列表和翻页是所有应用系统里面必不可少的需求,但是当深度翻页的时候,越深越慢。下面是几种常用方式
准备工作
CREATE UNLOGGED TABLE data (
id bigint GENERATED ALWAYS AS IDENTITY,
value double precision NOT NULL,
created timestamp with time zone NOT NULL
);
/* 设置随机数种子 */
SELECT setseed(0.2740184);
/* 初始化数据 */
INSERT INTO data (value, created)
SELECT random() * 1000, d
FROM generate_series(
TIMESTAMP '2022-01-01 00:00:00 UTC',
TIMESTAMP '2022-12-31 00:00:00 UTC',
INTERVAL '1 second'
) AS d(d);
/* 添加主键 */
ALTER TABLE data ADD PRIMARY KEY (id);
/* 回收空间,并对表数据进行统计分析 */
VACUUM (ANALYZE) data;
我们的查询目标是下面的SQL
SELECT value, created
FROM data
WHERE value BETWEEN 0 AND 10
ORDER BY created;
为了加速查询我们可以创建对应索引
CREATE INDEX data_created_value_idx ON data
(created, value);
简单分页 LIMIT ? OFFSET ?
这是第一种方式
-- 首页
SELECT value, created
FROM data
WHERE value BETWEEN 0 AND 10
ORDER BY created
LIMIT 50;
-- 第 深n 页
SELECT value, created
FROM data
WHERE value BETWEEN 0 AND 10
ORDER BY created
OFFSET 180000 LIMIT 50;
不论是mysql 还是pg数据库 直接使用offset limit 这种查询的时候都是扫描处理前 n * pageSIze 数据然后丢弃前面 (n-1) * pageSize页的数据,数据库是否使用索引是有优化策略的,当经过一系列复杂的预估之后,假如数据库优化器 判定 走索引还没全表扫描效率高的时候就会放弃走索引,这个时候我们的查询就会比较慢,基本上都是秒级别的了
上面两个sql的执行计划如下
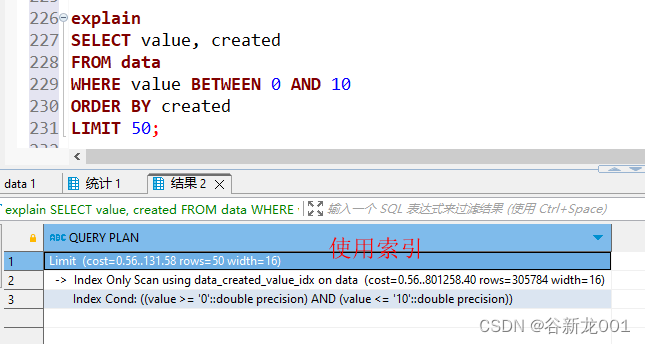
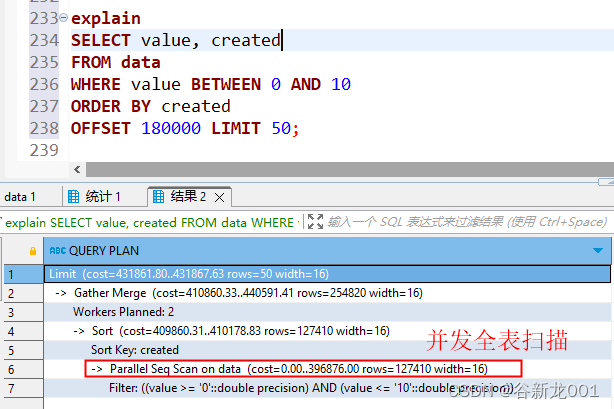
全表扫描最大的问题不仅仅是某个查询慢,更严重的是会导致锁表
缺点
- 页码越深,性能越差,但是假如用户只关心前面几页的数据,是没有什么问题的
- 并发情况下翻页会有跳数据或者重复数据的问题,比如用户A是在查看数据翻页的,用户B在第一页加了一条数据,这个时候用户A翻页,那么原来第一页最后的数据就会被挤到第二页,类似这种情况,但是一般的时候非高并发情况可以不考虑
优点
简单,不管怎么翻都一招鲜 吃遍天
使用游标 WITH HOLD CURSORS
WITH HOLD CURSORS是一种特殊的游标,与普通游标主要区别如下
- 普通游标:普通游标(或称为会话级游标)的生命周期通常与创建它的事务相同。这意味着,当事务提交或回滚时,游标也会被关闭,其相关的资源会被释放。
- WITH HOLD CURSORS:WITH HOLD游标在事务结束后仍然保持打开状态,即使原始事务已经提交或回滚。这使得游标可以在多个事务之间保持活动状态,直到显式关闭或会话结束
但是在分页情况下我们一般一页是一个请求,这个时候肯定是不同的事务,所以这个时候普通游标是无法满足我们的要求的
我们使用WITH HOLD CURSORS
DECLARE c SCROLL CURSOR WITH HOLD FOR
SELECT value, created
FROM data
WHERE value BETWEEN 0 AND 10
ORDER BY created;
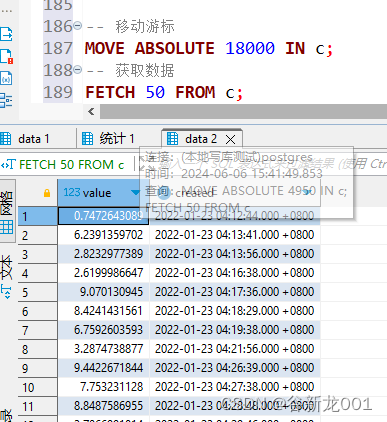
获取任意数据
-- 移动游标
MOVE ABSOLUTE 4950 IN c;
-- 获取数据
FETCH 50 FROM c;
注意继续FETCH会继续后翻页
还需要注意的是这个游标用完可一定要关闭、关闭;关闭,重要的事情说三遍
-- 关闭游标
CLOSE c;
优点
- 适用于所有查询,不管是第一页还是最后一页,效率一样
- 结果集是稳定的,没有像OFFSET和LIMIT那样跳过或重复结果
- 可以跳页,从第5页,直接跳到第100页
缺点
- 当完成操作时,一定不要忘记关闭游标,否则结果集将保存在服务器上,直到数据库会话结束
- 如果游标长时间打开,数据将变的陈旧,无法获取动态的最新数据
- 游标长时间打开,相当于一个长事务
KEYSET PAGINATION
暂时翻译为位点,原理上就是记录上一次数据最后一条内容,所以,这个值必须是唯一的强有序的,这样翻页的时候才不会重复或者跳过数据
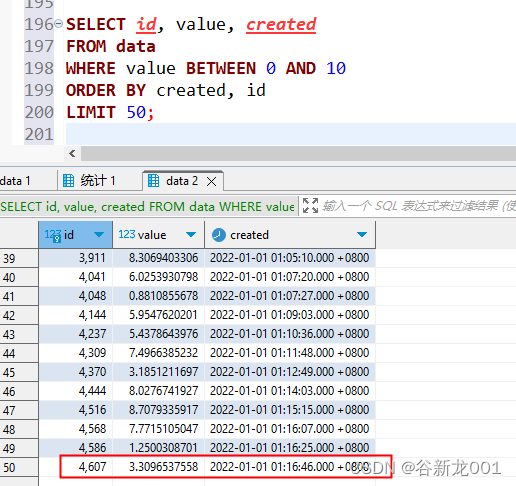
-- 首页查询
SELECT id, value, created
FROM data
WHERE value BETWEEN 0 AND 10
ORDER BY created, id
LIMIT 50;
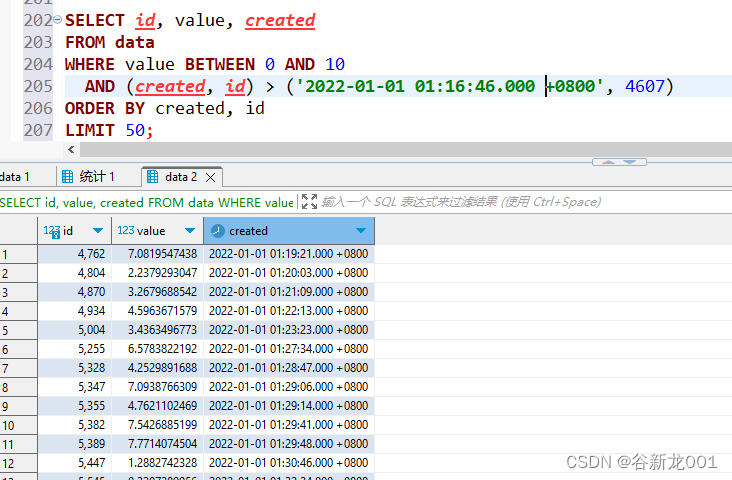
-- 基于上面位点的下一页
SELECT id, value, created
FROM data
WHERE value BETWEEN 0 AND 10
AND (created, id) > ('2022-01-01 01:27:35+01', 5256)
ORDER BY created, id
LIMIT 50;
位点查询
如果使用这种方式的话我们添加这个索引效率会更好
CREATE INDEX data_keyset_idx ON data
(created, id, value);
优点
- 每次查询只获取我们需要的数据,不需要扫描不额外的数据,减少了相关资源代价
- 每个查询将展示最新并发数据修改的当前数据
缺点:
- 需要一个专门为查询而设计的特殊索引
- 需要对业务进行改造只有事先能获取到确切的位点,查询时才有用,并且当我们修改排序字段或者条件的时候,这个位点可能跟之前的就不一致了。
- 前后端都需要改造
其他
一般情况下我们可能也需要count这个值,上面三种方式中WITH HOLD CURSORS是天然支持的
MOVE ALL IN c;

剩下两种都是扫描全表,使用昂贵的资源,简单点跟产品battle 不支持,tips:对于ES深度翻页,直接limit比PG,MySQL资源更严重,因为ES会在每个分区上进行计算到协作节点进行统一聚合,所以一般的ES可能会关闭这种深度分页或者使用游标,类似Feed流,下一个下一个。整体思想是一致的。
参考