Scala 练习一 将Mysql表数据导入HBase
续第一篇:Java代码将Mysql表数据导入HBase表
源码仓库地址:https://gitee.com/leaf-domain/data-to-hbase
- 一、整体介绍
- 二、依赖
- 三、测试结果
- 四、源码
一、整体介绍

-
HBase特质连接HBase, 创建HBase执行对象
- 初始化配置信息:多条(hbase.zookeeper.quorum=>ip:2181)
Configuration conf = HBaseConfiguration.create()
conf.set(String, String) - 创建连接:多个连接(池化)
Connection con = ConnectionFactory.createConnection() - 创建数据表:表名: String
Table table = con.getTable(TableName)
def build(): HBase // 初始化配置信息 def initPool(): HBase // 初始化连接池 def finish(): Executor // 完成 返回执行对象 - 初始化配置信息:多条(hbase.zookeeper.quorum=>ip:2181)
-
Executor特质对HBase进行操作的方法: 包含如下函数
def exists(tableName: String): Boolean // 验证数据表是否存在 def create(tableName: String, columnFamilies: Seq[String]): Boolean // 创建数据表 def drop(tableName: String): Boolean // 删除数据表 def put(tableName: String, data: util.List[Put]): Boolean // 批量插入数据 -
Jdbc封装Jdbc封装
- 初始化连接
driver : com.mysql.cj.jdbc.Driver
参数:url, username, password
创建连接 - 初始化执行器
sql, parameters
创建执行器【初始化参数】 - 执行操作并返回【结果】
DML: 返回影响数据库表行数
DQL: 返回查询的数据集合
EX: 出现异常结果
- 初始化连接
-
MyHBase用于实现HBase和Executor特质 -
测试数据格式
mysql表
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; DROP TABLE IF EXISTS `test_table_for_hbase`; CREATE TABLE `test_table_for_hbase` ( `test_id` int NULL DEFAULT NULL, `test_name` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL, `test_age` int NULL DEFAULT NULL, `test_gender` varchar(6) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL, `test_phone` varchar(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic; INSERT INTO `test_table_for_hbase` VALUES (1, 'testName1', 26, 'male', '18011111112'); INSERT INTO `test_table_for_hbase` VALUES (2, 'testName2', 25, 'female', '18011111113'); INSERT INTO `test_table_for_hbase` VALUES (3, 'testName3', 27, 'male', '18011111114'); INSERT INTO `test_table_for_hbase` VALUES (4, 'testName4', 35, 'male', '18011111115'); -- .... 省略以下数据部分hbase表
# 创建表 库名:表名, 列族1, 列族2 create "hbase_test:tranfer_from_mysql","baseInfo","scoreInfo" truncate 'hbase_test:tranfer_from_mysql' # 清空hbase_test命名空间下的tranfer_from_mysql表 scan 'hbase_test:tranfer_from_mysql' # 查看表
二、依赖
<dependencies>
<!-- HBase 驱动 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.3.5</version>
</dependency>
<!-- Hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.1.3</version>
</dependency>
<!-- mysql -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.0.33</version>
</dependency>
<!-- zookeeper -->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.3</version>
</dependency>
</dependencies>
三、测试结果
终端有个日志的小警告(无伤大雅hh),输出为 true
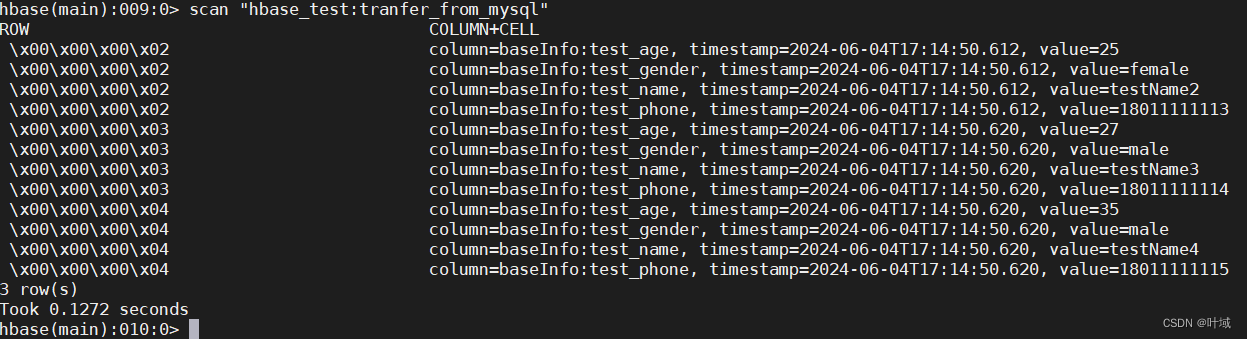
查看hbase表,发现数据正常导入
四、源码
scala代码较简单这里直接上源码了,去除了部分注释,更多请去仓库下载
Executor
package hbase
import org.apache.hadoop.hbase.client.Put
import java.util
trait Executor {
def exists(tableName: String): Boolean
def create(tableName: String, columnFamilies: Seq[String]): Boolean
def drop(tableName: String): Boolean
def put(tableName: String, data: util.List[Put]): Boolean
}
HBase
package hbase
import org.apache.hadoop.hbase.client.Connection
trait HBase {
protected var statusCode: Int = -1
def build(): HBase
case class PoolCon(var available: Boolean, con: Connection) {
def out = {
available = false
this
}
def in = available = true
}
def initPool(): HBase
def finish(): Executor
}
MyHBase
package hbase.impl
import hbase.{Executor, HBase}
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client.{ColumnFamilyDescriptorBuilder, ConnectionFactory, Put, TableDescriptorBuilder}
import org.apache.hadoop.hbase.exceptions.HBaseException
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import java.util
import scala.collection.mutable.ArrayBuffer
class MyHBase (conf: Map[String, String])(pooled: Boolean = false, poolSize: Int = 3) extends HBase{
private lazy val config: Configuration = HBaseConfiguration.create()
private lazy val pool: ArrayBuffer[PoolCon] = ArrayBuffer()
override def build(): HBase = {
if(statusCode == -1){
conf.foreach(t => config.set(t._1, t._2))
statusCode = 0
this
}else{
throw new HBaseException("build() function must be invoked first")
}
}
override def initPool(): HBase = {
if(statusCode == 0){
val POOL_SIZE = if (pooled) {
if (poolSize <= 0) 3 else poolSize
} else 1
for (i <- 1 to POOL_SIZE) {
pool.append(PoolCon(available = true, ConnectionFactory.createConnection(config)))
}
statusCode = 1
this
}else{
throw new HBaseException("initPool() function must be invoked only after build()")
}
}
override def finish(): Executor = {
if (statusCode == 1) {
statusCode = 2
new Executor {
override def exists(tableName: String): Boolean = {
var pc: PoolCon = null
try{
pc = getCon
val exists = pc.con.getAdmin.tableExists(TableName.valueOf(tableName))
pc.in
exists
}catch {
case e: Exception => e.printStackTrace()
false
}finally {
close(pc)
}
}
override def create(tableName: String, columnFamilies: Seq[String]): Boolean = {
if (exists(tableName)) {
return false
}
var pc: PoolCon = null
try {
pc = getCon
val builder: TableDescriptorBuilder = TableDescriptorBuilder
.newBuilder(TableName.valueOf(tableName))
columnFamilies.foreach(
cf => builder.setColumnFamily(
ColumnFamilyDescriptorBuilder.of(cf)
)
)
pc.con.getAdmin.createTable(builder.build())
true
} catch {
case e: Exception => e.printStackTrace()
false
} finally {
close(pc)
}
}
override def drop(tableName: String): Boolean = {
if(!exists(tableName)){
return false
}
var pc: PoolCon = null
try {
pc = getCon
pc.con.getAdmin.deleteTable(TableName.valueOf(tableName))
true
} catch {
case e: Exception => e.printStackTrace()
false
} finally {
close(pc)
}
}
override def put(tableName: String, data: util.List[Put]): Boolean = {
if(!exists(tableName)){
return false
}
var pc: PoolCon = null
try {
pc = getCon
pc.con.getTable(TableName.valueOf(tableName)).put(data)
true
} catch {
case e: Exception => e.printStackTrace()
false
} finally {
close(pc)
}
}
}
}
else {
throw new HBaseException("finish() function must be invoked only after initPool()")
}
}
private def getCon = {
val left: ArrayBuffer[PoolCon] = pool.filter(_.available)
if (left.isEmpty) {
throw new HBaseException("no available connection")
}
left.apply(0).out
}
private def close(con: PoolCon) = {
if (null != con) {
con.in
}
}
}
object MyHBase{
def apply(conf: Map[String, String])(poolSize: Int): MyHBase = new MyHBase(conf)(true, poolSize)
}
Jdbc
package mysql
import java.sql.{Connection, DriverManager, ResultSet, SQLException}
import java.util
object Jdbc {
object Result extends Enumeration {
val EX = Value(0)
val DML = Value(1)
val DQL = Value(2)
}
// 3种结果(异常,DML,DQL)封装
case class ResThree(rst: Result.Value) {
def to[T <: ResThree]: T = this.asInstanceOf[T]
}
class Ex(throwable: Throwable) extends ResThree(Result.EX)
object Ex {
def apply(throwable: Throwable): Ex = new Ex(throwable)
}
class Dml(affectedRows: Int) extends ResThree(Result.DML) {
def update = affectedRows
}
object Dml {
def apply(affectedRows: Int): Dml = new Dml(affectedRows)
}
class Dql(set: ResultSet) extends ResThree(Result.DQL) {
def generate[T](f: ResultSet => T) = {
val list: util.List[T] = new util.ArrayList()
while (set.next()) {
list.add(f(set))
}
list
}
}
object Dql {
def apply(set: ResultSet): Dql = new Dql(set)
}
// JDBC 函数封装
def jdbc(url: String, user: String, password: String)(sql: String, params: Seq[Any] = null): ResThree = {
def con() = {
// 1.1 显式加载 JDBC 驱动程序(只需要一次)
Class.forName("com.mysql.cj.jdbc.Driver")
// 1.2 创建连接对象
DriverManager.getConnection(url, user, password)
}
def pst(con: Connection) = {
// 2.1 创建执行对象
val pst = con.prepareStatement(sql)
// 2.2 初始化 SQL 参数
if (null != params && params.nonEmpty) {
params.zipWithIndex.foreach(t => pst.setObject(t._2 + 1, t._1))
}
pst
}
try {
val connect = con()
val prepared = pst(connect)
sql match {
case sql if sql.matches("^(insert|INSERT|delete|DELETE|update|UPDATE) .*")
=> Dml(prepared.executeUpdate())
case sql if sql.matches("^(select|SELECT) .*")
=> Dql(prepared.executeQuery())
case _ => Ex(new SQLException(s"illegal sql command : $sql"))
}
} catch {
case e: Exception => Ex(e)
}
}
}
Test
import hbase.impl.MyHBase
import mysql.Jdbc._
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.util.Bytes
import java.util
object Test {
def main(args: Array[String]): Unit = {
// 初始化MySQL JDBC操作函数
val jdbcOpr: (String, Seq[Any]) => ResThree = jdbc(
user = "root",
url = "jdbc:mysql://localhost:3306/test_db_for_bigdata",
password = "123456"
)
// 执行SQL查询,并将结果封装在ResThree对象中
val toEntity: ResThree = jdbcOpr(
"select * from test_table_for_hbase where test_id between ? and ?",
Seq(2, 4)
)
// 判断ResThree对象中的结果是否为异常
if (toEntity.rst == Result.EX) {
// 如果异常,执行异常结果处理
toEntity.to[Ex]
println("出现异常结果处理")
} else {
// 如果没有异常,将查询结果转换为HBase的Put对象列表
val puts: util.List[Put] = toEntity.to[Dql].generate(rst => {
// 创建一个Put对象,表示HBase中的一行
val put = new Put(
Bytes.toBytes(rst.getInt("test_id")), // row key设置为test_id
System.currentTimeMillis() // 设置时间戳
)
// 向Put对象中添加列值
// baseInfo是列族名,test_name、test_age、test_gender、test_phone是列名
put.addColumn(
Bytes.toBytes("baseInfo"), Bytes.toBytes("test_name"),
Bytes.toBytes(rst.getString("test_name"))
)
put.addColumn(
Bytes.toBytes("baseInfo"), Bytes.toBytes("test_age"),
Bytes.toBytes(rst.getString("test_age")) // 注意:这里假设test_age是字符串类型,但通常应为整数类型
)
put.addColumn(
Bytes.toBytes("baseInfo"), Bytes.toBytes("test_gender"),
Bytes.toBytes(rst.getString("test_gender"))
)
put.addColumn(
Bytes.toBytes("baseInfo"), Bytes.toBytes("test_phone"),
Bytes.toBytes(rst.getString("test_phone"))
)
// 返回构建好的Put对象
put
})
// 如果有数据需要插入HBase
if (puts.size() > 0) {
// 初始化HBase连接池并执行Put操作
val exe = MyHBase(Map("hbase.zookeeper.quorum" -> "single01:2181"))(1)
.build()
.initPool()
.finish()
// 执行Put操作,并返回是否成功
val bool = exe.put("hbase_test:tranfer_from_mysql", puts)
// 打印操作结果
println(bool)
} else {
// 如果没有数据需要插入
println("查无数据")
}
}
}
}






![[线程与网络] 网络编程与通信原理(六):深入理解应用层http与https协议(网络编程与通信原理完结)](https://img-blog.csdnimg.cn/direct/519f50271879474fb021cf132b45fd23.png)