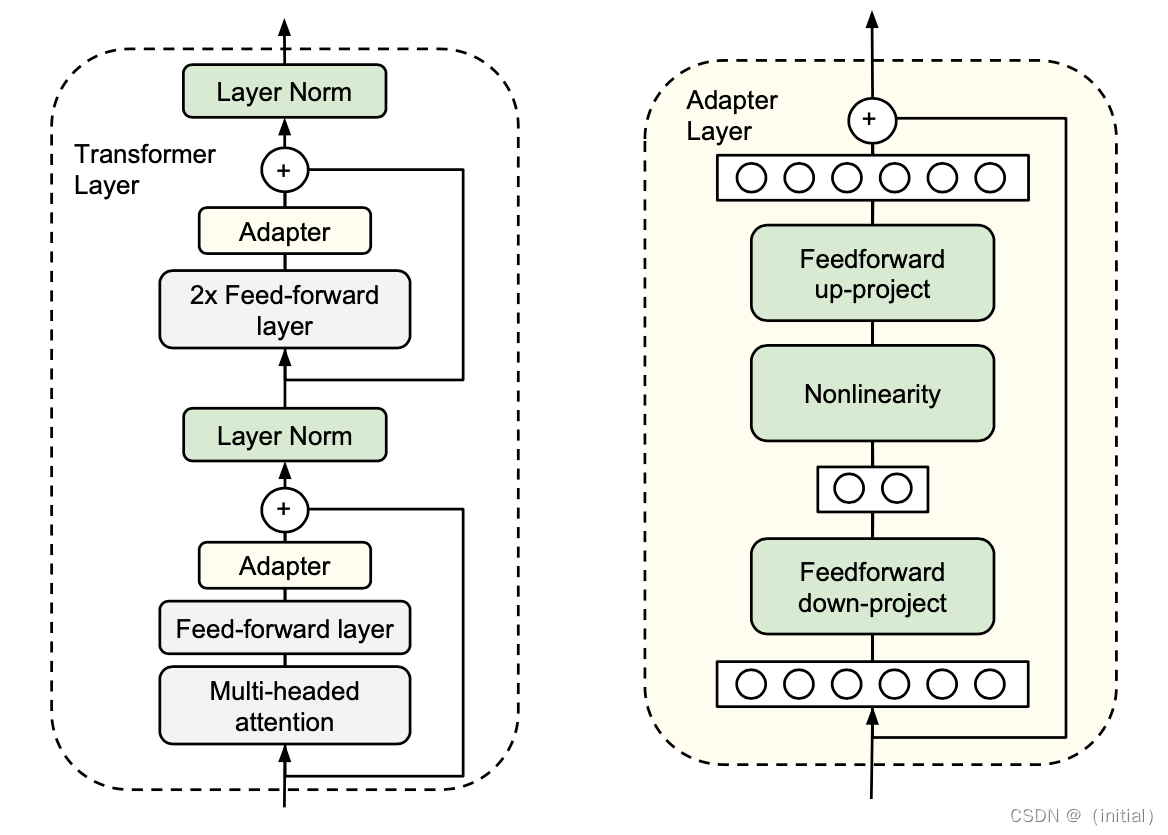
排序算法是数据结构相关知识中非常重要的一节,相信很多小伙伴对这部分知识一知半解。那么接下来,小编就要带领大家一起来进行对排序算法的深入剖析学习,希望本篇文章能够使你有所收获!
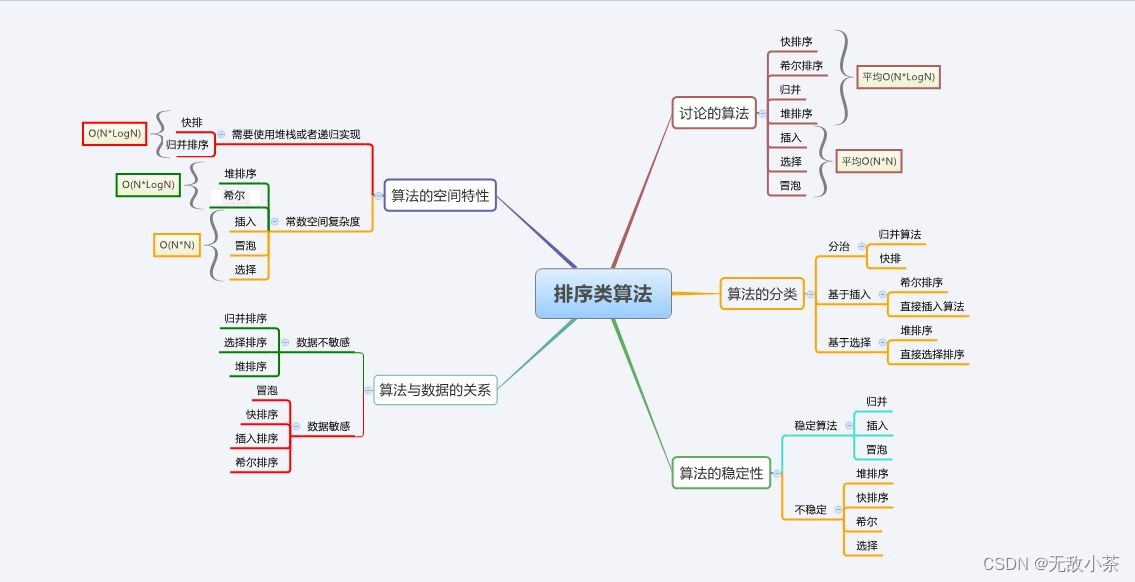
一.常见的排序算法
排序算法有很多种,为了使同学们有一个比较系统的了解,小编找了一张图片,用以加深同学们的理解:
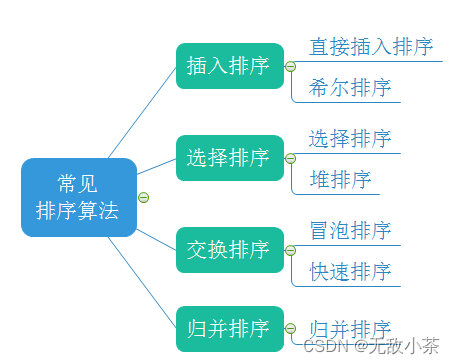
那么接下来,我们就对上图所提到的排序算法进行一一细致的学习吧!
二..插入排序
插入排序,就是把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为 止,得到一个新的有序序列 。
我们平时玩扑克牌,就是运用到了插入排序的思想。
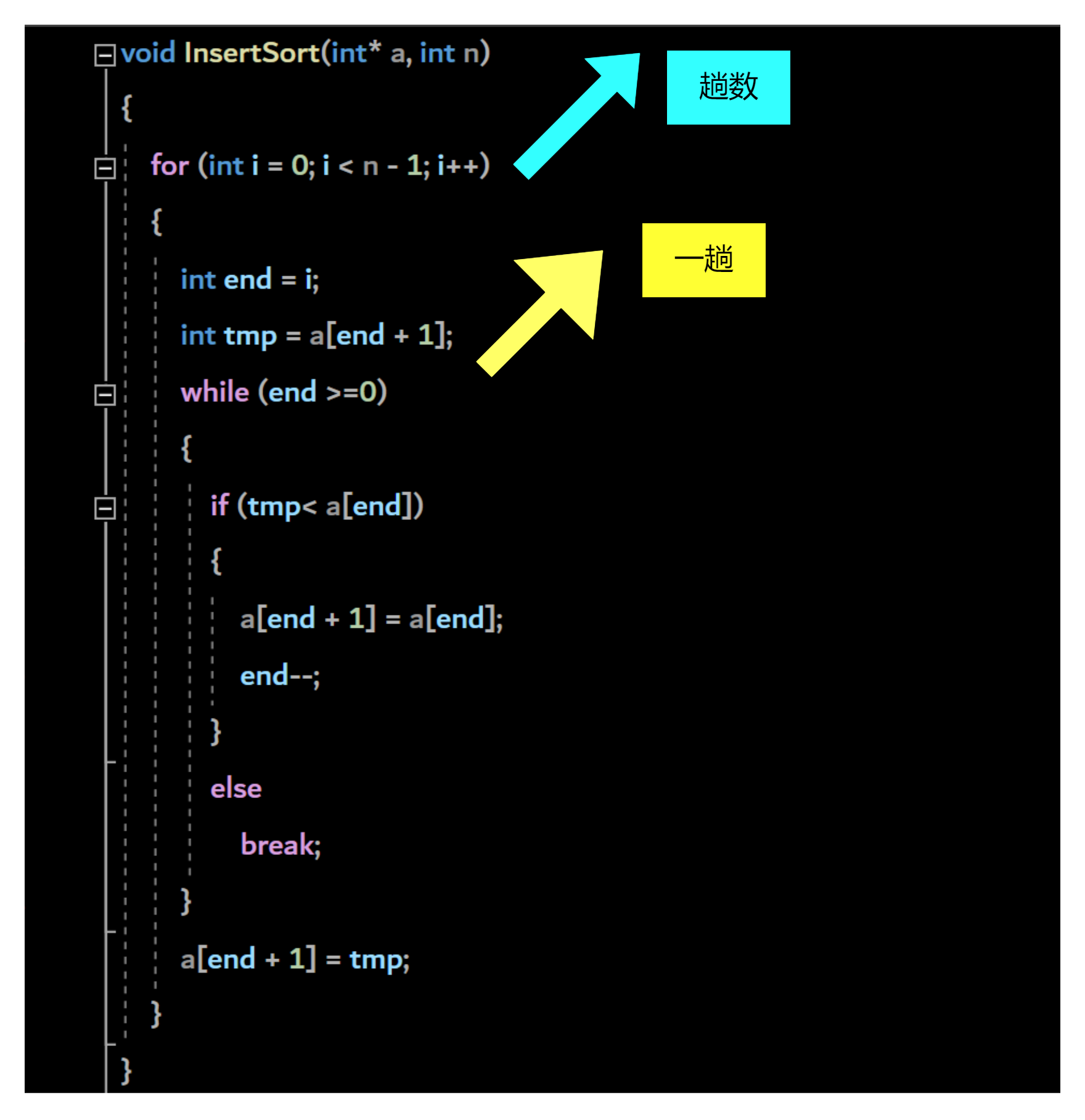
代码展示:
时间复杂度问题:
插入排序最好的时间复杂度是O(N) (当数组元素顺序时)
最坏时间复杂度是是O(N^2) (当数组元素逆序时)
三.希尔排序
只有掌握好插入排序,才会有可能掌握希尔排序。希尔排序是建立在插入排序的基础之上。
希尔排序分为两步:1.预排序(让数组接近有序 注意预排序是多次)
2.插入排序
其中,预排序是将数组分为gap组,每一组中的数是原数组间隔了gap个数而划分的,间隔为gap,亦将数组划分为gap组。
希尔排序的特性总结:
1. 希尔排序是对直接插入排序的优化。
2. 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就 会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。
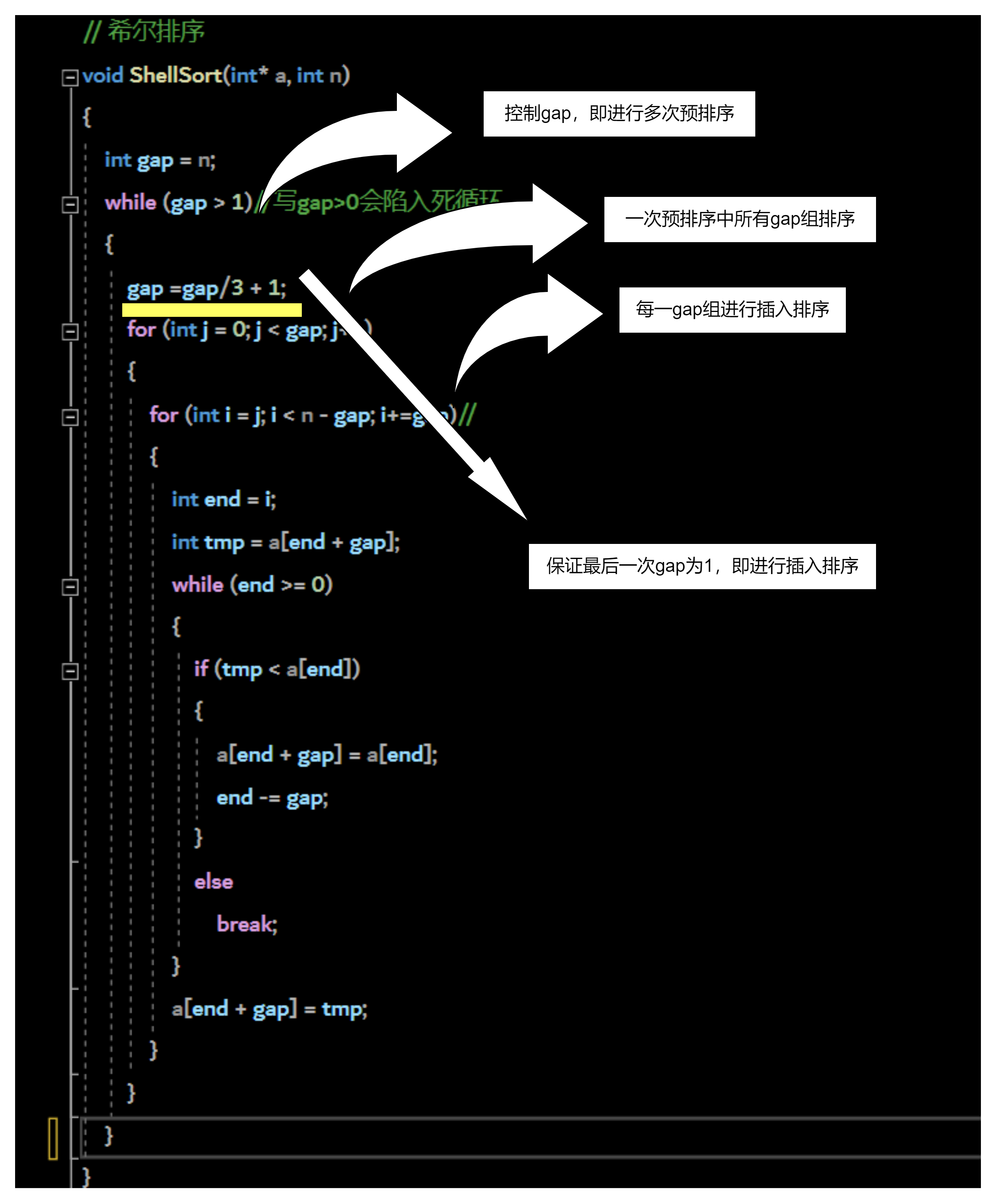
代码展示:

为了方便同学们理解代码,老师做了详细的批注:
时间复杂度问题分析:
希尔排序的复杂度问题分析非常复杂,我们不做过多研究,我们只告诉大家希尔排序的平均时间复杂度:
O(N^1.3)
四.堆排序
堆排序相信大家都不陌生,早在堆的实现中,我们就已经涉及到了堆的相关知识,那么我们就一起来温习一下吧!
堆排序包括两步:
1.向下调整建堆
2.堆排序
代码展示: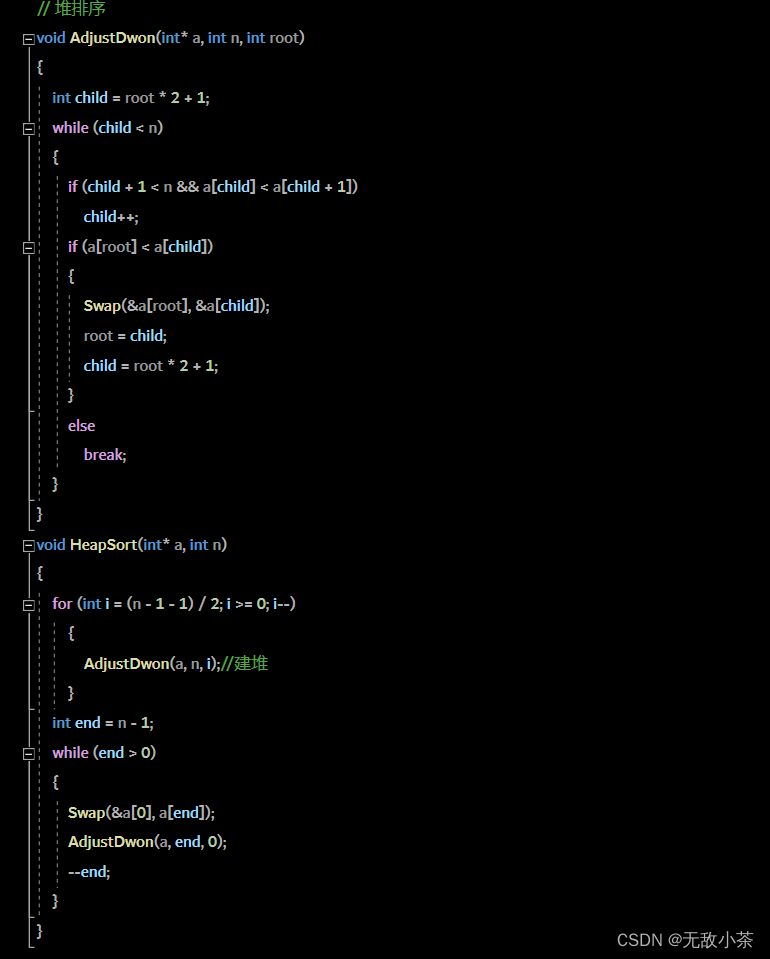
堆排序示意图:
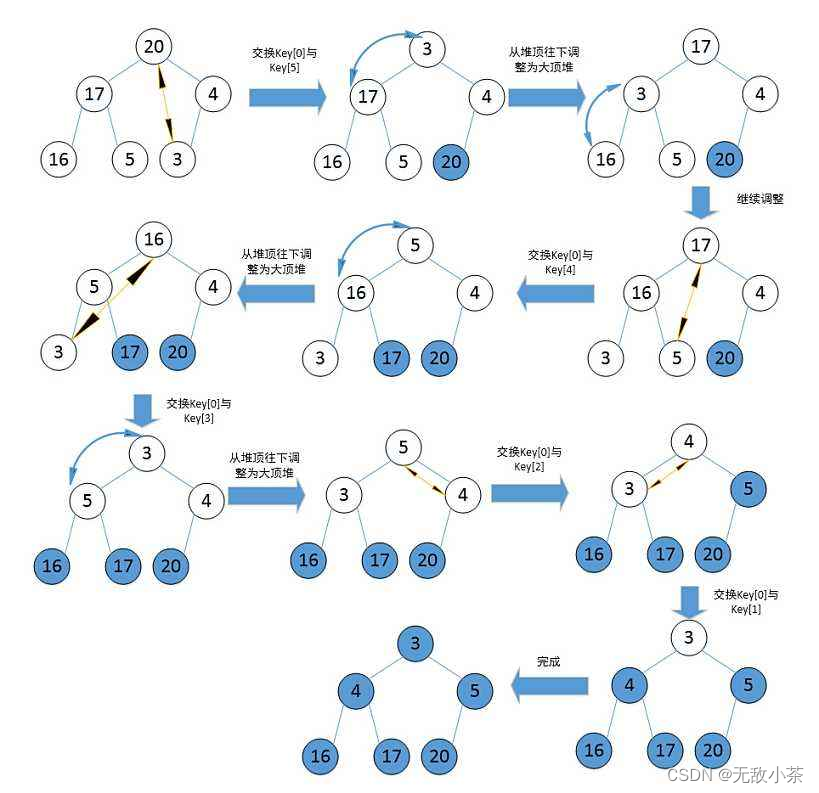
(注意:升序建大堆 降序建小堆 本代码建的是大堆 堆排序具有实践意义,堆排序使用堆来选数,效率就高了很多。)
堆排序时间复杂度:
O(N*logN)
五.选择排序
每一次从待排序的数据元素中选出最小(或/和 最大)的一个元素,存放在序列的起始位置,直到全部待排序的 数据元素排完 。
代码展示:
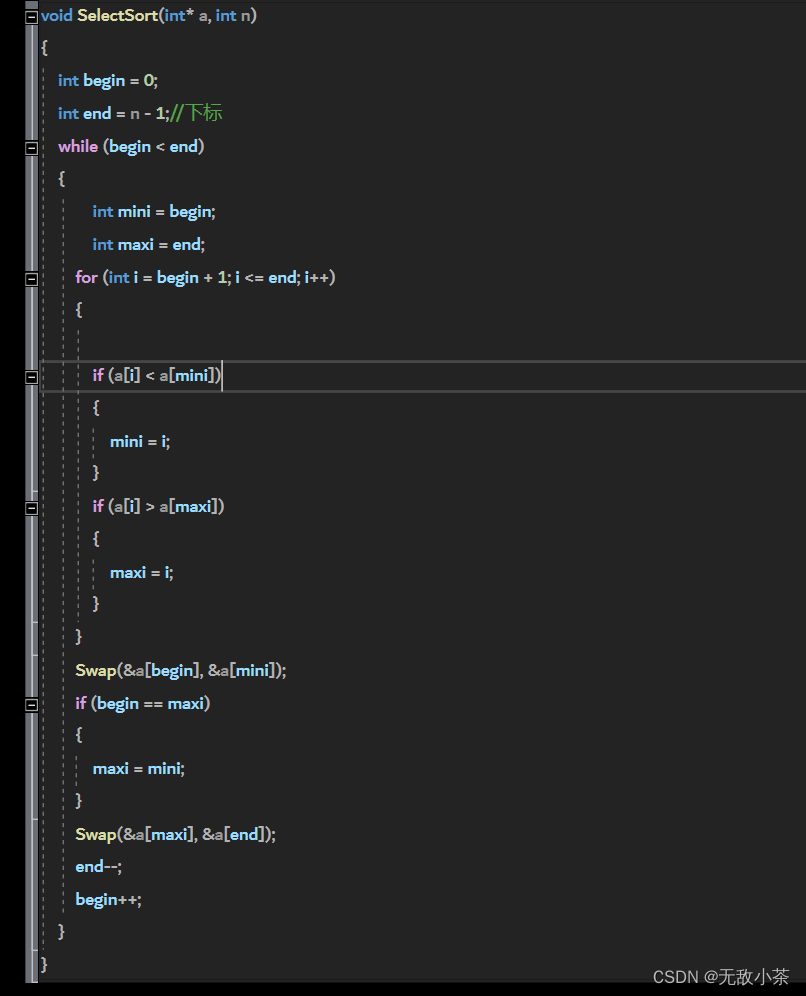
时间复杂度:
O(N^2)
本代码是优化后的选择排序的代码,我们直接同时寻找最小和最大的两个元素,分别放在序列的最左边和最右边。
六.冒泡排序
冒泡排序相信大家都不陌生,那么话不多说,我们直接上代码来展示一下:
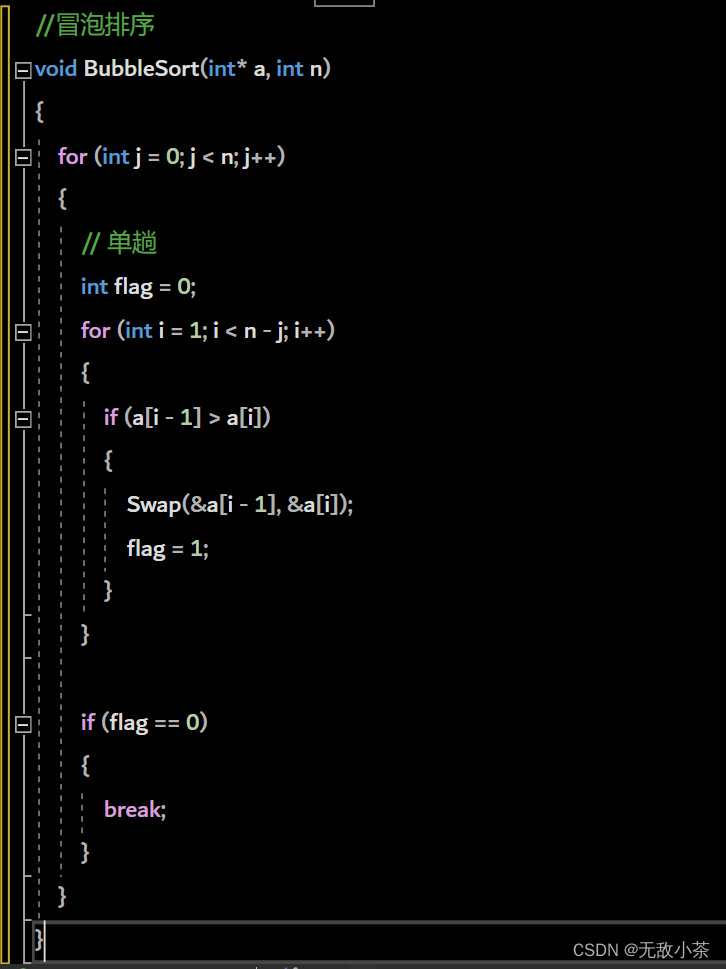
这里我们展示的代码是优化版本的冒牌排序(设立了flag 放置有序情况下效率降低)
冒泡排序的时间复杂度:
最坏情况下时间复杂度:O(N^2)
最好情况下时间复杂度:O(N) (数组顺序)
七.快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:
任取待排序元素序列中 的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
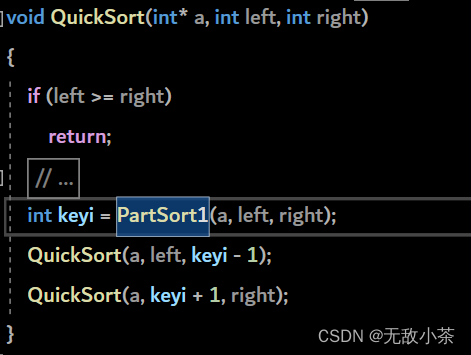
(一)递归算法
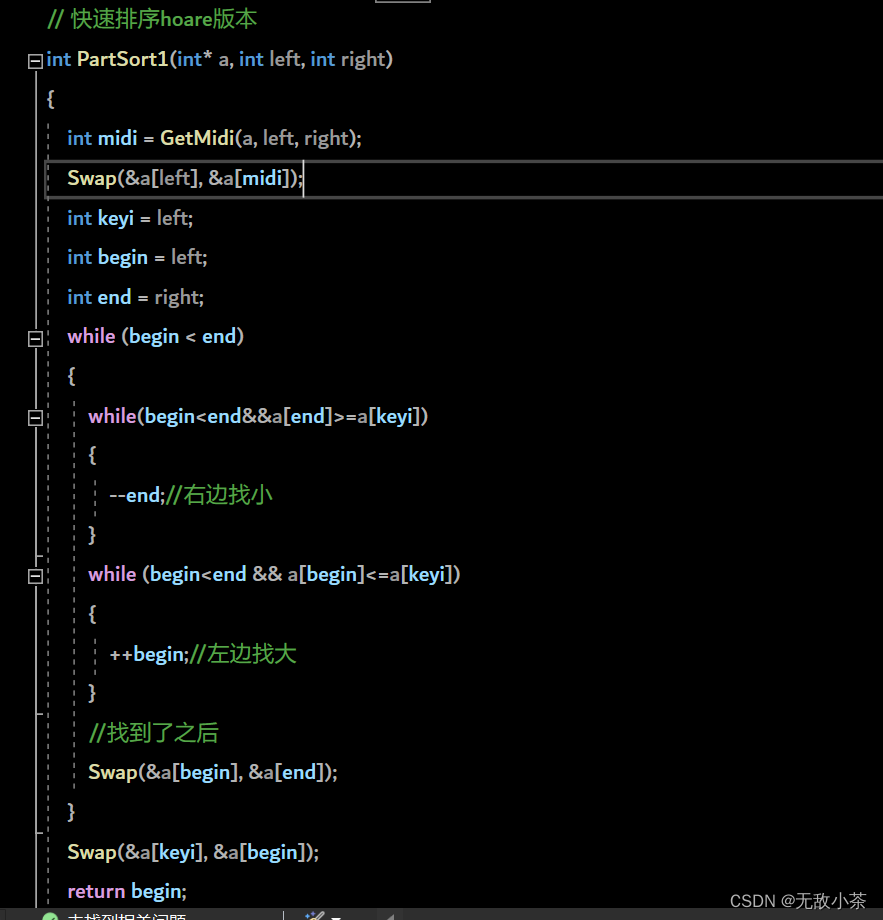
(1).霍尔版本
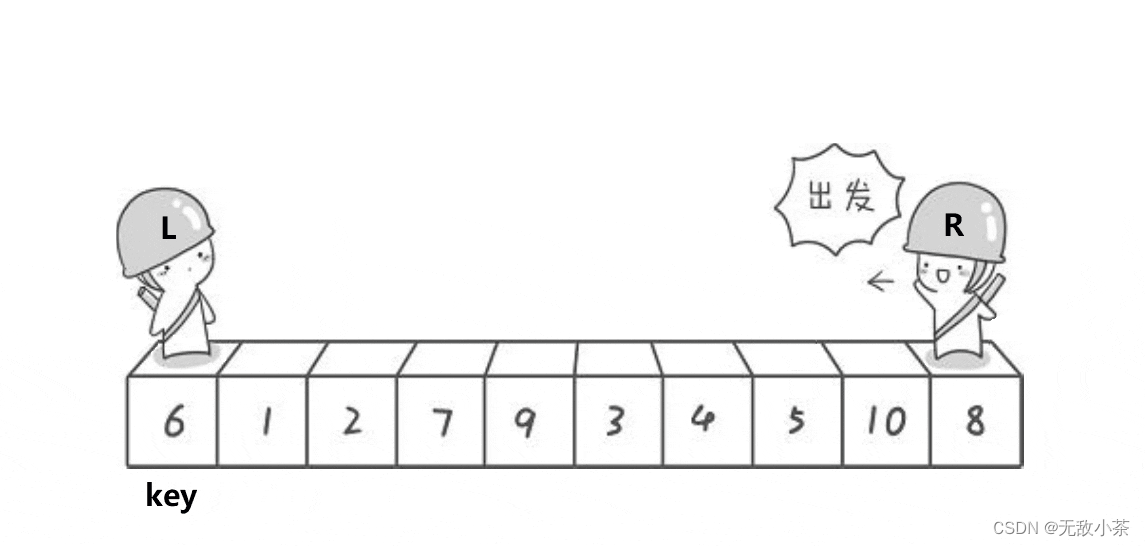
代码展示:
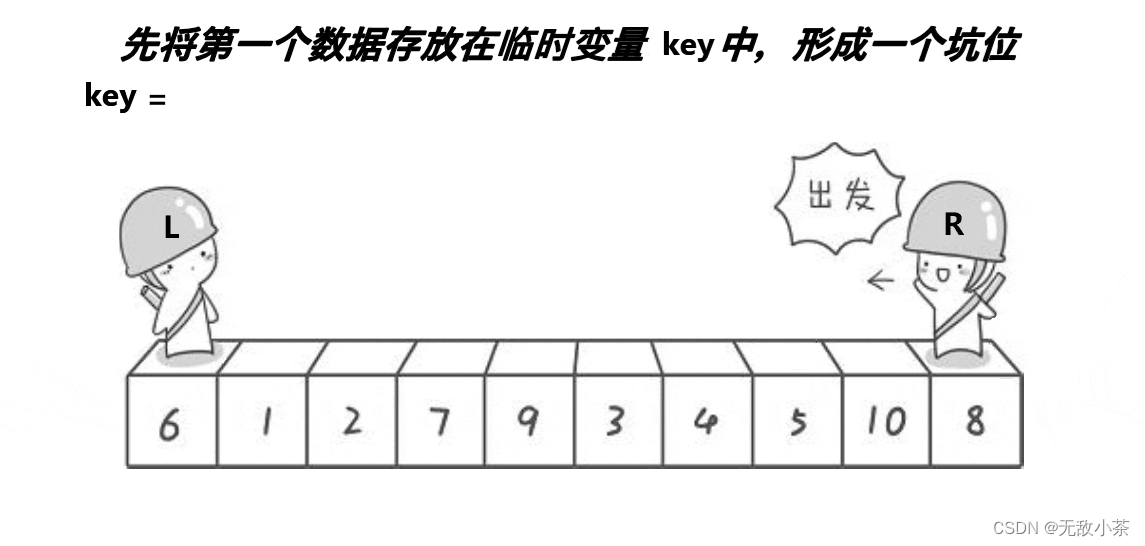
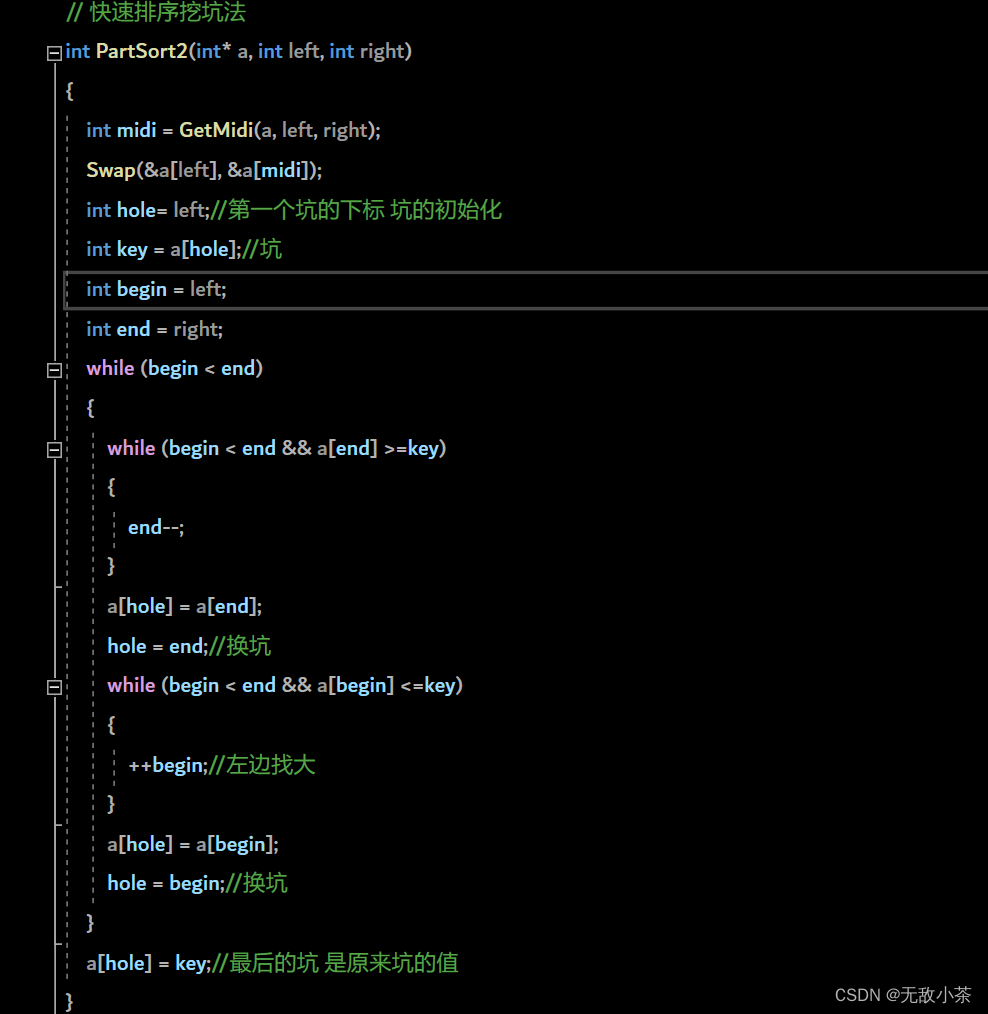
(2).挖坑法
代码展示:
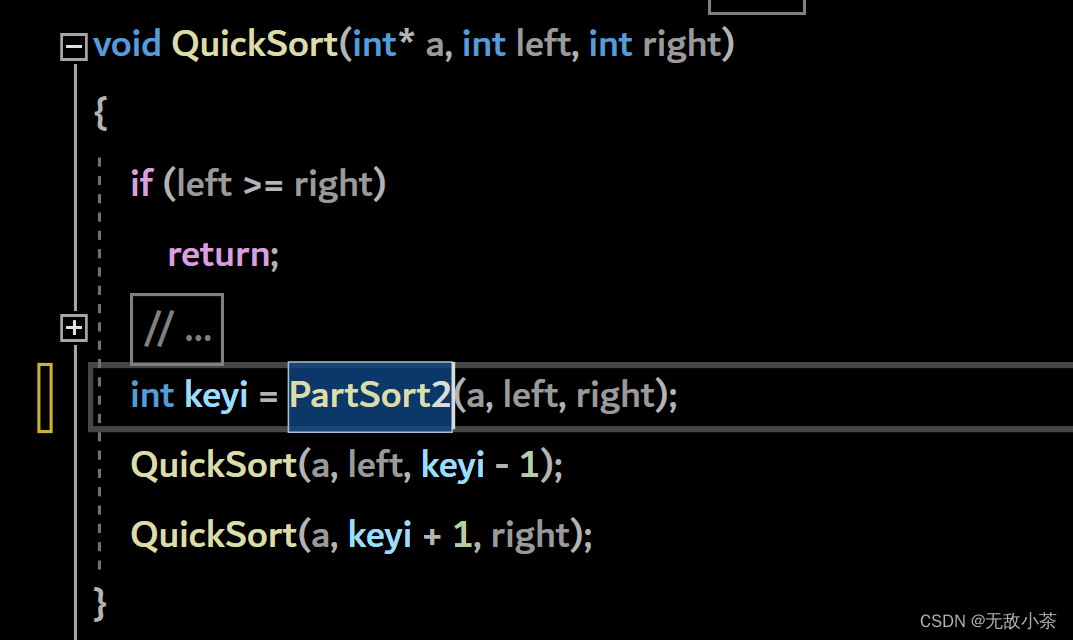
(3).前后指针法

代码展示:
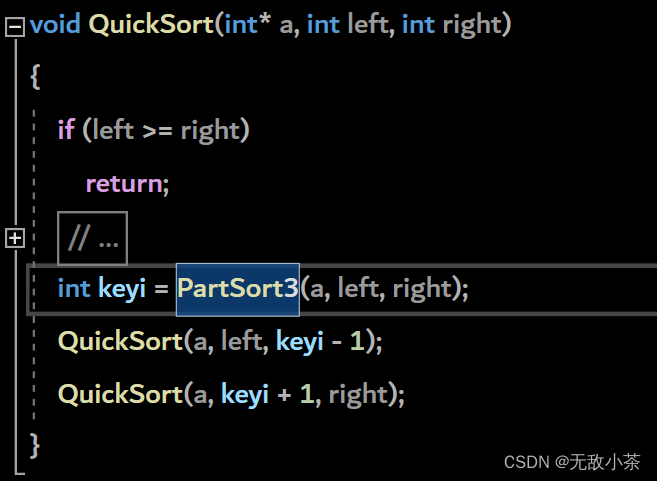
快速排序的时间复杂度:
O(NlogN) (每一层的次数N*层数logN)
注意:
以上代码均是优化后的快速排序算法。快速排序算法的优化:
1.三数取中选择keyi值(避免有序情况下效率退化)(O(N*N)
2.小区间递归优化(当要排序个数小于10时,我们可以采用插入排序。其目的是不再进行递归分割,减小递归深度,防止溢出。)
(二)非递归算法
光是掌握快速排序的递归算法是远远不够的,我们还需要掌握它的非递归算法: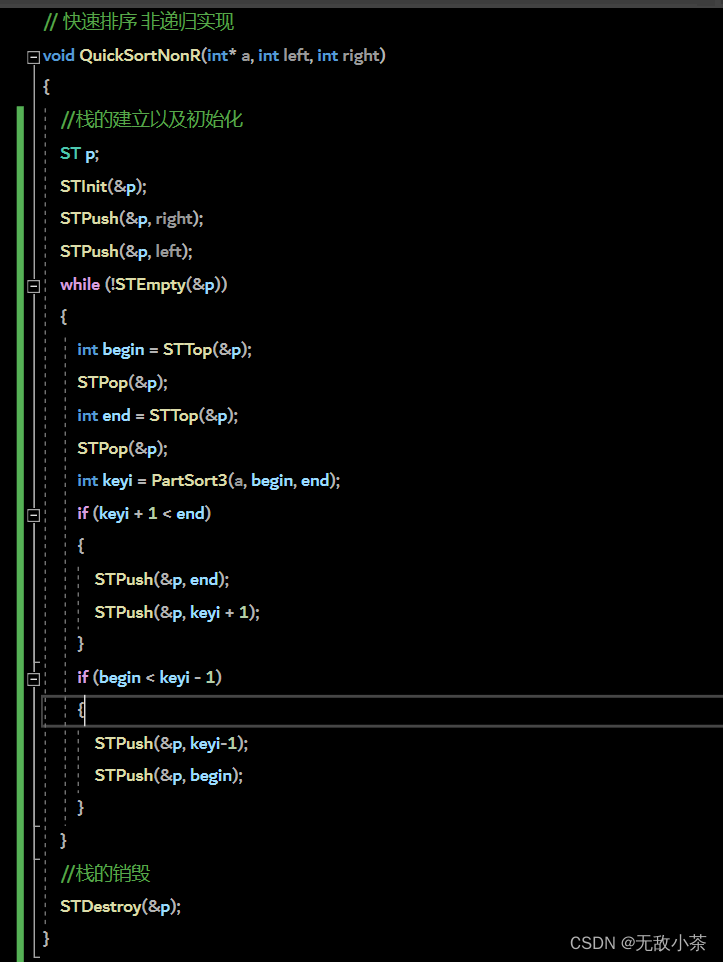
我们借助栈实现了快速排序的非递归算法。
八.归并排序
归并排序,简而言之,我们将其总结为“分而治之”。分,即将待排数组分成一个个有序的序列,治,即排序,将这些有序的序列合并,得到完全有序的数组。
(一)递归算法
相信借助下图你可以对归并排序有一个更深入的理解:
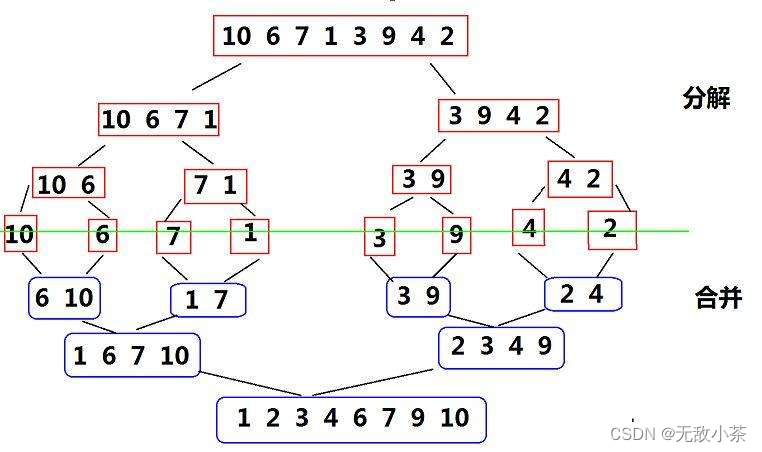
代码展示:
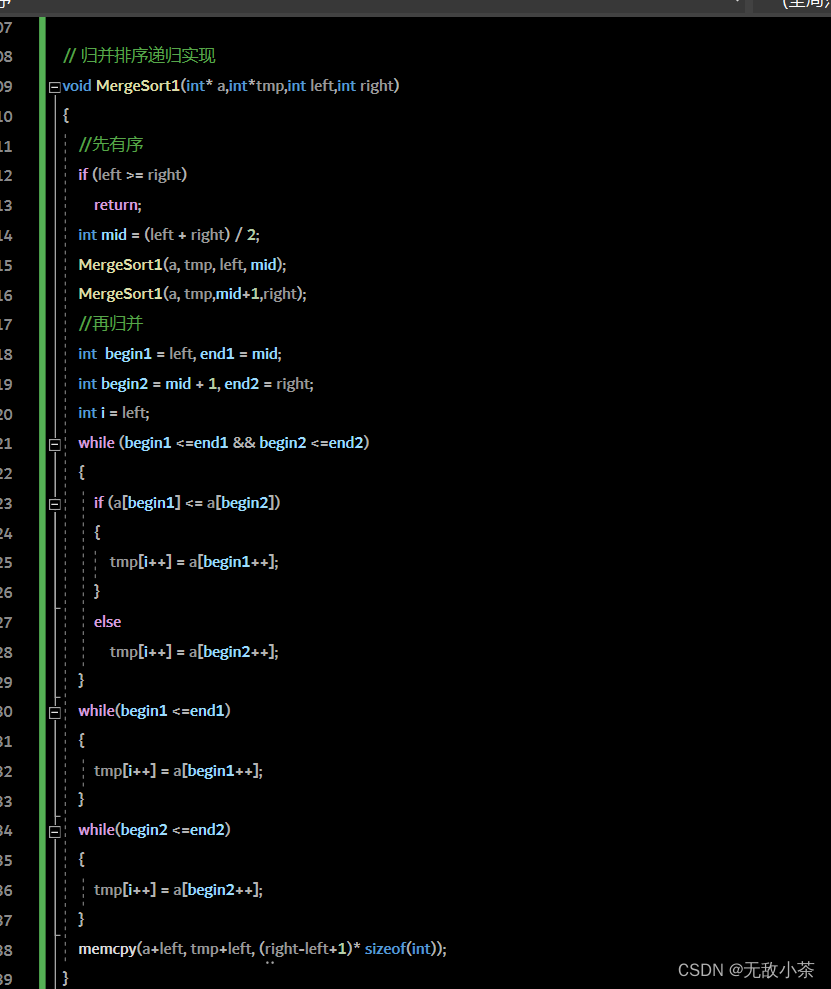
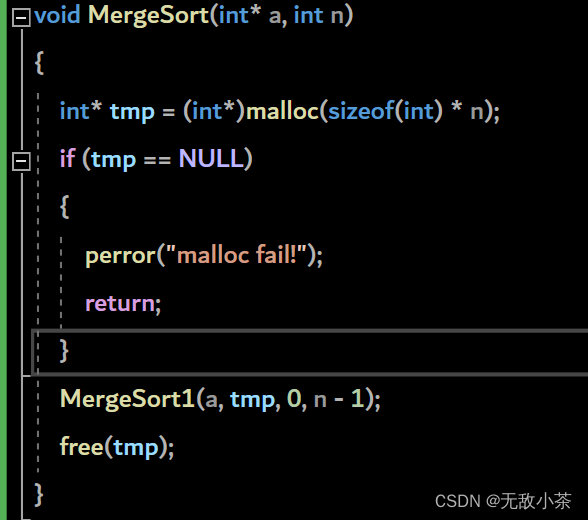
归并排序的时间复杂度分析:
O(N*logN) (每一层的次数N*层数logN)
归并排序的空间复杂度:
O(N) (开辟了一个tmp数组)
(二)非递归算法
我们可以借助栈来实现归并排序的非递归算法: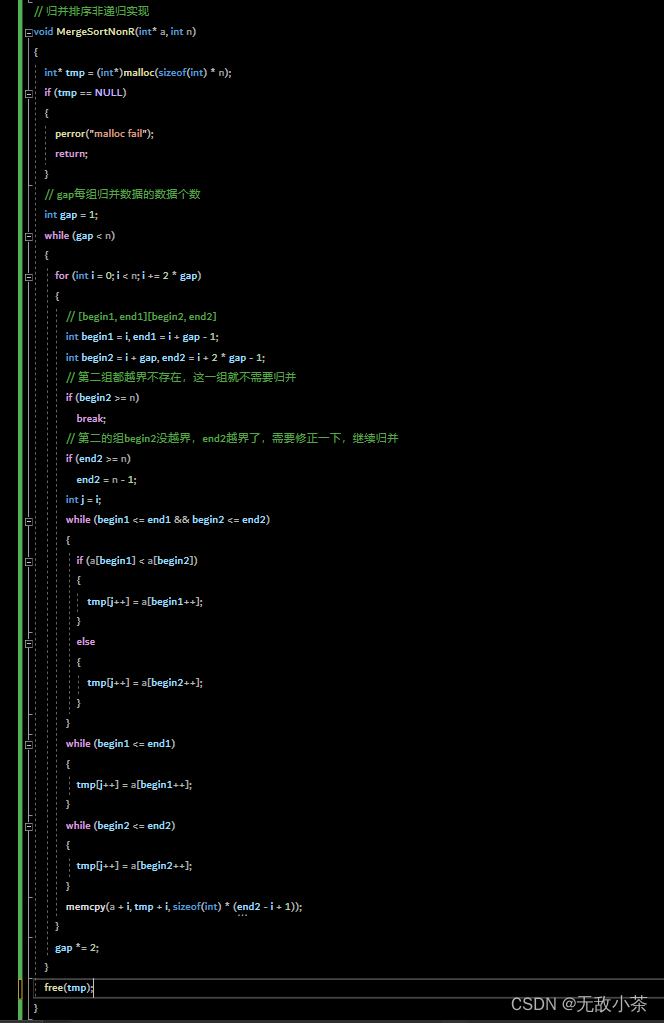
注意:这里要谨防数组边界越界问题。
九.计数排序
计数排序是非比较排序的一种,它的实现原理非常的巧妙。
1.建立count数组,统计元素出现的次数
2.根据元素出现的次数回馈到原数组(排序)
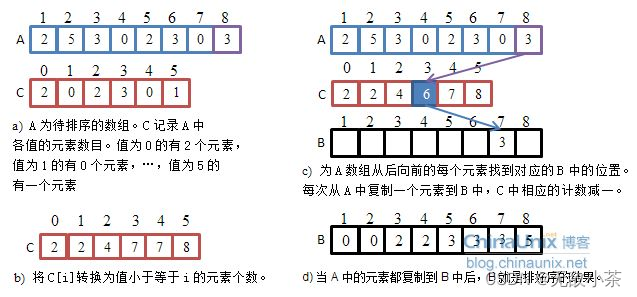
代码展示:
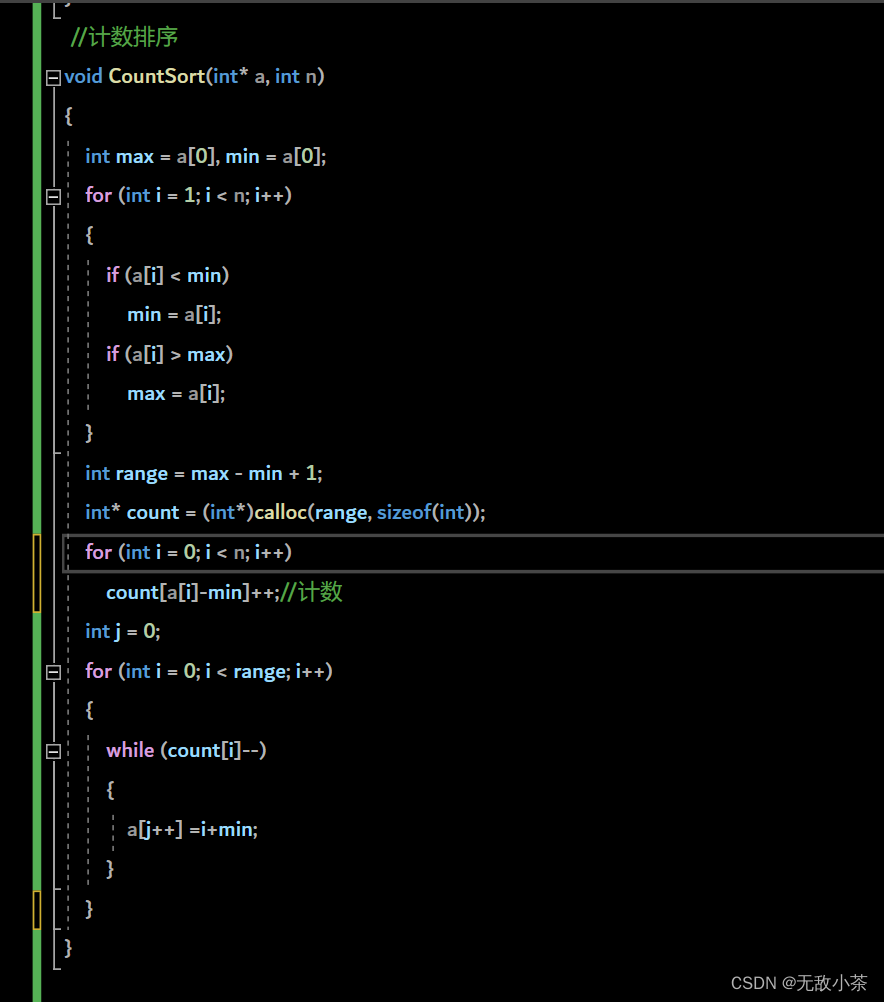
本着减少空间浪费的原则,本代码采用了相对映射的方法。即设立一个range变量。在计数的时候,count的下标写为a[i]-min,在排序的时候,a[j]的值赋值为i+mi。count的下标存储的就是数值。
计数排序适用于数据较为集中且数据为整数的情况。
计数排序的时间复杂度:
O(MAX(range,N))
计数排序的空间复杂度:
Q(N) (开辟了一个数组用以计数)
十.排序算法的稳定性分析
稳定性:
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次 序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排 序算法是稳定的;否则称为不稳定的。
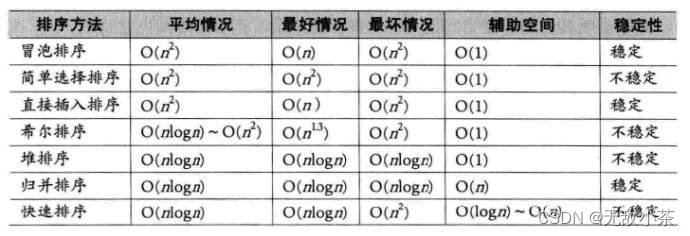
那么下面这个表格可以帮你快速梳理一下排序算法的相关性质:
今天关于排序算法的讲解就到这里,相信坚持学习到这里的小伙伴一定收获满满!如果有相关问题,欢迎大家私信留言!小编一定竭尽所能为大家指点迷津!我们下次再会!