科技的每一次飞跃都在重新塑造世界,而近年来,跨越式的技术革新再次引发了深刻的变革,那就是人工智能(AI)。
人工智能已然超越了此前的所有技术概念,成为了继互联网之后的下一个巨大浪潮。从自动驾驶汽车到个性化推荐,从机器学习到生成式大语言模型,AI已经逐渐渗透到我们的生活的方方面面,也引发了社会的极度关注和投资热潮。
行业和企业都在积极寻找使用AI赋能提升效率的可能,他们都明白AI的价值并期待利用AI来提升自己的生产力和竞争力。然而,AI的应用并非易事,企业必须初期投入大量的资源,包括时间,人力和资金来建设和维护。
不同于传统的研发投资与产品价值之间的次线性关系,AI的发展显示出一种独特的特性:增加计算资源直接导致产品性能的提升,如大模型的训练,游戏领域的AI辅助开发和云游戏都需要海量的算力资源,最大的挑战就是获取算力成本的高昂。
在AI模型的计算过程中,GPU(图形处理单元)扮演了核心角色。目前,高效的GPU供应几乎被Nvidia等巨头垄断,使得中小型企业很难获取到需要的算力资源。虽然很多企业急于尝试AI赋能,但事实上,供应和需求之间的差距正在日益加大。
据CAPEX分析预测,2024年仅北美四大云厂商(Amazon、Microsoft、Google、Meta)的GPU采购需求已经在300万片量级。由于供不应求导致GPU价格难以下降且交付周期不断延长,许多公司在算力资源上的开支超过了其在AI领域投入资本总量的80%,算力的短缺已经成为制约行业发展的关键因素。
特斯拉创始人马斯克曾公开表示,随着人工智能技术的快速发展,特别是在深度学习、自然语言处理等领域,对算力的需求呈现出爆炸性增长。然而,当前全球范围内的AI算力供应却难以满足这一需求,这将对AI技术的发展和应用产生深远影响。AI算力短缺的问题不仅存在于商业领域,还涉及到安全、医疗健康等重要领域。因此,解决AI算力短缺问题,不仅是科技企业和研究机构的责任,更是全社会共同面临的挑战。
正是基于以上的问题,算力租赁(云算力)便成为了解决问题的关键。较少的前期成本、能够上下扩展的能力、区域可用性以及避免自建数据中心的分心,对于大多数初创公司甚至部分大型公司来说都很有吸引力。不同的组织和公司能够按需租用算力,而不必承受购买硬件的投入和维护的沉重负担。
目前市场上关于云计算的服务商也五花八门,如亚马逊网络服务(AWS)、微软Azure和谷歌云平台(GCP)都提供GPU实例,但这些国际巨头往往因为处于市场垄断地位而定价高企。虽然也有一些专门针对AI工作负载的新服务商,但是竞争力往往不强。
尤其是目前美国等在AI领域处于领先地位的国家为了保护自己的优势,限制顶级芯片出口和算力的供应,导致部分国家和地区的客户既无法购买到足够的GPU,也无法在服务商处获得服务。
Aethir:构建AI时代去中心化云基础设施
Aethir作为新一代的云算力解决方案提供商,采用AI云算力+GPU DePIN的解决方案,来解决现有AI领域算力紧缺的问题。Aethir通过建立一套全新的、分布式的、基于人工智能的云算力网络,为全球范围内的企业和个人提供按需求匹配的高效、可扩展、灵活的算力租用服务。

Aethir可以优化计算密集型领域如AI、ML和云游戏的GPU利用率:一是通过资源池,让所有者将未充分利用的GPU贡献到网络中,形成强大的计算资源集体池,实现GPU全球分发,降低成本,民主化高级计算能力;二是通过去中心化所有权,超越传统所有权结构的限制,实现分布式资源占有,培育公平开放的技术格局,消除新消费者和创业者使用AI的壁垒,为全球互联的数字生态系统做出贡献。
简单来说,在目前全球算力短缺、GPU供不应求的情况下,如何利用好闲置的GPU资源是关键。Aethir通过DePin的运作模式,激励用户或节点贡献出自己闲置的GPU算力并实现规模化,为需要的企业提供算力支持,满足对算力的需求。
技术架构&代币经济
我们都知道,人工智能大模型训练需要使用“整块的高性能算力”,目前的解决策略主要是利用多张GPU配合高性能卡间相互连接构成所需要的算力。然而对比之下,民间的算力往往是零散的,而且网络条件也普遍较为糟糕,这使得怎样让零散的算力高效地服务于AI训练成为了一个难题。
在这个环境下,Aethir要满足需求,就需要解决这两个问题:如何保证算力的质量,以及如何解决网络问题。借助于Aethir的自有H100算力集群,以及优秀的架构和代币经济模型,两个问题得到了有效解决。
NVIDIA的H100 GPU是Aethir去中心化云基础设施的核心元素。超过4000张H100 可供AI企业客户按需使用,预计在未来半年内,该平台将再增设数千张NVIDIA H100还会增加部署大量NVIDIA H100。

每一块加入到Aethir网络中的H100,都经过了严密的检测和筛查,包括性能参数配置、模型的可使用性、带宽的吞吐量、稳定性等等,以确保其在高速训练和推理任务中的性能表现。
而且Aethir的优势不仅仅在于可用H100的数量。传统的云计算服务将GPU资源集中在集中式服务器中心,因此无法有效地将GPU功率传输到远离数据中心的客户端。另一方面,得益于Aethir分布式网络基础设施,可以有效地覆盖全球大多数地区网络边缘的客户。每个客户端都由最接近的可用H100芯片提供服务,从而消除了延迟问题。
除了分布式部署H100保证算力的稳定,Aethir的架构和经济模型保证了零散算力的质量和网络的稳定。
Aethir的架构设计包括了五个基本角色:矿工、开发者、用户、代币持有者和Aethir DAO。最核心的三个部分则是Container容器、Indexer索引器和Checker检查器:
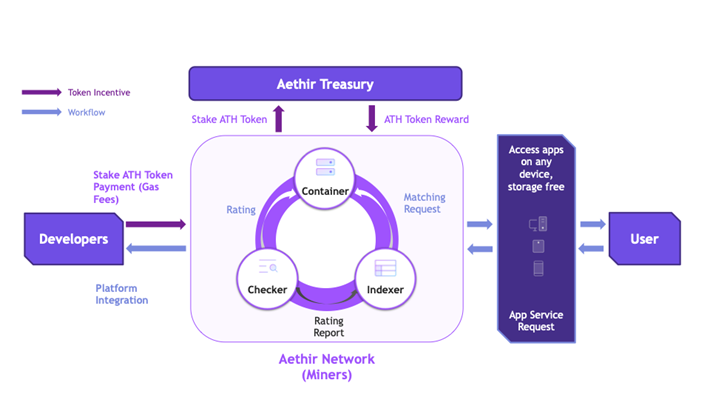
Container是Aethir的核心计算单元,负责执行和渲染应用程序,每一个任务被封装在一个独立的Container中,每一个Container作为一个相对隔离的环境来运行用户的任务,避免了任务间互相干扰的情况。如有用到大数据处理或机器学习等计算资源密集型应用,它们可以在Container里顺利执行并最终得出结果。即实现了所要求的高性能算力。
Indexer主要被用于实时匹配并调度用户的任务需求和可用资源。实时匹配和调度是为了保证用户的需求可以在最短的时间内被满足,而存在的容错与冗余设计是为了应对可能的服务故障,可以选择其他备用节点进行任务调度,以防止任务进展被中断。同时,动态资源调整能够根据系统的负载情况,动态将资源分配给不同的任务,以达到优化整体性能的目标。
Checker则负责实时监控和评估Container的性能,它可以实时地监控和评估整个系统的状态,并对可能出现的问题作出及时的反应。如需应对网络攻击等安全事件,在检测到异常行为后,能够及时发出警告并启动防护措施。同样的,在系统性能出现瓶颈或其他问题时,Checker也可以及时发出提醒,以便问题能够被及时解决,保证了服务质量和网络安全。
同时,Aethir建立了严格的节点奖惩机制,对符合质量的高标准节点进行奖励,不符合服务质量标准的节点进行经济处罚,保证了整个网络的稳定性和可用性。该机制有效保护了客户权益,提高了节点的服务意识。
Aethir的代币经济以ATH代币为核心,用于云计算服务的交易、平台治理、激励和开发。代币总量为420亿,通过购买GPU计算能力和质押机制,ATH代币促进了生态系统的去中心化管理和增长,同时为新节点运营商和用户提供了一种承诺和经济保障。
代币经济模型的关键之处还在于其共识机制(Proof of Rendering),由两个主要组成部分构成:Proof of Rendering Capacity(渲染能力证明)和Proof of Rendering Work(渲染工作证明)。
-
Proof of Rendering Capacity:此策略为每一个Container进行定向评估,其代币投资(节点质押的ATH代币数量)、算力水平和在线时长被合计考虑,以估算该Container的有效算力。这种机制使得所有节点能够公正地参与到网络中,并鼓励节点运营商去质押更多的ATH代币。
-
Proof of Rendering Work:当容器在提供算力服务时,Checker会进行工作情况的监督,并将服务具体情况(例如,延迟、分辨率、帧率等)提交至链上。根据工作质量和工作时长来分配Proof of Rendering Work奖励。
Aethir的服务费(Service Fee)以ATH代币支付,价格锚定法币,以此来确保服务费的稳定性。若因Container出现故障导致服务中断,用户将会获得相应的退款,同时发生故障的Container将会被罚款。
为了满足不同规模和需求的客户需求,Aethir还设计了零售(Retail)和批发(Wholesale)两种运营模式。批发模式牺牲了一定的灵活性,以提供较低的服务费用、偏向于长期的服务保证和交易结算方便性。零售模式更加灵活,可以随时根据需求提供服务,无需预定或承诺。
Aethir引入了法币定价机制,允许客户以法币支付算力服务,大大降低了其进入门槛和财务风险,增强了客户粘性和合规性。
总的来看,Aethir通过优秀的架构和代币经济模型,从技术架构和制度上具备充分调动高质量零散算力的可能,解决了在当前商业环境下AI需求场景最大的大模型训练需要的高性能算力问题,这使得Aethir在大模型训练场景下,有着极高的商业可用性。
在游戏领域的应用
在过去的几年里,我们已经见证了AI在游戏领域中的广泛应用,如新手引导和NPC文本生成等。随着科技的发展,未来AI在游戏产业中的应用将更加深入,需要大量的算力进行训练和学习。 除了AI算力的共享,云游戏领域则是Aethir另一大擅长的领域。

在GPU和存储技术疯狂进化的20年中,随着家用PC设备算力的提升,开发商对游戏的画面和游戏空间的追求也在不断扩大。例如GTA把算力用到了城市生成,极品飞车把算力用到了赛车碰撞和画质的提升,因此也诞生了精美的游戏画面和超大真实的城市,最终结果是动辄几百G的容量和对显卡性能的要求,大量玩家的电脑难以负载。
云游戏是指以云计算为基础的游戏方式,在云游戏的运行模式下,所有游戏都在服务器端运行,并将渲染完毕后的游戏画面压缩后通过网络传送给用户。在客户端,用户的游戏设备不需要任何高端处理器和显卡,只需要基本的视频解压能力即可。
Aethir通过其分布式网络,为云游戏领域带来了显著价值,包括提供低成本的高端GPU计算能力,优化游戏体验实现设备的即时访问和低延迟,服务游戏开发商提供新的发布方式和游戏移植服务,扩大玩家基础规模,提高游戏升级效率,提升游戏安全性。
生态发展
Aethir与IO.net达成了战略合作伙伴关系,二者联合进行技术研发和对接,打通了Aethir的H100与IO网络之间的连接。这样,Aethir的H100就能自动接入IO网络,为IO网络的客户提供稳定的企业级服务。通过联合的技术研发和对接,Aethir的H100可以自动加入IO网络,为IO的客户提供稳定的企业级服务。Aethir的H100提供者,在获得Aethir奖励的同时,将可以同时获得IO网络的Token奖励。
同时,Aethir正在推动集群与边缘计算的融合。简单的说,通过Aethir的边缘计算,客户可以匹配到就近的节点,保证了算力和网络的畅通。
Aethir Edge是专为Aethir边缘计算服务的硬件设备。它将打破远离用户的单一集中化的GPU集群部署方式,将算力部署到边缘。这样远离集中服务器集群的客户也能够享受稳定无缝的GPU云计算服务。
APhone是Aethir推出的一款Web 3.0云电话。它采用了Aethir的分布式云架构,实现了安全、设备无关同时跨越通信服务供应商地理边界的Web3通信体验。作为Aethir网络的一部分,APhone不仅支持无缝的dApp访问,还集成了Web 3.0的应用商店。截至目前,Aphone用户量超过3.6万。
总结
在当前AI成为重要的技术革新的背景下,AI算力的短缺问题已经成为阻碍行业发展的主要束缚。作为新兴的云计算解决方案提供商的Aethir意在通过建立分布式算力网络来解决这一问题,为全球企业和个人提供高效且可扩展的算力。
Aethir的架构设计和代币经济模型,以及在游戏领域和边缘计算方面的应用,都表明了其在技术架构和商业布局方面具备潜力。Aethir通过激励机制保证网络的稳定性和可用性,为AI和游戏等领域提供了商用水平的解决方案。
总体来看,Aethir不论是在项目基本面、技术架构,还是产品与生态上都表现得可圈可点。其代币ATH也即将TGE,值得我们关注。