文章目录
- 水果成篮
- 找到字符串中所有字母异位词
- 串联所有单词的子串*
- 最小覆盖子串*
水果成篮

两元素排空操作
窗口中存在元素交错情况,所以出窗口一定要出干净!!!
class Solution {
public:
int totalFruit(vector<int>& fruits) {
unordered_map<int, int> hash; // 统计水果情况
int res = 0;
for (int left = 0, right = 0; right < fruits.size(); right++) {
hash[fruits[right]]++; // 进窗口
while (hash.size() > 2) // 判断
{
// 出窗口
hash[fruits[left]]--;
if (hash[fruits[left]] == 0)
hash.erase(fruits[left]);
left++;
}
res = max(right - left + 1, res);
}
return res;
}
};
优化:
class Solution {
public:
int totalFruit(vector<int>& fruits) {
int hash[100001] = {0}; // 统计水果情况
int res = 0;
for (int left = 0, right = 0, kinds = 0; right < fruits.size();
right++) {
if (hash[fruits[right]] == 0)
kinds++; // 维护水果种类
hash[fruits[right]]++; // 进窗口
while (kinds > 2) // 判断
{
// 出窗口
hash[fruits[left]]--;
if (hash[fruits[left]] == 0)
kinds--;
left++;
}
res = max(right - left + 1, res);
}
return res;
}
};
技巧:数据有限的情况下,用数组比用容器快很多
找到字符串中所有字母异位词

class Solution {
public:
vector<int> findAnagrams(string s, string p) {
if (s.size() < p.size())
return {};
vector<int> res;
long long sum = 0;
for (auto e : p)
sum += (e - '0') * (e - '0') * (e - '0');
int left = 0, right = 0;
long long target = 0;
while (right < s.size()) {
target += (s[right] - '0') * (s[right] - '0') * (s[right] - '0');
while (target >= sum && left <= right) {
if (target == sum && right - left == p.size() - 1)
res.push_back(left);
target -= (s[left] - '0') * (s[left] - '0') * (s[left] - '0');
left++;
}
right++;
}
return res;
}
};
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
if (s.size() < p.size())
return {};
int hash1[26] = {0};
for (auto e : p)
hash1[e - 'a']++;
vector<int> res;
int hash2[26] = {0};
int m = p.size();
for (int left = 0, right = 0, count = 0; right < s.size(); right++) {
char in = s[right];
if (++hash2[in - 'a'] <= hash1[in - 'a']) // 进窗口及维护count
count++;
if (right - left + 1 > m) // 判断
{
char out = s[left++];
if (hash2[out - 'a']-- <= hash1[out - 'a'])
count--; // 出窗口及维护count
}
// 结果更新
if (count == m)
res.push_back(left);
}
return res;
}
};
串联所有单词的子串*



class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
int slen = s.size(), plen = words.size(), _size = words[0].size();
plen *= _size;
if (plen == 0 || slen < plen)
return {};
// 滑动窗口+哈希表
vector<int> res;
unordered_map<string, int> aCount;
for (auto& e : words)
aCount[e]++;
unordered_map<string, int> bCount;
int n = words[0].size();
while (n--) /// 执行n次滑动窗口
{
for (int left = n, right = n, count = 0; right + _size <= s.size();
right += words[0].size()) {
string in = s.substr(right, words[0].size());
bCount[in]++;
// if(aCount[in] && bCount[in] <= aCount[in]) count++;
if (aCount.count(in) && bCount[in] <= aCount[in])
count++;
// 这里窗口的长度是right + len -left,
// 也就是说窗口的长度已经大于words的总体长度
if (right - left == words[0].size() * words.size()) {
string out = s.substr(left, words[0].size());
// 这里用[]会影响速度,用哈希的计数函数快一些
// count函数的返回值是0或1
// ,类似于bool值,表示其是否存在,而[]返回的是次数,就涉及到了查找,故花费时间较长
if (aCount.count(out) && bCount[out] <= aCount[out])
count--;
// if(aCount[out] && bCount[out] <= aCount[out]) count--;
bCount[out]--;
left += words[0].size();
}
if (count == words.size())
res.push_back(left);
}
bCount.clear();
}
return res;
}
};
```cpp
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> result;
if (s.empty() || words.empty())
return result;
int word_length = words[0].length();
int num_words = words.size();
int total_length = word_length * num_words;
unordered_map<string, int> word_count;
for (const string& word : words) {
word_count[word]++;
}
for (int i = 0; i < word_length; ++i) {
int left = i, right = i;
unordered_map<string, int> window_count;
while (right + word_length <= s.length()) {
string word = s.substr(right, word_length);
right += word_length;
if (word_count.find(word) != word_count.end()) {
window_count[word]++;
while (window_count[word] > word_count[word]) {
string left_word = s.substr(left, word_length);
window_count[left_word]--;
left += word_length;
}
if (right - left == total_length) {
result.push_back(left);
}
} else {
window_count.clear();
left = right;
}
}
}
return result;
}
};
两段代码都是:哈希+滑动窗口,时间空间复杂度也一样,但是测试时间却减少了许多,可以对比一下第二段代码优于第一段代码的点在哪里?
最小覆盖子串*

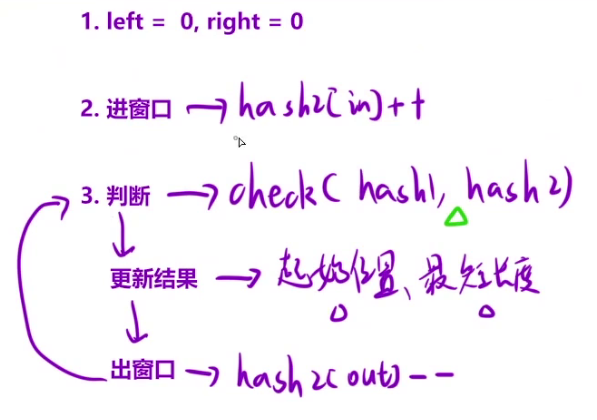
class Solution {
public:
string minWindow(string s, string t) {
string res;
int hash[128] = {0};
int tt = 0; // 字符种类
for (char& e : t)
if (0 == hash[e]++)
tt++;
int hash1[128] = {0};
int begin = -1, m = INT_MAX;
for (int left = 0, right = 0, count = 0; right < s.size(); right++) {
// 进窗口
char in = s[right];
if (++hash1[in] == hash[in])
count++;
// 检查
while (count == tt) {
// 更新
if (right - left + 1 < m) {
begin = left;
m = right - left + 1;
}
// 出窗口
char out = s[left++];
if (hash1[out]-- == hash[out])
count--;
}
}
if (begin != -1)
res = s.substr(begin, m);
return res;
}
};
// "ADOBEC"




![[网鼎杯 2020 青龙组]jocker](https://img-blog.csdnimg.cn/direct/a188d89407174ab2977c63c9f4011c5f.png)