Spark MLlib 机器学习详细教程
Apache Spark 是一个强大的开源分布式计算框架,广泛用于大数据处理和分析。Spark 提供了丰富的库,其中 MLlib 是其机器学习库,专为大规模数据处理设计。本教程将详细介绍 Spark MLlib,包括其主要功能、常见应用场景、具体实现步骤和示例代码。
目录
- Spark MLlib 简介
- 安装与配置
- 数据准备
- 常见算法与应用场景
- 线性回归
- 逻辑回归
- 决策树
- 随机森林
- 支持向量机
- 聚类算法
- 推荐系统
- 数据预处理
- 数据清洗
- 特征工程
- 模型训练与评估
- 训练模型
- 模型评估
- 模型保存与加载
- 案例分析
- 房价预测
- 电影推荐系统
- 总结
Spark MLlib 简介
Spark MLlib 是 Spark 生态系统中的机器学习库,旨在提供可扩展的机器学习算法和实用工具。MLlib 支持多种通用的机器学习算法,包括分类、回归、聚类和协同过滤等,此外还提供特征提取、转换、降维和数据预处理等功能。
主要特点
- 高性能:利用 Spark 的内存计算能力,MLlib 可以处理大规模数据集,训练速度快。
- 易用性:提供了简洁的 API,易于与 Spark 其它组件(如 SQL、Streaming)集成。
- 丰富的算法:支持多种常见的机器学习算法,涵盖分类、回归、聚类、协同过滤等。
- 跨语言支持:MLlib 支持多种编程语言,包括 Scala、Java、Python 和 R。
适用场景
- 大规模数据处理:适用于需要处理大规模数据集的机器学习任务。
- 实时数据分析:与 Spark Streaming 结合,适用于实时数据分析和处理。
- 复杂数据管道:通过与 Spark SQL、GraphX 等组件集成,适用于复杂的数据分析管道。
安装与配置
在使用 Spark MLlib 之前,需要安装和配置 Spark。以下是 Spark 安装与配置的基本步骤。
安装 Spark
- 下载 Spark:从 Apache Spark 官方网站 下载适合的版本。
- 解压文件:将下载的文件解压到指定目录。
- 设置环境变量:配置
SPARK_HOME环境变量指向 Spark 安装目录,并将其 bin 目录添加到PATH中。
export SPARK_HOME=/path/to/spark
export PATH=$PATH:$SPARK_HOME/bin
配置 Spark
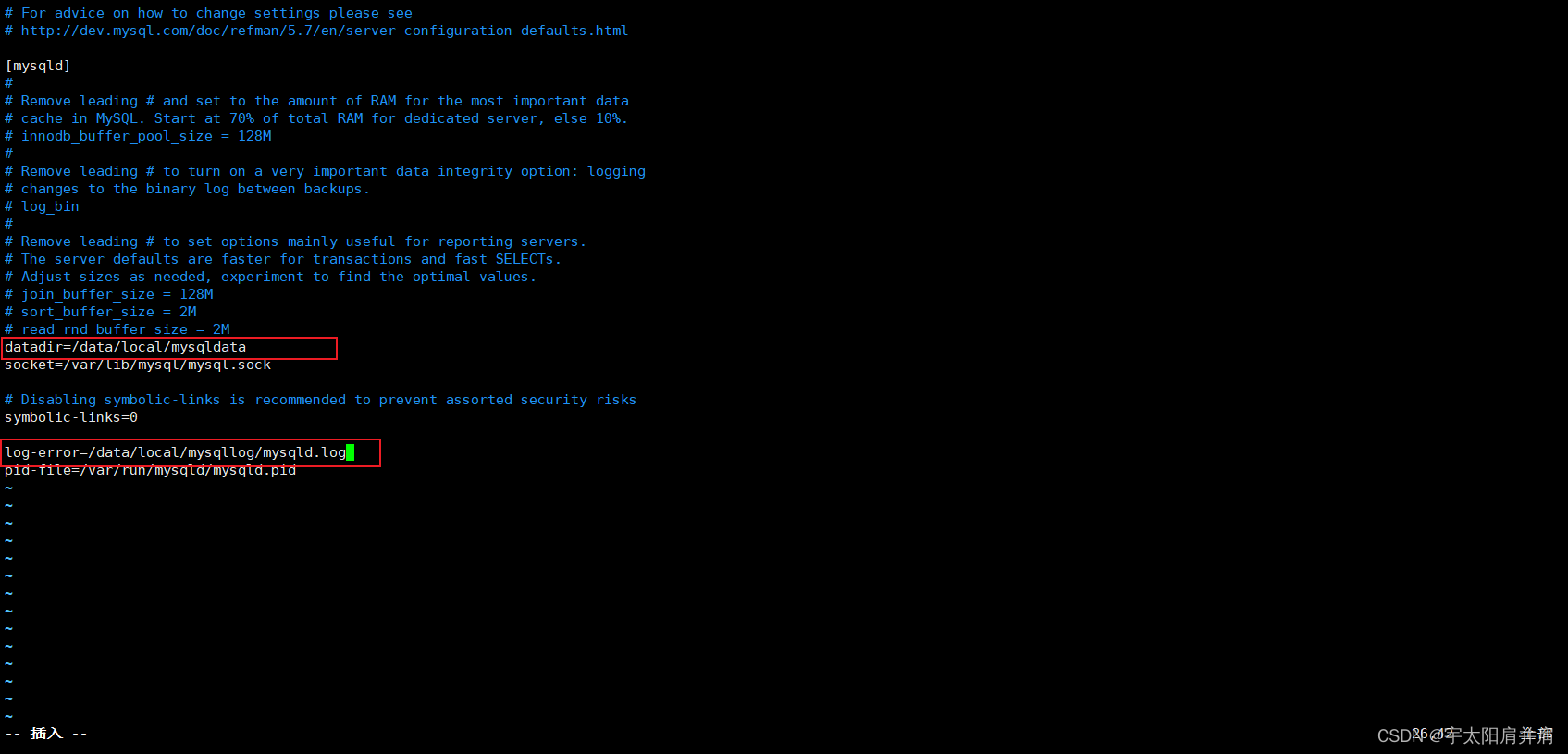
Spark 可以在本地模式或集群模式下运行。以下是基本的配置文件:
conf/spark-env.sh:用于配置 Spark 的环境变量。conf/spark-defaults.conf:用于配置 Spark 的默认参数。conf/log4j.properties:用于配置 Spark 的日志级别。
启动 Spark Shell
安装和配置完成后,可以启动 Spark Shell 进行测试:
spark-shell
对于 Python 用户,可以使用 pyspark 启动 PySpark Shell:
pyspark
数据准备
在进行机器学习任务之前,需要准备数据。数据准备包括数据收集、数据清洗和数据转换等步骤。Spark 提供了多种数据源支持,包括 HDFS、S3、HBase、Cassandra 以及本地文件系统等。
加载数据
以下是使用 Spark 加载不同数据源的示例:
从本地文件加载数据
val data = spark.read.textFile("data.txt")
从 HDFS 加载数据
val data = spark.read.textFile("```scala
val data = spark.read.textFile("hdfs://namenode:9000/path/to/data.txt")
从 S3 加载数据
val data = spark.read.textFile("s3a://bucket-name/path/to/data.txt")
从 CSV 文件加载数据
val df = spark.read
.option("header", "true") // 表示 CSV 文件有表头
.option("inferSchema", "true") // 自动推断数据类型
.csv("path/to/data.csv")
数据预处理
数据预处理是机器学习过程中非常重要的一步。它包括数据清洗、特征工程和数据转换等步骤。
数据清洗
数据清洗包括处理缺失值、去除重复数据和处理异常值等。以下是一些常见的数据清洗操作:
处理缺失值
// 删除包含缺失值的行
val cleanedDF = df.na.drop()
// 填充缺失值
val filledDF = df.na.fill(Map("column1" -> 0, "column2" -> "unknown"))
去除重复数据
val deduplicatedDF = df.dropDuplicates()
特征工程
特征工程是将原始数据转换为适合模型训练的特征的过程。常见的特征工程包括特征提取、特征选择和特征转换等。
特征提取
使用 VectorAssembler 将多个列组合成一个特征向量:
import org.apache.spark.ml.feature.VectorAssembler
val assembler = new VectorAssembler()
.setInputCols(Array("column1", "column2", "column3"))
.setOutputCol("features")
val featureDF = assembler.transform(df)
特征选择
使用 ChiSqSelector 进行特征选择:
import org.apache.spark.ml.feature.ChiSqSelector
val selector = new ChiSqSelector()
.setNumTopFeatures(50)
.setFeaturesCol("features")
.setLabelCol("label")
.setOutputCol("selectedFeatures")
val selectedDF = selector.fit(featureDF).transform(featureDF)
特征转换
使用 StandardScaler 进行特征标准化:
import org.apache.spark.ml.feature.StandardScaler
val scaler = new StandardScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
.setWithStd(true)
.setWithMean(false)
val scaledDF = scaler.fit(featureDF).transform(featureDF)
常见算法与应用场景
Spark MLlib 提供了多种常见的机器学习算法,适用于不同的应用场景。以下是一些常见算法及其应用场景的详细介绍。
线性回归
线性回归用于预测数值型目标变量。常见应用场景包括房价预测、销售额预测等。
示例代码
import org.apache.spark.ml.regression.LinearRegression
val lr = new LinearRegression()
.setLabelCol("label")
.setFeaturesCol("features")
val lrModel = lr.fit(trainingData)
val predictions = lrModel.transform(testData)
逻辑回归
逻辑回归用于二分类问题。常见应用场景包括垃圾邮件检测、信用卡欺诈检测等。
示例代码
import org.apache.spark.ml.classification.LogisticRegression
val lr = new LogisticRegression()
.setLabelCol("label")
.setFeaturesCol("features")
val lrModel = lr.fit(trainingData)
val predictions = lrModel.transform(testData)
决策树
决策树用于分类和回归任务。常见应用场景包括风险评估、疾病诊断等。
示例代码
import org.apache.spark.ml.classification.DecisionTreeClassifier
val dt = new DecisionTreeClassifier()
.setLabelCol("label")
.setFeaturesCol("features")
val dtModel = dt.fit(trainingData)
val predictions = dtModel.transform(testData)
随机森林
随机森林是多个决策树的集成,用于分类和回归任务。常见应用场景包括特征重要性评估、复杂分类任务等。
示例代码
import org.apache.spark.ml.classification.RandomForestClassifier
val rf = new RandomForestClassifier()
.setLabelCol("label")
.setFeaturesCol("features")
val rfModel = rf.fit(trainingData)
val predictions = rfModel.transform(testData)
支持向量机
支持向量机(SVM)用于分类任务,特别是二分类问题。常见应用场景包括图像分类、文本分类等。
示例代码
import org.apache.spark.ml.classification.LinearSVC
val lsvc = new LinearSVC()
.setLabelCol("label")
.setFeaturesCol("features")
val lsvcModel = lsvc.fit(trainingData)
val predictions = lsvcModel.transform(testData)
聚类算法
聚类算法用于将数据对象分组,使得同一组内的对象彼此相似,而不同组的对象差异较大。常见的聚类算法包括 K 均值(K-Means)和高斯混合模型(GMM)。
K-Means 聚类
K-Means 是一种常用的聚类算法,适用于客户分群、图像分割等场景。
示例代码
import org.apache.spark.ml.clustering.KMeans
val kmeans = new KMeans()
.setK(3) // 设置簇的数量
.setFeaturesCol("features")
val model = kmeans.fit(data)
val predictions = model.transform(data)
高斯混合模型(GMM)
GMM 是一种软聚类算法,适用于数据具有多峰分布的场景。
示例代码
import org.apache.spark.ml.clustering.GaussianMixture
val gmm = new GaussianMixture()
.setK(3) // 设置簇的数量
.setFeaturesCol("features")
val model = gmm.fit(data)
val predictions = model.transform(data)
推荐系统
推荐系统用于根据用户的历史行为推荐可能感兴趣的物品。Spark MLlib 提供了基于矩阵分解的协同过滤算法,适用于电影推荐、商品推荐等场景。
示例代码
import org.apache.spark.ml.recommendation.ALS
val als = new ALS()
.setUserCol("userId")
.setItemCol("itemId")
.setRatingCol("rating")
val model = als.fit(trainingData)
val predictions = model.transform(testData)
数据预处理
数据预处理是机器学习过程中非常关键的一步,它包括数据清洗、特征工程、数据转换等操作。
数据清洗
数据清洗包括处理缺失值、去除重复数据和处理异常值。
示例代码
// 删除包含缺失值的行
val cleanedDF = df.na.drop()
// 填充缺失值
val filledDF = df.na.fill(Map("column1" -> 0, "column2" -> "unknown"))
// 去除重复数据
val deduplicatedDF = df.dropDuplicates()
特征工程
特征工程是将原始数据转换为适合模型训练的特征的过程,包括特征提取、特征选择和特征转换等。
特征提取
使用 VectorAssembler 将多个列组合成一个特征向量:
import org.apache.spark.ml.feature.VectorAssembler
val assembler = new VectorAssembler()
.setInputCols(Array("column1", "column2", "column3"))
.setOutputCol("features")
val featureDF = assembler.transform(df)
特征选择
使用 ChiSqSelector 进行特征选择:
import org.apache.spark.ml.feature.ChiSqSelector
val selector = new ChiSqSelector()
.setNumTopFeatures(50)
.setFeaturesCol("features")
.setLabelCol("label")
.setOutputCol("selectedFeatures")
val selectedDF = selector.fit(featureDF).transform(featureDF)
特征转换
使用 StandardScaler 进行特征标准化:
import org.apache.spark.ml.feature.StandardScaler
val scaler = new StandardScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
.setWithStd(true)
.setWithMean(false)
val scaledDF = scaler.fit(featureDF).transform(featureDF)
模型训练与评估
模型训练与评估是机器学习的核心部分。在这一步,我们使用预处理后的数据训练模型,并评估模型的性能。
训练模型
使用选择的算法和预处理后的数据进行模型训练。
示例代码
import org.apache.spark.ml.classification.LogisticRegression
val lr = new LogisticRegression()
.setLabelCol("label")
.setFeaturesCol("features")
val lrModel = lr.fit(trainingData)
模型评估
使用不同的评估指标评估模型的性能,如准确度、精确率、召回率和 F1 分数等。
示例代码
import org.apache.spark.ml.evaluation```scala
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictions)
println(s"Test set accuracy = $accuracy")
对于回归模型,可以使用均方误差(MSE)、均方根误差(RMSE)等评估指标:
import org.apache.spark.ml.evaluation.RegressionEvaluator
val evaluator = new RegressionEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("rmse")
val rmse = evaluator.evaluate(predictions)
println(s"Root Mean Squared Error (RMSE) on test data = $rmse")
模型保存与加载
在训练和评估模型后,可以将模型保存到磁盘,以便后续使用。Spark 提供了简单的 API 用于模型的保存和加载。
保存模型
lrModel.save("path/to/save/model")
加载模型
import org.apache.spark.ml.classification.LogisticRegressionModel
val loadedModel = LogisticRegressionModel.load("path/to/save/model")
案例分析
为了更好地理解 Spark MLlib 的使用,我们将通过两个具体案例来展示其应用:房价预测和电影推荐系统。
房价预测
房价预测是一个典型的回归问题。我们将使用线性回归模型来预测房价。
数据准备
假设我们有一个包含房屋特征和价格的数据集。
val data = spark.read
.option("header", "true")
.option("inferSchema", "true")
.csv("path/to/housing.csv")
特征工程
将多个特征列组合成一个特征向量。
import org.apache.spark.ml.feature.VectorAssembler
val assembler = new VectorAssembler()
.setInputCols(Array("size", "bedrooms", "bathrooms"))
.setOutputCol("features")
val featureDF = assembler.transform(data)
训练模型
使用线性回归模型进行训练。
import org.apache.spark.ml.regression.LinearRegression
val lr = new LinearRegression()
.setLabelCol("price")
.setFeaturesCol("features")
val Array(trainingData, testData) = featureDF.randomSplit(Array(0.8, 0.2))
val lrModel = lr.fit(trainingData)
评估模型
val predictions = lrModel.transform(testData)
val evaluator = new RegressionEvaluator()
.setLabelCol("price")
.setPredictionCol("prediction")
.setMetricName("rmse")
val rmse = evaluator.evaluate(predictions)
println(s"Root Mean Squared Error (RMSE) on test data = $rmse")
电影推荐系统
电影推荐系统是一个典型的协同过滤问题。我们将使用交替最小二乘法(ALS)进行推荐。
数据准备
假设我们有一个包含用户、电影和评分的数据集。
val ratings = spark.read
.option("header", "true")
.option("inferSchema", "true")
.csv("path/to/ratings.csv")
训练模型
使用 ALS 进行模型训练。
import org.apache.spark.ml.recommendation.ALS
val als = new ALS()
.setUserCol("userId")
.setItemCol("movieId")
.setRatingCol("rating")
val Array(trainingData, testData) = ratings.randomSplit(Array(0.8, 0.2))
val model = als.fit(trainingData)
评估模型
val predictions = model.transform(testData)
val evaluator = new RegressionEvaluator()
.setMetricName("rmse")
.setLabelCol("rating")
.setPredictionCol("prediction")
val rmse = evaluator.evaluate(predictions)
println(s"Root-mean-square error = $rmse")
生成推荐
为特定用户生成推荐列表。
val userRecs = model.recommendForAllUsers(10)
userRecs.show()
祝福大家都快些学会这些spark MLlib
希望通过本教程,读者能够掌握 Spark MLlib 的基本用法,并能够在自己的项目中应用这些知识






![[AIGC] Springboot 自动配置的作用及理由](https://img-blog.csdnimg.cn/direct/9963aacd73a2401eb84074152efb4ff0.png)