欢迎来到Golang的世界!在当今快节奏的软件开发领域,选择一种高效、简洁的编程语言至关重要。而在这方面,Golang(又称Go)无疑是一个备受瞩目的选择。在本文中,带领您探索Golang的世界,一步步地了解这门语言的基础知识和实用技巧。
目录
初识协程
启动多协程
初识锁
初识管道
协程与管道协同
初识协程
在go语言中,"协程"(coroutine)通常指的是go的轻量级线程,也被称为goroutine,它使得并发编程变得更加简单和高效。这里我先对go语言中其他概念进行一个简单叙述:
1)程序(program)
是为完成特定任务、用某种语言编写的一组指令的集合,是一段静态的代码(程序是静态的)
2)进程(process)
是程序的一次执行过程,正在运行的一个程序,进程作为资源分配的单位,在内存中会为每个进程分配不同的内存区域。(进程是动态的)是一个动的过程,进程的生命周期:有它自身的产生、存在和消亡的过程
3)线程(thread)
进程可进一步细化为线程,是一个程序内部的一条执行路径,若一个进程同一时间并行执行多个线程,就是支持多线程的。
4)协程(goroutine)
又称为微线程,纤程,协程是一种用户态的轻量级线程

与传统的线程相比,goroutine非常轻量,它们的创建和销毁成本很低,因此可以大量创建而不会对系统造成太大的负担,因此它是go实现高效并发编程的核心机制之一。
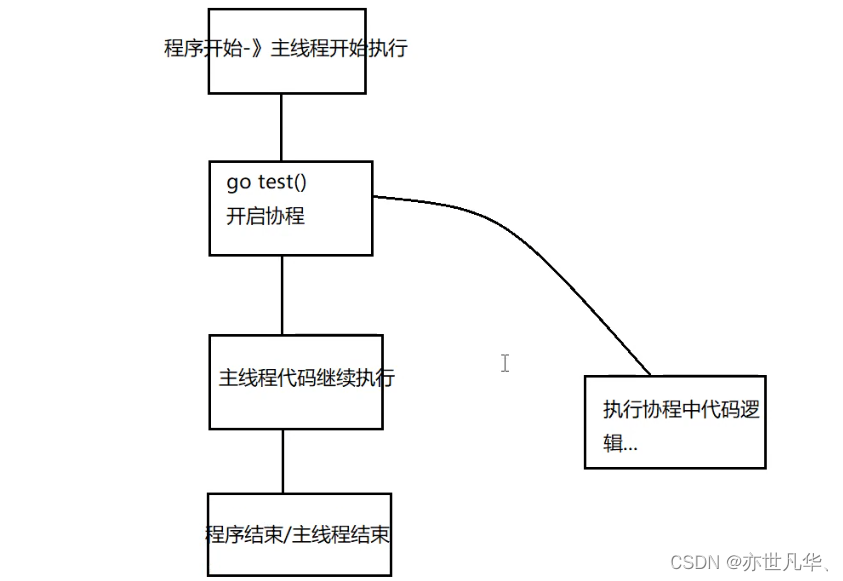
协程的作用:在执行A函数的时候,可以随时中断,去执行B函数,然后中断继续执行A函数(可以自动切换),注意这一切换过程并不是函数调用(没有调用语句),过程很像多线程,然而协程中只有一个线程在执行 (协程的本质是个单线程),如下图所示:

对于单线程下,我们不可避免程序中出现io操作,但如果我们能在自己的程序中(即用户程序级别,而非操作系统级别)控制单线程下的多个任务能在一个任务遇到io阻塞时就将寄存器上下文和栈保存到某个其他地方,然后切换到另外一个任务去计算。在任务切回来的时候,恢复先前保存的寄存器上下文和栈,这样就保证了该线程能够最大限度地处于就绪态,即随时都可以被cpu执行的状态。
相当于我们在用户程序级别将自己的io操作最大限度地隐藏起来,从而可以迷惑操作系统,让其看到:该线程好像是一直在计算,io比较少,从而会更多的将cpu的执行权限分配给我们的线程(注意:线程是CPU控制的,而协程是程序自身控制的,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级)
我们老说协程协程,那么协程到底如何实现呢?这里给出下面的案例进行讲解:
请编写一个程序,完成如下功能:
1)在主线程中,开启一个goroutine,该goroutine每隔1秒输出"hello golang"
2)在主线程中也每隔一秒输出"hello world",输出10次后,退出程序
3)要求主线程和goroutine同时执行
package main
import (
"fmt"
"strconv"
"time"
)
func test() {
for i := 0; i < 10; i++ {
fmt.Println("hello golang + " + strconv.Itoa(i))
// 阻塞1秒
time.Sleep(1 * time.Second)
}
}
func main() { // 主线程
go test() // 开启协程
for i := 0; i < 10; i++ {
fmt.Println("hello world + " + strconv.Itoa(i))
// 阻塞1秒
time.Sleep(1 * time.Second)
}
}开启协程之后,协程和主线程交替执行,效果如下:
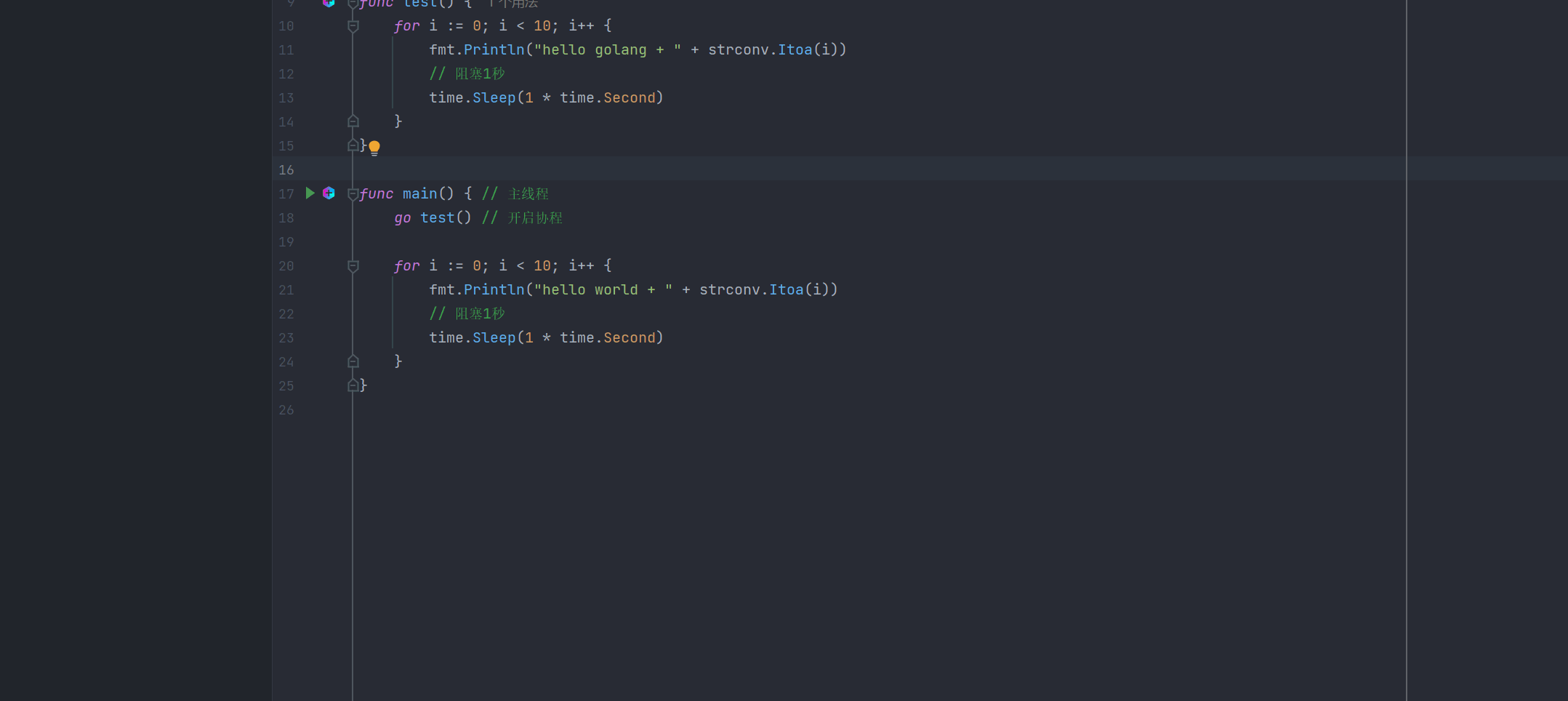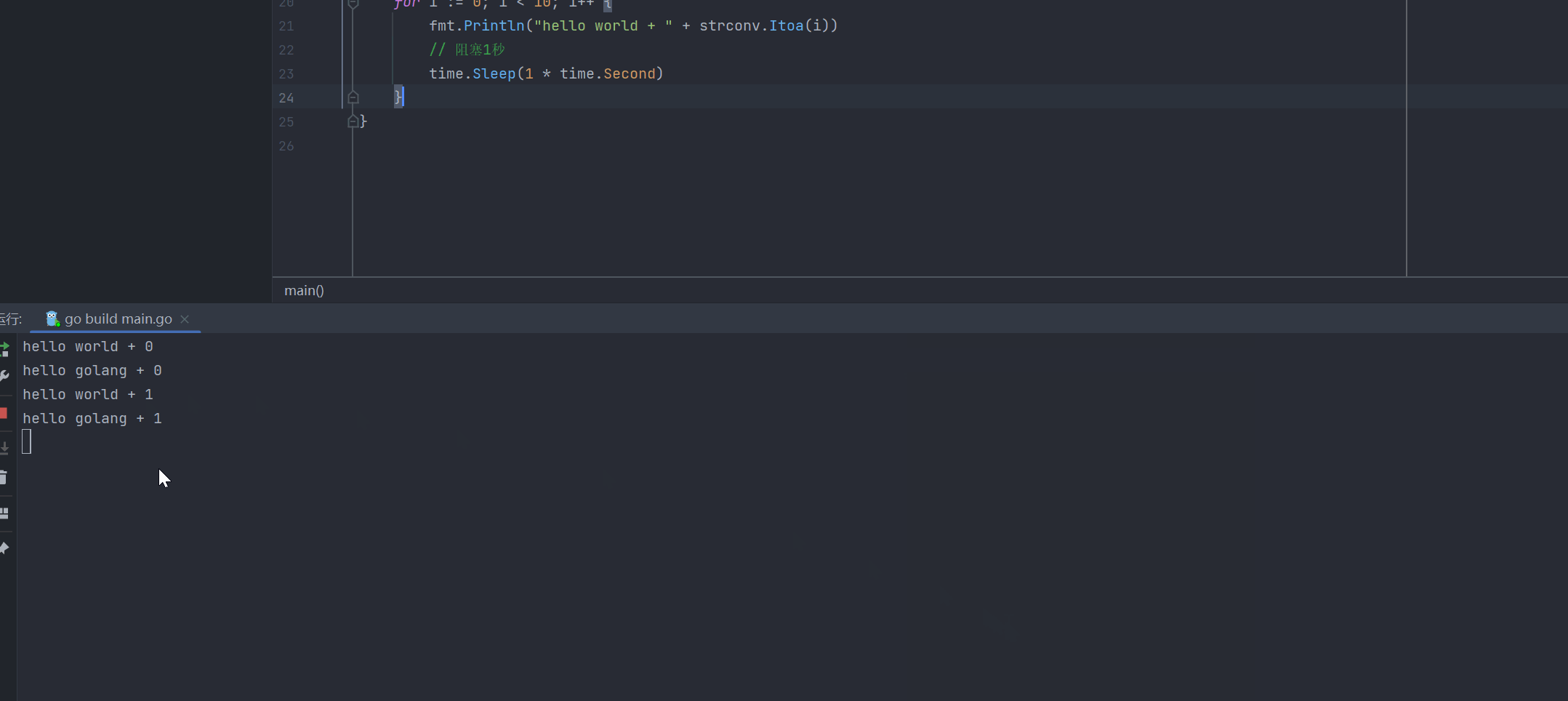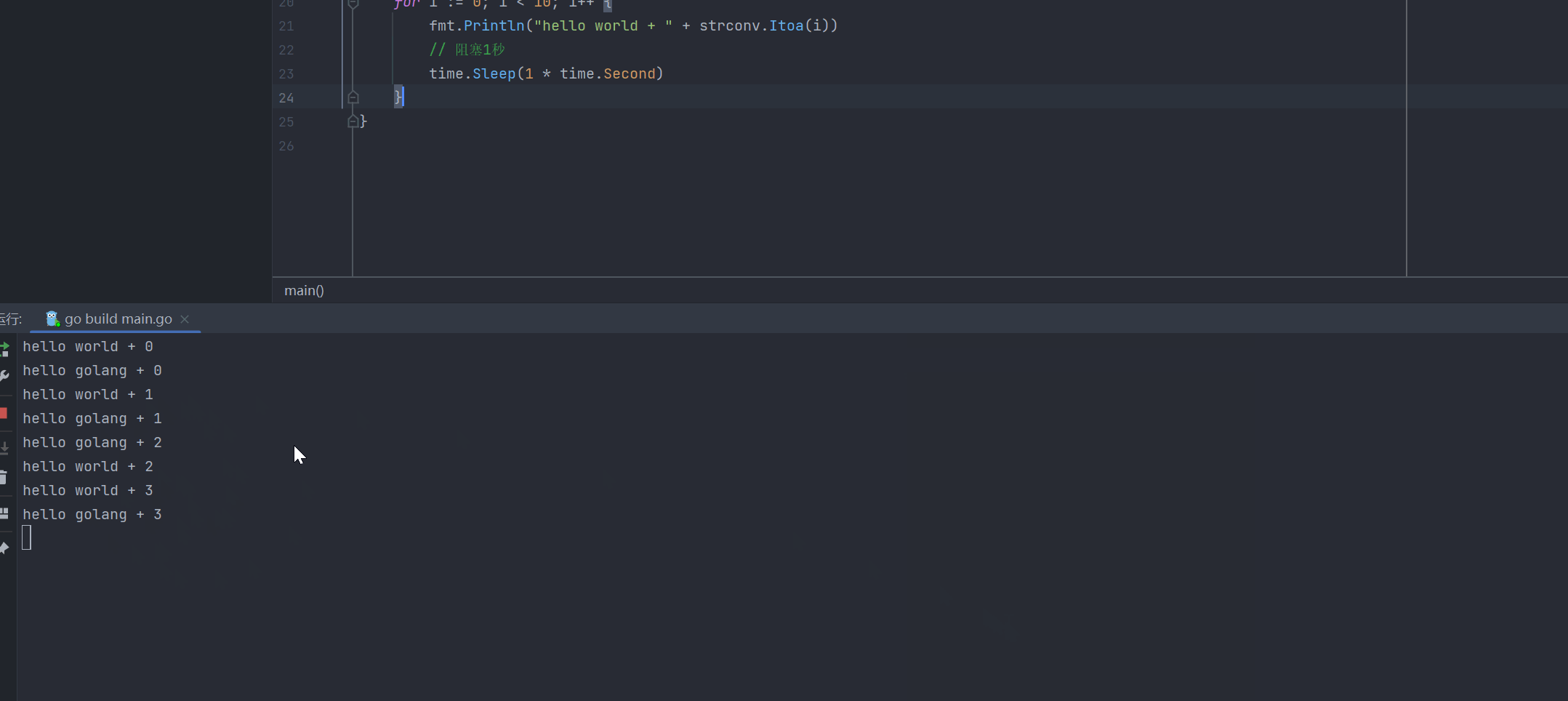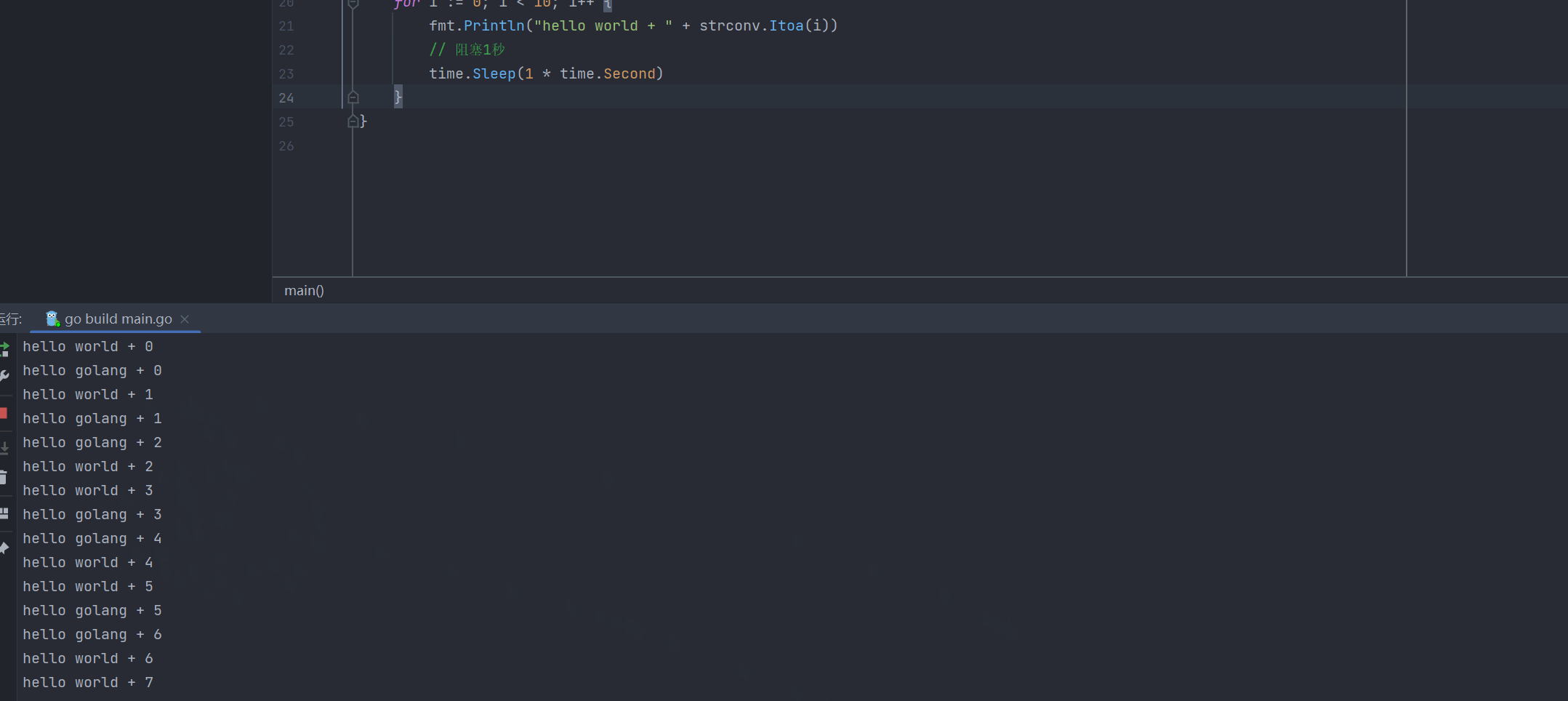
主线程和协程执行流程:可以从下图所示看到:
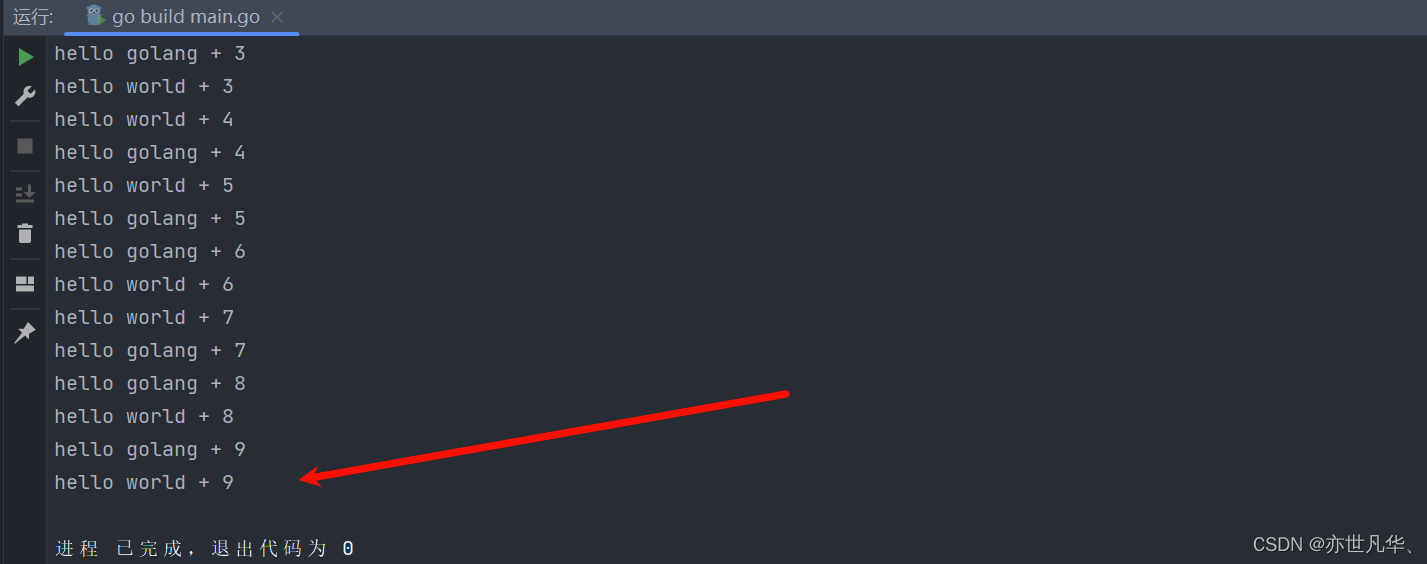
主死协从: 在go语言中有如下概念,如果主线程退出了,则协程即使还没有执行完毕,也会退出,当然协程也可以在主线程没有退出前,就自己结束了,比如完成了自己的任务,这里我们对上面的代码进行一个简单的修改,让协程的任务量变大,如下:

当我们运行程序之后,即使协程没有执行完毕,其仍要跟随主程序的结束而结束:
启动多协程
相比于线程,协程的创建和销毁成本非常低,这里可以在同一时间启动多个协程,它们会并发执行,go运行时会自动调度协程,以便它们可以在多个操作系统线程上运行,协程之间通常通过通道进行通信,以避免共享状态导致的竞态条件。下面是一个简单的go代码示例:
package main
import (
"fmt"
"time"
)
func main() {
// 匿名函数+外部变量 = 闭包
for i := 0; i <= 5; i++ {
// 启动协程,使用匿名函数直接调用匿名按时
go func(n int) {
fmt.Println(n)
}(i)
}
time.Sleep(time.Second * 2)
}最终实现的效果如下所示,由于它们都在并发地运行,所以输出的顺序可能是不确定的,如果你想要控制协程的执行顺序或等待它们完成,你可以使用通道或其他同步机制,这个后面再讲:

当然如果不想使用time.Sleep的方式的话,也可以采用下面的方式进行实现:
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup // 只定义无需赋值
func main() {
// 启动五个协程
for i := 0; i < 5; i++ {
wg.Add(1) // 计数器加一
go func(n int) {
fmt.Println(n)
wg.Done() // 协程执行完成减1
}(i)
}
// 主线程一直在阻塞,什么时候wg减为0就停止
wg.Wait()
}如果多个协程操作同一个数据的情况下,给出如下代码进行示例:
package main
import (
"sync"
)
// 定义一个变量
var totalNum int
var wg sync.WaitGroup // 只定义无需赋值
func add() {
defer wg.Done()
for i := 0; i < 100000000; i++ {
totalNum++
}
}
func sub() {
defer wg.Done()
for i := 0; i < 100000000; i++ {
totalNum--
}
}
func main() {
wg.Add(2)
// 启动两个协程
go add()
go sub()
// 等待协程结束
wg.Wait()
println(totalNum)
}因为协程是交替不确定的执行,结果可能都不一样,如下图所示:

初识锁
从上文的案例可以看出,如果多个协程操作同一个数据, 因为协程会交替并发执行,所以会出现争抢资源的情况,导致最终的结果可能并不是我们想要的,那么我们如何处理这个问题呢?这里我们就需要通过一个机制,确保一个协程在执行逻辑的时候另外的协程不执行,这里我们就需要引入一个概念:“锁的机制”,即加入互斥锁,示例代码如下,最终结果为0,是我们想要的:
package main
import (
"sync"
)
// 定义一个变量
var totalNum int
var wg sync.WaitGroup // 只定义无需赋值
// 加入互斥锁
var lock sync.Mutex
func add() {
defer wg.Done()
for i := 0; i < 100000000; i++ {
lock.Lock() // 加锁
totalNum++
lock.Unlock() // 解锁
}
}
func sub() {
defer wg.Done()
for i := 0; i < 100000000; i++ {
lock.Lock() // 加锁
totalNum--
lock.Unlock() // 解锁
}
}
func main() {
wg.Add(2)
// 启动两个协程
go add()
go sub()
// 等待协程结束
wg.Wait()
println(totalNum)
}当然golang中sync包实现了两种锁Mutex(互斥锁)和RWMutex(读写锁),具体如下:
1)互斥锁:其中Mutex为互斥锁,Lock(加锁,Unlock()解锁,使用Lock()加锁后,便不能再次对其进行加锁,直到利用Unlock(解锁对其解锁后,才能再次加锁.适用于读写不确定场景,即读写次数没有明显的区别,其性能和效率相对较低。
2)读写锁:RWMutex是一个读写锁,其经常用于读次数远远多于写次数的场景,在读的时候数据之间不产生影响,写和读之间才会产生影响。
package main
import (
"fmt"
"sync"
"time"
)
// 定义一个变量
var totalNum int
var wg sync.WaitGroup // 只定义无需赋值
// 加入读写锁
var lock sync.RWMutex
func read() {
defer wg.Done()
lock.RLock() // 读锁,如果只是读数据那么这个锁不产生任何影响,但是读写同时发生时,就会有影响
fmt.Println("开始读取数据")
time.Sleep(time.Second)
fmt.Println("读取数据完毕")
lock.RUnlock() // 关锁
}
func write() {
defer wg.Done()
lock.Lock() // 写锁
fmt.Println("开始写入数据")
time.Sleep(time.Second)
fmt.Println("写入数据完毕")
lock.Unlock() // 关锁
}
func main() {
wg.Add(6)
// 启动两个协程,读多写少
for i := 0; i < 5; i++ {
go read()
}
go write()
// 等待协程结束
wg.Wait()
}
初识管道
在go语言中,管道(Channel)是一种特殊的类型,用于在协程(goroutine)之间进行通信,它允许一个协程将数据发送到管道,并由另一个协程从管道中接收数据。这种机制可以实现协程之间的同步和数据交换,以下是管道相关特点介绍:
1)管道本质就是一个数据结构-队列
2)数据是先进先出
3)自身线程安全,多协程访问时,不需要加锁,channel本身就是线程安全的
4)管道有类型的,一个string的管道只能存放string类型数据

管道的定义: var 变量名chan 数据类型
chan是管道关键字;数据类型指的是管道的类型,里面放入数据的类型,管道是有类型的,intChan只能写入整数int;管道是引用类型,必须初始化才能写入数据,即make后才能使用。
package main
import "fmt"
func main() {
// 定义一个int类型管道
var intChan chan int
// 通过make初始化,管道可以存放3个int类型数据
intChan = make(chan int, 3)
// 证明管道是引用类型
fmt.Printf("intChan的值:%v \n", intChan) // intChan的值:0xc000018200
// 向管道存放数据,注意存放的数据不能超出管道的容量
intChan <- 1 // 往管道中存放数据
num := 20
intChan <- num // 往管道中存放数据
// 取出管道数据(队列先进先出)
fmt.Printf("intChan的值:%v \n", <-intChan) // intChan的值:1
fmt.Printf("intChan的值:%v \n", <-intChan) // intChan的值:20
// 输出管道的长度
fmt.Printf("intChan的长度:%d \n", len(intChan)) // intChan的长度:2
}管道的关闭:使用内置函数close可以关闭管道,当管道关闭后,就不能再向管道写数据了,但是仍然可以从该管道读取数据。
package main
import "fmt"
func main() {
// 定义管道
var intChan chan int
// 通过make初始化管道,可以存放3个int类型数据
intChan = make(chan int, 3)
// 往管道中写入数据
intChan <- 1
intChan <- 2
// 关闭管道
close(intChan)
// 再次写入数据会报错
//intChan <- 3 // panic: send on closed channel
// 当管道关闭后,再读取数据是可以的
num := <-intChan
fmt.Println(num) // 1
}管道的遍历:管道支持for-range的方式进行遍历,请注意两个细节:
1)在遍历时,如果管道没有关闭,则会出现deadlock的错误
2)在遍历时,如果管道已经关闭,则会正常遍历数据,遍历完后,就会退出遍历。
package main
import "fmt"
func main() {
// 定义管道
var intChan chan int
// 通过make初始化管道,可以存放100个int类型数据
intChan = make(chan int, 100)
// 往管道中写入数据
for i := 0; i < 100; i++ {
intChan <- i
}
// 在遍历前,如果没有关闭管道,就会出现deedlock的错误
// 遍历管道中的数据
for v := range intChan {
fmt.Println("value = ", v)
}
}如上代码由于没有关闭管道,导致出现如下问题:
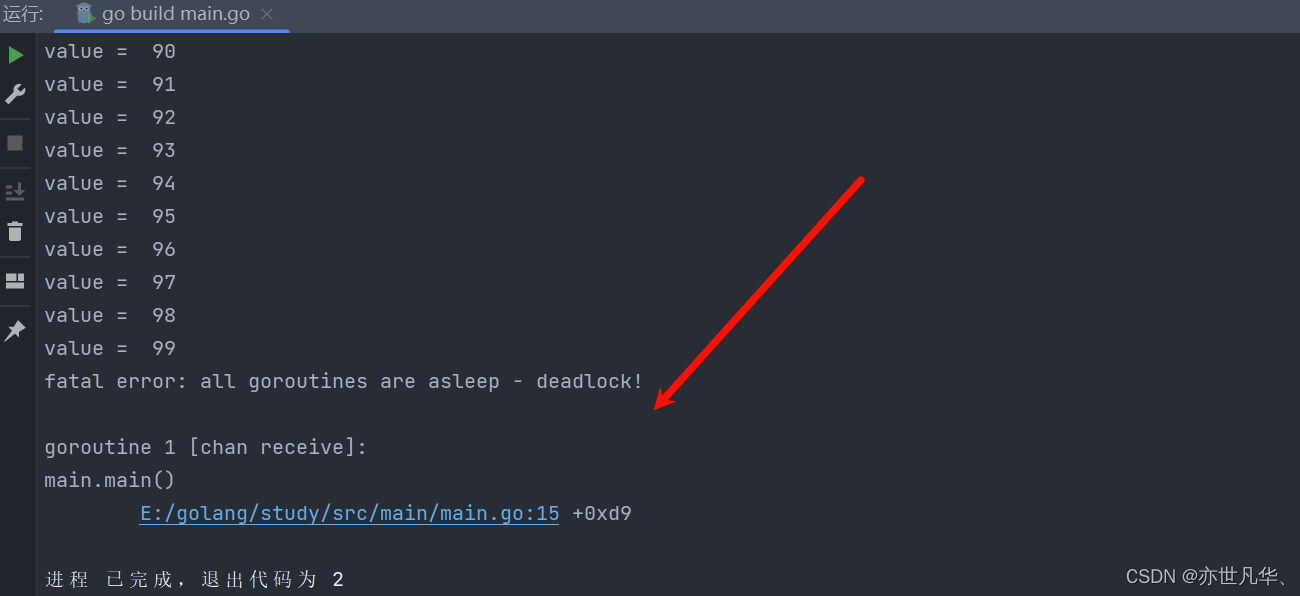
所以我们需要在遍历管道前,需要进行管道的关闭,如下:

管道的只读只写: 可以在初始化管道的时候,通过代码设置只读只写属性,如下:
func main() { // 主线程
// 默认情况下,管道是双向的,可读可写
var intChan chan int
// 声明为只写管道
var intChan1 chan<- int
// 声明为只读管道
var intChan2 <-chan int
}select功能:解决多个管道的选择问题,也可以叫做多路复用,可以从多个管道中随机公平地选择一个来执行,如下代码输出的就是hello
1)case后面必须进行的是io操作,不能是等值,随机去选择一个io操作
2)default防止select被阻塞住,加入default
package main
import (
"fmt"
"time"
)
func main() { // 主线程
// 定义一个int类型管道
intChan := make(chan int, 1)
go func() {
time.Sleep(time.Second * 5)
intChan <- 1
}()
// 定义一个string类型管道
stringChan := make(chan string, 1)
go func() {
time.Sleep(time.Second * 2)
stringChan <- "hello"
}()
//fmt.Println(<-intChan) // 阻塞等待,本身取数据就是阻塞的
select {
case v := <-intChan:
fmt.Println("intChan: ", v)
case v := <-stringChan:
fmt.Println("stringChan: ", v)
default:
fmt.Println("防止select被阻塞")
}
}异常错误捕获:多个协程工作,其中一个协程出现panic,导致程序崩溃,这里利用refer+recover捕获panic进行处理,即使协程出现问题,主线程仍然不受影响可以继续执行,示例代码如下:
package main
import (
"fmt"
"time"
)
// 输出数字
func printNum() {
for i := 0; i < 10; i++ {
fmt.Println(i)
}
}
// 除法操作
func devide() {
defer func() {
err := recover()
if err != nil {
fmt.Println("程序异常退出")
}
}()
num1 := 10
num2 := 0
result := num1 / num2
fmt.Println(result)
}
func main() {
// 启动两个协程
go printNum()
go devide()
time.Sleep(time.Second * 5)
}得到的结果如下所示:

协程与管道协同
接下来我们通过一个案例来实现协程与管道的共同操作,案例需求如下:
请完成协程和管道协同工作的案例,具体要求:
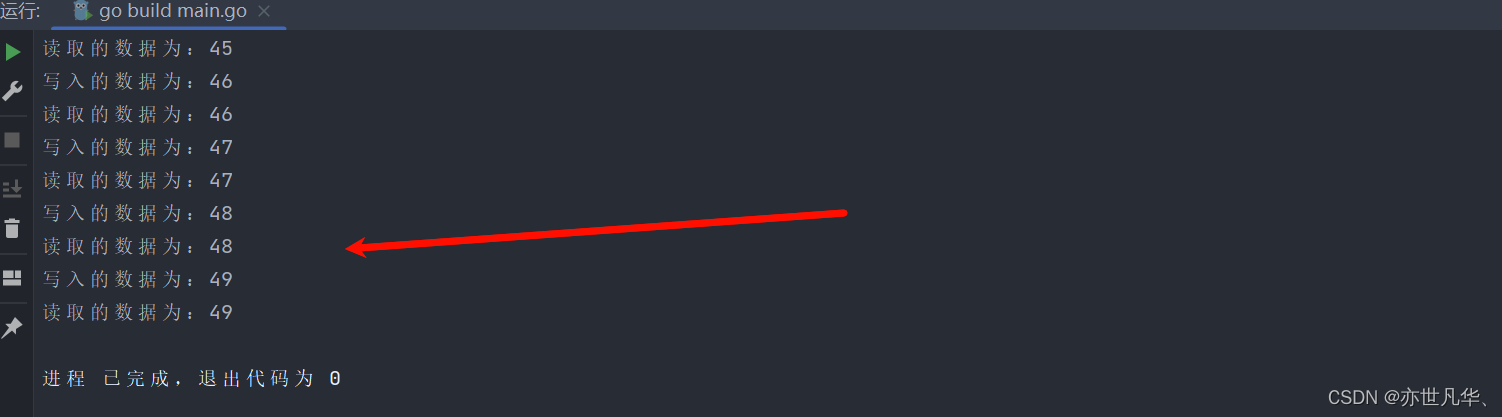
1)开启一个writeData协程,向管道中写入50个整数。
2)开启一个readData协程,从管道中读取writeData写入的数据。
3)注意:writeData和readDate操作的是同一个管道。
4)主线程需要等待writeData和readDate协程都完成工作才能退出
其对应的原理图如下所示:

package main
import (
"fmt"
"strconv"
"sync"
"time"
)
var wg sync.WaitGroup
// 写数据
func writeData(intChan chan int) {
defer wg.Done()
for i := 0; i < 50; i++ {
intChan <- i
fmt.Println("写入的数据为:" + strconv.Itoa(i))
time.Sleep(time.Second)
}
// 关闭通道
close(intChan)
}
// 读数据
func readData(intChan chan int) {
defer wg.Done()
for i := range intChan {
fmt.Println("读取的数据为:" + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
func main() { // 主线程
// 写协程和读协程共同操作同一个通道
intChan := make(chan int, 50)
wg.Add(2)
// 开启读和写的协程
go writeData(intChan)
go readData(intChan)
// 主线程一直在阻塞,什么时候wg.Done()减为0,主线程才会结束
wg.Wait()
}最终实现的效果如下所示: