若该文为原创文章,转载请注明原文出处。
一、介绍
PP-OCR 是百度公布并开源的OCR领域算法,一个轻量级的OCR系统,在实现前沿算法的基础上,考虑精度与速度的平衡, 进行模型瘦身和深度优化,使其尽可能满足产业落地需求。
PP-OCR是一个两阶段的OCR系统,其中文本检测算法选用DB,文本识别算法选用CRNN,并在检测和识别模块之间添加文本方向分类器,以应对不同方向的文本识别。
原本想测试PP-ORCv4,但在训练数据时,显卡内存一直报错,原因未知,修改参数无效,所以本章记录的是PP-ORCv3训练及部署,PP-ORCv4理论方法一样,可以自行测试,如有成功往告知。
二、 平台介绍
1、训练平台: Autodl
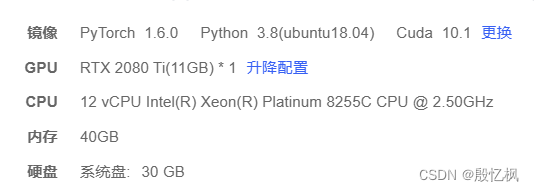
2、开发板: ATK-DLRK3568
3、系统: buildroot
可以使用自己的电脑训练或平台租服务器,必须要有GPU.
三、环境搭建
1、创建虚拟环境
conda create -n paddle_env python=3.82、激活
conda activate paddle_env3、下载PaddleOCR
https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.7使用git克隆或直接下在到虚拟机解压。
4、安装轮子
cd PaddleOCR-release-2.7
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple5、安装paddle
开始使用_飞桨-源于产业实践的开源深度学习平台 (paddlepaddle.org.cn)
根据CUDA版本自行安装配套版本,租的是2080 CUDA 10.1,下面命令安装:
python -m pip install paddlepaddle-gpu==2.3.2.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html6、paddle验证
使用 python 进入 python 解释器
# 输入
import paddle
# 再输入
paddle.utils.run_check()如果出现PaddlePaddle is installed successfully!,说明您已成功安装。

卸载
python -m pip uninstall paddlepaddle四、标注工具使用
使用的数据集不是自己标注的,用的是一个车牌识别的数据集。
但标注工具了解一下
1、安装标注工具
cd PaddleOCR/PPOCRLabel
python setup.py bdist_wheel
pip install .\dist\PPOCRLabel-2.1.3-py2.py3-none-any.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
PPOCRLabel --lang ch2、打开PPOCRLabel
PPOCRLabel --lang ch3、PPOCRLabel使用说明
PPOCRLabel使用自行了解
五、测试
测试训练等都需要模型,所以先下载模型
1、下载模型
PaddlePaddle/PaddleOCR: Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices) (github.com)
分别下载PP-OCRv3的检测和识别的推理模型和训练模型
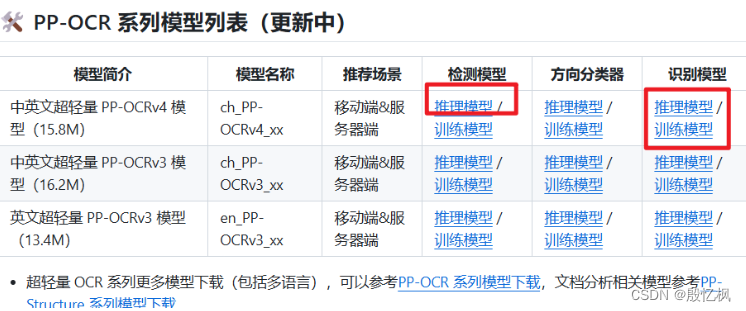
模型分别放在inference_model和pretrain_models目录下,没有自行新创建
![]()
inference_model存放推理模型

2、下载测试数据
https://paddleocr.bj.bcebos.com/dygraph_v2.1/ppocr_img.zip下载后解压
3、测试
命令是推理测试,根据自己的路径需要image和model
python tools/infer/predict_system.py --image_dir="../ppocr_img/imgs/11.jpg" --det_model_dir="./inference_model/ch_PP-OCRv3_det_infer/" --rec_model_dir="./inference_model/ch_PP-OCRv3_rec_infer/"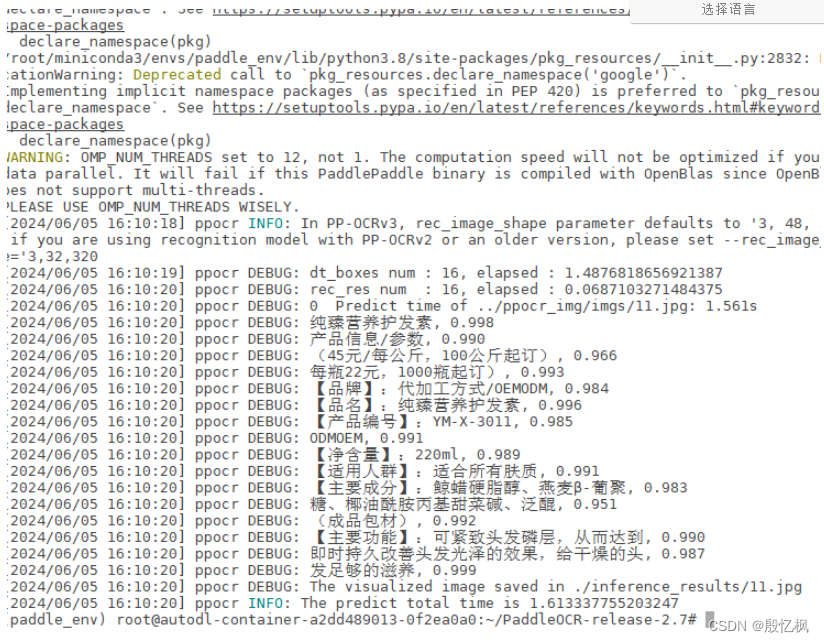
六、文本检测模型训练
自行准备数据集(或是用官方提供的,但测试官方的数据集有问题没测试通过)
1、修改配置文件
修改config/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml配置文件,主要修改train和test路徑
# 1、训练数据集路径
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/images_det/train/
label_file_list:
- ./train_data/images_det/det_label_train.txt
ratio_list: [1.0]
# 2、测试数据集路径
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data/images_det/test/
label_file_list:
- ./train_data/images_det/det_label_test.txt2、训练
python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_det_distill_train/best_accuracy.pdparams
等待,训练500轮大概3-4小时
输出模型保存在./output/ch_PP-OCR_V3_det目录下。
3、测试
python tools/infer_det.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.infer_img="./doc/imgs/car.jpg" Global.pretrained_model="./output/ch_PP-OCR_V3_det/best_accuracy"4、inference 模型导出
训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。 inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
导出模型命令:
python tools/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model="./output/ch_PP-OCR_V3_det/best_accuracy" Global.save_inference_dir="./output/det_PP-OCRv3_inference/"
七、文字识别模型训练
1、修改配置文件
修改配置文件configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
这里需要注意的是显存问题,默认的配置使用8卡,如果训练出错需要修改下面两个参数:
batch_size_per_card: 64
num_workers: 2修改的内容
# 1、训练路径
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/images_rec/train/
ext_op_transform_idx: 1
label_file_list:
- ./train_data/images_rec/rec_label_train.txt
# 2、batch_size
loader:
shuffle: true
batch_size_per_card: 64
drop_last: true
num_workers: 2
# 3、测试路径
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data/images_rec/test/
label_file_list:
- ./train_data/images_rec/rec_label_test.txt
# 4、batch_size
loader:
shuffle: false
drop_last: false
batch_size_per_card: 16
num_workers: 12、训练
python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy.pdparams
3、inference 模型导出
python tools/export_model.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model="./output/rec_ppocr_v3/best_accuracy" Global.save_inference_dir="./output/rec_PP-OCRv3_inference/"八、导出ONNX模型
1、安装paddle2onnx
python -m pip install paddle2onnx -i https://pypi.tuna.tsinghua.edu.cn/simple
python -m pip install onnxruntime==1.9.0 -i https://pypi.tuna.tsinghua.edu.cn/simple2、导出det模型
paddle2onnx --model_dir ./output/det_PP-OCRv3_inference --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./output/det_PP-OCRv3_inference/car_ocrv3_det.onnx --opset_version 12# Seting fix input shape
python -m paddle2onnx.optimize --input_model ./output/det_PP-OCRv3_inference/car_ocrv3_det.onnx --output_model output/det_PP-OCRv3_inference/ppocrv3_det.onnx --input_shape_dict "{'x':[1,3,480,480]}"
3、导出rec模型
paddle2onnx --model_dir ./output/rec_PP-OCRv3_inference --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./output/rec_PP-OCRv3_inference/car_ocrv3_rec.onnx --opset_version 12 Seting fix input shape和det的不一样
python -m paddle2onnx.optimize --input_model ./output/rec_PP-OCRv3_inference/car_ocrv3_rec.onnx --output_model output/rec_PP-OCRv3_inference/ppocrv3_rec.onnx --input_shape_dict "{'x':[1,3,48,320]}"
至此,模型训练完成。
九、ONNX模型测试
测试使用的是airockchip/rknn_model_zoo (github.com)测试,安装环境可以查看正点原子的教程安装。
1、测试ppocrv3_det.onnx
把上面转换后的ONNX模型复制到rknn_model_zoo-main\examples\PPOCR\PPOCR-Det\model目录下,在进入目录 rknn_model_zoo-main\examples\PPOCR\PPOCR-Det\python目录
执行下面命令测试
python ppocr_det.py --model_path ../model/ppocrv3_det.onnx
2、测试ppocrv3_rec.onnx
把上面转换后的ONNX模型复制到rknn_model_zoo-main\examples\PPOCR\PPOCR-Rec\model目录下,在进入目录 rknn_model_zoo-main\examples\PPOCR\PPOCR-Rec\python目录
执行下面命令测试
python ppocr_rec.py --model_path ../model/ppocrv3_rec.onnx
测试检测输出正常,由于训练的轮数不够,所以识别率有点低。
转成RKNN模型及部署到开发板上参考前面文章。
至此训练部署正常。
遗憾PP-ORCv4训练没有跑通。
如有侵权,或需要完整代码,请及时联系博主。