😄 19年之后由于某些原因断更了三年,23年重新扬帆起航,推出更多优质博文,希望大家多多支持~
🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志
🎐 个人CSND主页——Micro麦可乐的博客
🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战
🌺《RabbitMQ》本专栏主要介绍使用JAVA开发RabbitMQ的系列教程,从基础知识到项目实战
🌸《设计模式》专栏以实际的生活场景为案例进行讲解,让大家对设计模式有一个更清晰的理解
💕《Jenkins实战》专栏主要介绍Jenkins+Docker+Git+Maven的实战教程,让你快速掌握项目CI/CD,是2024年最新的实战教程
如果文章能够给大家带来一定的帮助!欢迎关注、评论互动~
Spring Boot 使用自定义注解和自定义线程池实现异步日志记录
- 1、前言
- 2、异步日志记录的重要性
- 2.1 提高性能
- 2.2 减少延迟
- 2.3 提升稳定性
- 2.4 资源管理优化
- 3、开始构建
- 3.1 创建 Spring Boot 项目
- 3.2 创建自定义注解类
- 3.3 配置自定义线程池
- 3.4 编写日志记录切面
- 3.5 编写Controller中使用@LogAsync
- 4、接口测试
- 5、结语
1、前言
在我们日常开发工作中,日志记录是至关重要的部分。它不仅有助于调试和故障排除,还能提供系统运行的历史记录,帮助进行性能优化和安全监控。然而,日志记录也可能对系统性能产生影响,特别是在高并发环境下。因此,使用异步日志记录技术可以有效地提升系统性能和可靠性。
博主将带着大家一起探讨 Spring Boot 异步日志记录的优雅实现方法。
2、异步日志记录的重要性
2.1 提高性能
在传统的同步日志记录方式中,每次日志记录操作都需要等待日志写入完成,才能继续执行后续操作。这种方式在高并发环境下会导致明显的性能瓶颈。异步日志记录通过将日志写入操作放入独立的线程中执行,避免了主线程的阻塞,从而大幅提高了系统的整体性能。
2.2 减少延迟
在需要快速响应的应用程序中,如实时系统或高频交易系统,任何形式的延迟都会影响系统的响应时间。异步日志记录能将日志记录操作从主业务流程中剥离出来,减少了响应时间,提升了用户体验。
2.3 提升稳定性
在高负载情况下,同步日志记录可能会导致系统资源的争用,影响系统的稳定性。异步日志记录通过使用独立的线程池管理日志写入操作,避免了这种资源争用,提高了系统的稳定性和可靠性。
2.4 资源管理优化
异步日志记录允许更灵活地管理系统资源。通过配置线程池的大小和任务队列,可以更好地控制系统资源的使用,避免了因为日志记录过多导致的内存和磁盘 I/O 资源耗尽问题。
3、开始构建
3.1 创建 Spring Boot 项目
可以使用 Spring Initializr 创建项目,确保在 pom.xml 文件中添加了必要的依赖:
<dependencies>
<!-- Spring Boot Starter Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring Boot Starter AOP -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
</dependencies>
3.2 创建自定义注解类
定义一个自定义注解类 LogAsync 用于标记需要异步记录的日志方法,并且系统会记录功能组、操作人、方法名、传递的参数等(仅模拟,大家根据自己项目需求定制)
代码如下:
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface LogAsync {
// 可以根据需要添加属性 比如功能组
String funGroup() default "";
}
3.3 配置自定义线程池
为了优化异步日志记录,我们需要配置一个自定义线程池
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.context.annotation.Bean;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.Executor;
@Configuration
@EnableAsync
public class AsyncConfig{
@Bean(name = "logExecutor")
public Executor logExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setQueueCapacity(100);
executor.setThreadNamePrefix("LogExecutor-");
executor.initialize();
return executor;
}
}
3.4 编写日志记录切面
创建一个AOP切面 LoggingAspect 来处理异步日志记录
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.AfterReturning;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Component;
import java.util.concurrent.Executor;
@Aspect
@Component
@Slf4j
public class LoggingAspect {
private final Executor logExecutor;
public LoggingAspect(@Qualifier("logExecutor") Executor logExecutor) {
this.logExecutor = logExecutor;
}
@Pointcut("@annotation(LogAsync)")
public void loggableMethods() {
}
@AfterReturning(pointcut = "loggableMethods()", returning = "result")
@Async("logExecutor")
public void logMethodCall(JoinPoint joinPoint, Object result) {
//获取注解类
LogAsync logAsync = ((MethodSignature) joinPoint.getSignature()).getMethod().getAnnotation(LogAsync.class);
//获取注解上的功能组
String funGroup = logAsync.funGroup();
//获取方法名
String methodName = joinPoint.getSignature().getName();
//获取参数
Object[] args = joinPoint.getArgs();
//方法返回结果 Object result
log.info("funGroup: {}, Method: {}, Args: {}, Result: {}", funGroup, methodName, args, result);
//TODO 这里可以加入日志入库操作
}
}
3.5 编写Controller中使用@LogAsync
创建一个TestUser类,作为接收参数
import lombok.Data;
@Data
public class TestUser {
private String username;
private String password;
}
创建 LogSampleController ,标注@LogAsync注解
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api")
public class LogSampleController {
/**
* 模拟保存
* @param user 自定义用户类
* @return
*/
@LogAsync(funGroup = "用户模块")
@PostMapping("/save-user")
public ResponseEntity<String> saveUser(@RequestBody TestUser user) {
return new ResponseEntity<>("操作成功", HttpStatus.OK);
}
}
4、接口测试
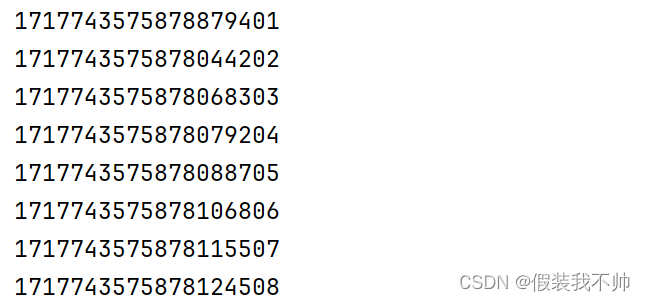
运行 Spring Boot 应用程序,使用测试工具访问 http:/your_host/api/save-user。观察控制台中可以看到异步日志记录的信息

控制台输出:

温馨提示
演示代码中,博主是获取 功能组、方法名、传递的参数、返回结果;
正常我们日志记录还会有很多主要信息,比如:操作人、修改前数据、修改后数据、修改时间等等,大家可以根据自己系统情况进行调整
5、结语
通过自定义注解、Spring AOP 和自定义线程池,我们可以在 Spring Boot 应用中实现高效的异步日志记录。这种方法不仅提高了日志记录的灵活性,还能减小对主业务线程的影响。希望本文对您在实际项目中实现日志记录有所帮助。
这种方式在实际生产环境中非常实用,特别是在需要高效处理大量日志记录的场景下。通过合理配置线程池,可以确保日志记录的性能和稳定性。





![[word] word表格如何设置外框线和内框线 #媒体#笔记](https://img-blog.csdnimg.cn/img_convert/92108c5d428a158d2a9383719d18f792.png)