执行前记得在对应的节点上启动hdfs(start-dfs.sh )、yarn(start-yarn.sh)和任务历史服务(mapred --daemon start historyserver)
一、打包操作
1、在pom.xml中下载打包插件
直接将pom.xml里面的build删掉换成下面的部分
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>2、将代码打包成jar文件
(1)先把原来的target文件夹整个删掉,再把一些不必要没用的东西也删掉
(2)在窗口最右端点击Maven,双击红框内容

(3)打包完成后会重新生成target目录,目录下生成了这两个jar包
小的jar包没依赖,大的jar包有依赖,选择主要取决于你的运行环境有没有依赖,接下来我们用到的是有依赖的

3、将文件上传至虚拟机和hdfs指定位置
(1)拖动文件,将jar包和文件分别上传至/opt/jar和/opt/file文件夹中


(2)在hadoop中创建一个文件夹input
hadoop dfs -mkdir /input(3)上传accounts.txt文件至hdfs上
hadoop fs -put accounts.txt /input
4、进行执行
/opt/jar/hdfs_api.jar :jar包的具体路径
org.example.maperduce.account.AccountDriver:Driver的包路径
hadoop jar /opt/jar/hdfs_api.jar org.example.maperduce.account.AccountDriver /input /output

5、查看结果
(1)方式一:web上查看
在Windows上打开网址http://bigdata03:9870 ,点击Utilities进入Browse Directory页面,在红框中输入/output后点击Go!

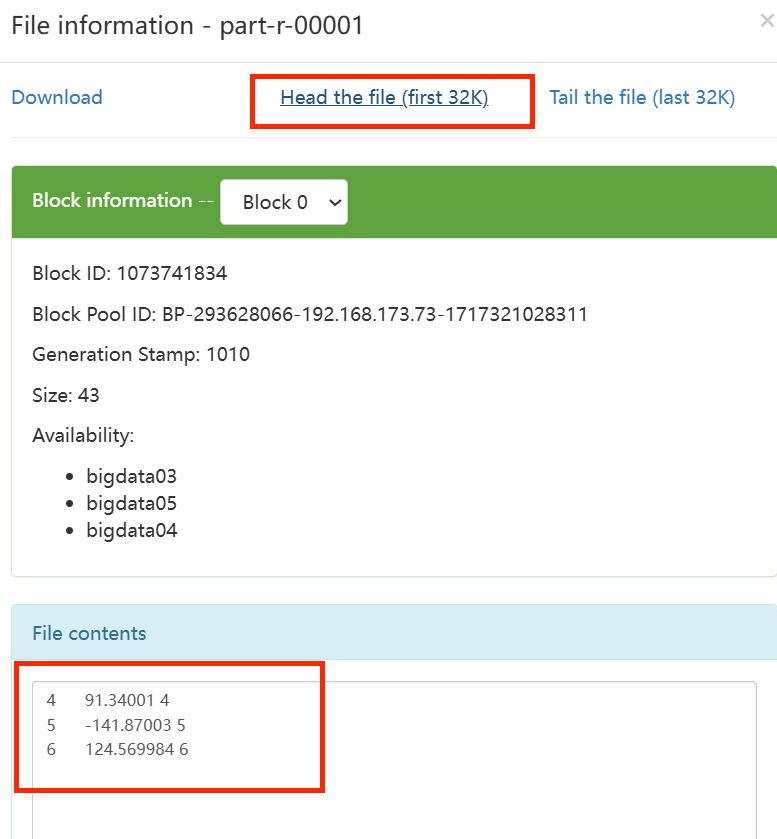
可以挨个点进去再点Head the file查看结果

(2)方式二:终端上查看
hadoop fs -ls /outputhadoop fs -cat /output/part-r-00000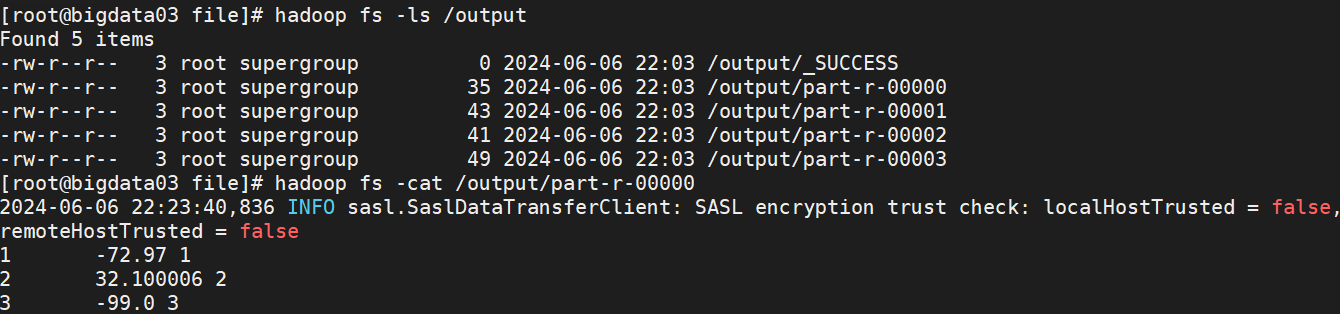
如果二次执行记得删掉/output目录后再执行
执行完成后记得关闭所有服务
二、集群崩溃处理
1、问题表现
在删除/output目录后再二次执行.jar报错信息如下:
org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: Diagnostics report from attempt_1663122661041_0001_m_000000_0: [2022-09-14 15:03:31.933]Container [pid=3059,containerID=container_1663122661041_0001_01_000002] is running 242518528B beyond the 'VIRTUAL' memory limit. Current usage: 76.9 MB of 1 GB physical memory used; 2.3 GB of 2.1 GB virtual memory used. Killing containe
这是由于出现了内存限制的问题
2、解决方法
(1)在mapred-site.xml的<configuration>标签中添加如下内容
<!-- 是否对容器强制执行虚拟内存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for
containers</description>
</property>
<!-- 为容器设置内存限制时虚拟内存与物理内存之间的比率 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>5</value>
<description>Ratio between virtual memory to physical memory when
setting memory limits for containers</description>
</property>(2)在yarn-site.xml的<configuration>标签中添加如下内容
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
<description>default value is 1024</description>
</property>(3)找到集群中配置文件的位置
我的配置文件在/opt/softs/hadoop3.1.3/etc/hadoop目录下
(4)直接在MobaXterm中删除mapred-site.xml和yarn-site.xml
(5)直接拖动新的文件至原来的地方
我这里没有用命令行的形式去实现,也可以用vim命令实现,只要添加对应内容至两个.xml文件即可