gcc源码分析 词法和语法分析
- 一、输入参数相关
-
- 1、命令行到gcc
- 二、词法与语法分析
-
- 1、词法分析
-
- 1.1 struct cpp_reader
- 1.2 struct tokenrun/struct cpp_token/lookahead字段
- 1.3 struct ht
- 2.1 语法符号相关的结构体c_token定义如下:
- 2.2在语法分析中实际上有多个API组成了其接口函数,主要包括:
- 3、语法分析中声明说明符的解析
-
- 3.1 c_parse_file ();
- 3.2 声明说明符的解析(c_parser_declaration_or_fndef)
-
- 3.2.1 声明说明符解析流程概述
- 3.2.2声明说明符结构体
- 3.2.3 声明说明符的解析
- 3.3 说明符的解析(c_parser_declaration_or_fndef)
-
- 3.3.1 c_parser_declaration_or_fndef函数
- 3.3.2 c_parser_declarator函数
- 3.3.3 c_parser_direct_declarator函数
- 3.3.4 c_parser_parms_list_declarator函数
- 3.3.5 c_parser_parameter_declaration函数
- 3.3.6 c_parser_declarator函数
- 3.3.7 get_parm_info函数
- 4 语法分析对声明和函数定义解析
-
- 4.1 基本流程
- 4.2 过程分析
-
- 4.2.1 产生式
- 4.2.2 解析函数定义具体流程
- 4.2.3 函数定义相关流程小结
一、输入参数相关
gcc本质上类似于一个驱动器,编译阶段为例,gcc的参数解析有两部分:命令行到gcc;gcc再到cc1
1、命令行到gcc
编译出的gcc二进制程序只是一个编译的驱动,内部实际要调用cc1,as,collect来进行编译,汇编和连接,下图展示了整个过程的基本流程:
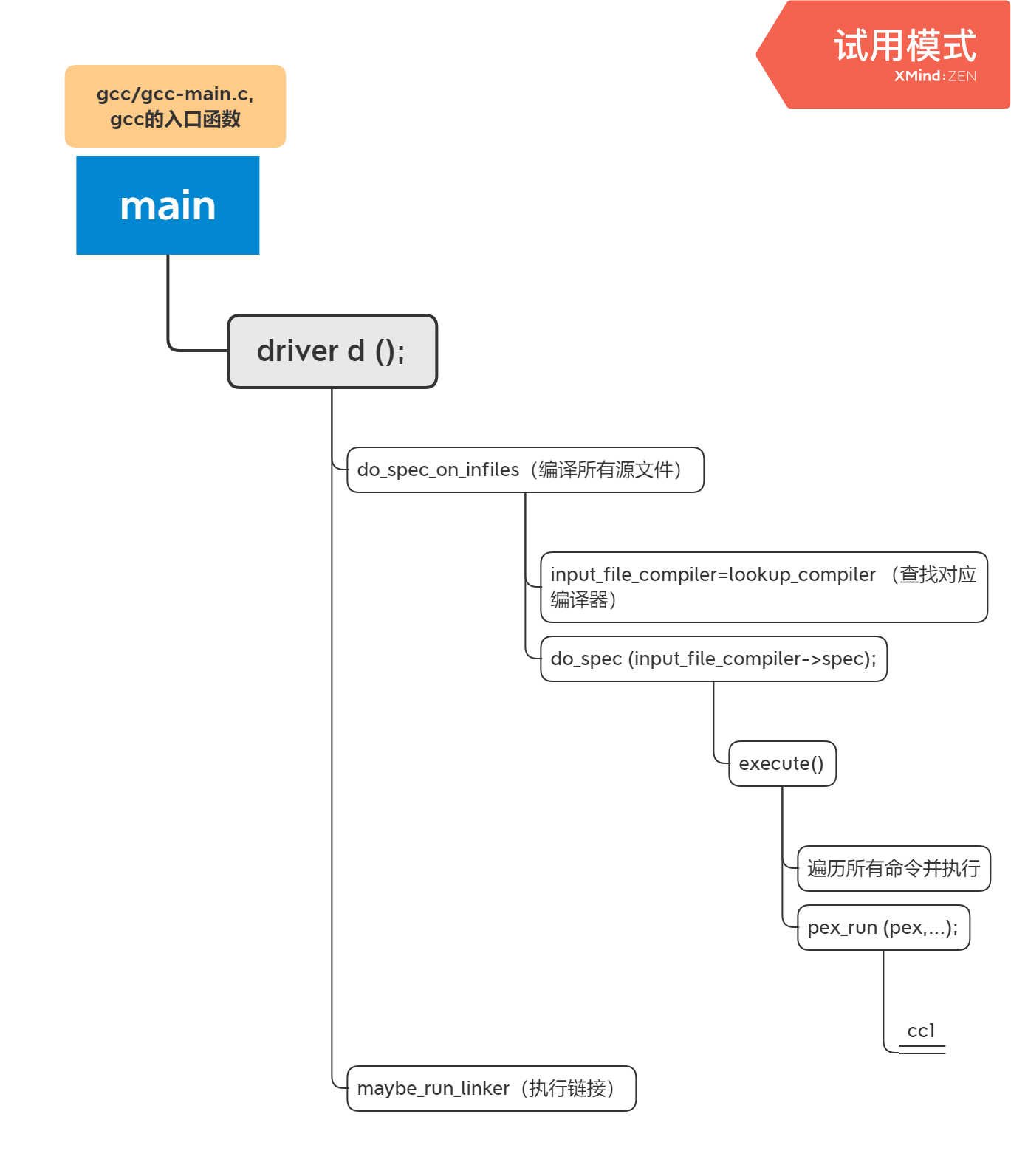
cc1一次只能处理一个源码进行编译,对参数进行分析时gcc和cc1用的是一套代码,主要依赖gcc下的options.c和options.h中的用户参数数组
##2、gcc到cc1
主要在toplev的实现:
(1)将选项转换为数组
decode_cmdline_options_to_array_default_mask (argc,
CONST_CAST2 (const char **,
char **, argv),
&save_decoded_options,
&save_decoded_options_count);
(2)将saved_decoded_options中的大部分参数都转化为global_options中的flags
decode_options (&global_options, &global_options_set,
save_decoded_options, save_decoded_options_count,
UNKNOWN_LOCATION, global_dc);
(3)对global_options等参数的处理
if (!exit_after_options)
{
if (m_use_TV_TOTAL)
start_timevars ();
do_compile ();
}
二、词法与语法分析
1、词法分析
1.1 struct cpp_reader
gcc的词法分析的主要代码是从cc1(如./gcc/c-family/c-lex.c) => libcpp(如./gcc/libcpp/lex.c)中的**,其API接口函数为接口函数_cpp_lex_token,真正解析词法正则表达式的函数为_cpp_lex_direct。
从源码到词法分析结束过程,与词法分析相关的的信息都记录在parse_in结构体中,或者通过此结构体索引到,因此可以从parse_in展开分析。
parse_in的初始化过程:
toplev::main
=> general_init (argv[0], m_init_signals);
=> init_stringpool (void) //1) 为全局变量struct ht* ident_hash分配空间并初始化alloc_node
=> lang_hooks.init_options (save_decoded_options_count, save_decoded_options);
=> parse_in = cpp_create_reader()
=> _cpp_init_hashtable (pfile, table); //2)设置parse_in->hash_table = ident_hash, 作为词法解析过程中的全局标识符hash表
cpp_reader
##./gcc/c-family/c-common.c
cpp_reader *parse_in;
//主要有以下三个场景
//1) 这里主要是对全局变量parse_in的初始化
//2) 这里主要负责打开并读入编译单元文件
//3) 这里每一次的词法分析(获取一个token)都要用到parse_in
##./libcpp/internal.h //这里只记录部分结构体成员
struct cpp_reader //省略部分代码
{
/*
buffer是一个链表,每一个元素都记录了一个文件内容存储位置,此文件当前解析到哪里了和文件结构体指针等信息.
此时会push新的文件到buffer,新的文件会先被解析,直到解析完成再返回原有buffer继续解析,因此这里会出现buffer列表.
*/
cpp_buffer *buffer;
struct lexer_state state;
struct line_maps *line_table; //所有源码的行号信息在这里索引
/* The line of the '#' of the current directive. */
location_t directive_line;
/* If in_directive, the directive if known. */
const struct directive *directive;
/* Token generated while handling a directive, if any. */
cpp_token directive_result;
source_location invocation_location;
struct _cpp_file *all_files; //词法分析过程中,所有打开的文件都会记录到这里
struct _cpp_file *main_file; //当前cc1编译的主文件
/* Lexing. 以下是具体词法分析相关成员 */
cpp_token *cur_token; //在词法分析中,每个符号都存储为一个cur_token结构体
/*
一个tokenrun中主要存储了一个cpp_token的数组,这个数组是一次性分配的,每次解析一个新的token,就会让cur_token++,指向下一个位置.
当token_run不够时,就会分配一个新的token_run,所有的token_run都是通过自身的链表链接的。
* base_run记录系统中第一个分配的cpp_token[]数组的信息
* cur_run指向当前正在使用的token_run结构体的指针,实际上也是最后一个分配的token_run的指针.
*/
tokenrun base_run, *cur_run;
/*
之前词法分析预先解析出多少个cpp_token,这些预先解析出来的cpp_token,实际上就存在
cur_token[0] - cur_token[lookaheads] 中,下次解析如果有预解析的token,直接cur_token++即可
*/
unsigned int lookaheads;
/*
此成员代表标识符的hash表,其以hash表为结构,记录了词法分析中分析出的所有标识符的指针(相同标识符系统内是只一份存储的)
- 其entries[]是一个记录标识符地址指针的数组,这个数组就是这里的hash表。
- 其alloc_node函数是用来为标识符分配存储空间的
- 标识符的hash是根据其字符串的每个字符和字符串长度来确定的
若hash冲突,则会循环用二次hash算法找下一个位置
注意这里只是个指针,通常指向全局变量 ident_hash
*/
struct ht *hash_table;
};
1.2 struct tokenrun/struct cpp_token/lookahead字段
在词法分析过程中所有词法符号在编译过程中会一直保留,每个cpp_token结构都代表词法分析中分析出一个符号,整个编译过程中需要大量的此结构体,struct tokenrun就是来记录这些结构体的数组信息,在parse_in结构体中有一个lookahead字段记录在当前的tokenrun中有多少个预读的cpp_token,由于cpp_token是数组顺序排列的,获取下一个token只需 cur_token ++。
##./libcpp/internal.h
struct tokenrun
{
tokenrun *next, *prev; /* tokenrun是一个双向链表,next/prev是后/前向指针, 系统中第一个tokenrun的指针保存在 parse_in->base_run中*/
cpp_token *base, *limit;
};
cpp_token是用来保存一个词法元素的结构体,词法元素可以是标识符,数字,字符串,或操作符如+等(在cpp_lex_direct 中的分类),在词法分析过程中每确认一个词法元素就会生成一个cpp_token结构体来保存此词法元素的信息
struct GTY(()) cpp_token {
source_location src_loc; /* 记录第一个元素的源码位置 */
ENUM_BITFIELD(cpp_ttype) type : CHAR_BIT; /* token type */
unsigned short flags; /* flags - see above */
union cpp_token_u /*为各个元素建立值节点,不同的词法元素使用不同的结构体*/
{
/* An identifier. */
struct cpp_identifier GTY ((tag ("CPP_TOKEN_FLD_NODE"))) node;
/* Inherit padding from this token. */
cpp_token * GTY ((tag ("CPP_TOKEN_FLD_SOURCE"))) source;
/* A string, or number. */
struct cpp_string GTY ((tag ("CPP_TOKEN_FLD_STR"))) str;
/* Argument no. (and original spelling) for a CPP_MACRO_ARG. */
struct cpp_macro_arg GTY ((tag ("CPP_TOKEN_FLD_ARG_NO"))) macro_arg;
/* Original token no. for a CPP_PASTE (from a sequence of
consecutive paste tokens in a macro expansion). */
unsigned int GTY ((tag ("CPP_TOKEN_FLD_TOKEN_NO"))) token_no;
/* Caller-supplied identifier for a CPP_PRAGMA. */
unsigned int GTY ((tag ("CPP_TOKEN_FLD_PRAGMA"))) pragma;
} GTY ((desc ("cpp_token_val_index (&%1)"))) val;
};
1.3 struct ht
这个结构体作为字符串的hash table,其存储的元素固定为struct ht_identifier。
struct GTY(()) ht_identifier {
const unsigned char *str; //标识符的字符串名的指针
unsigned int len; //字符串名的长度
unsigned int hash_value; //字符串的hash
};
ht表中的entries字段指向一个hashnode[]数组,其每个元素都是一个hashnodehashnode这个指针真正指向的才是一个struct ht_identifier结构体。
struct ht
{
/* Identifiers are allocated from here. */
struct obstack stack;//hash表中的内存分配
hashnode *entries;//指向hashnode[]数组的首地址,数组中的每个元素都记录了一个具体元素的指针(所以每个元素叫做一个hashnode),hashnode具体的元素则是一个 ht_identifer结构体
/* Call back, allocate a node. */
hashnode (*alloc_node) (cpp_hash_table *);//alloc_node函数是用来分配节点内存的
/* Call back, allocate something that hangs off a node like a cpp_macro. NULL means use the usual allocator. */
void * (*alloc_subobject) (size_t);
unsigned int nslots; /* entires 数组大小 */
unsigned int nelements; /* entries中已使用的位置个数 */
/* Link to reader, if any. For the benefit of cpplib. */
struct cpp_reader *pfile; /*指向对应的cpp_reader*/
/* Table usage statistics. */
unsigned int searches;/* 记录当前的ht结构体被搜索过的次数 */
unsigned int collisions;/* 记录hash冲突的次数 *
/* Should 'entries' be freed when it is no longer needed? */
bool entries_owned;
};
##2、词法符号与语法符号
c语言的语法分析过程可以理解为:提前预读词法符号的自顶向下的语法推导过程。在词法分析中会将源码解析为词法符号,在语法分析的开始,将词法符号转换为语法符号,主要以下两个方面:
- 将词法符号中的节点转换为具体AST树节点,AST树结点可代表源码整个内容
- 确定词法符号中的标识符的类型
2.1 语法符号相关的结构体c_token定义如下:
##./gcc/c/c-parser.h
/*c_token结构体来描述一个C语言中的语法符号*/
struct GTY (()) c_token {
/* The kind of token. */
ENUM_BITFIELD (cpp_ttype) type : 8;
/* 记录标识符的类型. */
ENUM_BITFIELD (c_id_kind) id_kind : 8;
/* 若一个标识符是关键字,非关键字的keyword默认为为 RID_MAX */
ENUM_BITFIELD (rid) keyword : 8;
/* 编译制导的标识符 */
ENUM_BITFIELD (pragma_kind) pragma_kind : 8;
/* 记录token在源代码中的位置 */
location_t location;
/* The value associated with this token, if any. */
tree value;
source_range get_range () const
{
return get_range_from_loc (line_table, location);
}
location_t get_finish () const
{
return get_range ().m_finish;
}
};
2.2在语法分析中实际上有多个API组成了其接口函数,主要包括:
-
c_parser_peek_token: 预读一个语法符号c_token
-
c_parser_peek_2nd_token: 预读当前未分析的第二个语法符号
-
c_parser_peek_nth_token: 预读当前未分析的第n个语法符号(n<4)
-
c_parser_consume_token: 消耗掉当前第一个语法符号
前三个函数通过c_lex_one_token函数获取真正的语法符号,并将其保存到c_parse结构体中。
以c_parse_peek_token为例:
##./gcc/c/c-parser.h
static inline c_token *
c_parser_peek_token (c_parser *parser)
{
if (parser->tokens_avail == 0)
{
/* 若parse中没有可用的语法符号了,则通过c_lex_one_token解析出一个语法符号 */
c_lex_one_token (parser, &parser->tokens[0]);
parser->tokens_avail = 1;
}
/* 若parse中有未消耗的符号,则直接拿来用 */
return &parser->tokens[0];
}
c_parser_peek_token函数传入的是全局变量the_parser,c_parser结构体定义如下:
struct GTY(()) c_parser {
/* The look-ahead tokens. */
c_token * GTY((skip)) tokens; /* 当前正在处理的语法符号c_token的地址,应该指向 tokens_buf[0] */
/* Buffer for look-ahead tokens. */
c_token tokens_buf[4]; /* c_token预读缓存,预读不会超过4个语法符号 */
/* How many look-ahead tokens are available (0 - 4, or
more if parsing from pre-lexed tokens). */
unsigned int tokens_avail; /* tokens_buf中可用的预读词法符号的数目 */
/* True if a syntax error is being recovered from; false otherwise.
c_parser_error sets this flag. It should clear this flag when
enough tokens have been consumed to recover from the error. */
BOOL_BITFIELD error : 1; /*是否是错误状态*/
/* True if we're processing a pragma, and shouldn't automatically
consume CPP_PRAGMA_EOL. */
BOOL_BITFIELD in_pragma : 1; /*是否进行编译制导*/
/* True if we're parsing the outermost block of an if statement. */
BOOL_BITFIELD in_if_block : 1;
/* True if we want to lex an untranslated string. */
BOOL_BITFIELD lex_untranslated_string : 1;
/* Objective-C specific parser/lexer information. */
/* True if we are in a context where the Objective-C "PQ" keywords
are considered keywords. */
BOOL_BITFIELD objc_pq_context : 1;
/* True if we are parsing a (potential) Objective-C foreach
statement. This is set to true after we parsed 'for (' and while
we wait for 'in' or ';' to decide if it's a standard C for loop or an
Objective-C foreach loop. */
BOOL_BITFIELD objc_could_be_foreach_context : 1;
/* The following flag is needed to contextualize Objective-C lexical
analysis. In some cases (e.g., 'int NSObject;'), it is
undesirable to bind an identifier to an Objective-C class, even
if a class with that name exists. */
BOOL_BITFIELD objc_need_raw_identifier : 1;
/* Nonzero if we're processing a __transaction statement. The value
is 1 | TM_STMT_ATTR_*. */
unsigned int in_transaction : 4;
/* True if we are in a context where the Objective-C "Property attribute"
keywords are valid. */
BOOL_BITFIELD objc_property_attr_context : 1;
/* Cilk Plus specific parser/lexer information. */
/* Buffer to hold all the tokens from parsing the vector attribute for the
SIMD-enabled functions (formerly known as elemental functions). */
vec <c_token, va_gc> *cilk_simd_fn_tokens;
};
全局变量the_parser的具体操作在源码中进行了详细介绍,这里就不赘述
3、语法分析中声明说明符的解析
语法分析需要一个新的语法符号时其内部则会调用词法分析接口来获取一个新的token,其本质就是转换为tree节点,c_common_parse_file函数负责语法分析到AST树结点的生成:
/*
toplev::main
=> do_compile
=> compile_file
=> lang_hooks.parse_file
=> c_common_parse_file()
*/
## /gcc/c-family/c-opts.c
void
c_common_parse_file (void)
{
unsigned int i;
i = 0;
for (;;)
{
c_finish_options ();
/* Open the dump files to use for the original and class dump output
here, to be used during parsing for the current file. */
original_dump_file = dump_begin (TDI_original, &original_dump_flags);
class_dump_file = dump_begin (TDI_class, &class_dump_flags);
pch_init ();
push_file_scope (); // 创建file_scope,以记录编译单元中解析出的所有声明
c_parse_file (); // 解析整个编译单元
pop_file_scope (); // 销毁当前file_scop
/* And end the main input file, if the debug writer wants it */
if (debug_hooks->start_end_main_source_file)
(*debug_hooks->end_source_file) (0);
if (++i >= num_in_fnames)
break;
cpp_undef_all (parse_in);
cpp_clear_file_cache (parse_in);
this_input_filename
= cpp_read_main_file (parse_in, in_fnames[i]);
if (original_dump_file)
{
dump_end (TDI_original, original_dump_file);
original_dump_file = NULL;
}
if (class_dump_file)
{
dump_end (TDI_class, class_dump_file);
class_dump_file = NULL;
}
/* If an input file is missing, abandon further compilation.
cpplib has issued a diagnostic. */
if (!this_input_filename)
break;
}
c_parse_final_cleanups ();
}
3.1 c_parse_file ();
gcc中最大的编译单位是一个**编译单元( translation-unit ),**一个编译单元也就是一个文件, 而文件的构成元素则是一个个的外部声明(external-declaration),c语言的源代码实际上就是由一条条外部声明构成的。
toplev::main
=> do_compile
=> compile_file
=> lang_hooks.parse_file
=> c_common_parse_file()
=> c_parse_file ();
=> c_parser_translation_unit 






![[hddm]python模块hddm安装后测试代码](https://img-blog.csdnimg.cn/direct/94855141845b40529578290714fbeeb4.png)