视频虚拟试穿技术日益受到关注,然而现有的工作局限于将服装图像转移到姿势和背景简单的视频上,对于随意拍摄的视频则效果不佳。最近,Sora 揭示了 Diffusion Transformer (DiT) 在生成具有真实场景的逼真视频方面的可扩展性,可以说是风头无两。正是在这样的背景下,中山大学和字节跳动团队探索并提出第一个基于 DiT 的视频虚拟试穿框架 VITON-DiT,一键就能生成换装后视频了!
论文题目:
VITON-DiT: Learning In-the-Wild Video Try-On from Human Dance Videos via Diffusion Transformers
论文链接:
http://arxiv.org/abs/2405.18326
论文单位:
中山大学、字节跳动
引言
视频虚拟试穿系统旨在通过视频为目标人物穿上所需的服装,同时保持其动作和身份。这项技术在电子商务和娱乐等实际应用中具有巨大的潜力。现有的大部分工作都集中在基于图像的试穿上,例如基于生成对抗网络(GANs)的图像试穿。
尽管图像生成质量令人印象深刻,但基于UNet的LDMs在处理视频场景时表现欠佳。而新兴的基于Transformer的LDMs(或称扩散Transformer,DiT)在生成高保真现实世界图像/视频方面展示了显著的能力和可扩展性,例如Stable Diffusion 3和Sora。受Sora的启发,作者提出了VITON-DiT,这是首个基于DiT的视频虚拟试穿模型,旨在解决真实场景中的视频试穿问题。
具体来说,VITON-DiT 包含三个主要组件:
-
用于视频潜在生成的空间时间去噪 DiT
-
用于保持服装细节的服装提取器
-
用于保留人物姿势和身份的 ID 控制网络
这三个模块通过创新的注意力融合机制连接。这种机制通过一个附加的注意力过程将提取的服装特征与人物去噪特征相结合,从而能够将服装特征无缝地集成到视频生成过程中。
方法
VITON-DiT 的核心是扩散变换器 DiT,这是一种结合了扩散模型和变换器架构的新型神经网络模型。扩散模型通过逐步添加噪声并在反向过程中去除噪声来生成数据,而变换器则利用自注意力机制处理序列数据。这种结合使得VITON-DiT能够生成高质量且逼真的视频内容。
VITON-DiT框架 包含三个组件:去噪DiT、服装提取器和ID ControlNet。时空DiT模块是去噪DiT中的主要结构,每个块包含空间自注意力(SSA)、时间自注意力(TSA)和提示交叉注意力(PCA)层。
3.5研究测试:
hujiaoai.cn
4研究测试:
askmanyai.cn
Claude-3研究测试:
hiclaude3.com
SSA 在空间维度上执行注意力,以生成/保留纹理。而TSA 在时间维度上执行注意力,以保持时间一致性。对于 PCA,则是在提示嵌入(例如,“跳舞的人”)和 TSA 的中间特征之间执行交叉注意力,以增强整体视觉质量。
这些层协同工作,不仅能够生成服装的纹理,还能保持视频序列中的时间连贯性。
对于去噪 DiT 来说,其训练目标仍是标准的潜在扩散损失。
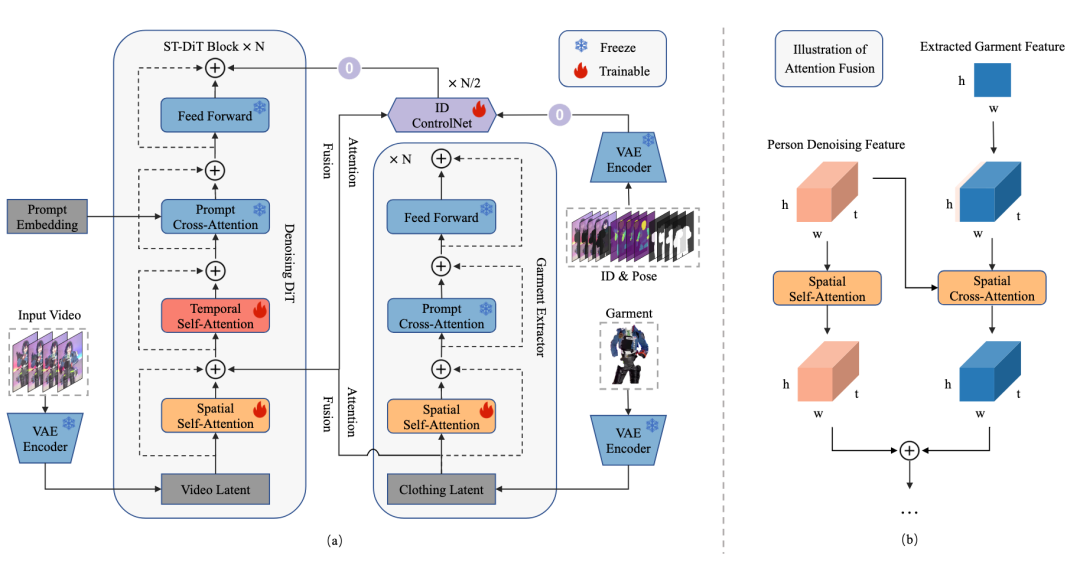
▲图 2. VITON-DiT概述。(a)该架构包含三个组件,具有以下任务。(1)去噪 DiT:通过一组时空 (ST-) DiT 块生成视频内容的潜在表示。(2)ID 控制网络:为去噪 DiT 生成特征残差,以保留参考人物的身份、姿势和背景。(3)服装提取器:通过注意力融合获取并向去噪 DiT 和控制网络传递服装特征,从而在生成的试穿视频中恢复详细的服装纹理。(b)注意力融合说明:使用加性注意力整合人物去噪特征和提取的服装特征。此操作同时用于去噪 DiT 和 ID 控制网络。
👗 服装提取器
服装提取器是VITON-DiT中的另一个关键组件,它负责从输入的服装图像中提取特征。这些特征随后会被融合到去噪DiT和 ID ControlNet中,以确保生成视频中的服装细节得到精确恢复。
由于输入仅包含一张服装图像 (即没有时间信息),因此它去掉了时间注意力机制。
与去噪 DiT 类似,服装图像由 编码并经过 个服装提取模块。在每次传递中,需要存储中间特征,然后将其输入到主 DiT 和 ID 控制网络中。具体来说,如图 2(b) 所示,注意力融合模块发挥作用,并通过加性注意将服装编码器与其他两个模块关联起来。注意力的融合过程可以表述为:
🔒 身份保留控制网络(ID ControlNet)
ID ControlNet的设计目的是在试穿过程中保持人物的姿势和身份信息。它通过一个网络来引导去噪DiT,确保人物的面部和身体特征在生成的视频中保持一致。
从本质上讲,视频虚拟试穿可以看作是一个图像修复(inpainting)问题。它需要四元组 将目标服装 放置在参考人物视频 上,包括与服装无关的图像 、DensePose 图像 和修复掩码 ,如图 2(a) 所示。由于 OpenSora 的预训练权重未针对图像修复任务进行调整,因此作者引入了一个 ID ControlNet 来保留人物的姿势、身份和背景。
形式上,给定一个与服装无关的条件序列 ,VAE 编码器 产生潜在变量 ,这些变量进一步与掩码 拼接。
然后,大小为 的潜在变量被修补,并通过一个零初始化的线性层,然后再送入 ID 控制网络。 的输出信号直接注入去噪 DiT 中作为特征残差。通过这样的设置可以使 能够提供精确、像素对齐的控制信号,以实现准确的身份保留。这个过程可以被描述为:
其中 表示拼接操作。同时,作者发现提出的 ID 控制网络对条件错误具有鲁棒性,以图 5(a) 为例,虽然控制网络的 DensePose 输入有明显的伪影,但 VITON-DiT 仍然产生了合理的结果。
🔄 长视频生成的训练和推理策略

▲图 3.(a)随机不可知条件交换:随机用对应的真实图像且全零掩码替换掉不可知图像和修复掩码。(b)IAR 推断:在每个划分的序列内生成关键帧,然后进行 AR 推断以填充缺失的帧。
直接生成长视频是非常具有挑战性的,特别是在计算资源有限的情况下。为了缓解这一问题,作者在训练过程中使用了一种新的随机选择策略,而在推理过程中使用一种插值自回归(IAR)技术。
在训练过程中,系统会随机选择一些帧,并在这些帧上应用特定的训练技术,以增强模型对不同视角和动作的适应能力。而在推理过程中使用 IAR 技术,通过先生成关键帧、再使用自回归的方法,将剩余帧进行填充,从而生成高质量的长视频。
对于 IAR 技术,作者称它改进了传统的自回归方法,更有利于生成高质量的扩展视频。作者将视频生成分为两个子任务:关键帧生成和帧填充。具体来说,对于生成 帧视频的任务,IAR 首先将其分成 个子视频,根据提供的条件预测每个子视频中的起始帧,然后进行自回归技术填充缺失的 帧。这可以防止模型因遮挡而导致质量下降,还能确保视频的流畅性。
实验结果
作者收集了一个不成对的人类舞蹈视频数据集,其中包含各种服装、背景和身体动作。使用场景检测工具对收集到的数千个视频进行分割,并筛选出多人或一小部分人的片段,从而产生超过 15,000 个高质量视频片段。作者进一步结合 FashionVideo 和 Tiktok 数据集进行训练。最后挑选了50个不同身份、不同背景的片段,作为评估视频试穿效果的新基准。
VITON-DiT采用了多阶段自监督训练策略,具体步骤如下:
-
图像预训练(Garment Extractor):在这一阶段,仅训练服装提取器,冻结其他所有模块,从解析出的服装图像中重建人物图像。这有助于模型学习更大量的服装图像,并增强生成人物图像的能力。
-
图像预训练(ID ControlNet):接着,加入ID ControlNet,除了去噪ST-DiT的SSA模块,其他的所有参数都设置为可训练。训练目标与第一阶段相同。
-
视频微调(VITON-DiT):最后,除了去噪ST-DiT的SSA模块,对所有参数进行训练。
📊 定量与定性结果
-
定量评估:研究人员使用了结构相似性指数(SSIM)、学习感知图像补丁相似性(LPIPS)和 Fréchet Inception Distance(VFID)等指标来评估生成视频的视觉质量和时间连贯性。
-
定性评估:VITON-DiT在VVT数据集上与其他基线方法进行了比较。结果显示,VITON-DiT在保持服装形状和颜色一致性,以及在不同摄像机距离下服装-人物对齐方面表现优于其他基线。
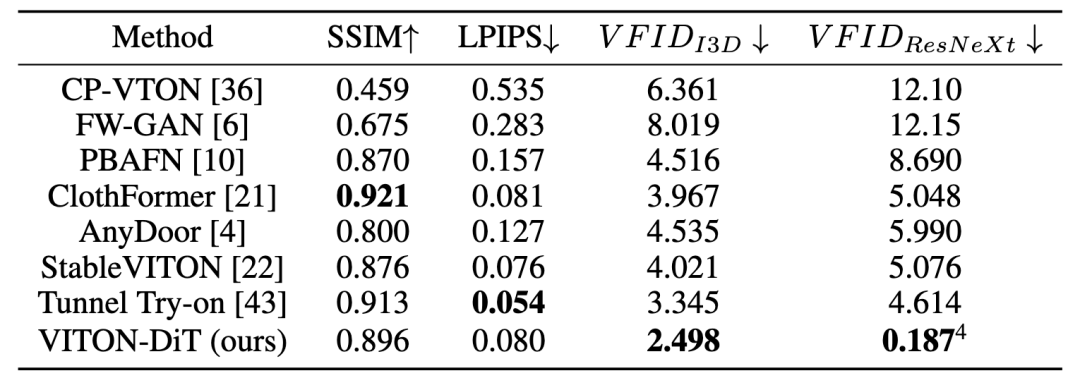
▲表 1:VVT 数据集的定量比较。最好的结果用粗体表示。

▲图 4:与基线的定性比较。VITON-DiT 在一致保留服装形状和颜色以及在不同相机距离下稳定的服装与人对齐方面优于其他基线。
📈 消融研究

▲图 5:数据量消融研究。随着数据质量和数量的增加,模型的视觉性能也相应逐渐提高。
研究表明,随着数据质量和数量的增加,模型的视觉性能也逐渐提高。使用少量但是高质量的数据(即 Data-S)训练的模型明显优于 Data-F。此外,更多数量的 HQ 数据能够获得更好的人体先验知识,即使在姿势引导不准确的情况下,模型也能产生合理的结果,如图5所示(Data-M 和 Data-L 列)。

包含空间交叉注意力(SCA)的完整模型在恢复服装纹理方面比其他模型变体表现更好。另外,与传统的自回归(AR)方法相比,IAR技术在处理遮挡和恢复纹理细节方面更为稳健。

总结
这篇文章提出了第一个基于DiT的视频试穿网络VITON-DiT,能够有效地恢复生成视频中的服装细节,实现数十秒的视频生成。
相比于之前的 VITON、GP-VTON等工作,VITON-DIT 方法将当前的先进技术融入进来,包括 DiT、注意力机制等。摒弃了以前工作中的各种形变方法后,不仅获得了非常先进的性能,而且也拓展到了视频生成领域,这也正是技术发展的魅力了。