大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。
大型语言模型能够取得巨大的进步完全取决于缩放定律。随着基础模型的参数规模增加,性能的确也是平滑提升。当不断地扩展这些参数规模大的LLMs时,内存成本和计算资源也会随之而剧增,进而达到硬件的最终极限。那么是否可以使用稀疏激活的大语言模型来解决这个问题?

Mixture of Experts (MoE)
专家混合(层)MoE,允许增加语言模型的大小或容量,而无需相应增加计算量。只是将模型的某些层替换为该层的多个副本(称为“专家”,可以理解为每个副本专注各自的领域),这些副本具有独立的参数。
然后使用门控机制稀疏地(如何理解稀疏,就是将部分的请求分给部分专家)选择用于处理每个输入的专家。这个想法其实早在90年代早期的条件计算研究,它允许以一种易于处理的方式训练大规模模型。
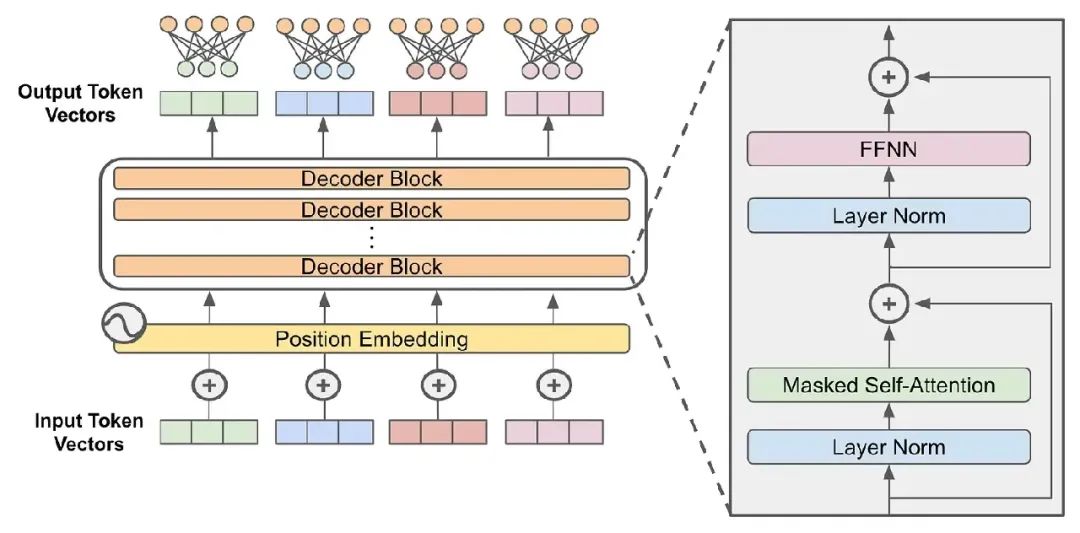
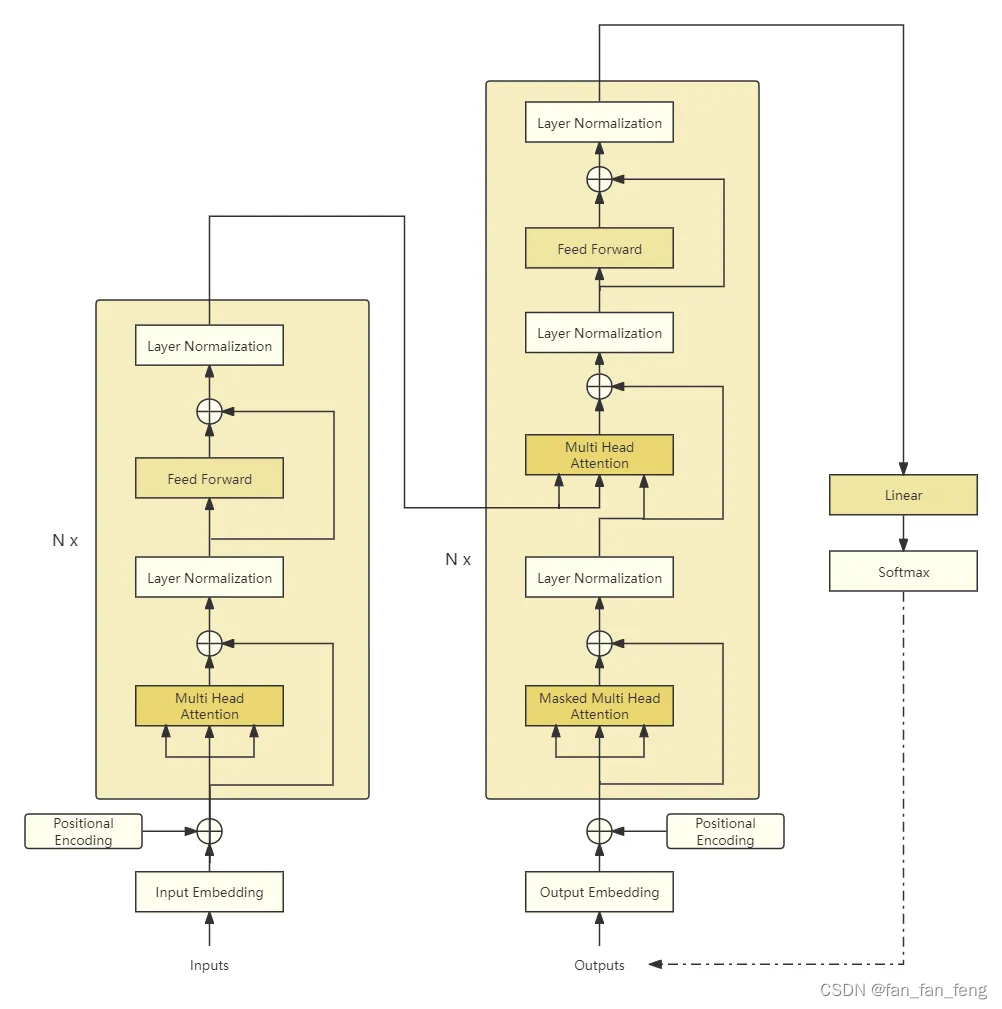
先来看看Decode-Only的Transformer架构,例如GPT系列都是基于Decode-Only,而Bert则是基于Encode-Only的架构。Decode-Only的大模型基本都是由Decoder Block堆叠而成,每一个Block的结构如上图左侧所示。在通过多头注意力模块之后,会接一个FFNN层。<若是忘记FFNN,可以点击链接回去温习!>
在LLMs中,MoE对这个架构进行了简单修改——用MoE层替换了前馈层!该MoE层由多个专家组成(数量在几个到几千个之间),其中每个专家都是前馈子层,各自拥有独立的参数。
可以通过将编码器和解码器中的前馈子层替换为MoE层,进而将原来的模型转换为MoE模型。也可以只将这些子层的一部分(例如,每隔N层)转换为MoE层。
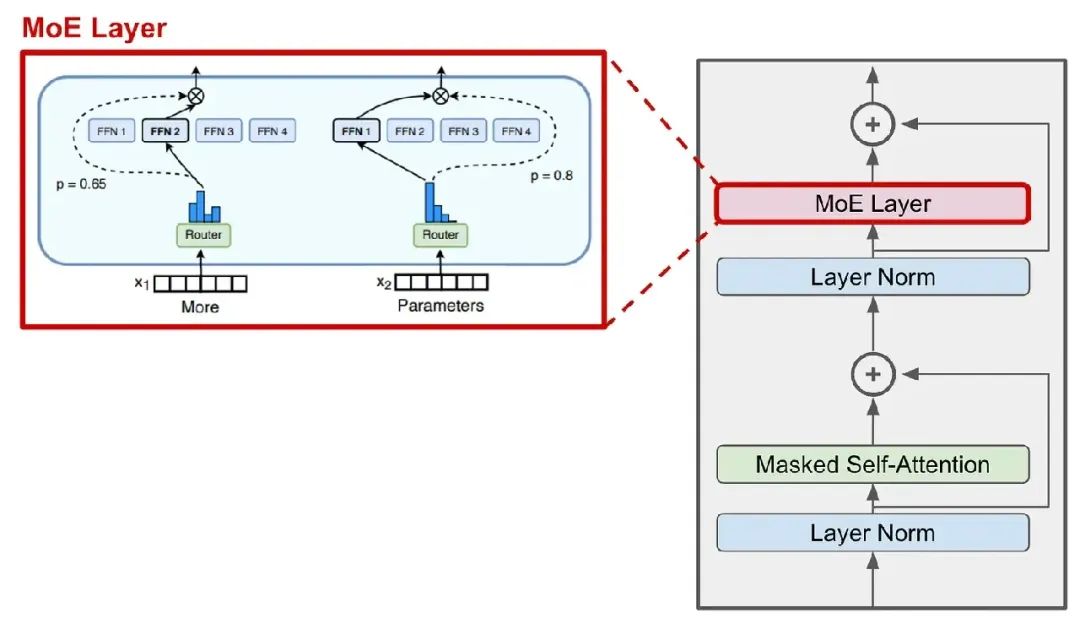
也许会疑惑,不是增加了很多专家,肯定向模型添加了大量参数。毕竟MoE模型在Transformer的每个前馈子层内具有多个独立的神经网络。其实可以这么来理解稀疏的,给定一个Token序列作为输入,使用路由机制稀疏地选择一组专家,每个Token将被发送到这些专家,而不是激活所有的专家,因此MoE模型前向传递的计算成本远低于具有相同参数数量的密集模型的计算成本。

MoE的结构
MoE应用于 transformer 模型时,MoE 层有两个主要组件:
-
Sparse MoE Layer: 将变压器中的前馈层替换为几个结构相似的“专家”的稀疏层。
-
Router: 路由器,确定将 MoE 层中的哪些令牌发送给哪些专家。

稀疏MoE层中的每个专家都是一个前馈神经网络,具有自己独立的参数集 。每个专家的架构都模仿传统的前馈子层。路由器将每个Token作为输入,并在专家上产生概率分布,以确定每个Token发送到哪个专家。
路由器有自己的一组参数,并与网络的其余部分共同训练。每个Token都可以发送给许多专家,一般而言只向通过某些计算得到的前k位专家发送Token。k取决于参数设置,例如k=1或k=2 则意味着每个Token分别由一个或两个专家处理。
例如,假设有一个7B参数LLM,并将其每个前馈子层替换为一个由 8 个专家组成的MoE层,其中每个令牌激活2个专家。这与Mixtral-8x7B(Mistral-7B的MoE变体)所使用的架构完全相同。完整模型大约有 47B 参数,所有这些参数都必须加载到内存中。但是,该模型的推理成本与 14B参数模型相当。每个Token只使用两个专家来处理,这会产生约2 x 7B的矩阵乘法。然而整体实现了约50B的参数模型。
MoE模型被广泛使用,能够用固定的计算资源训练更大的模型。与密集模型相比,MoE模型的预训练速度更快,并且与具有相同参数数量的密集模型相比,推理速度要快得多。
但是MoE类的LLMs也会消耗更多的VRAM,因为所有专家都必须加载到内存中,再者GPU擅长高效执行算术运算,但不擅长分支,而条件计算则对分支计算的要求较高。此外MoE模型容易出现过拟合,并且很难微调。
当然MoE和RNN网络也是可以可以整合。


门控机制
为了计算MoE模块的输出,可以利用专家输出的加权组合,其中权重由路由器提供。路由器输出权重的N维向量(N是专家的数量)。当路由器输出稀疏时,在计算 MoE时不考虑权重为零的专家。

对于MoE内部路由有很多不同的策略。最简单的方法是将输入乘以权重矩阵并应用softmax。为了进一步保证是稀疏的输出,有研究人员提出一种改进的门控机制,为这种简单的softmax门控机制增加了稀疏性和噪声。

上图示意在应用softmax之前,将可调节的高斯噪声添加到路由器的输出。另外除了Top K专家的输出,所有输出都被设置为-∞进行屏蔽以确保专家的选择是稀疏的。
MoE的经典问题是,在训练期间,网络一般都会倾向重复的使用相同的少数专家。门控机制将收敛到一种状态,即始终为每个输入选择同一组专家。这是一个循环,一旦一个专家被频繁的选中,它的训练速度更快,因此它会被继续选中!很多研究都在解决这个问题的方法,例如可以通过在训练损失中添加一个简单的“软”约束来平衡。
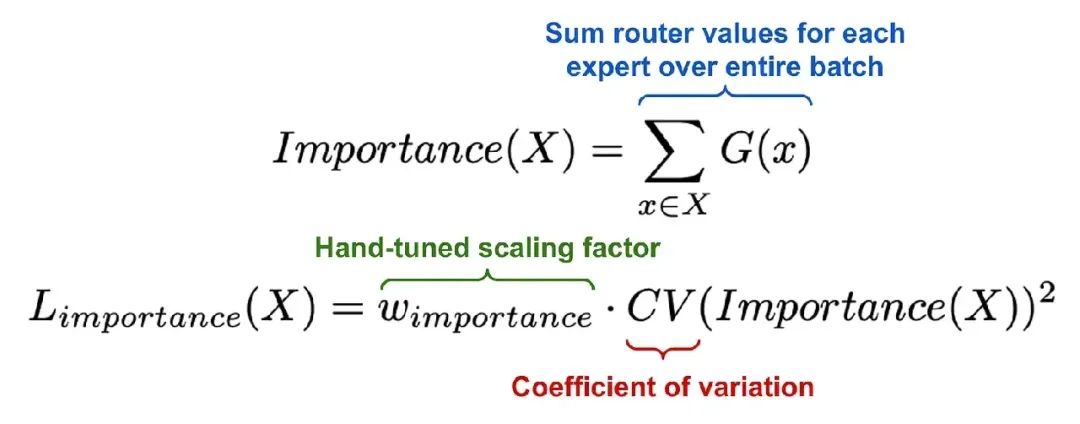
说来也简单,首先在每个批次的训练过程中,将每个专家的门控得分做累加得到Importance Score。那意味着在某个批次中经常被选中的专家将获得最高的分数。
接下来通过取专家Importance Score的平方变异系数 (CV) 来计算辅助损失函数。若所有专家的分数都非常相似,那么CV值就会很小,反之亦然。将这个损失项添加到模型的训练目标中以便于鼓励专家在每批中获得同等的重要性。