Linux CGroup资源限制(详解)
最近客户认为我们程序占用cpu过高,希望我们限制,排查之后发现是因为程序频繁gc导致,为了精细化、灵活的的限制,想到了使用Linux CGroup。
0 前置知识
①概念及作用
官网:https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html
Linux系统每个进程都可以自由竞争系统资源,有时候会导致一些次要进程占用了系统某个资源(如CPU)的绝大部分,主要进程就不能很好地执行,从而影响系统效率,重则在linux资源耗尽时可能会引起错杀进程。因此linux引入了linux cgroups来控制进程资源,让进程更可控。
- CGroup可以让进程更加的可控。相当于给你画了一个圈,你只能在这个圈里活动(受限制)。
- Linux Cgroup 可让我们为系统中所运行任务(进程)的用户定义组群分配资源,比如 CPU 时间、系统内存、网络带宽或者这些资源的组合。我们可以监控配置的 cgroup,拒绝 cgroup 访问某些资源,甚至在运行的系统中动态配置cgroup。所以,可以将 controll groups 理解为 controller (system resource) (for) (process)groups,也就是是说它以一组进程为目标进行系统资源分配和控制。
主要用处:
- Resource limitation: 限制资源使用,比如内存使用上限以及文件系统的缓存限制。
- Prioritization: 优先级控制,比如:CPU利用和磁盘IO吞吐。
- Accounting: 一些审计或一些统计,主要目的是为了计费。
- Control: 挂起进程,恢复执行进程。
在实践中,系统管理员一般会利用CGroup做下面这些事(有点像为某个虚拟机分配资源):
- 隔离一个进程集合(比如:nginx的所有进程),并限制他们所消费的资源,比如绑定CPU的核。
- 为这组进程分配其足够使用的内存
- 为这组进程分配相应的网络带宽和磁盘存储限制
- 限制访问某些设备(通过设置设备的白名单)
②组成结构及规则
组成结构
Cgroups主要由task,cgroup,subsystem及hierarchy构成。
- Task : 在Cgroups中,task就是系统的一个进程。
- Cgroup : Cgroups中的资源控制都以cgroup为单位实现的。cgroup表示按照某种资源控制标准划分而成的任务组,包含一个或多个Subsystems。一个任务可以加入某个cgroup,也可以从某个cgroup迁移到另外一个cgroup。
- Subsystem : Cgroups中的subsystem就是一个资源调度控制器(Resource Controller)。比如CPU子系统可以控制CPU时间分配,内存子系统可以限制cgroup内存使用量。
- Hierarchy : hierarchy由一系列cgroup以一个树状结构排列而成,每个hierarchy通过绑定对应的subsystem进行资源调度。hierarchy中的cgroup节点可以包含零或多个子节点,子节点继承父节点的属性。整个系统可以有多个hierarchy。
1. Subsystems子系统:可控制的资源类型(CPU、MEM等)
想象一下,你家有个大花园,里面种着各种植物,比如蔬菜区、水果区、花卉区等。每个区域都需要不同的照顾,比如
水、阳光、肥料的量都可能不同。在CGroup中,Subsystems就像是这些不同的区域,代表了操作系统可以控制和限制的资源类型,比如CPU时间、内存使用、磁盘I/O等。每个子系统负责管理和限制一组特定的资源。
Linxu中为了方便用户使用cgroups,已经把其实现成了文件系统,其目录在/sys/fs/cgroup下:
# 查看可限制的资源
ls -l /sys/fs/cgroup

我们可以看到/sys/fs/cgroug目录下有多个子目录,这些目录都可以认为是收到cgroups管理的subsystem资源。每个subsystem对应如下:
- blkio — 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
- cpu — 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
- cpuacct — 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
- cpuset — 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
- devices — 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
- freezer — 这个子系统挂起或者恢复 cgroup 中的任务。
- memory — 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成内存资源使用报告。
- net_cls — 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
- net_prio — 这个子系统用来设计网络流量的优先级
- hugetlb — 这个子系统主要针对于HugeTLB系统进行限制,这是一个大页文件系统。
2. Hierarchies层级结构:自己的控制组
现在,假设你想更细致地管理这些区域,可能会
按照功能或者位置把花园划分成几个区域,每个区域下面再细分。在CGroup里,Hierarchies就是这样的层次结构,它允许你组织和嵌套不同的控制组(Control Groups),形成一个树状结构。每个层级可以挂载不同的子系统,这样就可以在不同的层级上应用不同的资源策略。
3. Control Group控制组:一组进程(类比用户组)
回到花园的例子,如果把每个具体的区域(比如“西红柿区”、“玫瑰区”)看作是一个Control Group,那么它就是一组进程的集合,这些进程共享相同的资源限制和优先级设置。你可以在每个控制组内设定具体某个子系统的使用规则,比如限制西红柿区的水用量,确保玫瑰得到足够的阳光。
4. Tasks运行中的进程:一个进程
Tasks其实就是运行中的进程。在CGroup的上下文中,一个进程(或者线程)可以被分配到某个控制组中,成为那个控制组的成员。这就像是花园里的每株植物,它们各自属于某个区域,并遵循那个区域的管理规则。
四种规则
1. 一个hierarchy附加N个(1个或多个)subsystem
同一个hierarchy能够附加一个或多个subsystem。如 cpu 和 memory subsystems(或者任意多个subsystems)附加到同一个hierarchy。
2. 一个subsystem附加到多个hierarchy
一个 subsystem 可以附加到多个 hierarchy,当且仅当这些 hierarchy 只有这唯一一个 subsystem。即某个hierarchy(hierarchy A)中的subsystem(如CPU)不能附加到已经附加了其他subsystem的hierarchy(如hierarchy B)中。也就是说已经附加在某个 hierarchy 上的 subsystem 不能附加到其他含有别的 subsystem 的 hierarchy 上。
3. 新建一个hierarchy -> root cgroup
系统每次新建一个hierarchy时,该系统上的所有task默认构成了这个新建的hierarchy的初始化cgroup,这个cgroup也称为root cgroup。对于你创建的每个hierarchy,task只能存在于其中一个cgroup中,即一个task不能存在于同一个hierarchy的不同cgroup中,但是一个task可以存在在不同hierarchy中的多个cgroup中。如果操作时把一个task添加到同一个hierarchy中的另一个cgroup中,则会从第一个cgroup中移除。
如:
cpu 和 memory subsystem被附加到 cpu_mem_cg 的hierarchy。而 net_cls subsystem被附加到 net_cls hierarchy。并且httpd进程被同时加到了 cpu_mem_cg hierarchy的 cg1 cgroup中和 net hierarchy的 cg2 cgroup中。并通过两个hierarchy的subsystem分别对httpd进程进行cpu,memory及网络带宽的限制。
4. child task默认与原task在同一个group
进程(task)在 fork 自身时创建的子任务(child task)默认与原 task 在同一个 cgroup 中,但是 child task 允许被移动到不同的 cgroup 中。即 fork 完成后,父子进程间是完全独立的。
Hierarchy层级结构应用场景:云服务器上的多租户应用管理
假设我们是一名云服务提供商,运营着一台高性能的服务器,该服务器上运行着多个租户的应用程序。每个租户都有自己的应用服务组合,可能包含Web服务器、数据库、缓存服务等。为了保证每个租户的资源使用既不会相互干扰,又能充分利用服务器资源,可以使用CGroup的层级结构来实现精细化管理。
- 根层级 (/):这是所有CGroup的起点,你可以在这里挂载所有可用的子系统(CPU、内存、I/O等)。
- 租户层级 (/tenant1, /tenant2, …): 在根层级下,为每个租户创建一个独立的层级,挂载CPU和内存子系统。这样,每个租户的资源使用就被初步隔离了。
- 服务层级 (例如,/tenant1/web, /tenant1/db, /tenant2/web, …): 在每个租户层级下,进一步细分出不同的服务类别,如Web服务、数据库服务等。针对不同服务的特点,可以设置不同的资源限制。例如,数据库服务可能需要较多的内存和I/O带宽,而Web服务则更依赖CPU。
策略:
- 对于/tenant1/db控制组,由于数据库操作通常较重,可以限制其使用不超过总CPU的30%,并分配较大比例的内存和I/O带宽。
- 对于/tenant2/web控制组,由于Web服务器更多涉及轻量级请求处理,可以限制其CPU使用率上限较低,但要求快速响应,因此给予较高的I/O优先级。
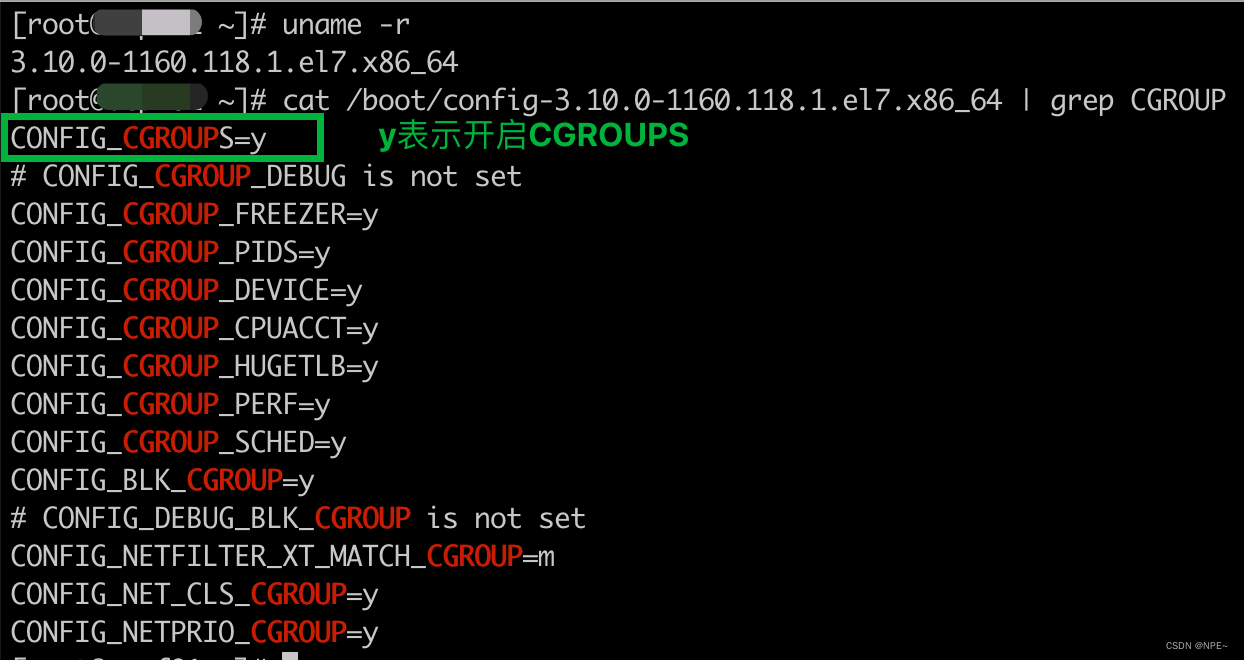
③查看系统是否开启cgroups
# 查看os信息(内核版本,硬件架构等)
uname -r
# 查看配置文件
cat /boot/config-xxx | grep CGROUP
1 配置文件方式
①支持参数(常用)
仅列出常用配置
②案例:限制进程CPU使用率
## 限制CPU使用
# pgrep xxx # 获取进程PID 14802
ps -ef | grep 进程名
mkdir /sys/fs/cgroup/cpu/test
# 将PID写入到文件
echo 14802 > /sys/fs/cgroup/cpu/test/cgroup.procs
# 该进程限制cpu 20%
echo 20000 > /sys/fs/cgroup/cpu/test/cpu.cfs_quota_us
# 解除cpu限制
echo -1 > /sys/fs/cgroup/cpu/test/cpu.cfs_quota_us
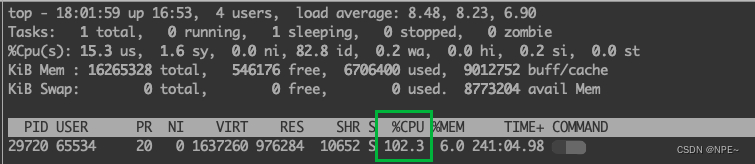
- 限制之前:
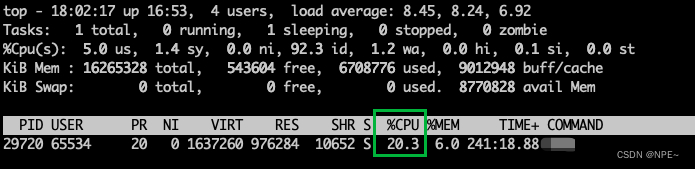
- 限制进程只能使用0.2核(cpu:20%)
2 系统服务方式systemd
cgroup有两个版本,新版本的cgroup v2即Unified cgroup(参考cgroup v2)和传统的cgroup v1(参考cgroup v1),在新版的Linux(4.x)上,v1和v2同时存在,但同一种资源(CPU、内存、IO等)只能用v1或者v2一种cgroup版本进行控制。systemd同时支持这两个版本,并在设置时为两者之间做相应的转换。对于每个控制器,如果设置了cgroup v2的配置,则忽略所有v1的相关配置。
- systemd通过Unit的配置文件配置资源控制,Unit包括services, slices, scopes, sockets, mount points, 和swap devices六种。systemd底层也是依赖Linux Control Groups (cgroups)来实现资源控制。
V1、V2区别:
- CPU: CPUWeight=和StartupCPUWeight=取代了CPUShares=和StartupCPUShares=。cgroup v2没有"cpuacct"控制器
- Memory:MemoryMax=取代了MemoryLimit=. MemoryLow= and MemoryHigh=只在cgroup v2上支持。
- IO:BlockIO前缀取代了IO前缀。在cgroup v2,Buffered写入也统计在了cgroup写IO里,这是cgroup v1一直存在的问题。
①CGroup V2(常用配置)
文档地址:https://www.kernel.org/doc/Documentation/cgroup-v2.txt
- 这里只列出常用配置,详细请见对应文档
1. CPUQuota:设置服务可用CPU上限
用于设置cgroup v2的cpu.max参数或者cgroup v1的cpu.cfs_quota_us参数。表示可以占用的CPU时间配额百分比。如:20%表示最大可以使用单个CPU核的20%。可以超过100%,比如200%表示可以使用2个CPU核。
2. MemoryLow=bytes:服务最低占用内存
用于设置cgroup v2的memory.low参数,不支持cgroup v1。当unit使用的内存低于该值时将被保护,其内存不会被回收。可以设置不同的后缀:K,M,G或者T表示不同的单位。
3. MemoryHigh=bytes:预期服务占用最高内存(不精准)
用于设置cgroup v2的memory.high参数,不支持cgroup v1。内存使用超过该值时,进程将被降低运行时间,并快速回收其占用的内存。同样可以设置不同的后缀:K,M,G或者T(单位1024)。也可以设置为infinity表示没有限制。
4. MemoryMax=bytes:服务占用最大内存(超过即被kill)
用于设置cgroup v2的memory.max参数,如果进程的内存超过该限制,则会触发out-of-memory将其kill掉。同样可以设置不同的后缀:K,M,G或者T(单位1024),以及设置为infinity。该参数去掉旧版本的MemoryLimit=。
5. TasksMax=N:unit可创建的最大task数
用于设置cgroup的pids.max参数。控制unit可以创建的最大tasks个数。
6. IOReadBandwidthMax=device bytes, IOWriteBandwidthMax=device bytes(带宽上限)
设置磁盘IO读写带宽上限,对应cgroup v2的io.max参数。该参数格式为“path bandwidth”,path为具体设备名或者文件系统路径(最终限制的是文件系统对应的设备名)。数值bandwidth支持以K,M,G,T后缀(单位1000)。可以设置多行以限制对多个设备的IO带宽。该参数取代了旧版本的BlockIOReadBandwidth=和BlockIOWriteBandwidth=。
7. IOReadIOPSMax=device IOPS, IOWriteIOPSMax=device IOPS(磁盘IOPS上限)
设置磁盘IO读写的IOPS上限,对应cgroup v2的io.max参数。格式和上面带宽限制的格式一样一样的。
8. DevicePolicy=auto|closed|strict(设备访问策略)
控制设备访问的策略。
- strict表示:只允许明确指定的访问类型;
- closed表示:此外,还允许访问包含/dev/null,/dev/zero,/dev/full,/dev/random,/dev/urandom等标准伪设备。
- auto表示如果没有明确的DeviceAllow=存在,则允许访问所有设备。auto是默认设置。
9. Delegate=false:开启后unit可以在单其cgroup下创建和管理其自己的cgroup的私人子层级
默认关闭,开启后将更多的资源控制交给进程自己管理。开启后unit可以在单其cgroup下创建和管理其自己的cgroup的私人子层级,systemd将不在维护其cgoup以及将其进程从unit的cgroup里移走。
②CGroup V1(V2被废弃的配置项)
文档地址:https://www.kernel.org/doc/Documentation/cgroup-v2.txt
- 这里只列出CGroupV2被废弃或修改的配置项,详细请见对应文档
- 这些是旧版本的选项,新版本已经弃用。列出来是因为centos 7里的systemd是旧版本,所以要使用这些配置。
1. CPUShares=weight, StartupCPUShares=weight(获取CPU的权重值)
进程获取CPU运行时间的权重值,对应cgroup的"cpu.shares"参数,取值范围2-262144,默认值1024。
2. MemoryLimit=bytes:进程内存使用上限
对应cgroup的"memory.limit_in_bytes"参数。支持K,M,G,T(单位1024)以及infinity。默认值-1表示不限制。
3. BlockIOWeight=weight, StartupBlockIOWeight=weight:磁盘IO的权重
对应cgroup的"blkio.weight"参数。取值范围10-1000,默认值500。
4. BlockIODeviceWeight=device weight:指定磁盘的IO权重
对应cgroup的"blkio.weight_device"参数。取值范围1-1000,默认值500。
5. BlockIOReadBandwidth=device bytes, BlockIOWriteBandwidth=device bytes:磁盘IO带宽的上限配置
对应cgroup的"blkio.throttle.read_bps_device"和 "blkio.throttle.write_bps_device"参数。支持K,M,G,T后缀(单位1000)。
③案例:限制服务CPU使用率
# 修改服务配置文件
vim /etc/systemd/system/test.service
[Unit]
Description=test service
After=network.target
[Service]
ExecStart=xxxxxx
ExecStopPost=xxxxxx
Restart=always
CPUQuota=75% # 配置服务CPU最多只能占用0.75核
[Install]
WantedBy=multi-user.target
# 重新加载服务
systemctl daemon-reload
# 重启服务
systemctl restart test.service
参考文章:
https://www.cnblogs.com/jimbo17/p/9107052.html
https://blog.csdn.net/lisemi/article/details/94021498