GBDT(Gradient Boosting Decision Tree),全名叫梯度提升决策树,是一种迭代的决策树算法,又叫 MART(Multiple Additive Regression Tree),它通过构造一组弱的学习器(树),并把多颗决策树的结果累加起来作为最终的预测输出。该算法将决策树与集成思想进行了有效的结合。
原理
GBDT的核心思想是将多个弱学习器(通常是决策树)组合成一个强大的预测模型。具体而言,GBDT的定义如下:
- 初始化:首先GBDT使用一个常数(通常是目标变量的平均值,也可以是其他合适的初始值。初始预测值代表了模型对整体数据的初始估计。)作为初始预测值。这个初始预测值代表了我们对目标变量的初始猜测。
- 迭代训练:GBDT是一个迭代算法,通过多轮迭代来逐步改进模型。在每一轮迭代中,GBDT都会训练一棵新的决策树,目标是减少前一轮模型的残差(或误差)。残差是实际观测值与当前模型预测值之间的差异,新的树将学习如何纠正这些残差。
- 1)计算残差:在每轮迭代开始时,计算当前模型对训练数据的预测值与实际观测值之间的残差。这个残差代表了前一轮模型未能正确预测的部分。
- 2):训练新的决策树:使用计算得到的残差作为新的目标变量,训练一棵新的决策树。这棵树将尝试纠正前一轮模型的错误,以减少残差。
- 3):更新模型:将新训练的决策树与之前的模型进行组合。具体地,将新树的预测结果与之前模型的预测结果相加,得到更新后的模型。
- 集成:最终,GBDT将所有决策树的预测结果相加,得到最终的集成预测结果。这个过程使得模型能够捕捉数据中的复杂关系,从而提高了预测精度。
每次都以当前预测为基准,下一个弱分类器去拟合误差函数对预测值的残差(预测值与真实值之间的误差)。
GBDT的弱分类器使用的是树模型。
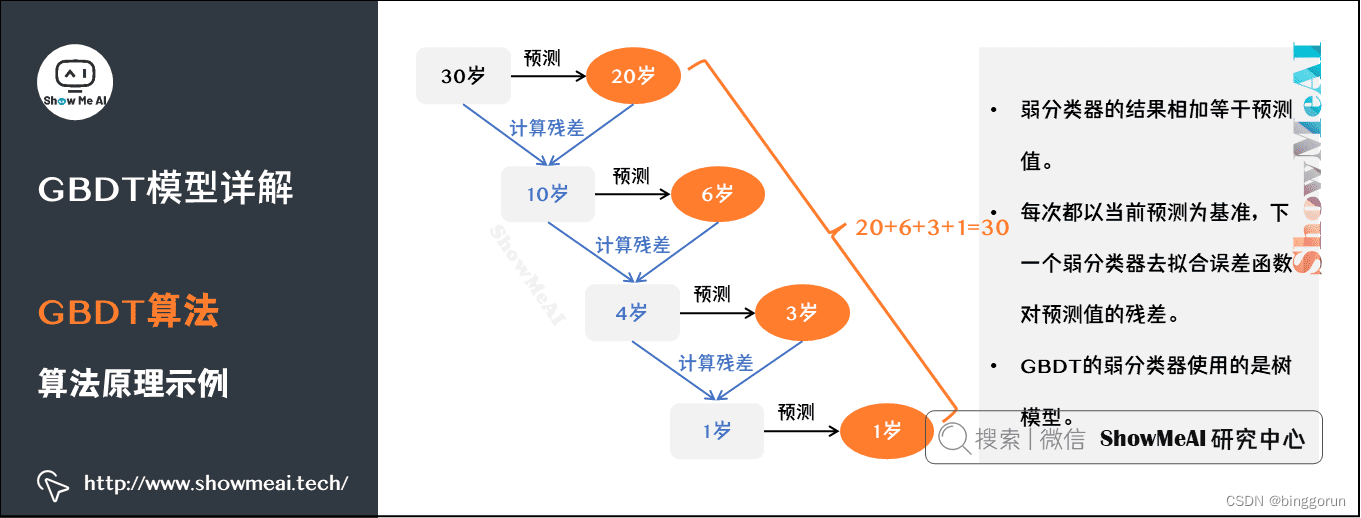
如图是一个非常简单的帮助理解的示例,我们用GBDT去预测年龄:
- 第一个弱分类器(第一棵树)预测一个年龄(如20岁),计算发现误差有10岁;
- 第二棵树预测拟合残差,预测值6,计算发现差距还有4岁;
- 第三棵树继续预测拟合残差,预测值3,发现差距只有1岁了;
- 第四课树用1岁拟合剩下的残差,完成。
最终,四棵树的结论加起来,得到30岁这个标注答案(实际工程实现里,GBDT是计算负梯度,用负梯度近似残差)。
GBDT的优势
1)高精度预测能力
GBDT以其强大的集成学习能力而闻名,能够处理复杂的非线性关系和高维数据。它通常能够在分类和回归任务中取得比单一决策树或线性模型更高的精度。
2)对各种类型数据的适应性
GBDT对不同类型的数据(数值型、类别型、文本等)具有很好的适应性,不需要对数据进行特别的预处理。这使得它在实际应用中更易于使用。
- 处理混合数据类型
在现实世界的数据挖掘任务中,常常会遇到混合数据类型的情况。例如,在房价预测问题中,特征既包括数值型(如房屋面积和卧室数量),还包括类别型(如房屋位置和建筑类型)和文本型(如房屋描述)数据。GBDT能够直接处理这些混合数据,无需将其转换成统一的格式。这简化了数据预处理的步骤,节省了建模时间。 - 不需要特征缩放
与某些机器学习算法(如支持向量机和神经网络)不同,GBDT不需要对特征进行缩放或归一化。这意味着特征的尺度差异不会影响模型的性能。在一些算法中,特征的尺度不一致可能导致模型无法正确学习,需要进行繁琐的特征缩放操作。而GBDT能够直接处理原始特征,减轻了数据预处理的负担。
3)在数据不平衡情况下的优势
- 加权损失函数
GBDT使用的损失函数允许对不同类别的样本赋予不同权重。这意味着模型可以更关注少数类别,从而提高对不平衡数据的处理能力。 - 逐步纠正错误
GBDT的迭代训练方式使其能够逐步纠正前一轮模型的错误。在处理不平衡数据时,模型通常会在多轮迭代中重点关注难以分类的少数类别样本。通过逐步纠正错误,模型逐渐提高了对少数类别的分类能力,从而改善了预测结果。
4)鲁棒性与泛化能力
GBDT在处理噪声数据和复杂问题时表现出色。其鲁棒性使得它能够有效应对数据中的异常值或噪声,不容易受到局部干扰而产生较大的预测误差。
5)特征重要性评估
GBDT可以提供有关特征重要性的信息,帮助用户理解模型的决策过程。通过分析每个特征对模型预测的贡献程度,用户可以识别出哪些特征对于问题的解决最为关键。这对于特征选择、模型解释和问题理解非常有帮助。
6)高效处理大规模数据
尽管GBDT通常是串行训练的,每棵树依赖于前一棵树的结果,但它可以高效处理大规模数据。这得益于GBDT的并行化实现和轻量级的决策树结构。此外,GBDT在处理大规模数据时可以通过特征抽样和数据抽样来加速训练过程,而不会牺牲太多预测性能。
关键参数与调优
参数解释
n_estimators:迭代次数,即最终模型中弱学习器的数量。
learning_rate(学习率):每次迭代时,新决策树对预测结果的贡献权重。
max_depth:决策树的最大深度,控制着树的复杂度。
min_samples_split:节点分裂所需的最小样本数。
subsample:用于训练每棵树的样本采样比例,小于1时可实现随机梯度提升。
loss:即我们GBDT算法中的损失函数。分类模型和回归模型的损失函数是不一样的。1)对于分类模型,有对数似然损失函数"deviance"和指数损失函数"exponential"两者输入选择。默认是对数似然损失函数"deviance"。2)对于回归模型,有均方差"ls", 绝对损失"lad", Huber损失"huber"和分位数损失“quantile”。默认是均方差"ls"。一般来说,如果数据的噪音点不多,用默认的均方差"ls"比较好。如果是噪音点较多,则推荐用抗噪音的损失函数"huber"。而如果我们需要对训练集进行分段预测的时候,则采用“quantile”。
subsample:用于训练每个弱学习器的样本比例。减小该参数可以降低方差,但也可能增加偏差。
调优策略
学习率与迭代次数的平衡:较低的学习率通常需要更多的迭代次数来达到较好的性能,但能减少过拟合的风险。
树的深度与样本采样:合理限制树的深度和采用子采样可以提高模型的泛化能力。
早停机制:在验证集上监控性能,一旦性能不再显著提升,则提前终止训练。
为了解决GBDT的效率问题,LightGBM和XGBoost等先进框架被提出,它们通过优化算法结构(如直方图近似)、并行计算等方式显著提高了训练速度。
python实现
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import GradientBoostingRegressor
GradientBoostingClassifier(*, loss='deviance', learning_rate=0.1, n_estimators=100, subsample=1.0,
criterion='friedman_mse', min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_depth=3, min_impurity_decrease=0.0, min_impurity_split=None, init=None, random_state=None,
max_features=None, verbose=0, max_leaf_nodes=None, warm_start=False, presort='deprecated',
validation_fraction=0.1, n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
GradientBoostingRegressor(*, loss='ls', learning_rate=0.1, n_estimators=100, subsample=1.0, criterion='friedman_mse', min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, min_impurity_decrease=0.0, min_impurity_split=None, init=None, random_state=None, max_features=None, alpha=0.9, verbose=0, max_leaf_nodes=None, warm_start=False, presort='deprecated', validation_fraction=0.1, n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
回归实现
# 导入必要的库
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
# 加载波士顿房价数据集
boston = load_boston()
X, y = boston.data, boston.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化GBDT回归器
gbdt_reg = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
# 训练模型
gbdt_reg.fit(X_train, y_train)
# 预测
y_pred = gbdt_reg.predict(X_test)
# 计算并打印均方误差
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.2f}")
GBDT正则化
针对GBDT正则化,我们通过子采样比例方法和定义步长v方法来防止过拟合。
- 子采样比例:通过不放回抽样的子采样比例(subsample),取值为(0,1]。如果取值为1,则全部样本都使用。如果取值小于1,利用部分样本去做GBDT的决策树拟合。选择小于1的比例可以减少方差,防止过拟合,但是会增加样本拟合的偏差。因此取值不能太低,推荐在[0.5, 0.8]之间。
- 定义步长v:针对弱学习器的迭代,我们定义步长v,取值为(0,1]。对于同样的训练集学习效果,较小的v意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。