前言
爬取 雪球网的股票数据
[环境使用]:
python 3.12 解释器
pycharm 编辑器
【模块使用】:
import requests -->数据请求模块 要安装 命令 pip install requests
import csv -->将数据保存到CSV表格中
import pandas -->也可以将数据保存到Excel表格文件中 也要安装 pip install pandas
爬虫实现流程:<基本公式 可以套用>
一、数据来源分析
1.明确需求:明确采集的网站以及数据内容
-网址:雪球网
-数据:股票数据
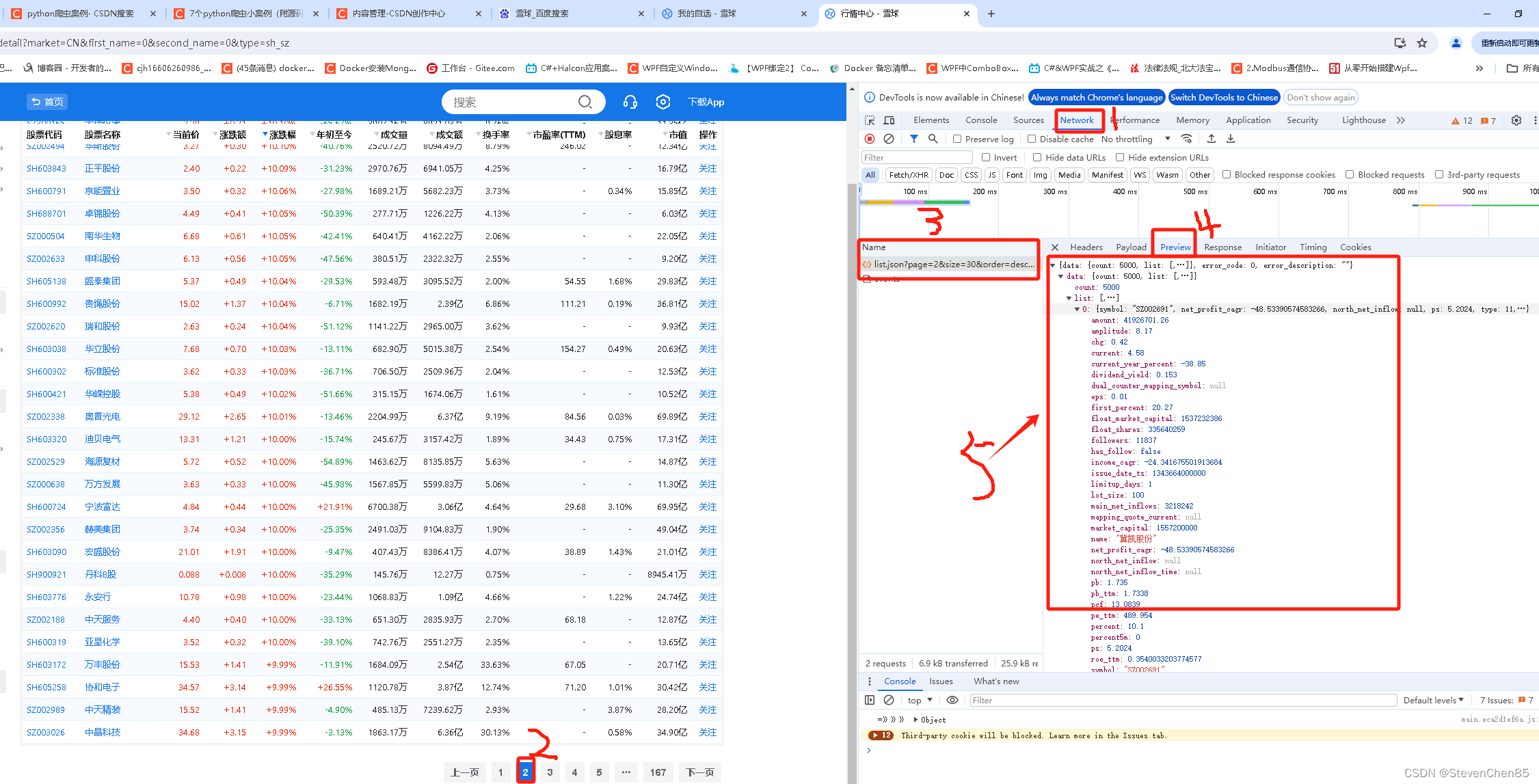
2.抓包分析:分析 股票数据,可以请求哪个网址能够得到数据
-打开 开发者工具:F12 / 右键 点击检查选择 network (网络)
-点击第二页数据
--数据真实地址:https://stock.xueqiu.com/v5/stock/screener/quote/list.json?page=2&size=30&order=desc&order_by=percent&market=CN&type=sh_sz
https://stock.xueqiu.com/v5/stock/screener/quote/list.json?page=3&size=30&order=desc&order_by=percent&market=CN&type=sh_sz
--请求网址:
--请求方式:
--请求头:
二、代码实现步骤
1、发送请求 ->模拟浏览器对于url发送请求
2.获取数据 ->获取服务器返回响应数据《整个数据》
3.解析数据 ->提取我们需要的数据
4.保存数据 ->保存表格文件<csv / Excel> 中
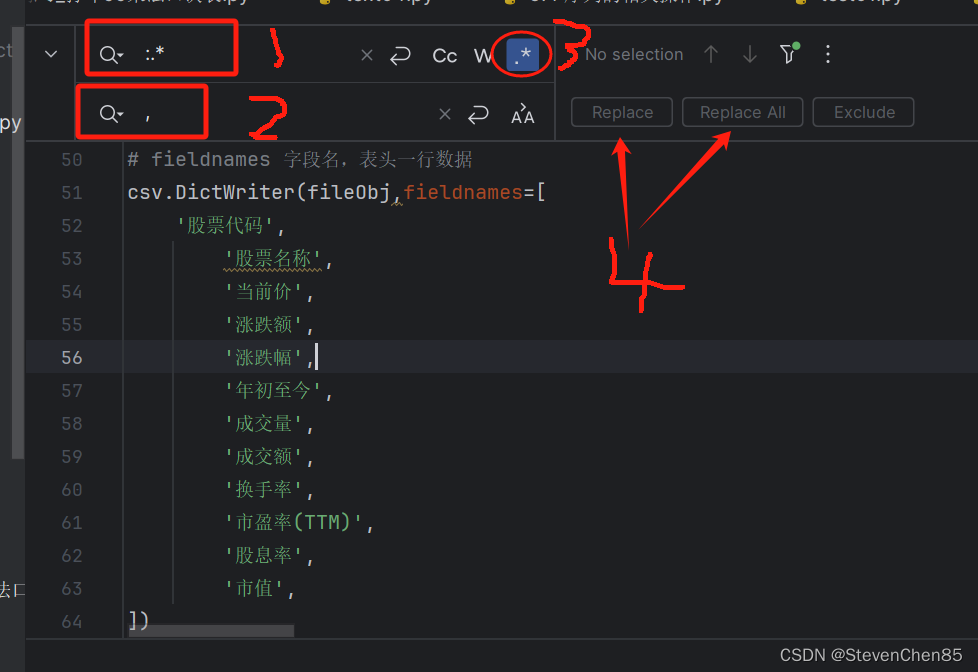
排量替换方法:
1.选择替换的内容
2.Ctrl + R
3.输入正则命令进行需要替换的内容
:.* ->匹配 : 冒号后的所有内容 , (.*?): ->匹配加引号 (.*) ->匹配加引号,逗号
, ->替换成 逗号 '$1': '$2',
4. 点 .* 按钮,最后点 Replace 或 Replace All 按钮 进行替换
1.效果
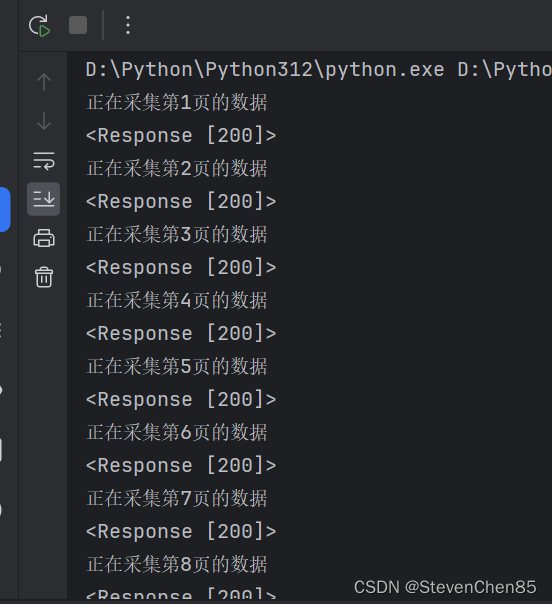
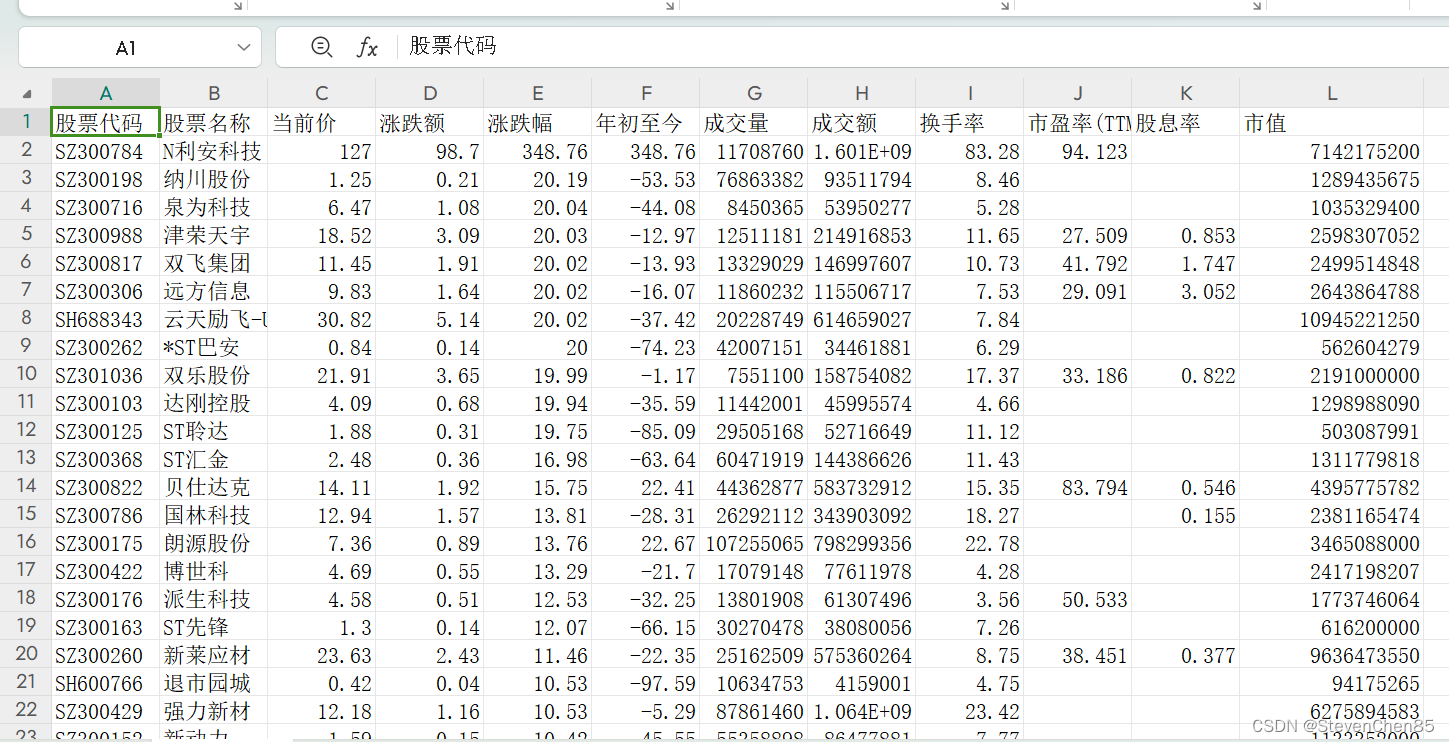
2.代码
'''
爬取 雪球网的股票数据
[环境使用]:
python 3.12 解释器
pycharm 编辑器
【模块使用】:
import requests -->数据请求模块 要安装 命令 pip install requests
import csv -->将数据保存到CSV表格中
import pandas -->也可以将数据保存到Excel表格文件中 也要安装 pip install pandas
爬虫实现流程:<基本公式 可以套用>
一、数据来源分析
1.明确需求:明确采集的网站以及数据内容
-网址:雪球网
-数据:股票数据
2.抓包分析:分析 股票数据,可以请求哪个网址能够得到数据
-打开 开发者工具:F12 / 右键 点击检查选择 network (网络)
-点击第二页数据
--数据真实地址:https://stock.xueqiu.com/v5/stock/screener/quote/list.json?page=2&size=30&order=desc&order_by=percent&market=CN&type=sh_sz
https://stock.xueqiu.com/v5/stock/screener/quote/list.json?page=3&size=30&order=desc&order_by=percent&market=CN&type=sh_sz
--请求网址:
--请求方式:
--请求头:
二、代码实现步骤
1、发送请求 ->模拟浏览器对于url发送请求
2.获取数据 ->获取服务器返回响应数据《整个数据》
3.解析数据 ->提取我们需要的数据
4.保存数据 ->保存表格文件<csv / Excel> 中
排量替换方法:
1.选择替换的内容
2.Ctrl + R
3.输入正则命令进行需要替换的内容
:.* ->匹配 : 冒号后的所有内容 , (.*?): ->匹配加引号 (.*) ->匹配加引号,逗号
, ->替换成 逗号 '$1': '$2',
4. 点 .* 按钮,最后点 Replace 或 Replace All 按钮 进行替换
'''
#导入数据请求模块<需要安装 命令 pip install requests>
import requests
# 导入格式化输出模块
from pprint import pprint
"""
保存数据,保存到表格文件
1.CSV - CSV 模块
2.Excel
"""
# 导入 CSV 模块
import csv
# 导入pandas 模块 <需要安装> 保存Excel文件
import pandas as pd
# 第4步 保存数据
# 4.1 创建文件对象
fileObj = open('雪球股票数据.CSV', mode='w', encoding='utf-8', newline='')
# 4.1 fieldnames 字段名,表头一行数据
csv_writer = csv.DictWriter(fileObj,fieldnames=[
'股票代码',
'股票名称',
'当前价',
'涨跌额',
'涨跌幅',
'年初至今',
'成交量',
'成交额',
'换手率',
'市盈率(TTM)',
'股息率',
'市值',
])
# 4.1 写入表头
csv_writer.writeheader()
# 4.2 保存数据到Excel文件
# 4.2.1 创建一个空列表
content_list = []
"""
第1步 :发送请求 -> 模拟浏览器对于url发送请求
-模拟浏览器:headers 请求头
从浏览器开发者工具中直接复制
headers 是字典数据类型,键/值对形式
-请求网址
-发送请求:
需要requests 模块 -> pip install requests
"""
# 1.模拟浏览器
headers = {
'Cookie' : 'cookiesu=901717811205751; Hm_lvt_1db88642e346389874251b5a1eded6e3=1717811218; device_id=fa5d0fc904c2d239c37239660f3f81e9; xq_a_token=ce05ae9ba331f0a4ebcd99207febf59b0b071ba8; xqat=ce05ae9ba331f0a4ebcd99207febf59b0b071ba8; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOjczMjE3OTE1NjAsImlzcyI6InVjIiwiZXhwIjoxNzIwNDA0NjYxLCJjdG0iOjE3MTc4MTI2NjE1OTIsImNpZCI6ImQ5ZDBuNEFadXAifQ.SeDDdnuih-A6rqJn7Nx2j_8XXDhUnp0SXp-XDTcC3klFq-CBfl2tyGepSoqx94gKV_Wp-amu00Wq1_rQ4Am6KISJlO1AB0Vk4E5d03E_DcC_jyFy-4mm25urTeN2h95JSmPoihAz4NjtddS8fkce8EQAE0ZS3BUFysm_G44_il_fAEiDApf2Mo2_BpBarLiffvGOMR5aV_kzpAipph_7DcMC0DMUuZFPp3F-LimBkrLxczVt8lda6Nf9UGDfn4QDrNJidrFZUcfJ3CGruVDty3HdgwsNrpcmSXE1OsseZPwsj_CzWoNBXULskr1D_VnxnqWPtjiOWhuMaAASAQGKoQ; xq_r_token=cc0f33963313bf4d82d1ec9471ab59f91b15e828; xq_is_login=1; u=7321791560; snbim_minify=true; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1717812883',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
# 多页采集
for page in range(1,168):
print(f'正在采集第{page}页的数据')
# 2.请求网址
url = f'https://stock.xueqiu.com/v5/stock/screener/quote/list.json?page={page}&size=30&order=desc&order_by=percent&market=CN&type=sh_sz'
# 3.发送请求
response = requests.get(url=url,headers=headers)
print(response)
# 返回 <Response [200]> 表示发送请求成功
"""
第2步:获取数据
获取数据 ->获取服务器返回响应数据<整个数据>
-response.test() 获取响应文本数据
-response.json() 获取响应json数据
-response.content() 获取响应二进制数据(保存图片、视频、音频、特定模式文件的时候使用)
第3步:解析数据 ->提取我们需要的数据
解决数据方法根据获取数据来选择的:
字典取值方法 -> 键值对取值(根据冒号左边的内容[键],提取冒号右边的内容【值】)
"""
json_data = response.json()
# print(json_data)
# print(json_data['data']['list'])
# 第3步:解析数据 ->提取我们需要的数据
for row in json_data['data']['list']:
# print(row)
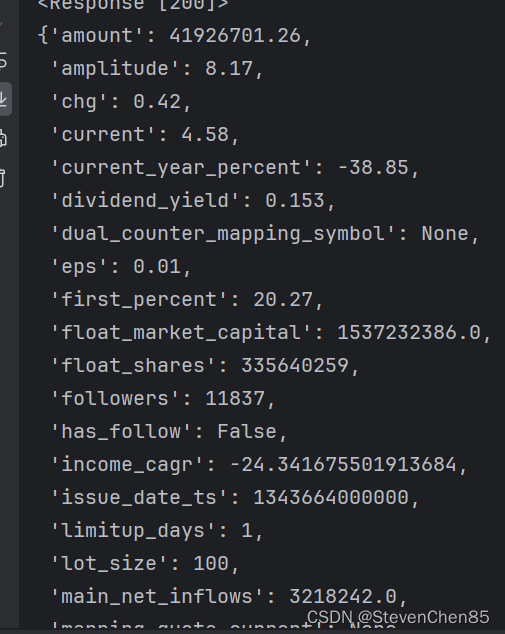
# pprint(row)#格式化输出数据
# break
# 提取数据保存到字典里面,方便后面保存到表格中
dit = {
'股票代码':row['symbol'],
'股票名称': row['name'],
'当前价': row['current'],
'涨跌额': row['chg'],
'涨跌幅': row['percent'],
'年初至今': row['current_year_percent'],
'成交量': row['volume'],
'成交额': row['amount'],
'换手率': row['turnover_rate'],
'市盈率(TTM)': row['pe_ttm'],
'股息率': row['dividend_yield'],
'市值': row['market_capital'],
}
# 保存数据
csv_writer.writerow(dit)
# 4.2.2 将数据添加到空列表中
# content_list.append(dit)
# print(dit)
# 4.2.3 格式化数据
# data = pd.DataFrame(content_list)
# print(f'data:{data}')
# 4.2.4 将数据写入文件
# data.to_excel('雪球股票.xlsx',index=False)码字不容易,看完请大家一键三连。谢谢
收集一下需求,有人想爬电影数据吗?想的欢迎在评论区留言。
小彩蛋:
1.安装第三方模块
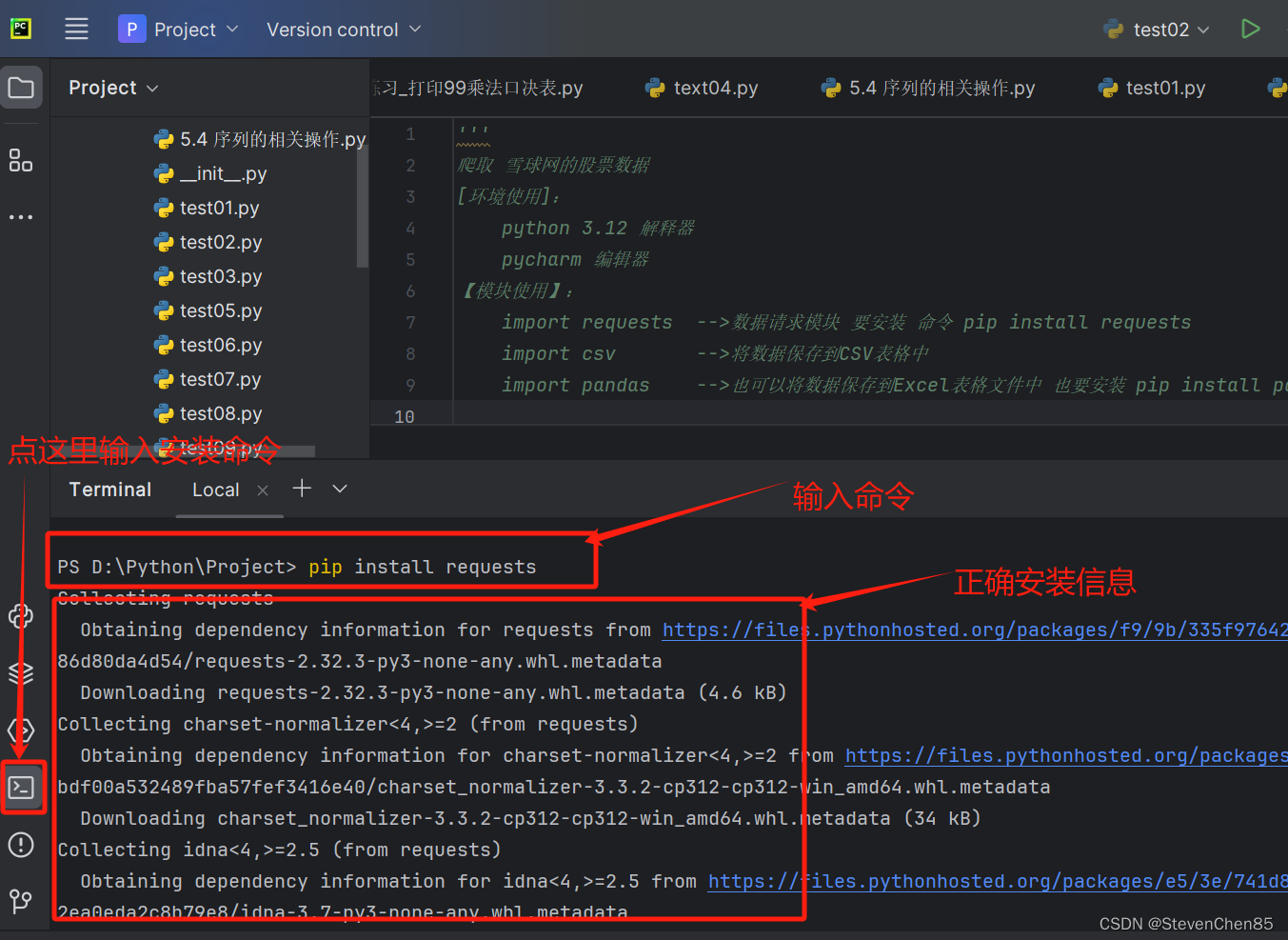
2.格式化数据,
# pprint(row)#格式化输出数据 的效果
3.批量替换小技巧
排量替换方法:
1.选择替换的内容
2.Ctrl + R
3.输入正则命令进行需要替换的内容
:.* ->匹配 : 冒号后的所有内容 , (.*?): ->匹配加引号 (.*) ->匹配加引号,逗号
, ->替换成 逗号 '$1': '$2',
4. 点 .* 按钮,最后点 Replace 或 Replace All 按钮 进行替换
4.F12开发者工具的使用
码字不容易,看完请大家一键三连。谢谢