目录
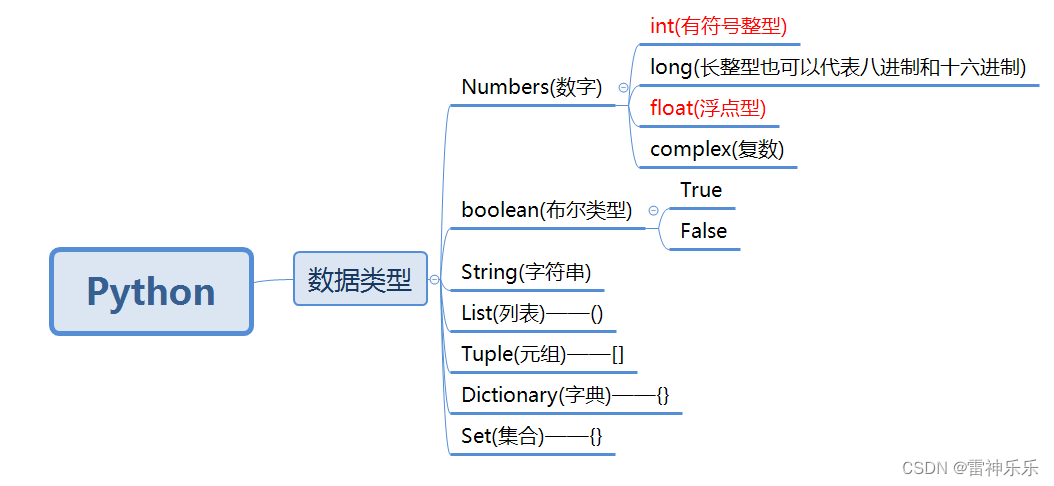
一、数据类型
判断数据类型type()
二、数据类型的转换
三、运算符
(一)算数运算符
(二)赋值运算符
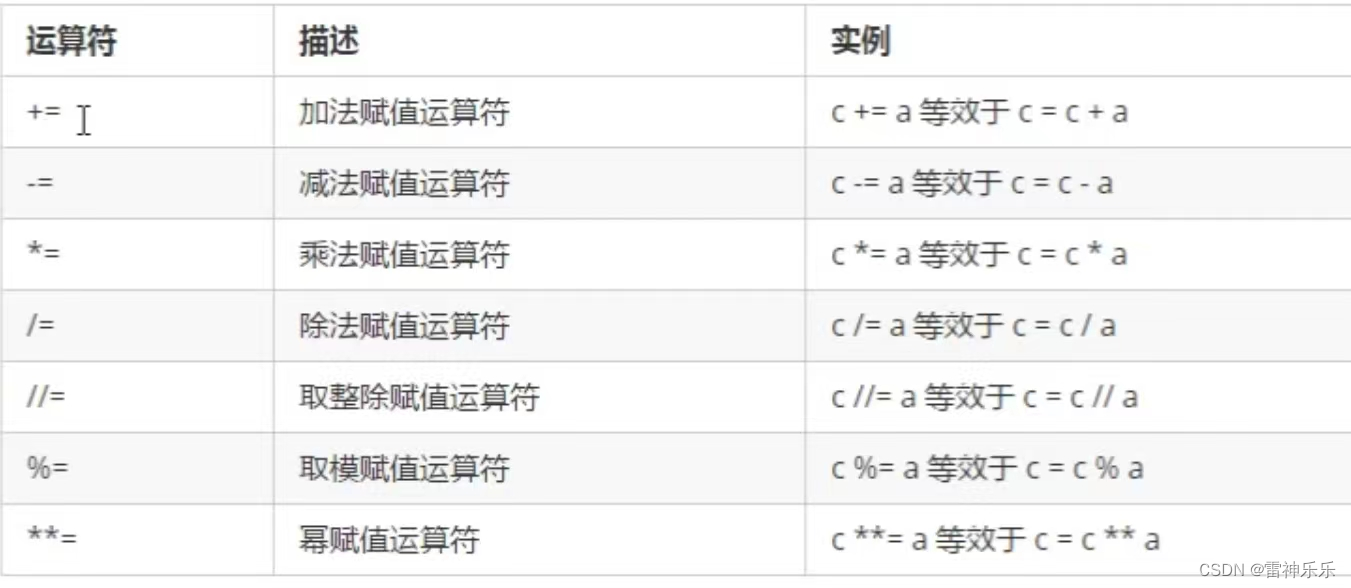
(三)复合赋值运算符
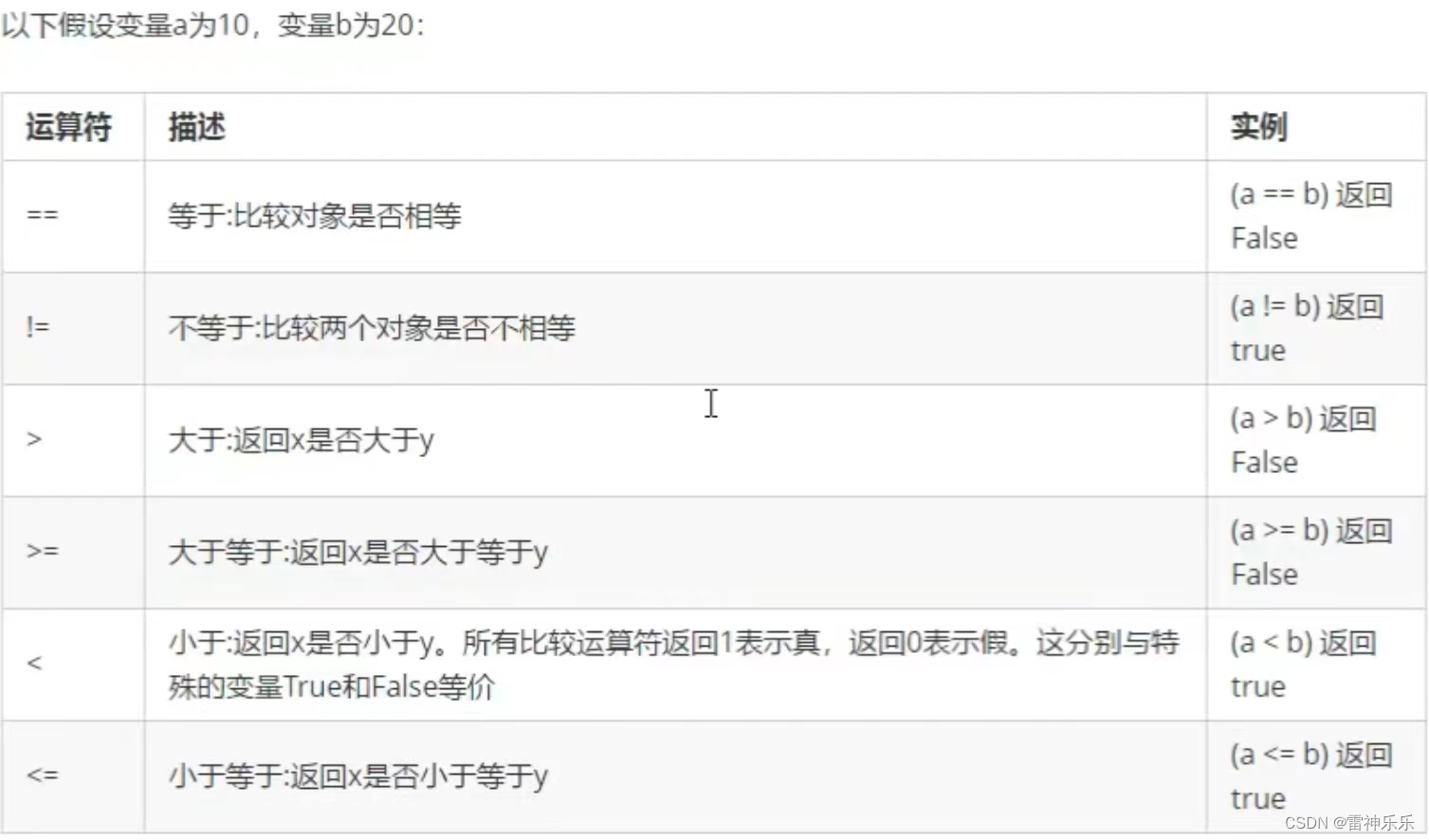
(四)比较运算符
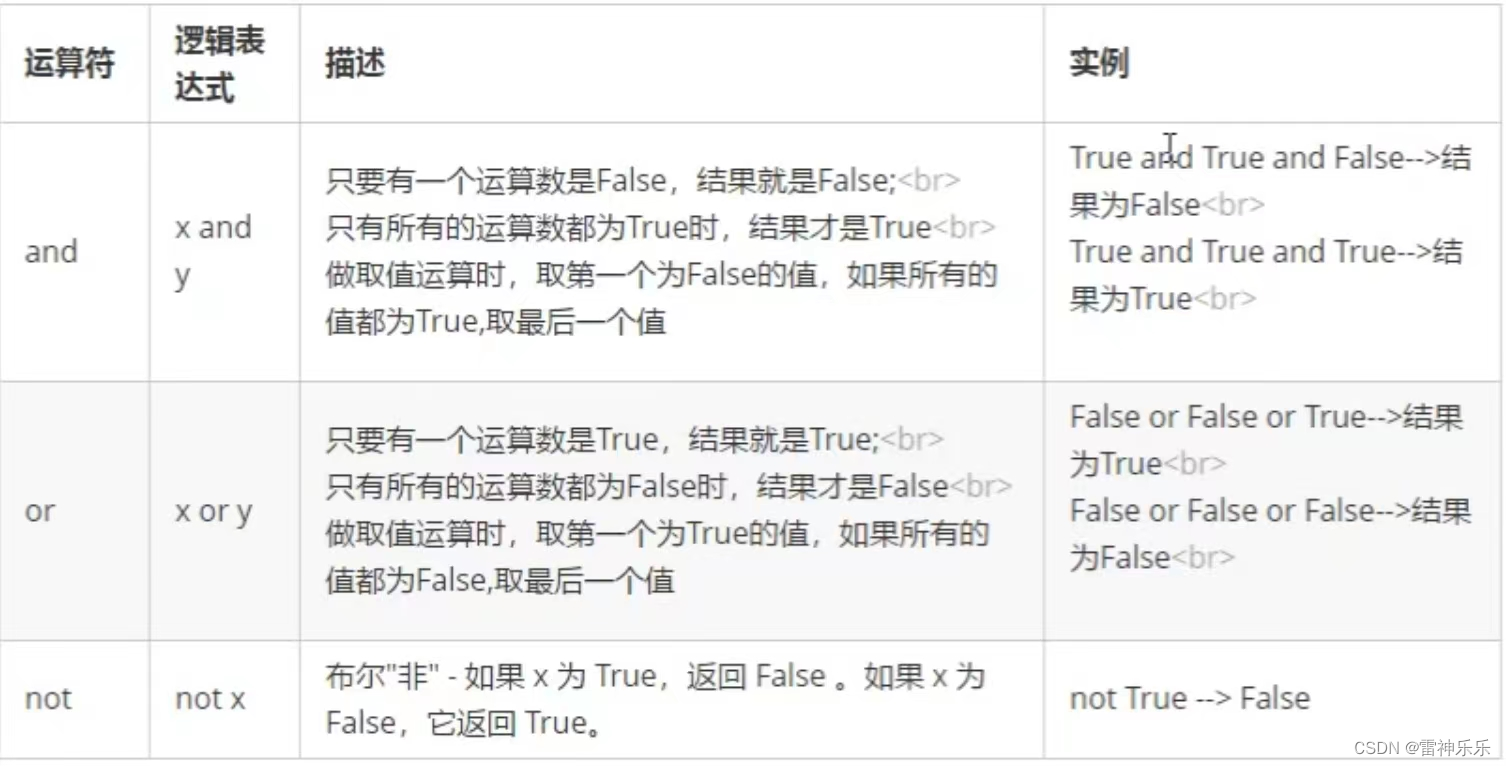
(五)逻辑运算符
四、输入输出
(一)输出
(二)输入
五、各数据类型常用函数
(一)数值函数
1.绝对值abs(x)
2.最大值max(x1,x2...)
3.最小值min(x1,x2...)
4.向上取整math.ceil(x)
5.向下取整math.floor(x)
6.返回e的x次幂math.exp(x)
7.返回x的整数部分与小数部分modf(x)
8.x**y的值math.pow(x)
9.四舍五入round(x)
10.求平方根math.sqrt(x)
11. 随机数random()
12.从指定范围内随机挑选random.choice()
13. 按指定基数递增的集合中获取一个随机数randrange ([start,] stop [,step])
14. 将序列的所有元素随机排序shuffle()
15.三角函数
(二)字符串函数
1.字符串取值取下标
2.字符串长度
3.全部转为小写
4.全部转为大写
5.整个字符串首字母大写(字符串"标题化")
6.单词首字母大写
7.字符串大小写互转
8.字符串填充
9.判断子字符串在字符串中出现的次数
10.判断字符串开头/结尾
11.判断子字符串是否包含在字符串中find(str,beg=0,end=len(string))
12. 寻找字符串下标
13.字符串指定拼接join
14.字符串去除空格
15.字符串中最大/最小的字母
16.替换字符串中的内容
17.字符串分割
18.返回长度为 width 的字符串,原字符串右对齐,前面填充0
(三)列表函数
1.列表取值取下标
2.列表拼接
3.删除列表元素
4.判断列表内容是否一致
5.返回列表个数
6.返回列表的最大/最小值
7.统计某个元素在列表中出现的次数
8.判断列表元素的索引位置
9.列表元素反转
10.列表元素排序
11.清空列表list.clear
12.复制列表list.copy
(四)元组函数
1.元组的形式
2.创建空元组
3.访问元组中的元素与字符串相同,取下标
4.判断元组的长度
5.判断元组内元素的最大/最小值
6.元组中的元素不能修改
(五)字典函数
1.访问字典的数据——通过键访问
2.修改字典
3.删除字典
4.字典键的特性
5.输出字典的长度
6.复制字典dict.copy()
7.创建新字典
8.判断键是否存在
(六)集合函数
1.集合可以自动去重
2.集合之间的运算
3.添加元素add()与update()
4.删除集合中的元素
5.复制集合copy()
6.返回多个集合的并集union()
7.判断是否包含元素
一、数据类型
判断数据类型type()
a = 1.23
print(type(a)) # float二、数据类型的转换
# 浮点型转换为整型
print(int(12.36)) # 12
# 整型转换为浮点型
print(float(17)) # 17.0
# 浮点型转换为字符串
print(str(-9.63)) # -9.63
# 转换为布尔类型
# False的情况:
print(bool(0))
print(bool(0.0))
print(bool(""))
print(bool(''))
print(bool(()))
print(bool([]))
print(bool({})
print(bool(" "))
# 其他转为布尔类型的结果都是True三、运算符
(一)算数运算符

(二)赋值运算符
a = 10
a = b = 10(三)复合赋值运算符
(四)比较运算符
(五)逻辑运算符
四、输入输出
——相当于java的Scanner scanner = new Scanner(System.in);
(一)输出
name = 'zs'
age = 12
# %s代表的是字符串 %d代表的是数值
print('我的姓名为%s,年龄为%d' % (name, age))
# 我的姓名为zs,年龄为12(二)输入
password = input('请输入姓名:')
print('您的姓名为:%s' % password)
# 请输入姓名:张三
# 您的姓名为:张三五、各数据类型常用函数
(一)数值函数
1.绝对值abs(x)
print(abs(-9.6)) # 9.62.最大值max(x1,x2...)
print(max(32, -9, 89)) # 89
3.最小值min(x1,x2...)
print(min(32, -9, 89)) # -9
4.向上取整math.ceil(x)
print(math.ceil(-5.8), math.ceil(5.3)) # -5 6
5.向下取整math.floor(x)
print(math.floor(-5.8), math.floor(5.8)) # -6 5
6.返回e的x次幂math.exp(x)
print(math.exp(1)) # 2.718281828459045
7.返回x的整数部分与小数部分modf(x)
print(math.modf(9.6)) # (0.5999999999999996, 9.0)8.x**y的值math.pow(x)
print(math.pow(2, 3)) # 8.0
9.四舍五入round(x)
print(round(-9.8), round(9.8)) # -10 10
10.求平方根math.sqrt(x)
print(math.sqrt(121)) # 11.011. 随机数random()
print(random()) # 0.7661687961118427
print(math.ceil(random() * 10)) # 312.从指定范围内随机挑选random.choice()
print(random.choice(range(100))) # 96
print(random.choice([8, 5.6, -4, 55])) # 5.6
print(random.choice('hello world')) # e
13. 按指定基数递增的集合中获取一个随机数randrange ([start,] stop [,step])
# 从1~99内获取奇数
print(random.randrange(1, 99, 2)) # 93
# 从0~100之间获取随机数
print(random.randrange(100)) # 1314. 将序列的所有元素随机排序shuffle()
list1 = [20, 8, 6, 77]
random.shuffle(list1)
print(list1) # [77, 8, 20, 6]15.三角函数
print(math.cos(0), math.cos(math.pi)) # 1.0 -1.0
print(math.sin(0)) # 0.0
print(math.tan(0)) # 0.0(二)字符串函数
1.字符串取值取下标
string = 'hello'
print(string[1],string[2:4]) # e ll2.字符串长度
print(len('java hadoop')) # 11
3.全部转为小写
print(str.lower('JAVA HADOOP')) # java hadoop
4.全部转为大写
print(str.upper('java hadoop')) # JAVA HADOOP
5.整个字符串首字母大写(字符串"标题化")
print(str.capitalize('JAVA HADOOP')) # Java hadoop
6.单词首字母大写
print(str.title('java hadoop')) # Java Hadoop7.字符串大小写互转
print(str.swapcase('javA hadOOP')) # JAVa HADoop8.字符串填充
print(str.center('Java hadoop', 20, '*')) # ****Java hadoop*****
print(str.ljust('Java hadoop', 20, '*')) # Java hadoop*********
print(str.rjust('Java hadoop', 20, '*')) # *********Java hadoop
9.判断子字符串在字符串中出现的次数
语法:str.count(sub, start= 0,end=len(string))
参数
- sub -- 搜索的子字符串
- start -- 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
- end -- 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
string = '****Java hadoop*****'
print(string.count('*')) # 9
print(string.count('*', 3, 10)) # 110.判断字符串开头/结尾
string = '****Java hadoop*****'
print(string.startswith('/')) # False
print(string.endswith('*')) # True
print(string.endswith('*', 1, 4)) # True
print(string.endswith('*', 3, 6)) # False11.判断子字符串是否包含在字符串中find(str,beg=0,end=len(string))
检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1
string = '****Java hadoop*****'
print(string.find('*',3,10)) # 3
print(string.rfind('*')) # 1912. 寻找字符串下标
与find方法一样,但是如果str不在字符串中会报异常
print(string.index('a')) # 5
print(string.rindex('a')) # 1013.字符串指定拼接join
str1 = '-'
str2 = 'world'
print(str1.join(str2)) # w-o-r-l-d14.字符串去除空格
print(str.strip(' java ')) # java
print(str.lstrip(' java ')) # java
print(str.rstrip(' java ')) # java15.字符串中最大/最小的字母
print(max('zhello'),min('zhello')) # z e16.替换字符串中的内容
print(str.replace('hello', 'l', '*')) # he**o17.字符串分割
string2 = 'Java hadoop spark flink mysql'
# 以空格为分隔符
print(string2.split(' ')) # ['Java', 'hadoop', 'spark', 'flink', 'mysql']
# 以a为分隔符,分割2次
print(string2.split('a',2)) # ['J', 'v', ' hadoop spark flink mysql']
# 以a为分隔符
print(string2.split('a')) # ['J', 'v', ' h', 'doop sp', 'rk flink mysql']18.返回长度为 width 的字符串,原字符串右对齐,前面填充0
string = '****Java hadoop*****'
print(string.zfill(25)) # 00000****Java hadoop*****(三)列表函数
1.列表取值取下标
list = ['java','hadoop','spark','flink']
print(list[1:3],list[-3:-2], list[2:])
# ['hadoop', 'spark'] ['hadoop'] ['spark', 'flink']2.列表拼接
list = ['java','hadoop','spark','flink']
list.append('flume')
print(list) # ['java', 'hadoop', 'spark', 'flink', 'flume']
list1 = ['hello','world']
list += list1
print(list) # ['java', 'hadoop', 'flink', 'flume', 'hello', 'world']
list2 = [list,list1] # 类似二维数组
print(list2)
# [['java', 'hadoop', 'flink', 'flume', 'hello', 'world'], ['hello', 'world']]
print(list2[0],list2[1][1])
# ['java', 'hadoop', 'flink', 'flume', 'hello', 'world'] world
list1.extend('oracle')
print(list1) # ['hello', 'world', 'o', 'r', 'a', 'c', 'l', 'e']
list1.insert(3,'2233')
print(list1) # ['hello', 'world', 'o', '2233', 'r', 'a', 'c', 'l', 'e']3.删除列表元素
list = ['java','hadoop','spark','flink']
del list[2]
print(list) # ['java', 'hadoop', 'flink', 'flume']
# 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
list1 = ['java', 'hadoop', 'flink', 'flume', 'hello', 'world']
list1.pop()
print(list1) # ['java', 'hadoop', 'flink', 'flume', 'hello']
list1 = ['java', 'hadoop', 'flink', 'flume', 'hello', 'world']
list1.pop(2)
print(list1) # ['java', 'hadoop', 'flume', 'hello', 'world']
# 移除列表中某个值的第一个匹配项
list1 = ['java', 'hadoop', 'flink', 'flume', 'hello', 'world']
list1.remove('flume')
print(list1) # ['java', 'hadoop', 'flink', 'hello', 'world']| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print(x, end=" ") | 1 2 3 | 迭代 |
4.判断列表内容是否一致
import operator
list1 = ['a', 'b']
list2 = ['a', 'b']
list3 = ['a']
print(operator.eq(list1, list2), operator.eq(list1, list3)) # True False5.返回列表个数
list1 = ['java', 'hadoop', 'flink', 'flume', 'hello', 'world']
print(len(list1)) # 6
6.返回列表的最大/最小值
list1 = [-9, 6, 78, 5.2]
print(max(list1), min(list1)) # 78 -97.统计某个元素在列表中出现的次数
list1 = ['java', 'hadoop', 'flink', 'flume', 'hello', 'java']
print(list1.count('java')) # 28.判断列表元素的索引位置
list1 = ['java', 'hadoop', 'flink', 'flume', 'hello', 'java']
print(list1.index('hadoop')) # 19.列表元素反转
list1 = ['java', 'hadoop', 'flink', 'flume', 'hello', 'world']
list1.reverse()
print(list1) # ['world', 'hello', 'flume', 'flink', 'hadoop', 'java']10.列表元素排序
list1 = [-9.4,-55,78,999]
list1.sort()
print(list1) # [-55, -9.4, 78, 999]11.清空列表list.clear
12.复制列表list.copy
(四)元组函数
1.元组的形式
>>> tup1 = ('Google', 'Runoob', 1997, 2000)
>>> tup2 = (1, 2, 3, 4, 5 )
>>> tup3 = "a", "b", "c", "d" # 不需要括号也可以
>>> type(tup3)
<class 'tuple'>
2.创建空元组
tup1=()
元组中只包含一个元素时,需要在元素后面添加逗号 , ,否则括号会被当作运算符使用:
>>> tup1 = (50)
>>> type(tup1) # 不加逗号,类型为整型
<class 'int'>
>>> tup1 = (50,)
>>> type(tup1) # 加上逗号,类型为元组
<class 'tuple'>
3.访问元组中的元素与字符串相同,取下标
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| tup[1] | 'Runoob' | 读取第二个元素 |
| tup[-2] | 'Weibo' | 反向读取,读取倒数第二个元素 |
| tup[1:] | ('Runoob', 'Taobao', 'Wiki', 'Weibo', 'Weixin') | 截取元素,从第二个开始后的所有元素。 |
| tup[1:4] | ('Runoob', 'Taobao', 'Wiki') | 截取元素,从第二个开始到第四个元素(索引为 3)。 |
4.判断元组的长度
tup1 = ('java','hadoop', 'spark', 'flume')
print(len(tup1)) # 4
5.判断元组内元素的最大/最小值
tup1 = ('java','hadoop', 'spark', 'flume')
print(max(tup1),min(tup1)) # spark flume
6.元组中的元素不能修改
(五)字典函数
d = {key1 : value1, key2 : value2, key3 : value3 }由键值对组合而成
键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
1.访问字典的数据——通过键访问
# 返回指定键的值
dict1 = {'name':'zs', 'age':19}
print(dict1['name']) # zs
# 如果dict1后面的键没有,会触发异常
# dict.get(key[, value])
# key -- 字典中要查找的键。
# value -- 可选,如果指定键的值不存在时,返回该默认值。
dict2 = {'name': 'zhangsan', 'age': 10, 'gender': '男'}
print(dict2.get('age')) # 10
print(dict2.get('java')) # None
print(dict2.get('hadoop', '没有这个值!')) # 没有这个值!
# dict.setdefault(key, default=None)函数:当键值不存在,或默认添加到字典中
print(dict2.setdefault('java','键不存在')) # 键不存在
print(dict2)
# {'name': 10, 'age': 10, 'gender': 10, 'java': '键不存在'}
# 嵌套字典
dict3 = {'name': {'name1': 'zs', 'name2': 'ls'}, 'age': {'age1': 18, 'age2': 19}}
print(dict3['name']) # {'name1': 'zs', 'name2': 'ls'}
print(dict3.get('name', {}).get('name2')) # ls
print(dict3.get('age', {}).get('age1')) # 18
2.修改字典
dict1 = {'name':'zs', 'age':19}
dict1['name']='ls'
print(dict1) # {'name': 'ls', 'age': 19}
dict2 = {'name': 10, 'age': 10, 'gender': 10}
dict2.update({'class': 'flink'})
print(dict2)
# {'name': 10, 'age': 10, 'gender': 10, 'class': 'flink'}3.删除字典
dict1 = {'name':'zs', 'age':19}
del dict1['name'] # 删除键 'name'
print(dict1) # {'age': 19}
dict1 = {'name':'zs', 'age':19}
dict1.clear() # 清空字典
print(dict1) # {}
dict1 = {'name':'zs', 'age':19}
del dict1 # 删除字典
print(dict1)
# pop(key[,default])
# key - 要删除的键
# default - 当键 key 不存在时返回的值
dict2 = {'name': 'zhangsan', 'age': 10, 'gender': 10}
element = dict2.pop('name')
print('删除的元素为:',element) # 删除的元素为: zhangsan
print('删除后的字典为:',dict2) # 删除后的字典为: {'age': 10, 'gender': 10}
dict2 = {'name': 'zhangsan', 'age': 10, 'gender': 10}
element = dict2.pop('java','不存在的key')
print('删除的元素为:',element) # 删除的元素为: 不存在的key
print('删除后的字典为:',dict2) # 删除后的字典为: {'name': 'zhangsan', 'age': 10, 'gender': 10}
# dict.popitem()
# 返回并删除字典中的最后一对键和值。
dict2 = {'name': 'zhangsan', 'age': 10, 'gender': 10}
dict2.popitem()
print('删除后的字典为:',dict2) # 删除后的字典为: {'name': 'zhangsan', 'age': 10}4.字典键的特性
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住
dict1 = {'name': 'zs', 'name': 'ls'}
print(dict1) # {'name': 'ls'}
2)键必须不可变,所以可以用数字,字符串或元组充当,但不可以用列表
dict1 = {1: 'zs', 'name': 'ls',['age']: 18}
print(dict1)
Traceback (most recent call last):
File "*********", line 1, in <module>
dict1 = {1: 'zs', 'name': 'ls',['age']: 18}
TypeError: unhashable type: 'list'5.输出字典的长度
dict1 = {'name': 'zhangsan','age': 22,'gender': '男'}
print(len(dict1)) # 36.复制字典dict.copy()
7.创建新字典
seq = ('name', 'age', 'gender')
# 不指定值
dict2 = dict.fromkeys(seq)
print(dict2) # {'name': None, 'age': None, 'gender': None}
# 指定值
dict2 = dict.fromkeys(seq, 10)
print(dict2) # {'name': 10, 'age': 10, 'gender': 10}8.判断键是否存在
dict2 = {'name': 'zhangsan', 'age': 10, 'gender': '男'}
if 'name' in dict2:
print('键存在')
else:
print('键不存在') # 键存在
if 'name1' not in dict2:
print('键不存在')
else:
print('键存在') # 键不存在(六)集合函数
集合(set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
1.集合可以自动去重
set1 = {'java','mysql', 'hadoop', 'spark', 'java'}
print(set1) # {'java', 'spark', 'hadoop', 'mysql'}2.集合之间的运算
a = set('afhduias')
b = set('afhyuias')
# a中有,b中没有
print(a - b) # {'d'}
# a中没有,b中有
print(b - a) # {'y'}
# 集合a或b中包含的所有元素
print(a | b) # {'y', 's', 'd', 'f', 'h', 'a', 'i', 'u'}
# 集合a和b中都包含了的元素——交集
print(a & b) # {'a', 'i', 'u', 'f', 's', 'h'}
# 不同时包含于a和b的元素
print(a ^ b) # {'d', 'y'}
########################################################
# 元素包含在集合 a ,但不在集合 b
a = {'hello', 'world'}
b = {'hello', 'java'}
c = a.difference(b)
d = b.difference(a)
print(a, b) # {'hello', 'world'} {'hello', 'java'}
print(c, d) # {'world'} {'java'}
# difference_update直接在原来的集合中移除元素,没有返回值
a = {'hello', 'world'}
b = {'hello', 'java'}
a.difference_update(b)
print(a, b) # {'world'} {'hello', 'java'}
########################################################
# 返回集合的交集
# intersection()——有返回值
# intersection()_update——没有返回值
#########################################################
symmetric_difference()
3.添加元素add()与update()
set1 = {'java','mysql', 'hadoop', 'spark'}
set1.add('flink')
print(set1) # {'spark', 'mysql', 'java', 'hadoop', 'flink'}
set1 = {('java', 'mysql', 'hadoop', 'spark')}
set1.update({1, 2})
set1.update([1, 4], [2, 6])
print(set1) # {1, 2, 4, 6, ('java', 'mysql', 'hadoop', 'spark')}4.删除集合中的元素
set1 = {'java', 'mysql', 'hadoop', 'spark', 'flink'}
set1.remove('mysql')
# 移除指定元素后顺序打乱
print(set1) # {'spark', 'java', 'flink', 'hadoop'}
##########################################################
set1 = {'java', 'mysql', 'hadoop', 'spark', 'flink'}
print(set1) # {'spark', 'mysql', 'java', 'hadoop', 'flink'}
set1.clear()
print(set1) # set()
##########################################################
# difference_update直接在原来的集合中移除元素,没有返回值
a = {'hello', 'world'}
b = {'hello', 'java'}
a.difference_update(b)
print(a, b) # {'world'} {'hello', 'java'}
##########################################################
# discard() 方法用于移除指定的集合元素。
set1 = {'java', 'mysql', 'hadoop', 'spark'}
set1.discard('java')
print(set1) # {'hadoop', 'mysql', 'spark'}
set1 = {'java', 'mysql', 'hadoop', 'spark'}
set1.discard('oracle')
print(set1) # {'mysql', 'java', 'spark', 'hadoop'}
##########################################################
# 随机移除一个元素
c = {'hello', 'java', 'hadoop'}
c.pop()
print(c) # {'hadoop', 'hello'}
##########################################################
# 返回两个集合中不重复的元素集合——有返回值
a = {'hello', 'java', 'mysql'}
b = {'hello', 'world', 'java'}
print(a.symmetric_difference(b)) # {'mysql', 'world'}
print(a, b) # {'mysql', 'hello', 'java'} {'hello', 'world', 'java'}
# 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中
a = {'hello', 'java', 'mysql'}
b = {'hello', 'world', 'java'}
a.symmetric_difference_update(b) # 没有返回值
print(a) # {'world', 'mysql'}5.复制集合copy()
6.返回多个集合的并集union()
a = {'hello', 'java', 'mysql'}
b = {'hello', 'world', 'java'}
c = {'zs', 'ls', 'ww'}
d = a.union(b,c)
print(d) # {'mysql', 'ls', 'ww', 'java', 'world', 'hello', 'zs'}7.判断是否包含元素
# isdisjoint() 方法用于判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。
a = {'hello1', 'world'}
b = {'hello', 'java'}
c = {'hello', 'java'}
# 判断集合b中是否有包含 集合a的元素
x = a.isdisjoint(b)
# 判断集合c中是否有包含 集合b的元素:
y = b.isdisjoint(c)
print(x, y) # True False
#############################################################
a = {'hello', 'java'}
b = {'hello', 'world', 'java'}
# b是否包含a
print(a.issubset(b)) # True
# b是否完全包含a
print(a.issuperset(b)) # False
##############################################################