 TEXT,
name7 TEXT,
name8 TEXT,
name9 TEXT,
INDEX name_index (name(32)),
INDEX name1_index (name1(32)),
INDEX name2_index (name2(32)),
INDEX name3_index (name3(32)),
INDEX name4_index (name4(32))
) engine=InnoDB;
DROP TABLE IF EXISTS test_insert_6_index;
CREATE TABLE test_insert_6_index (
id SERIAL PRIMARY KEY,
name TEXT,
name1 TEXT,
name2 TEXT,
name3 TEXT,
name4 TEXT,
name5 TEXT,
name6 TEXT,
name7 TEXT,
name8 TEXT,
name9 TEXT,
INDEX name_index (name(32)),
INDEX name1_index (name1(32)),
INDEX name2_index (name2(32)),
INDEX name3_index (name3(32)),
INDEX name4_index (name4(32)),
INDEX name5_index (name5(32))
) engine=InnoDB;
DROP TABLE IF EXISTS test_insert_7_index;
CREATE TABLE test_insert_7_index (
id SERIAL PRIMARY KEY,
name TEXT,
name1 TEXT,
name2 TEXT,
name3 TEXT,
name4 TEXT,
name5 TEXT,
name6 TEXT,
name7 TEXT,
name8 TEXT,
name9 TEXT,
INDEX name_index (name(32)),
INDEX name1_index (name1(32)),
INDEX name2_index (name2(32)),
INDEX name3_index (name3(32)),
INDEX name4_index (name4(32)),
INDEX name5_index (name5(32)),
INDEX name6_index (name6(32))
) engine=InnoDB;
DROP TABLE IF EXISTS test_insert_8_index;
CREATE TABLE test_insert_8_index (
id SERIAL PRIMARY KEY,
name TEXT,
name1 TEXT,
name2 TEXT,
name3 TEXT,
name4 TEXT,
name5 TEXT,
name6 TEXT,
name7 TEXT,
name8 TEXT,
name9 TEXT,
INDEX name_index (name(32)),
INDEX name1_index (name1(32)),
INDEX name2_index (name2(32)),
INDEX name3_index (name3(32)),
INDEX name4_index (name4(32)),
INDEX name5_index (name5(32)),
INDEX name6_index (name6(32)),
INDEX name7_index (name7(32))
) engine=InnoDB;
DROP TABLE IF EXISTS test_insert_9_index;
CREATE TABLE test_insert_9_index (
id SERIAL PRIMARY KEY,
name TEXT,
name1 TEXT,
name2 TEXT,
name3 TEXT,
name4 TEXT,
name5 TEXT,
name6 TEXT,
name7 TEXT,
name8 TEXT,
name9 TEXT,
INDEX name_index (name(32)),
INDEX name1_index (name1(32)),
INDEX name2_index (name2(32)),
INDEX name3_index (name3(32)),
INDEX name4_index (name4(32)),
INDEX name5_index (name5(32)),
INDEX name6_index (name6(32)),
INDEX name7_index (name7(32)),
INDEX name8_index (name8(32))
) engine=InnoDB;
DROP TABLE IF EXISTS test_insert_10_index;
CREATE TABLE test_insert_10_index (
id SERIAL PRIMARY KEY,
name TEXT,
name1 TEXT,
name2 TEXT,
name3 TEXT,
name4 TEXT,
name5 TEXT,
name6 TEXT,
name7 TEXT,
name8 TEXT,
name9 TEXT,
INDEX name_index (name(32)),
INDEX name1_index (name1(32)),
INDEX name2_index (name2(32)),
INDEX name3_index (name3(32)),
INDEX name4_index (name4(32)),
INDEX name5_index (name5(32)),
INDEX name6_index (name6(32)),
INDEX name7_index (name7(32)),
INDEX name8_index (name8(32)),
INDEX name9_index (name9(32))
) engine=InnoDB;
DROP PROCEDURE IF EXISTS test_insert_proc_batch_bulk;
DELIMITER //
CREATE PROCEDURE test_insert_proc_batch_bulk(IN name TEXT, IN fromNum INT, IN toNum INT)
BEGIN
DECLARE i INT DEFAULT fromNum;
DECLARE j INT DEFAULT 0;
DECLARE new_names TEXT DEFAULT '';
DECLARE nameList TEXT DEFAULT '';
SET @sql = 'INSERT INTO test_insert_src (name, name1, name2, name3, name4, name5, name6, name7, name8, name9) VALUES ';
WHILE i < toNum DO
SET nameList = '';
SET j = 0;
while j < 10 DO
SET new_names = CONCAT(name, i, "_", j);
IF j = 0 THEN
SET nameList = CONCAT(nameList, '"', new_names, '"');
ELSE
SET nameList = CONCAT(nameList, ',"', new_names, '"');
END IF;
SET j = j + 1;
END WHILE;
SET i = i + 1;
SET @sql = CONCAT(@sql, '(', nameList, '),');
END WHILE;
SET @sql = LEFT(@sql, LENGTH(@sql) - 1);
PREPARE stmt FROM @sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
COMMIT;
END //
DELIMITER ;
DROP PROCEDURE IF EXISTS test_insert_proc_batch;
DELIMITER //
CREATE PROCEDURE test_insert_proc_batch(IN name TEXT, IN count INT, IN step INT)
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < count DO
CALL test_insert_proc_batch_bulk(name, i, i + step);
SET i = i + step;
END WHILE;
COMMIT;
END //
DELIMITER ;
TRUNCATE TABLE test_insert_src;
CALL test_insert_proc_batch('test', 1000000, 5000);
TRUNCATE TABLE test_insert_0_index;
INSERT INTO test_insert_0_index (name, name1, name2, name3, name4, name5, name6, name7, name8, name9) SELECT name, name1, name2, name3, name4, name5, name6, name7, name8, name9 FROM test_insert_src;
TRUNCATE TABLE test_insert_1_index;
INSERT INTO test_insert_1_index (name, name1, name2, name3, name4, name5, name6, name7, name8, name9) SELECT name, name1, name2, name3, name4, name5, name6, name7, name8, name9 FROM test_insert_src;
TRUNCATE TABLE test_insert_2_index;
INSERT INTO test_insert_2_index (name, name1, name2, name3, name4, name5, name6, name7, name8, name9) SELECT name, name1, name2, name3, name4, name5, name6, name7, name8, name9 FROM test_insert_src;
TRUNCATE TABLE test_insert_3_index;
INSERT INTO test_insert_3_index (name, name1, name2, name3, name4, name5, name6, name7, name8, name9) SELECT name, name1, name2, name3, name4, name5, name6, name7, name8, name9 FROM test_insert_src;
TRUNCATE TABLE test_insert_4_index;
INSERT INTO test_insert_4_index (name, name1, name2, name3, name4, name5, name6, name7, name8, name9) SELECT name, name1, name2, name3, name4, name5, name6, name7, name8, name9 FROM test_insert_src;
TRUNCATE TABLE test_insert_5_index;
INSERT INTO test_insert_5_index (name, name1, name2, name3, name4, name5, name6, name7, name8, name9) SELECT name, name1, name2, name3, name4, name5, name6, name7, name8, name9 FROM test_insert_src;
TRUNCATE TABLE test_insert_6_index;
INSERT INTO test_insert_6_index (name, name1, name2, name3, name4, name5, name6, name7, name8, name9) SELECT name, name1, name2, name3, name4, name5, name6, name7, name8, name9 FROM test_insert_src;
TRUNCATE TABLE test_insert_7_index;
INSERT INTO test_insert_7_index (name, name1, name2, name3, name4, name5, name6, name7, name8, name9) SELECT name, name1, name2, name3, name4, name5, name6, name7, name8, name9 FROM test_insert_src;
TRUNCATE TABLE test_insert_8_index;
INSERT INTO test_insert_8_index (name, name1, name2, name3, name4, name5, name6, name7, name8, name9) SELECT name, name1, name2, name3, name4, name5, name6, name7, name8, name9 FROM test_insert_src;
TRUNCATE TABLE test_insert_9_index;
INSERT INTO test_insert_9_index (name, name1, name2, name3, name4, name5, name6, name7, name8, name9) SELECT name, name1, name2, name3, name4, name5, name6, name7, name8, name9 FROM test_insert_src;
TRUNCATE TABLE test_insert_10_index;
INSERT INTO test_insert_10_index (name, name1, name2, name3, name4, name5, name6, name7, name8, name9) SELECT name, name1, name2, name3, name4, name5, name6, name7, name8, name9 FROM test_insert_src;