一、将Hadoop传输到Windows中
1、备份副本
cp -r /opt/softs/hadoop3.1.3/ /opt/softs/hadoop3.1.3_temp2、删除备份的share目录
cd /opt/softs/hadoop3.1.3_temprm -rf share/3、下载到Windows中
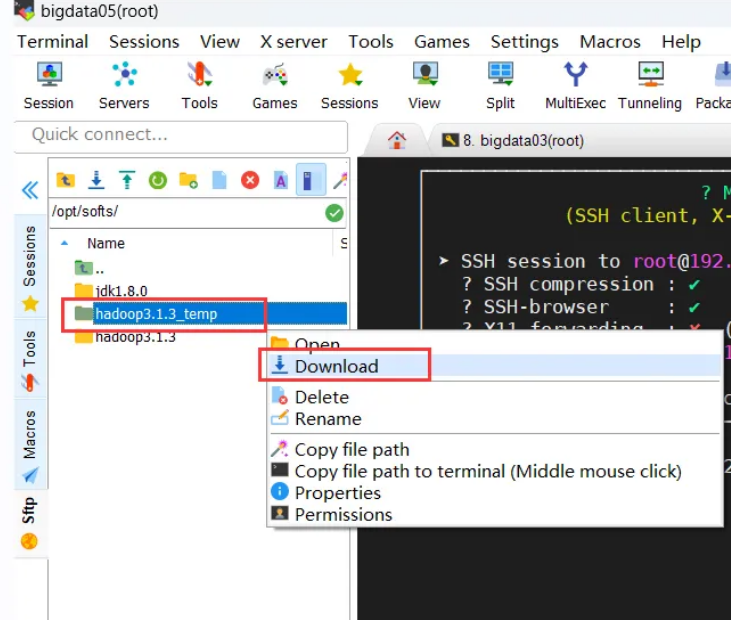
重命名去掉_temp
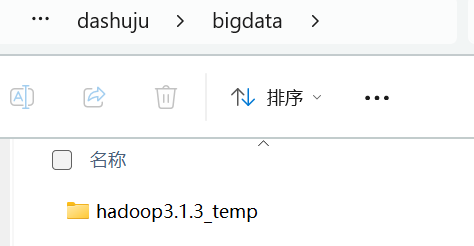
4、删除备份文件
rm -rf /opt/softs/hadoop3.1.3_temp二、配置Windows环境
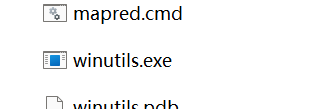
1、将Windos依赖目录下的bin目录中的全部文件,复制粘贴到hadoop3.1.3的bin目录下,有重复直接覆盖
2、双击winutils.exe,如果有窗体一闪而过,说明成功,如果失败则安装微软运行库
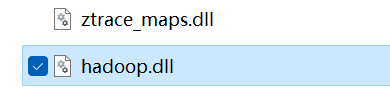
3、将hadoop.dll复制一份到C:\Windows\System32目录中
4、配置环境变量
(1)控制面板查找“高级系统设置”,打开后点击“环境变量”
(2)选择“系统变量”的“新建”输入如下信息:

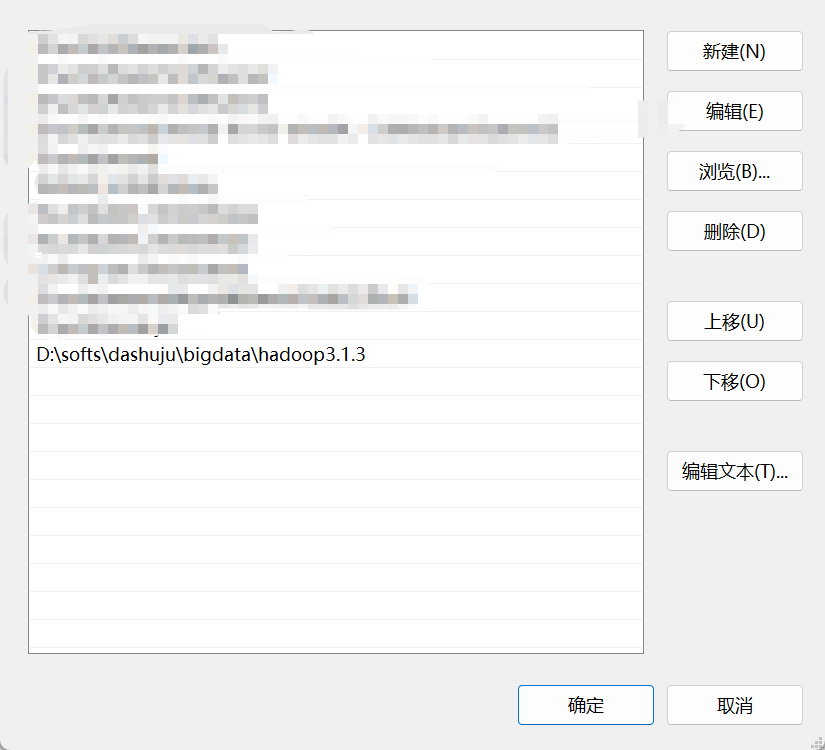
(3)选中“系统变量”的Path选择“编辑”后选择“新建”,输入如下信息
D:\softs\dashuju\bigdata\hadoop3.1.3 //输入你自己的地址
三、创建Java的Maven项目
idea版本:2023.2.5
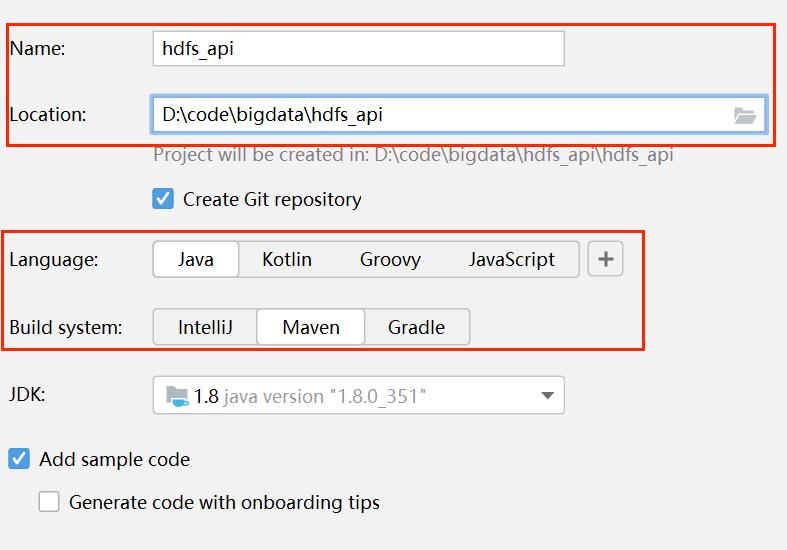
1、新建项目
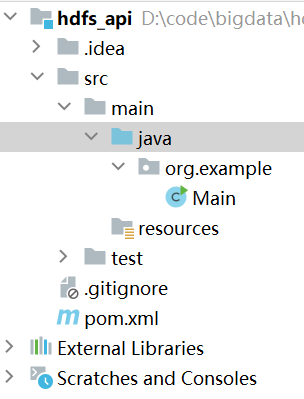
创建好后目录如下:
2、添加项目依赖
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
3、编写代码
package cn.edu.just.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.fs.permission.FsPermission;
import org.apache.hadoop.io.IOUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
*调用hdfs的Java Api
*/
public class hdfsApiClient {
//文件系统对象
FileSystem fileSystem = null;
/**
* 初始化hdfs文件系统
* @Before:在具体方法前会调用被注解的方法
*/
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
//创建文件系统配置对象
Configuration conf = new Configuration();
//创建文件系统对象
fileSystem = FileSystem.get(new URI("hdfs://bigdata03:8020"), conf, "root");
System.out.println("hdfs文件系统初始化成功!");
}
/**
* 创建hdfs目录
*/
@Test
public void createPath() throws IOException {
if (fileSystem != null) {
boolean result = fileSystem.mkdirs(new Path("/hdfs_api"));
if (result) {
System.out.println("创建目录成功");
}else {
System.out.println("创建目录失败");
}
}
}
/**
* 删除目录或者文件
*/
@Test
public void deletePath() throws IOException {
if (fileSystem != null) {
Path deletePath = new Path("/hdfs_api");
//判断hdfs上是否存在该目录
if (fileSystem.exists(deletePath)){
/**
* 目录存在,调用delete(Path f, boolean recursive)方法进行删除
* 第一个参数是要删除的目录的路径
* 第二个参数表示:是否要递归删除
*/
boolean deleteResult = fileSystem.delete(deletePath, false);
System.out.println(deleteResult == true ? "删除目录成功":"删除目录失败");
}else {
System.out.println("要删除的目录在hdfs上不存在");
}
}
}
/**
* 在hdfs上创建一个文件,并写入指定的内容
*/
@Test
public void createHdfsFile() throws IOException {
//获取数据输出流对象
FSDataOutputStream fsDataOutputStream =
fileSystem.create(new Path("/api_file.txt"));
//定义要输出的文件的内容
String line = "Hello bigdata";
//将指定内容写入文件
fsDataOutputStream.write(line.getBytes());
//对数据输出流对象进行刷新
fsDataOutputStream.flush();
//关闭输出流对象
fsDataOutputStream.close();
}
/**
* 先运行一下createPath,确保hdfs上目录存在
* 修改hdfs上的文件的路径和名称
*/
@Test
public void moveHdfsFile() throws IOException {
//文件的原路径
Path src = new Path("/api_file.txt");
//文件的新路径
Path dst = new Path("/hdfs_api/api_file_new.txt");
boolean moveResult = fileSystem.rename(src, dst);
if (moveResult){
System.out.println("文件路径修改成功");
}else {
System.out.println("文件路径修改失败");
}
}
/**
* 读取hdfs上的文件内容
*/
@Test
public void readHdfsFile() throws IOException {
//获取数据输入流对象
FSDataInputStream fsDataInputStream =
fileSystem.open(new Path("/hdfs_api/api_file_new.txt"));
//通过IO工具类读取文件中的数据
//System.out代表队是PrintStream对象,该对象是OutputStream类的间接子类
IOUtils.copyBytes(fsDataInputStream,System.out,2048,false);
//换行
System.out.println();
}
/**
* 从本地上传文件到hdfs上
*/
@Test
public void uploadFile() throws IOException {
//本地文件的路径
Path src = new Path("E:\\centos&&hadoop\\words.txt");
//文件上传到到hdfs的路径
Path dst = new Path("/hdfs_api");
//文件上传成功后,本地文件是否删除,默认为false
boolean delSrc = true;
//上传文件是否覆盖,默认为true
boolean overwrite = false;
fileSystem.copyFromLocalFile(delSrc,overwrite,src,dst);
}
/**
*从hdfs上下载文件到本地
*/
@Test
public void downloadFile() throws IOException {
//在hdfs上的文件
Path src = new Path("/hdfs_api/api_file_new.txt");
//文件的下载路径
Path dst = new Path("E:\\centos&&hadoop\\api_file_new.txt");
//文件下载后,是否删除hdfs上的源文件
boolean delSrc = false;
// false:下载的文件会存在crc校验文件
// true:不会存在crc校验文件
boolean useRawLocalFileSystem = false;
fileSystem.copyToLocalFile(src, dst);
}
/**
* 查看hdfs上的文件信息
*/
@Test
public void queryHdfsFileInfo() throws IOException {
//查询的起始路径
Path path = new Path("/");
//是否递归查询
boolean recursive = true;
//获取迭代器
RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator =
fileSystem.listFiles(path, recursive);
//进行遍历输出
while ( locatedFileStatusRemoteIterator.hasNext()) {
//获取迭代器中需要迭代的元素
LocatedFileStatus next = locatedFileStatusRemoteIterator.next();
//获取文件路径
Path filePath = next.getPath();
System.out.println("文件的路径是:"+filePath);
//获取文件的权限
FsPermission permission = next.getPermission();
System.out.println("文件的权限是:"+permission);
//获取文件的所属用户
String owner = next.getOwner();
System.out.println("文件的所属用户是:"+owner);
//获取文件的所属用户的用户组
String group = next.getGroup();
System.out.println("文件的所属用户的用户组是:"+group);
//获取文件的副本数
short replication = next.getReplication();
System.out.println("文件的副本数是:"+replication);
//获取文件的块大小,单位是字节
long blockSize = next.getBlockSize();
System.out.println("文件的块大小是:"+blockSize/1024/1024+"MB");
System.out.println("--------------------------------------------------------");
}
}
/**
* 关闭文件系统对象
* @After:在具体方法执行完毕后会调用被注解的方法
*/
@After
public void close() throws IOException {
if (fileSystem != null) {
fileSystem.close();
System.out.println("hdfs文件系统已关闭!");
}
}
}
运行前开启hadoop集群,在NameNode节点开启hdfs(start-dfs.sh)
可打开NameNode的web服务网址,便于后续查看