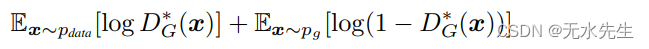作者:Tshb
引言
书接上回:《运维监控领域你不得不知道的黑话-中篇》。
在上一讲中,我们对监控系统中的四种指标类型进行了详细的阐述。不同类型的指标可以提供不同维度的系统信息,通过对比不同类型的指标,可以让我们更清晰地了解系统的整体健康状况和性能趋势,从而实现更精确的系统监控。
除了监控指标的收集、分析及展示外,监控系统还有另一个关键部分,那就是异常告警。
今天就让我们一起探讨告警部分相关的一些关键概念,如告警收敛、告警静默、告警闭环以及告警自愈等。同样,为了便于大家理解,在讨论这些监控概念时,我会以 Mapmost Alpha(空间场景轻应用创作平台)为例,介绍各个概念在实际应用中的表现形式。
告警收敛
在复杂的系统中,一个单一的基础设施层面的故障,就可能导致成百上千的告警。比如出现基础网络问题时,系统可能会产生主机节点不可达告警、服务或应用程序连接超时告警等一系列告警事件,形成告警风暴。
这样不仅会导致接收告警的媒介拥塞,比如手机不停接收到短信和电话呼入,没办法使用,还会导致运维团队可能会被大量的告警淹没,难以快速识别问题的核心,拖慢故障修复的速度。
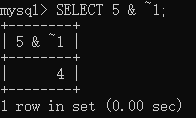
这个时候,我们就要想办法让告警事件变少,用的方法就是告警收敛。告警收敛的典型手段一个是告警聚合,另一个是告警抑制。
告警聚合
告警聚合是指将短时间触发的多个相似或有一定关联的告警聚合成一个单一的告警发送。聚合可以采用不同的维度,比如时间维度、策略维度、监控对象维度等等。
下面我们来举一个 Mapmost Alpha 平台中告警聚合的实例。
在虚拟化平台进行数据备份活动时通常需要进行大量的磁盘 I/O 操作,占用磁盘带宽,导致其上运行的 Mapmost Alpha 虚拟主机节点同时出现 I/O 读写延迟增大的现象,进而产生大量的 IO 相关告警。此时就可以以告警事件类型为维度,配置告警聚合,减少告警事件:
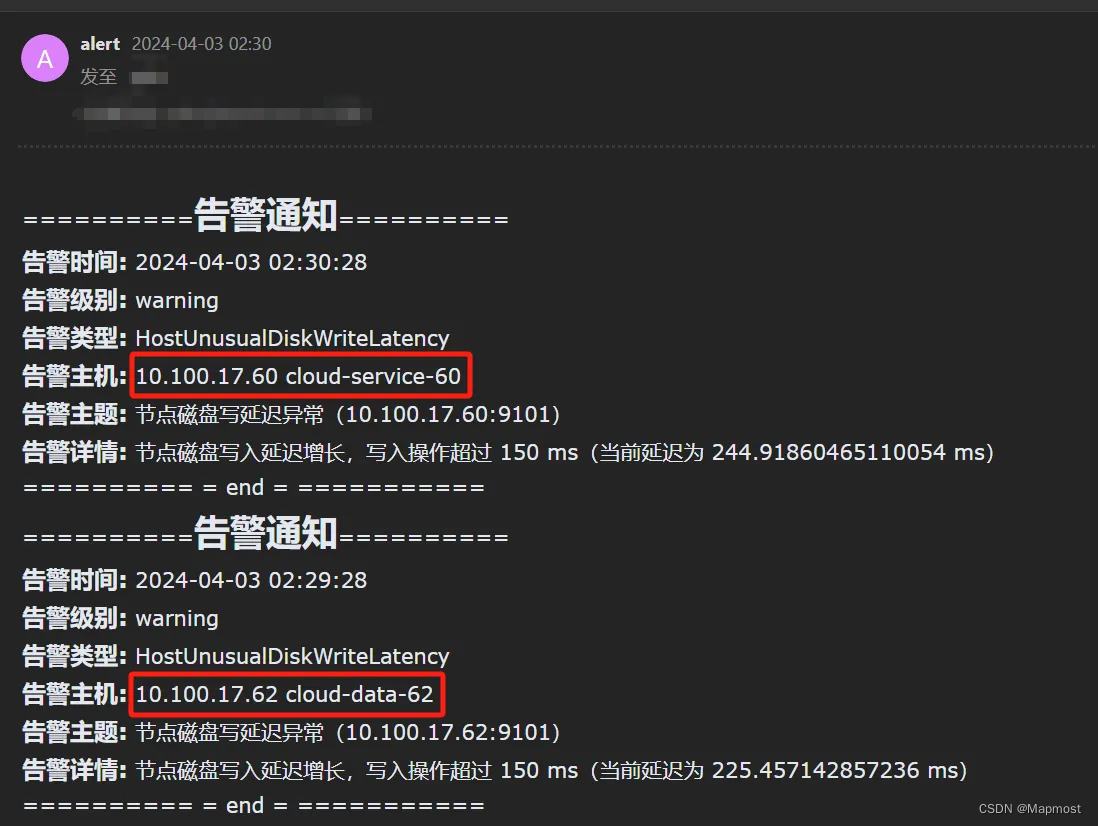
Mapmost Alpha 平台告警聚合示例,来源:@Tshb
可见配置了告警聚合后,不同主机的告警事件聚合为了单一告警,由此实现了告警收敛。
告警抑制
告警抑制指根据某些预定义的规则暂时隐藏或不显示告警。
我们来看一下 Alertmanager 中默认告警抑制规则配置:
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']上述配置表示,同时存在 critical 与 warning 级别的告警,且两个告警的 alertname、dev、instance 标签均相等时,warning 级别的告警会被抑制,不会触发告警通知。
如将主机宕机定义为 critical 级别,将服务不可达定义为 warning,此时若主机宕机,则只会触发宕机告警,不再触发服务不可达告警,从而实现告警收敛。
告警静默
在上述 Mapmost Alpha 平台的实际应用示例中,虽然我们通过告警聚合的手段,有效减少了告警通知的数量,但我们仍然会收到少量告警通知。而这些告警事件实际上是不需要我们去处理的,所以这些告警通知并没有意义。这时就引入了告警静默的方法。
告警静默指通过预定义静默窗口,在这段时间内,系统的告警通知将被暂停。其通常由用户手动设置,用于在已知的维护事件或已知的问题被解决的过程中防止不必要的告警通知干扰。
假设虚拟化平台数据备份的时间为凌晨 1:00~1:30,就可以针对 I/O 延迟告警,在 Alertmanager 中配置下述的告警静默:
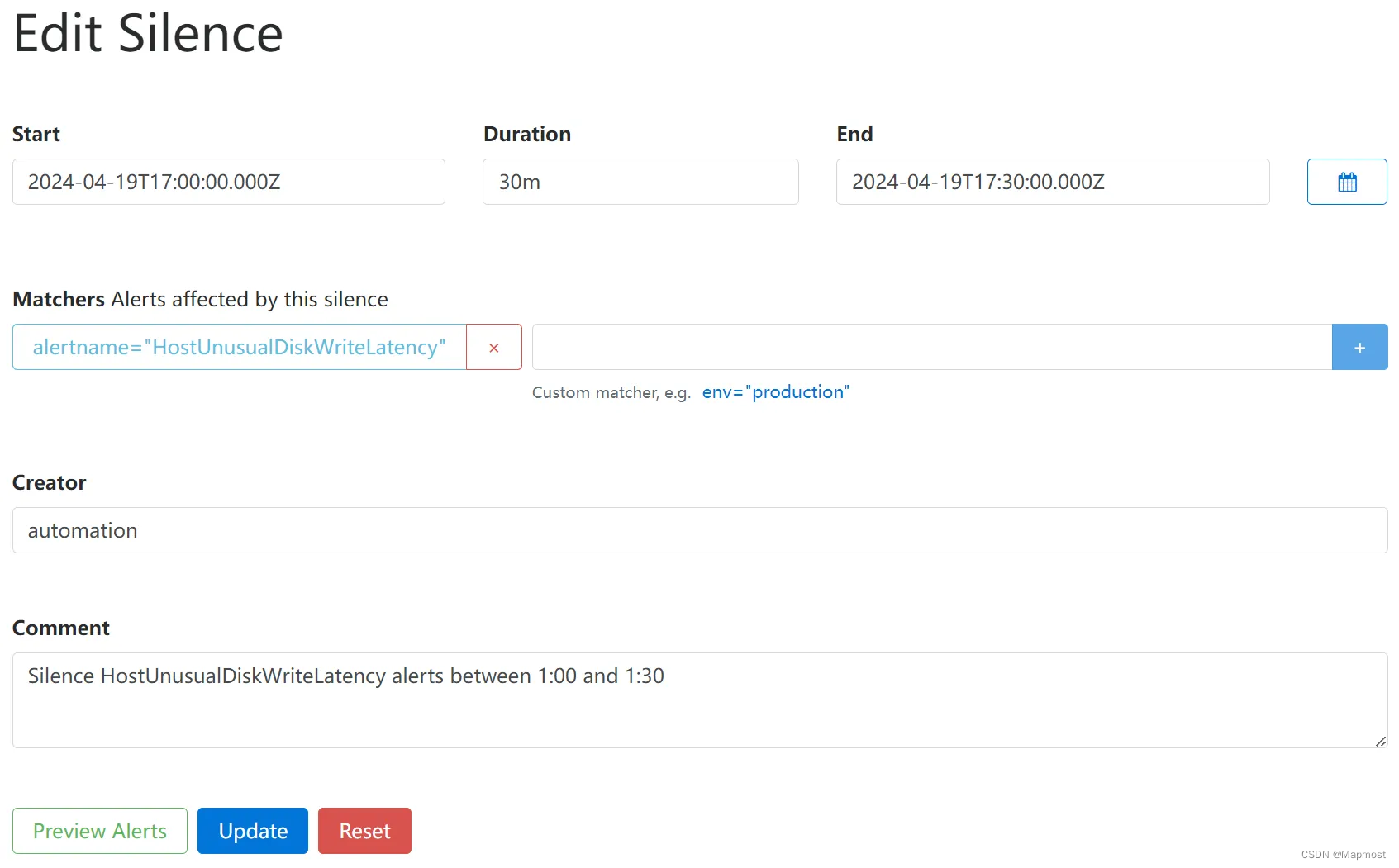
Mapmost Alpha 平台告警静默示例,来源:@Tshb
需注意的是,Alertmanager 并不支持周期性的告警静默,所以想实现每天 1:00~1:30 的告警静默,还需我们编写简单脚本,调用 Alertmanager API 并配置计划任务实现。脚本简单示例如下:
#! /bin/bash
curl -X POST -H "Content-Type: application/json" -d '{
"matchers": [
{
"name": "alertname",
"value": "HostUnusualDiskWriteLatency"
}
],
"startsAt": "'$(TZ=UTC date -d 'TZ="Asia/Shanghai" +1 days 1:00' '+%Y-%m-%dT%H:%M:%SZ')'",
"endsAt": "'$(TZ=UTC date -d 'TZ="Asia/Shanghai" +1 days 1:30' '+%Y-%m-%dT%H:%M:%SZ')'",
"createdBy": "automation",
"comment": "Silence HostUnusualDiskWriteLatency alerts between 1:00 and 1:30"
}' http://127.0.0.1:9093/api/v1/silences告警闭环
告警闭环是指从告警的发生、通知、处理到问题解决的完整流程。一个有效的闭环系统不仅会发送告警,并且会跟踪告警状态,直到问题被确认并解决。在故障解决后,相关告警会被自动或手动关闭,以防止重复处理。
实现告警闭环的手段有很多,在 Mapmost Alpha 平台的闭环流程中,主要包括下述几个手段:
1.告警排班
制定值班表,每日轮班的人是当天的第一责任人。责任到人更容易推进问题解决,而其他人也可以心无旁骛地进行一些长线工作。
责任人不一定要处理每一个的告警事件,但需要保证每一个告警事件都有人处理,并了解每一个告警事件的处理进展,避免告警事件的遗漏或重复处理。
2.制定告警升级机制
在告警事件没有被及时认领,或处理时间较长时,将告警事件进行升级,组织更多的相关人员或专家进行协同处理。
3.总结与优化
解决问题后,需要验证措施的有效性并确保问题已被解决。此外,对告警事件进行回顾,从中学习以改进未来的响应和预防措施,并整理完善告警预案。
告警自愈
告警自愈是指系统在检测到问题并发出告警后,能够自动执行一系列的动作以尝试解决问题。
目前比较典型的方法是配置 Webhook,当告警触发之后自动回调某个 HTTP 接口,来串联一些自动化的逻辑,让告警事件无人值守自动处理。如当磁盘使用率超过 80% 后,调用 HTTP 接口清理无用的日志。
但由于生产环境中遇到的故障往往都是较为复杂的,不会总是清理日志这么简单,这就造成自动化逻辑较难编写的问题。
所以我们不妨换一个角度思考,告警自动处理的这段逻辑,未必一定要做到告警自愈,有时只是使用这个机制来抓现场,也是非常有价值的。比如某个主机节点发生 OOM 时,获取机器的一些运行情况如资源占用情况、系统日志信息等等,节省手动登录机器查看信息的时间,从而提高问题处理的效率。
小结
本文书接上回:运维监控领域你不得不知道的黑话-中篇》,对监控系统中告警相关的概念进行了详细的阐述,并以 Mapmost Alpha(空间场景轻应用创作平台)系统为例,介绍了这些指标类型在实际应用中的具体表现形式及效果。
作为一个数字孪生应用创作工具,Mapmost Alpha 平台的稳定性对于用户至关重要。平台通过灵活运用各种监控指标,如系统负载和请求响应时间等,实时监控服务的状态,确保能够及时发现并解决潜在的问题。此外,Mapmost Alpha 平台具有高效的告警系统,其不仅能够及时将异常通知到运维团队,还能够通过自动化流程实现告警的快速收敛和闭环处理。
最后,将本文重点总结如下,感谢大家的阅读~
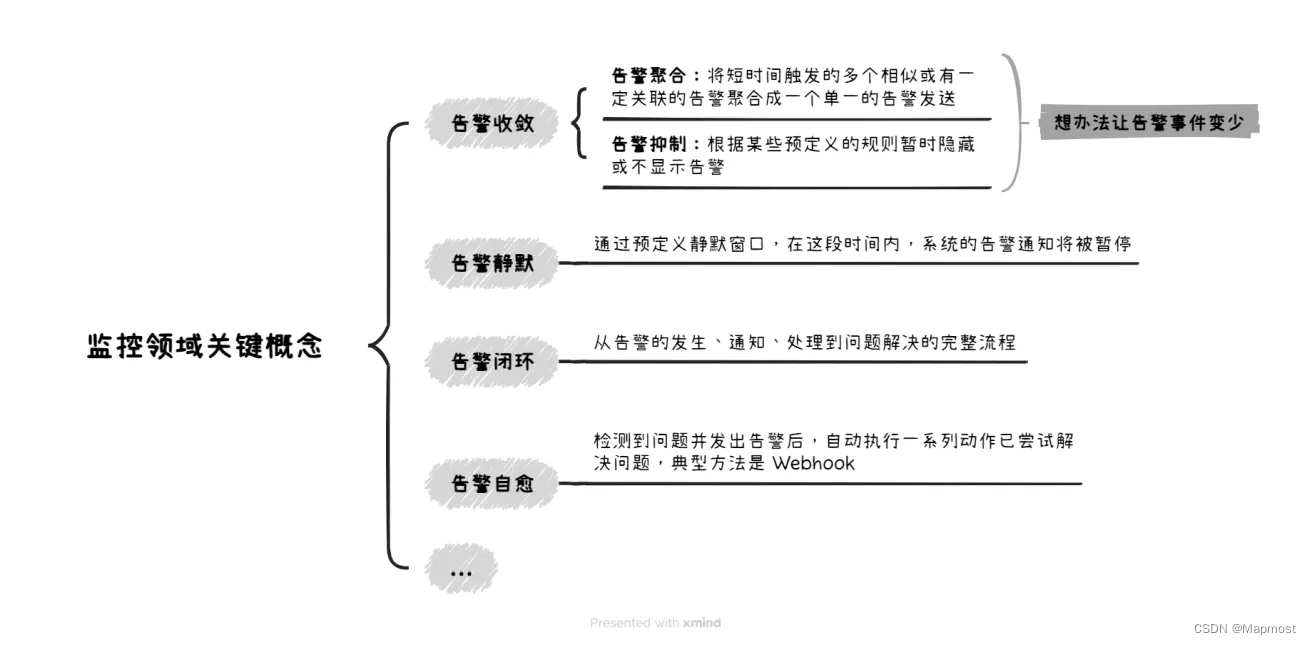
监控领域关键概念小结,来源:@Tshb
参考资料:
- 02|基本概念:监控圈子有哪些行业黑话?-运维监控系统实战笔记-极客时间
- Mapmost官网
关注Mapmost,持续更新GIS、三维美术、计算机技术干货
Mapmost是一套以三维地图和时空计算为特色的数字孪生底座平台,包含了空间数据管理工具(Studio)、应用开发工具(SDK)、应用创作工具(Alpha)。平台能力已覆盖城市时空数据的集成、多源数据资源的发布管理,以及数字孪生应用开发工具链,满足企业开发者用户快速搭建数字孪生场景的切实需求,助力实现行业领先。
欢迎进入官网体验使用:Mapmost——让人与机器联合创作成为新常态