在人工智能领域,大型语言模型(LLMs)的长序列生成能力一直是研究的热点。然而,随着模型规模的增长,推理过程中的内存和计算瓶颈成为了限制其应用的主要障碍。为了解决这一问题,Carnegie Mellon University和Meta AI (FAIR)的研究团队联合推出了TriForce,一种创新的分层推测解码系统。TriForce通过利用注意力稀疏性和上下文局部性,有效地缓解了关键的键值(KV)缓存和模型权重瓶颈,实现了对长序列生成的无损加速。在A100 GPU上,TriForce为Llama2-7B-128K模型带来了高达2.31倍的推理速度提升,在RTX 4090 GPU上更是达到了惊人的7.78倍加速,显著减少了生成每个token所需的时间。而且TriForce在处理大型批量数据时也展现了出色的性能,在实际应用中有着高效性和可扩展性。
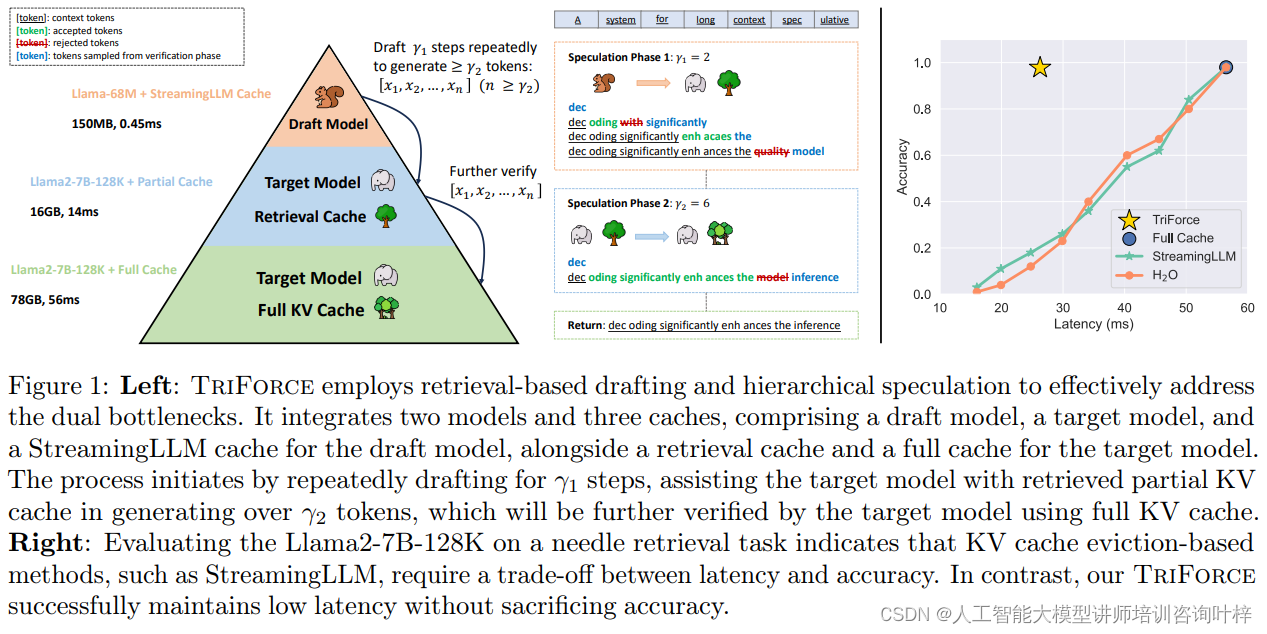
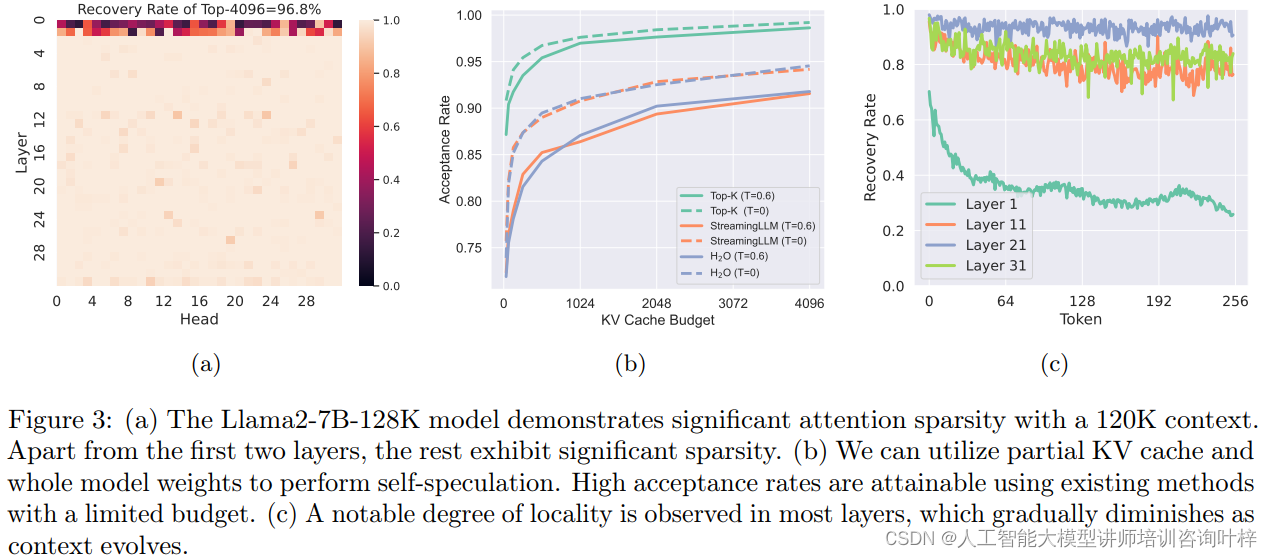
TriForce的设计深受对大模型(LLMs)处理长上下文时注意力机制的观察所启发。研究揭示了一个关键的现象:在预训练的LLMs中,即使面对长达120K的上下文,通过仅使用4K的token,就能恢复超过96%的注意力得分。这一发现表明,LLMs在处理长序列时,其注意力分布呈现出显著的稀疏性。注意力稀疏性的发现对于TriForce来说至关重要,因为它意味着在进行推测解码时,可以只利用一小部分关键信息,而不必加载整个KV缓存。
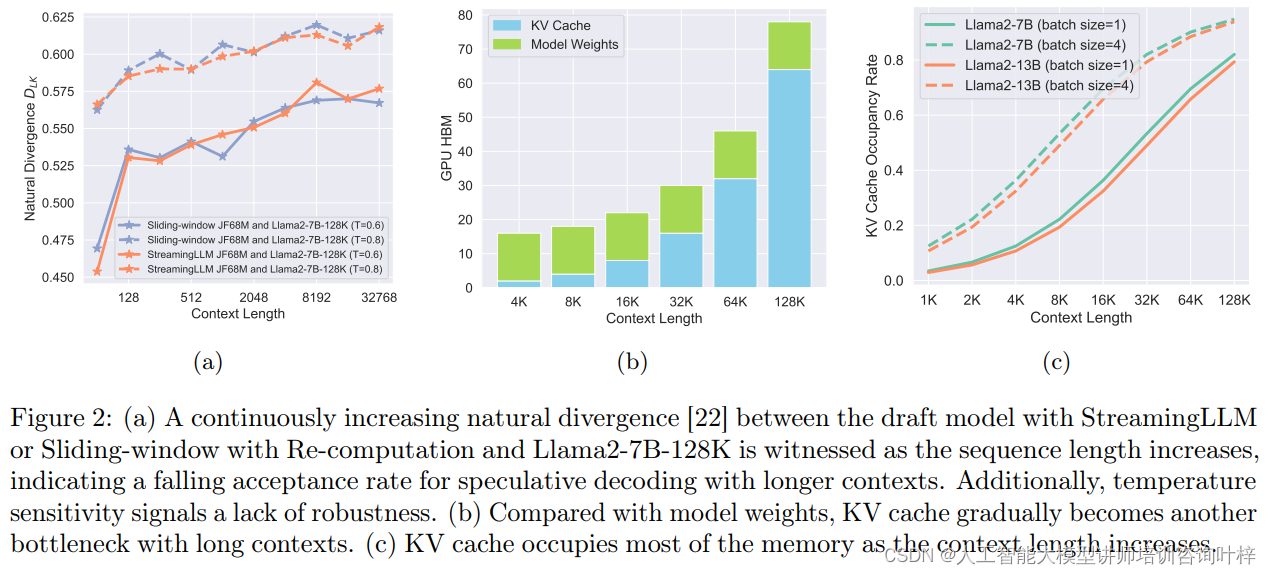
另一个关键的观察是上下文局部性。这一概念指出,相邻的token在长上下文中往往需要相似的信息。也就是说,对于任何给定的token,与其相关的信息在上下文中往往集中在一个局部区域内。这种局部性允许TriForce在多个解码步骤中重用特定的缓存段,而不是每次都重新构建整个缓存。通过这种方式,TriForce能够显著提高解码效率,同时保持对上下文的敏感度。
这两个观察结果为TriForce提供了坚实的理论基础,使其能够通过智能地选择和重用信息来优化长序列生成过程,从而在保持生成质量的同时,显著提高推理速度。
TriForce: 创新的分层推测解码系统
TriForce系统的核心在于其创新的检索式草稿方法。这种方法通过将KV缓存分割成小块,并计算给定查询与每个块中平均key缓存的注意力,有效地识别和选择最相关的信息。这一策略不仅直观,而且无损,与现有的基于逐出策略的方法相比,如StreamingLLM和H2O,它在保持低延迟的同时,能够更准确地检索详细的上下文信息。
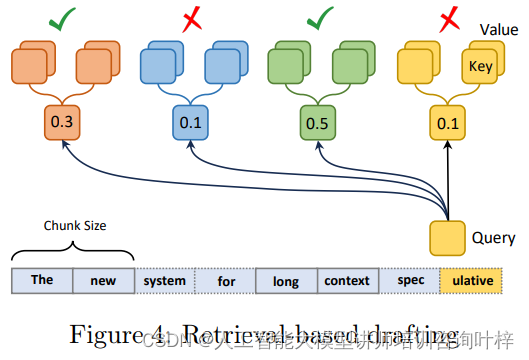
为了应对KV缓存瓶颈之外的模型权重瓶颈,TriForce采用了分层推测架构。这一架构首先使用一个轻量级模型,配备StreamingLLM缓存,对目标模型进行初步推测。这种分层的方法显著降低了草稿阶段的延迟,从而加速了整个推理过程。
TriForce的算法伪代码进一步阐释了其工作流程。系统首先初始化目标模型和草稿模型,然后构建检索缓存,并根据上下文局部性的洞察进行更新。在每次迭代中,草稿模型首先预测一定步数的token,然后目标模型使用完整的KV缓存进行自我验证。这个过程不仅构建了一个效率层级,还通过两个瓶颈的有效管理,提高了整体的推理速度。

以下是一个简化的伪代码示例,概述TriForce算法的主要步骤和结构:
# 输入参数:
# Prefix: 输入前缀序列 [x1,...,xt]
# Mp: 目标模型与完整缓存 Cp
# Mq: 草稿模型与StreamingLLM缓存 Cq
# T: 目标序列长度
# γ1, γ2: 推测长度参数
# Draft: 自回归草稿阶段
# Verify: 验证阶段
# Correct: 校正阶段
# 初始化阶段
Initialize(Prefix, Mp, Mq, T)
Prefill(Mp, C_p, Prefix)
Prefill(Mq, C_q, Prefix)
Construct(Cr, Prefix[-1])
# 迭代推断,直到达到目标序列长度 T
while N < T:
# 草稿模型推测阶段
for i in 1 to γ1:
qi = Draft(Mq, Cq, x≤N)
# 采样与验证阶段
for i in 1 to γ1:
~xi ~ qi
p_hat = Mp(Cr, x≤N, ~x≤i)
if Verify(~xi, qi, p_hat):
n += 1
else:
xi = Correct(qi, p_hat)
n += 1
break
# 如果所有推测的token都被接受,则采样下一个token
if all tokens accepted:
xn+1 ~ p_hat
N += 1
# 更新缓存
Update(Cr, Cq, accepted tokens)
# 返回生成的序列
return Generated_Sequence系统实现采用了Transformer架构,并利用PyTorch CUDA图形和FlashAttention技术来最小化推测解码期间的内核启动开销,并加速注意力操作。为了保持在固定的KV缓存预算内,系统实现了额外的推测缓存结构,包括检索缓存和StreamingLLM缓存。
实验
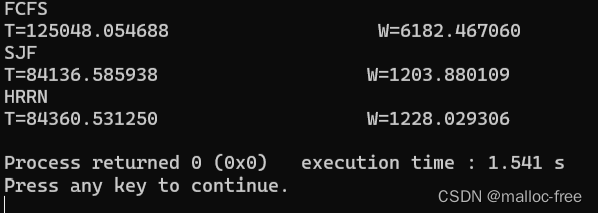
在实证评估部分,研究团队展示了TriForce在不同硬件配置下对长序列生成的加速能力。实验结果表明,在A100 GPU上,TriForce为Llama2-7B-128K模型实现了高达2.31倍的速度提升。而在两个RTX 4090 GPU上,通过卸载设置,TriForce实现了7.78倍的速度提升,将每个token的生成时间降至0.108秒,仅是A100 GPU上自回归基线的一半。
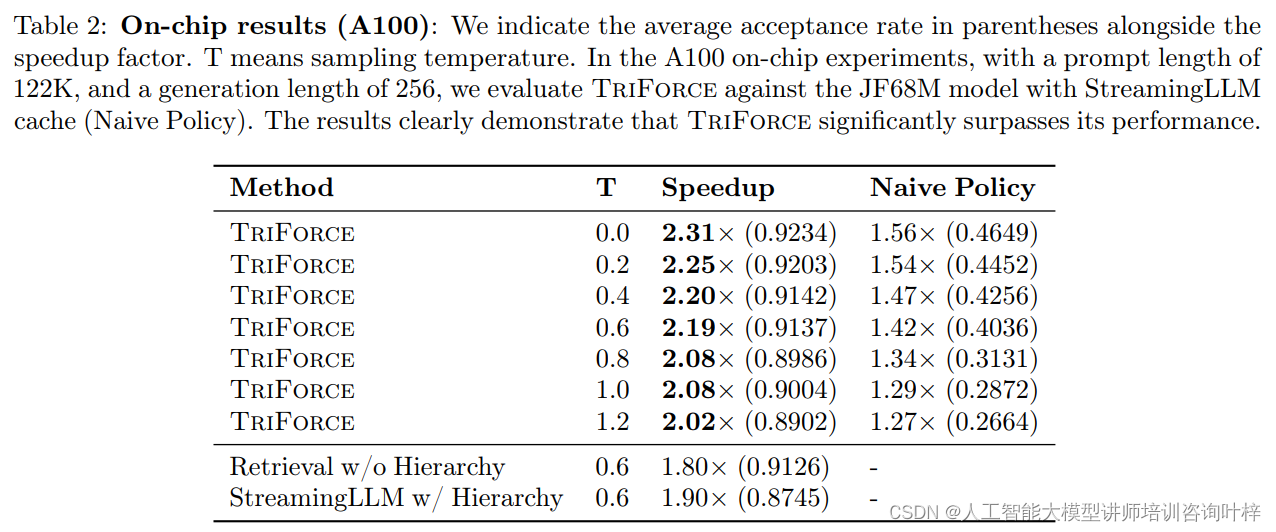
除了速度提升,TriForce在处理更长上下文和不同温度设置下也展现了出色的扩展性和稳健性。实验数据显示,随着上下文长度的增加,TriForce能够保持高接受率,理论上甚至可以达到13.1倍的速度提升。即使在温度参数设置为1.0的情况下,TriForce的接受率仍然能够保持在0.9以上,显示了其在不同条件下的稳定性和可靠性。TriForce在处理大批量数据时同样表现出色,实验结果显示,在批量大小为六的情况下,每个样本包含19K上下文,TriForce能够实现1.9倍的效率提升。
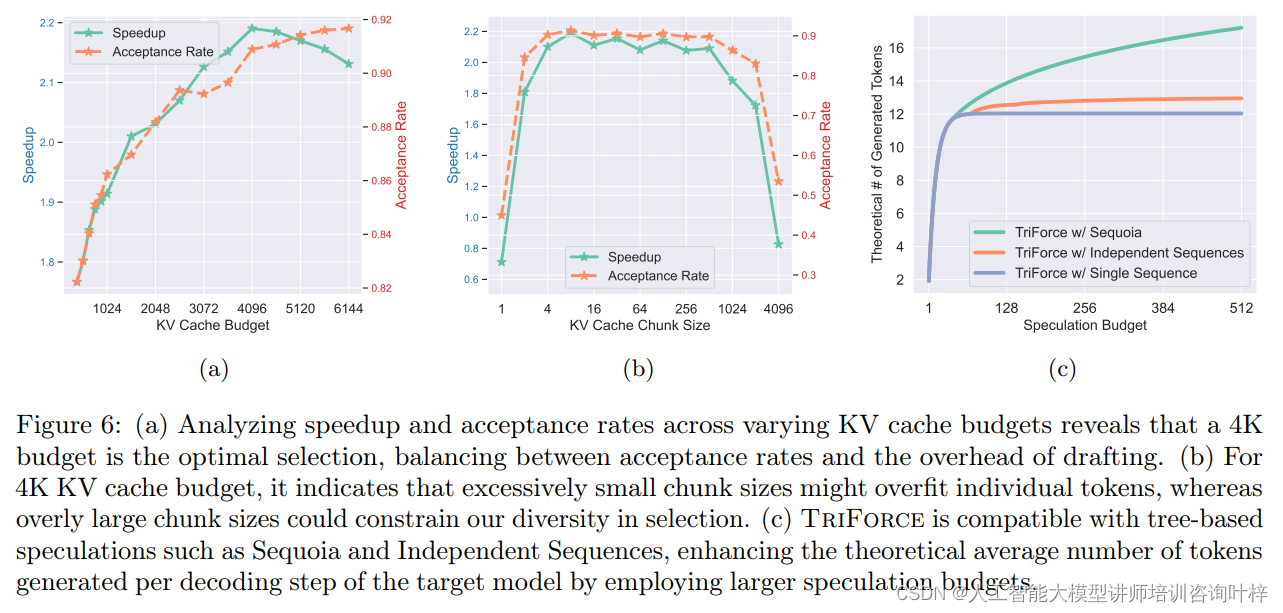
图6(a)展示了不同KV缓存预算对加速比和接受率的影响。实验结果揭示了一个重要发现:当KV缓存预算设置为4K时,可以在保持高接受率的同时,平衡草稿阶段的开销。这意味着,4K缓存预算是最优选择,它在加速模型推理和维持解码质量之间找到了一个平衡点。增加缓存预算超过4K,虽然可能进一步提高接受率,但对整体性能的提升贡献有限,反而可能增加计算和内存的负担。
(b) KV缓存块大小的选择
图6(b)探讨了在给定4K缓存预算下,KV缓存块大小对性能的影响。结果表明,过小的块大小可能导致过度拟合个别token,损害了对未来token的泛化能力。相反,过大的块大小可能会使高得分token的重要性被周围低得分token所抵消,从而限制了在有限缓存预算下的选择多样性。因此,选择合适的块大小对于实现高效的缓存利用和保持解码步骤的多样性至关重要。
(c) 与基于树的推测解码的兼容性
图6(c)说明了TriForce与基于树的推测解码方法(如Sequoia和Independent Sequences)的兼容性。这些方法通过使用多个候选来提高接受率让更多的token被接受。当TriForce与这些树状结构结合时,可以利用更大的推测预算,提高目标模型每个解码步骤生成的理论平均token数量。这表明TriForce不仅可以独立提高性能,还可以与其他先进的推测技术相结合,进一步提升LLMs的推理效率。
研究团队还进行了详细的分析和消融研究,以确定KV缓存预算和块大小对系统性能的影响。实验结果表明,4K的KV缓存预算是最有效的设置,能够平衡高接受率和减少额外草稿开销之间的关系。同时,对于4K的KV缓存预算,选择适当的块大小对于性能至关重要,过小或过大的块大小都可能影响性能。
TriForce通过利用注意力稀疏性和上下文局部性,有效地缓解了KV缓存和模型权重的双重瓶颈,显著提高了长上下文服务的效率。其在不同硬件配置上的实验结果证明了TriForce在加速长序列生成方面的潜力,有望为长上下文模型的服务带来革命性的变革。
论文链接:https://arxiv.org/abs/2404.11912
GitHub 地址:https://github.com/Infini-AI-Lab/TriForce
![[数据集][目标检测]盲道检测数据集VOC+YOLO格式2173张1类别](https://img-blog.csdnimg.cn/direct/dd05ea22da294ac8ab783094defe5cef.png)