热力图(Heatmap)是一种数据可视化工具,它通过使用颜色的深浅来展示数据矩阵中数值的大小或密度。在热力图中,每种颜色的深浅代表数据的一个特定值或值的范围,通常使用红色、黄色和绿色等颜色渐变来表示数据的热度,其中红色通常表示较高的值,而蓝色或绿色则代表较低的值。
热力图的应用非常广泛,以下是一些常见的用途:
网站分析:通过热力图,网站分析师可以了解用户在网页上的点击行为,哪些区域更受欢迎,用户在页面上的浏览路径等。
数据科学:在数据分析和数据科学中,热力图常用于展示数据集中的相关性矩阵、距离矩阵或任何其他形式的矩阵数据。
机器学习:在机器学习领域,热力图可以用来展示特征之间的相关性,或者模型在不同类别上的性能。
地理信息系统(GIS):在GIS中,热力图可以用来表示人口密度、犯罪率、温度分布等地理数据。
生物学:生物学家可以使用热力图来展示基因表达数据,比较不同样本或条件下的基因活动。
以下是一个热力图的基本组成部分:
- 颜色刻度:表示不同颜色对应的数据值范围。
- 数据点:每个数据点在热力图上用一个颜色块表示。
- 坐标轴:通常热力图的X轴和Y轴代表数据的分类或维度。
在实现热力图时,常用的工具和库包括
matplotlib、seaborn(基于matplotlib)等,它们在Python中提供了创建热力图的函数和方法。
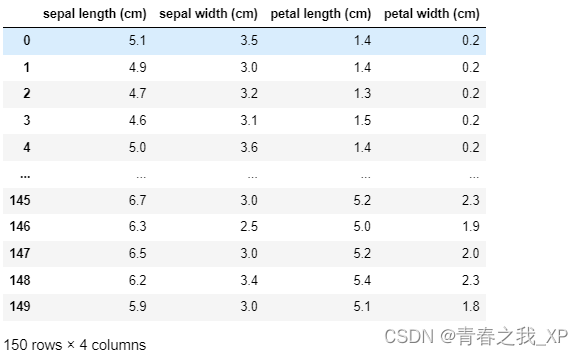
在数据科学领域,了解不同特征之间的相关性是非常重要的。本教程将引导你如何使用Python编程语言和Seaborn库来绘制鸢尾花数据集(Iris dataset)的特征相关性热力图。我们将首先导入所需的库,包括pandas和scikit-learn,然后加载鸢尾花数据集并提取其特征和目标变量。接下来,我们将创建一个数据框来存储这些数据,并使用Seaborn库中的heatmap函数来生成一个可视化的相关性热力图。这个图将帮助我们快速识别数据集中哪些特征之间存在强烈的相关性,从而为进一步的数据分析提供洞见。最后,我们将展示如何对图形进行一些美化处理,比如设置标题、调整字体以及解决负号显示问题。无论你是数据科学新手还是有经验的分析师,这个教程都将帮助你提升数据处理和可视化的技能。
一、准备数据
import pandas as pd
from sklearn.datasets import load_iris
# 加载鸢尾花数据集
iris = load_iris()
# 获取数据和目标变量
X = iris.data
y = iris.target
# 将数据转换为数据框
data = pd.DataFrame(X, columns=iris.feature_names)
# data['target'] = pd.Categorical.from_codes(y, iris.target_names)
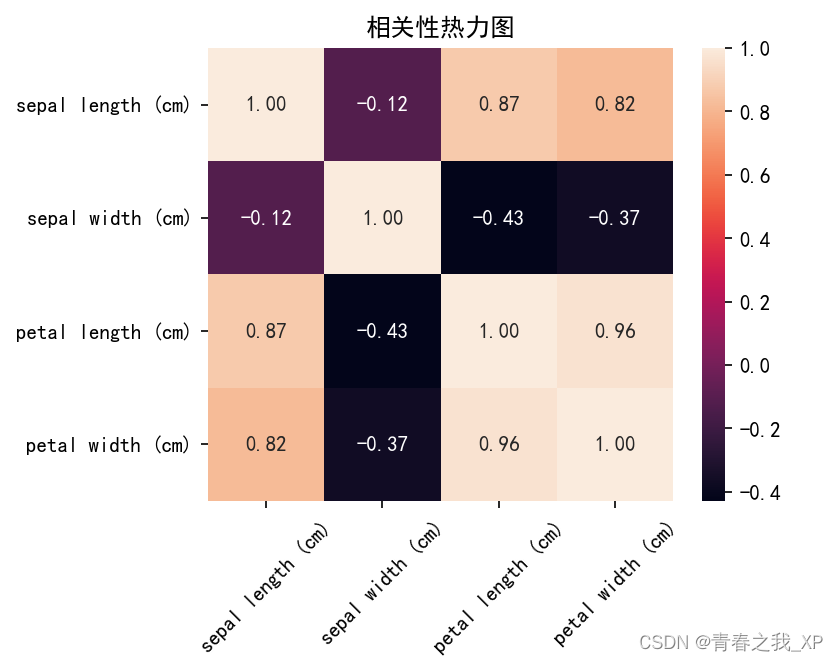
二、绘制热力图
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(5,4),dpi=150)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
ax = sns.heatmap(data.corr(), annot=True, fmt=".2f")
ax.set_title('相关性热力图') # 图标题
plt.xticks(rotation=45)
plt.show()


![[word] word如何清除超链接 #媒体#笔记#知识分享](https://img-blog.csdnimg.cn/img_convert/eec2e03c62507d5043f72728f015a515.gif)